Streaming Video Instruction Tuning
Abstract: We present Streamo, a real-time streaming video LLM that serves as a general-purpose interactive assistant. Unlike existing online video models that focus narrowly on question answering or captioning, Streamo performs a broad spectrum of streaming video tasks, including real-time narration, action understanding, event captioning, temporal event grounding, and time-sensitive question answering. To develop such versatility, we construct Streamo-Instruct-465K, a large-scale instruction-following dataset tailored for streaming video understanding. The dataset covers diverse temporal contexts and multi-task supervision, enabling unified training across heterogeneous streaming tasks. After training end-to-end on the instruction-following dataset through a streamlined pipeline, Streamo exhibits strong temporal reasoning, responsive interaction, and broad generalization across a variety of streaming benchmarks. Extensive experiments show that Streamo bridges the gap between offline video perception models and real-time multimodal assistants, making a step toward unified, intelligent video understanding in continuous video streams.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Streamo, an AI model that can watch a live video and talk about it in real time, like a helpful sports commentator or co-pilot. Unlike many previous models that only work on full, pre-recorded videos, Streamo can handle continuous video streams and decide the right moments to speak, explain actions, answer time-sensitive questions, and point out exactly when something important happens.
What questions did the researchers ask?
The researchers focused on two big questions:
- How can we build an AI that watches a video stream live and decides when to talk, what to say, and when to stay quiet?
- What kind of training data and testing setup do we need so the AI can handle many different live video tasks (like narration, action understanding, and answering changing questions) without getting confused?
How did they do it?
They designed both a new model and a special training dataset to teach the model how to behave during live video.
One model that both “listens” and “talks”
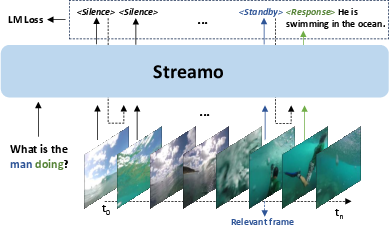
Most older systems separate two jobs: one small model decides if it’s time to speak, and a big model generates the answer. Streamo combines these into a single model, so it can understand what’s happening and respond immediately without waiting for a separate controller. This makes responses faster and better timed.
