- The paper introduces an end-to-end framework that enables real-time video QA through dual sliding-window context management.
- It employs a five-stage data engine to create robust streaming QA training data and a silent-speech balanced loss to mitigate response bias.
- Experimental results show state-of-the-art performance across multiple benchmarks with low latency and scalable deployment.
AURA: Unified, Real-Time Video Stream Understanding and Assistance
Introduction and Motivation
AURA introduces an end-to-end unified framework for always-on VideoLLMs that supports real-time understanding and user interaction over live video streams. Most previous VideoLLMs focus on offline or segment-based inference, limiting their applicability for live, time-sensitive AI assistant scenarios. Existing streaming solutions often employ decoupled trigger-response pipelines or remain constrained to narration-oriented outputs, both insufficient for robust, open-ended, and long-horizon video question answering. AURA directly targets the dual challenges in streaming video QA: enabling autonomous, silent observation interrupted by timely, contextually-triggered response; and managing unbounded multimodal context in circumstances where the user or system might interleave queries and responses over arbitrarily long time horizons.
Interactive Video Stream Context Management
AURA proposes a dual sliding-window context management scheme that enables scalable, low-latency inference over long, continuous video streams with interspersed QA interactions. The system divides the incoming video into small, temporal chunks (e.g., 1 second), organizing them with associated user queries as conversational turn-style messages. User queries can arrive at any time, and assistant responses can be immediate, delayed, or continuous.
To efficiently manage memory and compute, AURA maintains:
- A sliding window of the N most recent seconds of video visible to the model, preserving locality and focusing on relevant frames for current reasoning.
- A sliding window over the last M QA groups, outside the main video window, where each group includes a user query and associated assistant responses (non-silent).
This approach maintains pertinent historical interaction without exceeding the LLM context or incurring escalating latency costs.
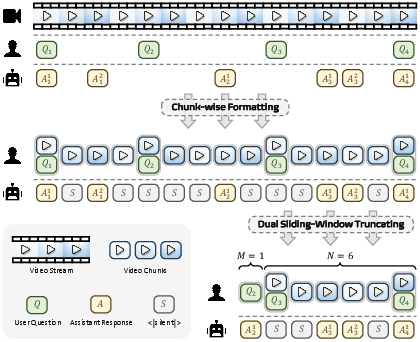
Figure 1: Dual sliding-window strategy for limiting active context: recent video chunks and selected historical QA groups.
This mechanism directly supports three streaming QA modes:
- Real-Time QA: Immediate response to a user's query, synchronized with the present video context.
- Proactive QA: Delayed response, where the model waits for sufficient future evidence before answering.
- Multi-Response QA: Event-tracking queries that require the model to produce ongoing responses as the situation evolves, without multiple explicit queries.
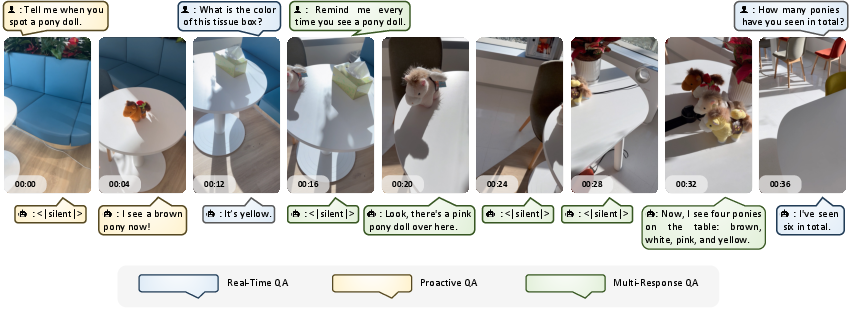
Figure 2: Three streaming QA paradigms, each with distinct response triggers and timing: Real-Time, Proactive, and Multi-Response QA.
Coarse-to-Fine Streaming Data Engine
AURA includes a five-stage pipeline for constructing high-quality, structured streaming QA training data aligned with the model’s operation:
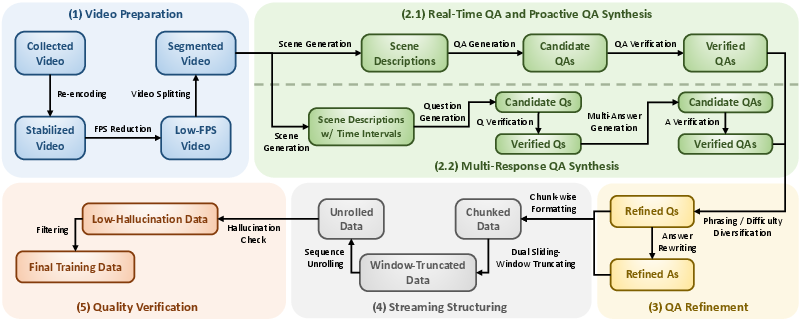
Figure 3: Five-stage data engine: Video Preparation, QA Synthesis, QA Refinement, Streaming Structuring, and Quality Verification.
- Video Preparation: Collects and standardizes videos from diverse domains.
- QA Synthesis: Uses an MLLM to segment videos temporally, generate timestamped QA pairs for Real-Time/Proactive interactions, and synthesize Multi-Response scenarios.
- QA Refinement: Increases QA type and phrasing diversity via targeted augmentation and rephrasing.
- Streaming Structuring: Packs QA pairs into streaming-style sample sequences, matching the model's inference structure with proper supervision masking.
