- The paper presents PALM, a novel algorithm that builds a fixed portfolio of LLM policies to cover the user preference space efficiently.
- It derives theoretical guarantees on portfolio size and approximation errors that do not scale with the number of users but with reward dimensions.
- Empirical results across different tasks show PALM’s superior coverage and less than 1.5% suboptimality compared to uniform and random baselines.
Authoritative Essay on "Many Preferences, Few Policies: Towards Scalable LLM Personalization" (2604.04144)
Motivation and Problem Setting
LLM personalization has become a significant operational and research challenge, driven by the heterogeneity of user preferences for traits such as helpfulness, harmlessness, brevity, and factuality. The prevalent paradigm assigns each user a bespoke LLM, perfectly aligned with their preferences. However, this approach is cost-prohibitive in terms of compute, memory, and system complexity, and essentially scales linearly with the number of users—a trend already observable in industry through model retirement and deprecation practices. Conversely, serving all users from a single model curtails the system’s ability to capture the diversity required for comprehensive personalization.
The central insight of the paper is the recognition that the space of user preferences (modeled as continuous weight vectors over reward functions) can be effectively approximated by a small portfolio of LLMs. Each LLM in this portfolio is optimized for a scalarized combination of rewards derived from a weight vector, and each such policy can serve not just its native vector but a region of the preference space, providing near-optimality for those users. Crucially, the portfolio size is determined by the dimensionality of the reward space, not the user population, allowing scalable personalization.
Multi-Objective Alignment Framework and Portfolio Construction
The authors model user preferences as weight vectors in the probability simplex. The scalarized objective for each policy π is given as:
Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)
where ri are reward functions and f(π) is a regularizer, typically KL divergence relative to a reference policy.
They introduce a formal definition of (ε,δ)-approximate portfolios: a policy π is (ε,δ)-approximate for weight w if Jw(π)≥(1−ε)optw−δ, and a portfolio P is Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)0-approximate if for every Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)1, there exists Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)2 that satisfies this guarantee.
The portfolio construction algorithm, PALM (Portfolio of Aligned LLMs), combines additive and multiplicative grid strategies in weight space. Purely random or uniform grids suffer from poor coverage and redundancy, particularly near simplex boundaries. PALM adaptively builds weight vectors via combined grids, leveraging the geometric structure of the simplex.
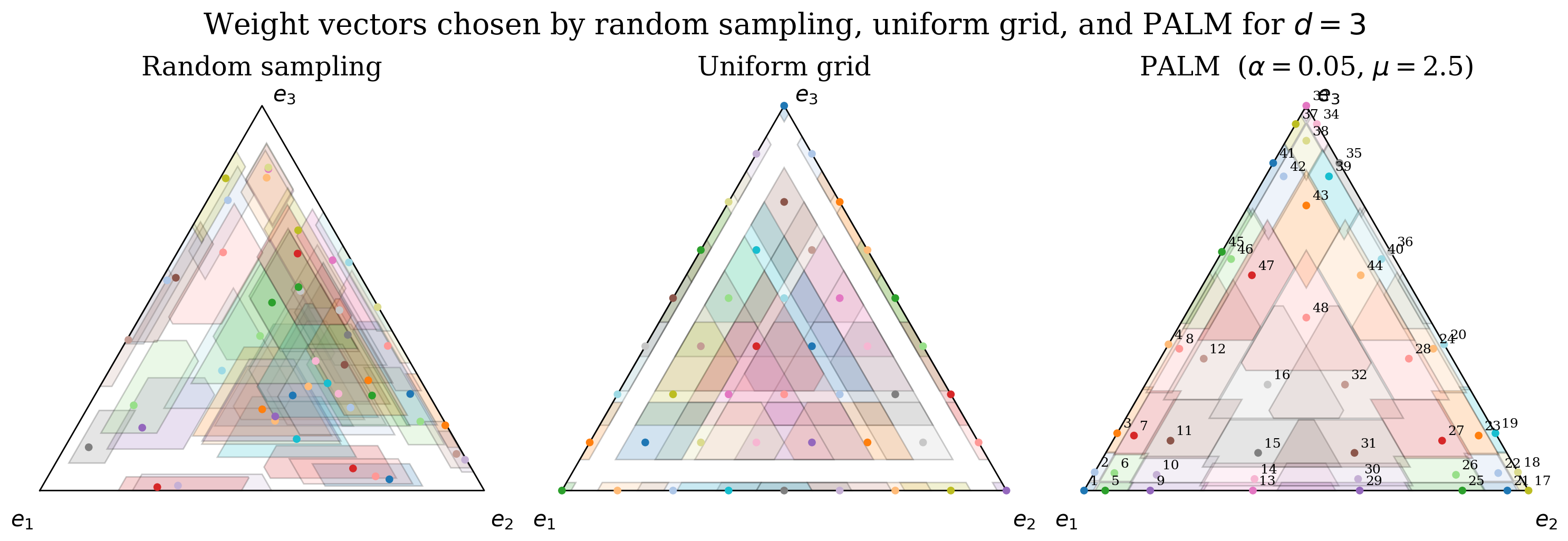
Figure 1: Comparison of weight selection methods; PALM achieves complete coverage of preference space, avoiding holes found in random and uniform methods.