Special state tokens: Silence, Standby, Response
Think of Streamo like a polite friend watching a show with you:
- Silence: keep watching, nothing to say yet.
- Standby: something relevant might be happening—pay close attention.
- Response: now is the right moment to speak.
These “state tokens” are built into the model’s output, so it can choose when to stay quiet and when to jump in, almost like a traffic light guiding its behavior.
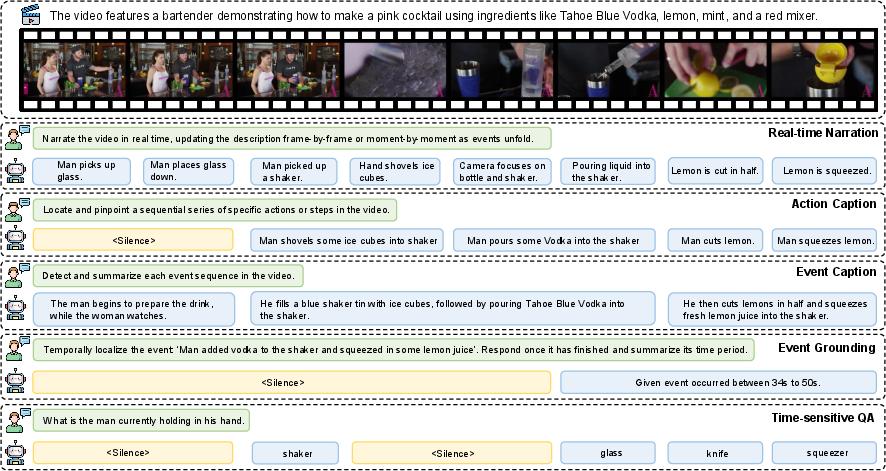
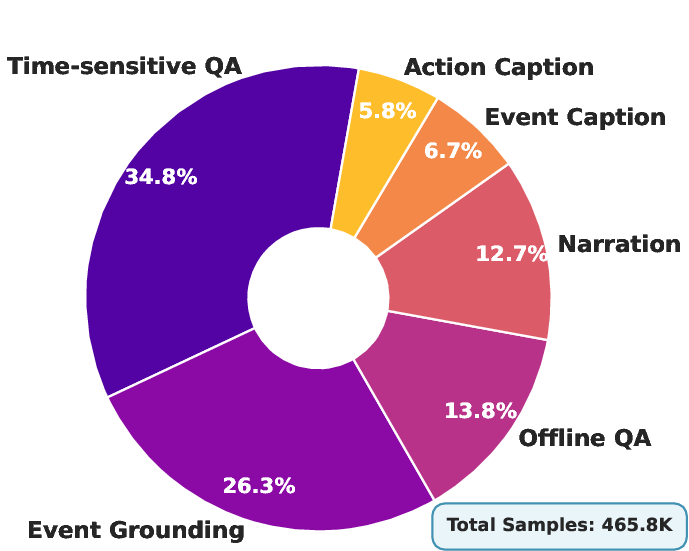
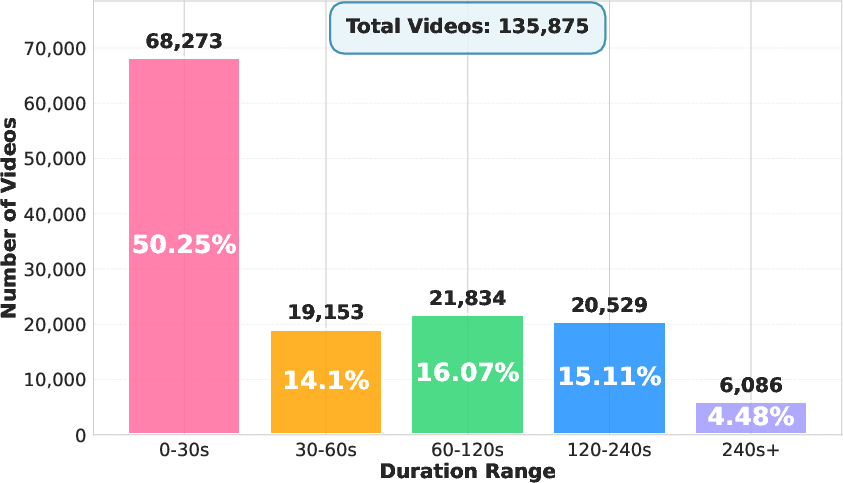
A big training set built for live video
The team created Streamo-Instruct-465K, a large training dataset designed specifically for streaming. It teaches the model many skills and the timing of when to use them. The same video can have several types of tasks, so the model learns to handle different instructions on the fly. Tasks include:
- Real-time narration: describing what’s happening second by second.
- Event captioning: summarizing actions when they finish.
- Action captioning: focusing on specific steps or actions.
- Temporal grounding: finding the exact time in the video when an event occurs.
- Time-sensitive Q&A: answering questions where the answer changes as the video changes (like “What color is the light now?”).
To keep everything consistent, they followed a unified labeling style so the model learns precise timing across all tasks.
Teaching the model when to speak
In live videos, most moments are “nothing to say” (Silence), and only a few moments deserve a response. If you train naively, the model might learn to stay quiet too much. To fix this, the researchers used a training trick (called “focal loss”) that gives extra attention to rare but important moments (like Response) so the model learns good timing.
An everyday analogy: If you’re learning to be a lifeguard, most of the day is uneventful, but you must practice reacting to the rare emergencies. Focal loss is like giving extra practice points to those rare events so you don’t miss them.
How they tested it
They evaluated Streamo on:
- Online (streaming) tests that check real-time narration, timing, and multi-turn interaction.
- Offline (standard) video tests to ensure it still understands regular videos well.
- A new benchmark called Streamo-Bench that mixes multiple instructions per video (like grounding, dense captions, and time-sensitive Q&A) to see if the model can follow different kinds of instructions during a live stream.