- Quality Verification: Ensures answers remain grounded and temporally valid after context truncation, reducing hallucination risk.
The data distribution exhibits broad QA types and diverse video sources, supporting generalization and robust event reasoning.
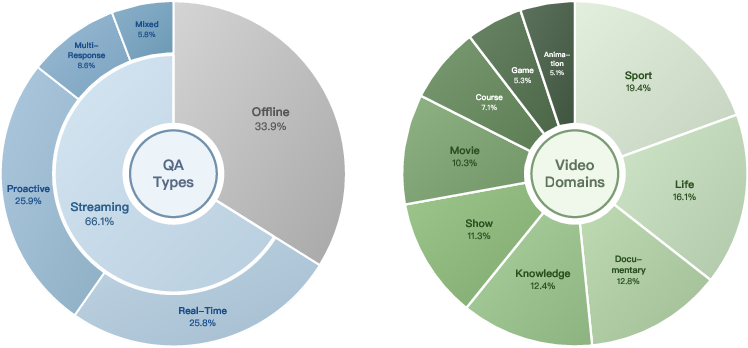
Figure 4: Distribution of QA types and video domains; dataset supports wide-ranging interaction and video content.
Silent-Speech Balanced Loss and Training Objective
AURA addresses the silent-turn bias inherent in streaming video understanding. In natural streams, <|silent|> tokens (moments when the assistant remains silent) vastly outnumber informative assistant responses. Uniform supervision yields a pathological preference for silence.
AURA applies a selective supervision mask:
- Loss is applied only to the last non-silent assistant response in each training sample, ensuring that the target is contextually valid after window truncation.
- All silent assistant messages within the chunk are down-weighted in the loss by the inverse silent-to-non-silent ratio, balancing the gradient signals and preventing over-silencing.
This objective preserves the ability to remain silent but ensures timely and confident response when sufficient evidence arises.
Real-Time Streaming Inference System
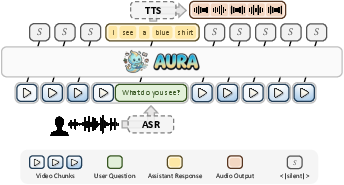
The AURA inference framework integrates ASR, TTS, video chunking, context management, and model inference into an asynchronous pipeline. The system supports:
Inference performance is characterized by low time-to-first-token (TTFT) and bounded computational cost per response, even for long streams. Introducing prefix cache reuse and sliding-windows is crucial for controlling both latency and memory consumption.
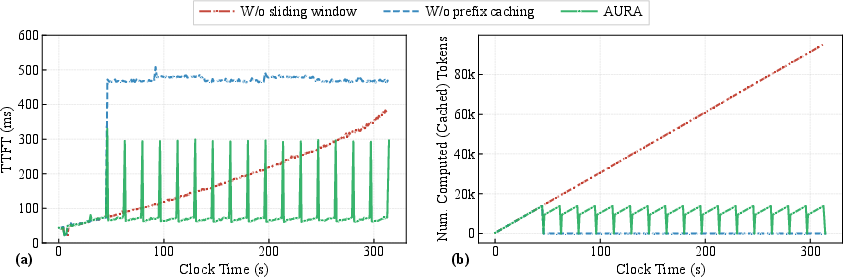
Figure 6: TTFT and computed-token count comparisons; AURA maintains stable, low latency with sliding-window and prefix caching.
End-to-end system latency (ASR → LLM → TTS) is approximately 312 ms for a typical interaction, supporting practical real-time applications.
Experimental Results
AURA establishes state-of-the-art open-source performance on all three major streaming video understanding benchmarks:
- StreamingBench: 73.1% accuracy (open-source SOTA by 10.4%, surpasses proprietary Gemini-1.5-Pro by 6.0%)
- OVO-Bench: 65.3% accuracy (open-source SOTA, best in two of three high-level settings)
- OmniMMI: 25.4% accuracy (best overall; top performance on 5/9 fine-grained metrics)
AURA sustains competitive performance on offline video benchmarks with modest, expected degradation, evidencing effective transfer from streaming optimization to canonical offline tasks.
Ablation studies validate the necessity of the Silent-Speech Balanced Loss for actionable, proactive behavior in streaming settings—default cross-entropy loss models become excessively silent and underperform across all positive-response metrics.
Implications and Future Prospects
AURA demonstrates the feasibility of unified, always-on VideoLLMs for complex, long-horizon, real-time human-AI visual interaction. The architecture and training strategy enable:
- Asynchronous, context-aware, multimodal streaming dialogue (across video, speech, and text).
- Proactive and multi-shot event grounding, suitable for open-ended surveillance, robotics, and real-world assistant applications.
- Efficient, scalable deployment on commodity accelerator clusters (2 FPS, 80 GB HBM3 ×2 for real-time operation).
Future research directions include: extending to multilingual/multimodal dialogue; scalable deployment to edge devices; enhanced event-to-action chaining for embodied AI; and active exploration of reinforcement learning on top of complex, interleaved user-assistant interactions in temporally continuous environments.
Conclusion
AURA provides a robust, open framework for real-time, proactive, and always-on video stream question answering via a unified VideoLLM. The key advances in context management, data synthesis, silent-response balancing, and latency-aware inference optimization collectively establish a new baseline for streaming visual understanding. By releasing both the model weights and supporting system, the work enables systematic advancement toward deployable, contextually intelligent visual agents.