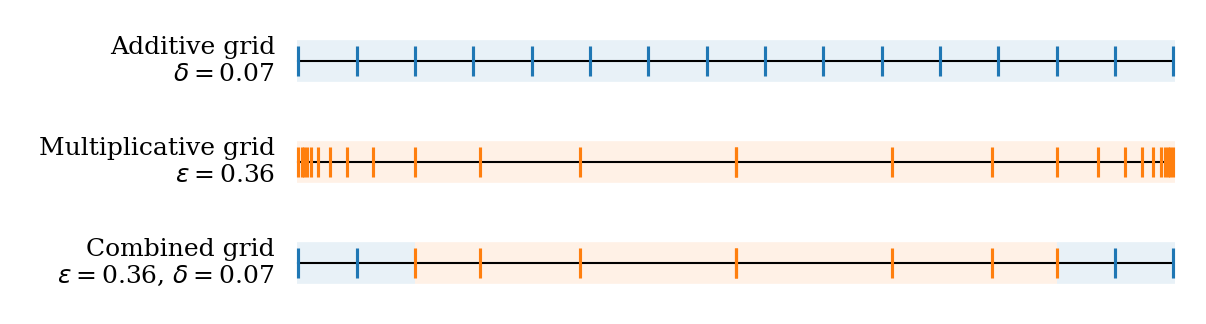
Figure 2: Illustration of multiplicative, additive, and combined grids in Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)3 dimensions, highlighting the coverage benefits of PALM's hybrid approach.
The algorithm iterates through each reward dimension, constructs structured grids in the remaining coordinates, normalizes these to the simplex, and then prunes redundant policies via a covering procedure.
Theoretical Guarantees and Algorithmic Trade-offs
PALM is proven to output a portfolio whose size is at most Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)4, where Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)5 and Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)6 are grid parameters controlling multiplicative and additive tolerances, respectively. The approximation quality is bounded by Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)7 and Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)8, ensuring both coverage and efficiency.
Key theoretical claims:
- The portfolio size does not scale with the number of users, only with the number of reward dimensions and approximation parameters.
- Tighter approximation ratios require a larger portfolio, but the system cost remains independent of user population.
Empirical Validation and Numerical Results
Empirical evaluation covers RLVR-GSM (brevity/helpfulness, Jw(π)=i=1∑dwiEx∼P,y∼π(x)[ri(x,y)]−f(π)9), safety alignment (helpfulness, harmlessness, ri0), and Helpful Assistants (helpfulness, harmlessness, humor, ri1).
- Across all tasks, PALM consistently outperforms uniform and random baselines in both approximation gap (multiplicative and additive) and policy coverage.
- With fewer than seven policies, PALM achieves less than 1.5% suboptimality in normalized reward space.
Policy usage distribution analysis reveals that PALM portfolios exhibit higher perplexity—i.e., more balanced assignment of users to policies—compared to baselines, reducing redundancy and maximizing behavioral diversity.
Figure 1: PALM's weight selection covers the entire preference space, unlike random or uniform sampling.
Figure 2: Combined grid strategy enables PALM to maintain multiplicative guarantees near the simplex boundary.
Qualitatively, PALM-generated portfolios yield distinct outputs for similar prompts, whereas uniformly spaced weights often produce nearly identical or degenerate outputs, underscoring the limitations of naive grid approaches.
Practical and Theoretical Implications
These results establish PALM as a practical solution that reframes personalization as coverage of behavioral regimes rather than individual user fine-tuning. The approach facilitates:
- Scalable deployment: Fixed-size portfolios can serve large user populations without increased system complexity.
- Auditability and efficiency: Reduced operational overhead, simplified governance, and easier safety monitoring.
- Robust personalization: Coverage guarantees across all possible user preferences in the reward simplex.
Theoretical implications include new insights into multi-objective RL for generative models, explicit trade-off characterization between fidelity and scalability, and evidence that portfolio selection methods can be generalized to settings with arbitrary regularization terms.
Speculation and Outlook
Future research directions may include:
- Extension to non-linear scalarization and richer reward landscapes.
- Application to broader classes of foundation models and multimodal tasks.
- Integration with interactive or inference-time steerability methods for hybrid approaches.
- Investigation into automated discovery of behavioral regimes beyond reward-defined axes.
Conclusion
This work advances the theory and practice of LLM personalization by demonstrating that a small, theoretically justified portfolio of aligned policies can efficiently approximate the landscape of user preferences. PALM provides uniform coverage guarantees and achieves superior empirical results compared to commonly used baselines, offering a practical path toward scalable, diverse, and auditable LLM personalization (2604.04144).