What did they find, and why does it matter?
Main results:
- Better real-time performance: Streamo beat other open-source streaming models across many tasks, especially in deciding the right moment to speak and giving accurate, timely answers.
- Strong multi-task skills: It handled narration, event/action captioning, temporal grounding, and time-sensitive Q&A in one unified system.
- Still great at offline tasks: Even though Streamo is built for streaming, it also performed strongly on standard (non-live) video benchmarks.
- Robust to faster inputs: A model trained at 1 frame per second could work even better when tested at 2 frames per second, showing good adaptability.
Why it matters:
- Real-world apps need good timing. Think driving assistance, security monitoring, sports commentary, or helping with live online classes. Knowing when to talk is just as important as knowing what to say. Streamo tackles both.
What’s the impact of this research?
This work moves AI towards being a real-time video assistant that:
- Watches continuous streams without missing context.
- Knows when to speak and when to wait.
- Understands many kinds of instructions, not just simple Q&A.
- Can support practical uses like live narration, safety alerts, step-by-step guidance, and event detection.
The authors also released:
- A large, carefully labeled streaming dataset (Streamo-Instruct-465K).
- A new benchmark (Streamo-Bench) to test instruction-following in live video.
Simple limitation and future direction:
- Very long, unending videos can still be memory-heavy and slow. The authors suggest adding smarter memory and compression tricks so the model can handle longer streams more efficiently.
In short, Streamo brings AI closer to being a helpful, real-time teammate for understanding and explaining live video.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of specific gaps and unresolved questions that future work could address:
- Real-time efficiency is not quantified: no end-to-end measurements of latency, jitter, throughput (fps), memory footprint, or energy use under streaming workloads or different hardware; report time-to-first-response and response timing error against ground truth per task.
- Long-sequence handling remains unoptimized: the model lacks concrete mechanisms for scalable context retention over hour-long streams (e.g., empirical evaluations of KV-cache policies, sliding-window attention, adaptive frame compression, visual token pruning) and their impact on accuracy/latency trade-offs.
- Simulated vs. live streaming: evaluations rely on offline videos reformatted into 1-second turns; the system is not stress-tested on live camera feeds with asynchronous frame arrival, dropped frames, network delays, variable frame rates, or multi-camera inputs.
- Limited frame-rate generalization: training at 1 fps and testing at 2 fps is promising, but robustness to higher and variable fps (e.g., 5–30 fps), sub-second events, and rapid motion is unexamined.
- No audio modality: despite positioning as “omni”/multi-modal, the architecture and dataset omit audio; quantify the benefit of audio cues (e.g., speech, environmental sounds) for response timing and event detection in streaming.
- Decision-state design not analyzed: the three states (
<Silence>,<Standby>,<Response>) lack formal semantics, calibration methods, and error analysis (false alarms vs. misses); evaluate per-task optimal state policies and the need for additional states (e.g., “update”, “revise”, “cancel”). - Lack of user-controllable response cadence: provide mechanisms to tune responsiveness (e.g., minimum inter-response interval, confidence thresholds, task-specific sensitivity) and measure their effects on precision/recall and user experience.
- Early-output revision is unsupported: the system does not demonstrate how it retracts or corrects earlier responses when new evidence arrives; design and evaluate streaming-aware self-correction protocols.
- Instruction dynamics underexplored: datasets pose pre-inserted prompts, but human-in-the-loop scenarios with mid-stream instruction changes, multi-turn clarifications, or conflicting directives aren’t evaluated.
- Dataset relies heavily on model-generated annotations: quality, bias, and temporal consistency of labels from Qwen2.5-VL-72B, GLM-4.5/4.5V, and ARC-Hunyuan-Video-7B lack human validation rates, inter-annotator agreement, or noise quantification; perform audits and corrective labeling.
- Possible evaluator bias in Streamo-Bench: caption “win rate” is judged by Qwen2.5-VL-72B, risking circularity and bias; introduce multi-judge ensembles, human assessments, and task-specific metrics (e.g., BERTScore, CIDEr, time-to-correct).
- Grounding metrics are narrow: grounding uses mIoU on temporal spans without reporting temporal precision/recall, onset/offset error, or tolerance analyses; add latency-aware and alignment-specific metrics for streaming.
- Domain coverage and distribution gaps: Streamo-Instruct-465K’s composition (egocentric vs. third-person, surveillance, sports, driving, screen recordings) isn’t quantified; assess generalization and failure modes across diverse domains and camera dynamics.
- Robustness stress-testing is missing: evaluate under occlusion, motion blur, lighting changes, scene cuts, compression artifacts, and adversarial perturbations; quantify degradation and recovery strategies.
- Sequence memory and drift: measure how long-range context affects decision accuracy and whether the model suffers from context drift or forgetting over long sessions; propose memory refresh and summarization strategies.
- Training design constraints: vision encoder is frozen; the effect of full or partial encoder fine-tuning on streaming tasks, response timing, and offline performance is unexplored.
- Loss design sensitivity: focal loss hyperparameters (e.g., γ, α weighting) aren’t ablated across tasks or streams; compare against alternative imbalance remedies (dynamic reweighting, class-balanced loss, label smoothing, sequence-level objectives).
- Reinforcement learning for decision timing: consider RL/policy gradient or direct preference optimization that explicitly optimizes time-to-correct response, false-alarm cost, and missed-event penalties; benchmark against supervised-only training.
- Task-unification choices: all tasks are cast as next-token generation with special tokens; evaluate whether dedicated heads or structured predictors (e.g., span regressors, pointer networks) improve event/time localization and reduce textual ambiguity.
- Event boundary granularity: 1-second segmentation may be too coarse for fast actions and too fine for long activities; study adaptive windowing, multi-scale temporal granularity, and their impact on different tasks.
- Handling missing or conflicting annotations: the dataset’s multi-task labels per video can conflict; provide consistency checks and methods to resolve contradictions (e.g., constraint-based training, curriculum schedules).
- Safety-critical scenarios: no evaluation on scenarios where delayed or incorrect responses carry risk (e.g., driving, industrial monitoring); introduce safety metrics and conservative decision policies.
- Data provenance and contamination risks: training on outputs from foundation models close to the base model (e.g., Qwen-family) may induce self-imitation and bias; assess out-of-family labeling sources and cross-model contamination effects.
- Scaling beyond 7B: study compute–accuracy scaling (3B→7B→>7B), memory pressure in streaming, and MoE architectures; quantify cost-benefit across deployment targets (edge vs. cloud).
- Tool use and external knowledge: the system doesn’t integrate OCR specialists, ASR, trackers, or retrieval; evaluate plug-in tool invocation in-stream and its latency implications.
- Real-time benchmark gaps: OVO-Bench and Streamo-Bench do not report standardized latency/bandwidth constraints or device-level measurements; create hardware-aware benchmarks with strict real-time budgets.
- Data splits and reproducibility: clarify train/val/test splits, duplicates across datasets, and leakage risks; publish detailed protocols for reproducible streaming evaluations.
- Privacy and ethics: continuous streaming raises privacy concerns (faces, homes, workplaces); outline datasets’ consent status and compliance, and define privacy-preserving inference techniques.
Practical Applications
Practical Applications of Streamo: A Real-Time Streaming Video LLM
Streamo unifies frame-level decision-making (“Silence, Standby, Response”) with text generation, and is trained on Streamo-Instruct-465K to handle multi-task streaming video interaction (real-time narration, action/event captioning, temporal grounding, time-sensitive QA). Below are actionable, real-world applications organized by deployment readiness.
Immediate Applications
These use cases can be prototyped or deployed now using the open-source code, models, and dataset (Streamo, Streamo-Instruct-465K), primarily at low frame rates (1–2 fps) and within modest context lengths.
- Smart surveillance alerts and logging (Public safety, Retail, Facilities)
- Description: Real-time detection and narration of events (e.g., “person enters restricted area,” “object left unattended”), with time-sensitive QA (“Is the exit currently blocked?”) and temporal grounding to produce auditable event windows.
- Tools/workflows: Streamo-based alert service; event timelines with captions; compliance audit logs.
- Assumptions/dependencies: Camera access; low-latency inference (edge GPU/CPU or on-prem server); privacy controls; domain prompts tuned to policies (e.g., “notify me when X occurs”).
- Live sports and broadcast production assistance (Media/Entertainment)
- Description: Real-time narration of plays, action/event captions, and instant grounding of key moments (goals, fouls) to speed highlight creation.
- Tools/workflows: “Response-state” gating to trigger commentary; auto-tagging highlight reels; operator-in-the-loop QC.
- Assumptions/dependencies: Studio integration; latency budgets; sports-specific prompt templates; rights management.
- Accessibility narration for low-vision users (Healthcare, Consumer apps)
- Description: Second-by-second environment descriptions and time-sensitive QA (“Has the traffic light turned green?”), delivered via wearable camera or phone.
- Tools/workflows: Mobile app with Streamo inference; personalized instruction presets (e.g., “describe obstacles”).
- Assumptions/dependencies: On-device or nearby edge inference; battery limits; safety disclaimers; robust in varied lighting.
- Industrial process monitoring and operator assistance (Manufacturing, Energy)
- Description: Real-time captioning and grounding of steps (“valve closed,” “conveyor stopped”), time-sensitive QA on equipment states to reduce downtime.
- Tools/workflows: Control-room dashboards; shift logs with temporally grounded events; integration with SCADA/MES.
- Assumptions/dependencies: Camera placement; domain adaptation; deterministic latencies; fallback to human confirmation for critical actions.
- Warehouse and logistics operations (Robotics, Supply chain)
- Description: Event/action grounding for pick/pack stages; time-sensitive QA (“How many pallets have passed in the last minute?”); narration for anomalies.
- Tools/workflows: Streamo plug-in for WMS; event-based billing; worker assistance terminals.
- Assumptions/dependencies: Frame-rate sufficient for process speed; occlusion handling; workflow prompts aligned to SOPs.
- Customer experience analytics in retail (Finance, Retail)
- Description: Dense captions of store activity, grounding queue formation and dispersal; time-sensitive QA for KPIs (wait times, staff response windows).
- Tools/workflows: KPI dashboards; alerting when SLA thresholds are breached; temporal evidence for audits.
- Assumptions/dependencies: Privacy-preserving pipelines (face blurring/anonymization); regional regulations; store Wi-Fi bandwidth.
- Video conferencing assistant (Software/Collaboration)
- Description: Real-time narration of meeting-room activities (whiteboard writing, presenter changes), action grounding (start/end of demos), time-sensitive QA (“Who is currently speaking?”).
- Tools/workflows: Meeting platform integration; automatic chaptering; searchable timelines.
- Assumptions/dependencies: Consent and compliance; multi-modal integration (audio + video recommended); consistent camera views.
- Content moderation and platform safety (Trust & Safety)
- Description: Real-time detection and grounded tagging of policy-relevant events; time-sensitive QA (“Is self-harm activity occurring now?”).
- Tools/workflows: Moderation queues; temporal evidence attached to cases; human-in-the-loop review.
- Assumptions/dependencies: Well-defined policy prompts; calibrated thresholds; legal review; robust false-positive handling.
- Research benchmarking and curriculum development (Academia)
- Description: Use Streamo-Bench and Streamo-Instruct-465K to evaluate streaming instruction-following, decision-state learning, and temporal grounding; design new multi-task curricula.
- Tools/workflows: Reproducible benchmark pipelines; ablations on focal loss/alpha weighting; multi-turn dialog experiments.
- Assumptions/dependencies: Access to datasets; compute for fine-tuning; ethics/IRB when using real-world streams.
- Annotation acceleration for video datasets (Software/ML tooling)
- Description: Semi-automatic event/action captioning and temporal boundary proposals to reduce labeling cost.
- Tools/workflows: Streamo-assisted labeling tool; human verification; batch export to standard formats.
- Assumptions/dependencies: Labeling taxonomy alignment; QC pipelines; domain prompts.
- Driver-assistance HUD for dashcams (Automotive)
- Description: Time-sensitive QA and event narration (“pedestrian entering crosswalk,” “light turned green”) at low frame rates.
- Tools/workflows: On-device inference for 1–2 fps; overlay alerts; pairing with existing ADAS sensors.
- Assumptions/dependencies: Latency constraints; safety disclaimers; geographic regulatory compliance.
- Drone and field inspection support (Construction, Utilities)
- Description: Real-time narration and event grounding (crack detection, equipment status changes), time-sensitive QA during flyovers.
- Tools/workflows: Operator console; auto-generated inspection reports with temporal evidence.
- Assumptions/dependencies: Connectivity to edge compute; domain prompts; environmental variability.
Long-Term Applications
These use cases require further research, scaling, or engineering (higher frame rates, longer context, multi-camera fusion, edge optimization, safety validation).
- High-fidelity robotics perception and autonomy (Robotics)
- Description: Continuous, multi-camera temporal reasoning for manipulation/navigation; frame-level output gating to trigger responses or actions.
- Tools/workflows: Streamo as perception module; policy layer connecting “Response” moments to action planners.
- Assumptions/dependencies: 10–30+ fps; tight real-time constraints; safety certification; multimodal fusion (depth, audio, proprioception).
- Clinical patient monitoring and fall detection (Healthcare)
- Description: Persistent, privacy-preserving monitoring with precise temporal grounding of events and time-sensitive QA for staff triage.
- Tools/workflows: Hospital monitoring system with secure storage; alerts routed to nurse stations; audit trails.
- Assumptions/dependencies: Medical-grade reliability; HIPAA/GDPR compliance; on-prem deployment; domain fine-tuning.
- Autonomous driving situational understanding (Automotive)
- Description: Continuous event narration, grounding, and QA across multiple sensors (cameras, LiDAR); temporal evidence for decision logs.
- Tools/workflows: Integration with perception stack; redundancy and failover; regulatory reporting.
- Assumptions/dependencies: Sub-100ms latency; multi-sensor fusion; rigorous validation; domain-specific datasets.
- Smart cities and traffic management (Public policy, Infrastructure)
- Description: City-scale monitoring with time-sensitive KPIs (congestion onset/relief), event grounding (accidents), and automated notification.
- Tools/workflows: Centralized dashboards; incident response workflows; public transparency reports.
- Assumptions/dependencies: Data governance; citizen privacy; edge compute at intersections; resilient networking.
- Multimodal education tools (Education)
- Description: Real-time instruction-following for lab demos and experiments; grounding step completion and answering time-sensitive student questions during live streams.
- Tools/workflows: Classroom streaming assistants; interactive lab notebooks with temporal traces.
- Assumptions/dependencies: Reliable capture; domain-specific prompts; alignment with curricula; accessibility features.
- Energy infrastructure monitoring (Energy, Utilities)
- Description: Long-duration turbine/pipeline/transformer monitoring with event grounding (overheating, abnormal vibrations) and time-sensitive QA for maintenance windows.
- Tools/workflows: Condition-based maintenance pipelines; integrated CMMS; escalation flows.
- Assumptions/dependencies: Long-context handling (sliding-window attention, KV-cache management); edge compute; domain-specific models.
- Financial branch operations analytics (Finance)
- Description: Temporal grounding of queue events, time-sensitive QA for service-level compliance; fraud-related event detection in branches.
- Tools/workflows: SLA dashboards; audit-ready timelines; compliance engines.
- Assumptions/dependencies: Privacy and consent; regulator-approved pipelines; robust de-identification.
- Multi-camera, multi-agent coordination (Security, Warehousing)
- Description: Streamo extended to fuse multiple concurrent feeds and reason across agents/events over long horizons.
- Tools/workflows: Camera fusion layer; cross-stream temporal grounding; orchestration of alerts.
- Assumptions/dependencies: Research on multi-stream attention; synchronization; compute scaling.
- Edge-optimized, high-frame-rate deployment (Software/Systems)
- Description: 15–30+ fps streaming with unbounded context via KV-cache management, visual token pruning, sliding-window attention, adaptive frame compression.
- Tools/workflows: Hardware-aware inference (Jetson, FPGA); model distillation/pruning; dynamic frame sampling.
- Assumptions/dependencies: Engineering trade-offs (accuracy vs latency); power budgets; robust benchmarking.
- Privacy-preserving streaming analytics (Policy, Trust & Safety)
- Description: Federated/secure processing with on-device anonymization, selective redaction triggered by “Response” states; policy-compliant logging with temporal evidence.
- Tools/workflows: Privacy-by-design pipelines; DPIA templates; regulator-facing transparency reports.
- Assumptions/dependencies: Differential privacy/redaction modules; legal review; stakeholder buy-in.
- Creator tools for interactive live streams (Media/Creator economy)
- Description: Real-time “co-host” that narrates, answers chat-driven time-sensitive questions, and grounds events for instant clips.
- Tools/workflows: Streaming platform integrations; automated clip generation; sponsor-compliant messaging.
- Assumptions/dependencies: Latency SLAs; moderation safety nets; audience-driven prompting.
- Scientific video analysis at scale (Academia, R&D)
- Description: Long-duration experiments (biology, materials) with temporal grounding and time-sensitive QA; unified multi-task annotations for discovery.
- Tools/workflows: Lab data lakes with Streamo indexing; search over temporal events; reproducibility audits.
- Assumptions/dependencies: Domain adaptation; standardized metadata; high storage throughput.
Cross-cutting assumptions and dependencies
Across applications, feasibility depends on:
- Compute and latency: Current models trained at 1 fps generalize to 2 fps; higher rates need optimization (KV-cache management, token pruning, sliding-window attention, adaptive frame compression).
- Context length: Unbounded streams require memory and attention optimizations; long-horizon reasoning is a research dependency.
- Data quality and domain adaptation: Prompts and fine-tuning must reflect specific domains (e.g., sports vs healthcare).
- Safety, privacy, and compliance: Real-time analytics often implicate regulatory regimes (HIPAA, GDPR); require de-identification, consent, audit trails.
- Reliability thresholds: For high-stakes decisions, human-in-the-loop verification and robust calibration are necessary.
- Integration: Productization needs APIs/SDKs, camera ingestion, storage, dashboards, and MLOps observability.
These applications leverage Streamo’s end-to-end response-state modeling, multi-turn streaming dialog format, and instruction-tuned multi-task capabilities to move video AI from offline analysis to real-time, interactive assistance.
Glossary
- Action Caption: A task that generates concise, step-level descriptions of discrete actions with clear temporal delineation. "Action Caption"
- adaptive frame compression: A technique to reduce the representation size of incoming frames to handle long sequences efficiently. "exploring sliding-window attention and adaptive frame compression for refined context management."
- alpha weights: Class-dependent weights used to rebalance losses based on the frequency of special tokens. "we introduce frequency-based alpha weights."
- Backward Tracing: An evaluation mode that assesses the ability to trace and reason about past events in a video stream. "Backward Tracing"
- class imbalance: A skewed distribution of labels that biases training, often causing the model to favor the majority class. "The multi-turn streaming format introduces severe class imbalance among the three response states."
- connector: The module linking the vision encoder to the LLM for multimodal integration. "only the connector and the LLM will be updated."
- cross-entropy loss: A standard objective measuring the divergence between predicted probabilities and the true labels. "The two weighting mechanisms are computed independently and multiplied into the cross-entropy loss."
- decision head: A specialized output layer that predicts discrete response states (e.g., Silence, Standby, Response). "three decision heads---Silence, Standby, and Response---"
- end-to-end training: Jointly optimizing the entire system so decision-making and generation are learned together. "enabling end-to-end parallel training."
- Event Caption: A task that requires detecting event boundaries and producing a caption when an event ends. "Event Caption"
- Event Grounding: Localizing a described event within its temporal span in the video stream. "Event Grounding"
- focal loss: A loss function that down-weights easy examples to focus learning on hard, under-represented cases. "our focal loss for training the three decision states"
- focal weighting: A per-sample weighting scheme emphasizing hard predictions to mitigate imbalance. "we apply focal weighting specifically to the three special state tokens."
- focusing parameter: The gamma parameter in focal loss that controls how strongly easy examples are down-weighted. "γ ≥ 0 is the focusing parameter that controls the rate at which easy examples are down-weighted."
- Forward Active Responding: An evaluation mode testing proactive, timely responses during ongoing streams. "Forward Active Responding"
- frame-level decision-making: Making fine-grained output decisions at the granularity of individual frames. "This design empowers the model with frame-level decision-making capabilities while maintaining the next-token prediction framework."
- fps (frames per second): The rate at which frames are sampled or processed in training/evaluation. "the model trained at 1 fps can be directly evaluated at 2 fps without retraining"
- inference latency: The time delay incurred by the model to produce an output during prediction. "increase computational cost and inference latency."
- KV-cache: Cached key-value tensors used in attention to accelerate sequential inference. "KV-cache management"
- logit: The pre-softmax score output for a class/token used to compute probabilities. "where is the logit for token at position "
- LongVideoBench: A benchmark for evaluating understanding in long-form videos. "LongVideoBench"
- mIoU: Mean Intersection over Union, a metric for evaluating temporal grounding/localization accuracy. "results are using the mIoU metric."
- multi-task supervision: Training with signals from multiple tasks to encourage generalization across capabilities. "multi-task supervision"
- multi-turn dialogue: A structured sequence of interleaved video segments and responses simulating streaming interactions. "we reformulate the single-turn offline format into a multi-turn dialogue structure."
- negative log-likelihood: The objective that penalizes the log probability of the true token; equivalent to cross-entropy for categorical targets. "This computes the negative log-likelihood of the true token."
- next-token prediction: An autoregressive modeling framework that predicts the subsequent token in a sequence. "while maintaining the next-token prediction framework."
- one-pass inference: Generating outputs in a single forward pass without separate controller stages or revisiting past frames. "achieving one-pass inference"
- OVO-Bench: A streaming video benchmark covering multiple tasks and temporal perception modes. "OVO-Bench"
- response-state token: A special token inserted into the sequence to mark Silence, Standby, or Response decisions. "directly integrates a response-state token into the data sequence"
- Silence: A decision/state token indicating the model should not respond yet. "\textless Silence\textgreater tokens dominate the distribution"
- sliding-window attention: An attention mechanism constrained to a moving window for scalable long-sequence processing. "sliding-window attention"
- Standby: A decision/state token indicating relevant input is detected but the model should wait for complete information. "three decision heads---Silence, Standby, and Response---"
- Streamo-Bench: A benchmark designed to evaluate instruction-following across diverse streaming tasks. "Streamo-Bench"
- streaming benchmarks: Evaluation suites focused on continuous, real-time video tasks. "across a variety of streaming benchmarks."
- streaming video LLM: A LLM capable of processing and responding to live video streams in real time. "a real-time streaming video LLM"
- temporal boundaries: Start and end times that demarcate segments or events in a video. "explicitly annotated with temporal boundaries"
- temporal event grounding: Detecting and localizing events over time within a continuous stream. "temporal event grounding"
- temporal grounding: Associating textual descriptions with their corresponding time spans in video. "temporal grounding, and time-sensitive question answering."
- temporal reasoning: Understanding and reasoning over time-dependent patterns or sequences in video. "strong temporal reasoning"
- time-sensitive QA: Question answering where correct answers change as the video progresses. "Time-sensitive QA"
- visual token pruning: Removing less informative visual tokens to reduce computation while preserving critical context. "visual token pruning"
- vision encoder: The component that extracts visual features from frames before passing them to the LLM. "with the vision encoder frozen"
- vocabulary size: The number of distinct tokens the model can represent and predict. "and is the vocabulary size."
- win rate: A comparative metric indicating how often a model’s output is preferred over baselines. "Caption evaluation is conducted by calculating the win rate with Qwen2.5-VL-72B model."
Collections
Sign up for free to add this paper to one or more collections.