- The paper introduces the Multi-Objective Control (MOC) paradigm, enabling a single LLM to optimize multiple user-defined objectives while achieving Pareto-optimal trade-offs.
- MOC employs surrogate gradients and a min-norm Frank-Wolfe solver to efficiently balance reward maximization with controllability, outperforming traditional RLHF and ensemble methods.
- Empirical results demonstrate that MOC ensures superior controllability, diversity, and scalability across varying LLM backbones and complex multi-objective settings.
Multi-Objective Controllable LLMs: A Unified Framework for Preference-Driven LLM Alignment
Introduction
The alignment of LLMs with multifaceted, user-specific preferences presents a significant challenge for scalable deployment. Traditional reinforcement learning from human feedback (RLHF) collapses human values into single-objective reward models, inhibiting personalized adaptation across the rich space of user preferences. "One Model for All: Multi-Objective Controllable LLMs" (2604.04497) introduces the Multi-Objective Control (MOC) paradigm—a policy optimization framework that enables a single LLM to achieve explicit, user-driven trade-offs across multiple objectives via preference vectors. Critically, MOC achieves this without the need to train multiple reward-specialized models or ensembles, and maintains efficiency comparable to single-objective RLHF.
Let p∈ΔN−1 denote a user-specified vector of preference weights across N objectives (e.g., helpfulness, harmlessness, humor). MOC operationalizes controllability as aligning the LLM’s achieved reward distribution, R(x,y), with p via mean squared error (MSE) constraints, while simultaneously maximizing reward. The core optimization targets a Pareto-optimal set of policies parameterized by p, with the preference vector prepended to the prompt for conditioning.
Whereas prior approaches such as MORLHF, Rewarded Soups, and RiC either scalarize objectives, require model ensembling, or rely on SFT without explicit policy improvement, MOC formulates bi-objective optimization:
- Maximizing p⊤J(π(⋅;θ,p)), the preference-weighted expected rewards.
- Minimizing constraint violation via a hinge penalty on the MSE between predicted rewards and preference vectors.
To ensure tractability for billion-scale LLMs, MOC employs surrogate gradients and a min-norm Frank-Wolfe solver over closed-form quadratic problems, thus avoiding the computational bottleneck of naive MOO in high dimensions.
Empirical Results
Illustrative Control on the Fishwood Environment
On the Fishwood multi-objective gym environment, MOC not only generates policies that align with diverse preference vectors but also ensures these solutions lie on the true Pareto front, in contrast to linear scalarization-based PPO which fails to consistently capture fine-grained trade-offs.
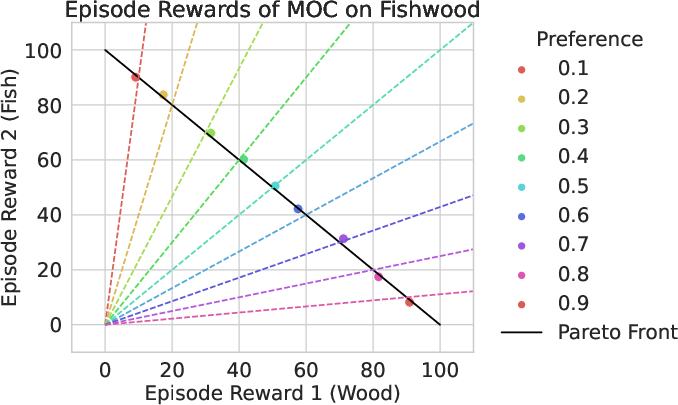
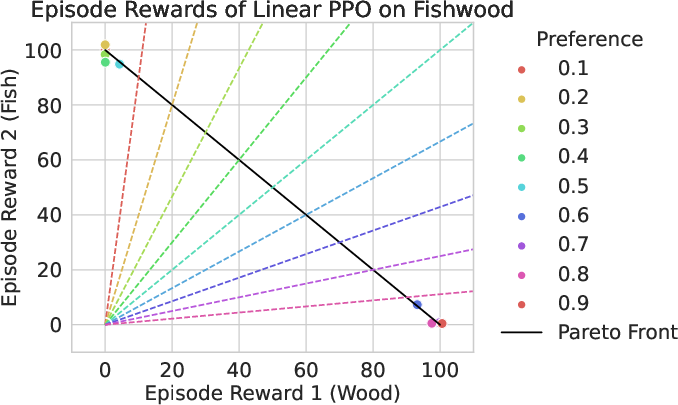
Figure 1: Solutions of MOC (left) versus Linear PPO (right) on the Fishwood environment, demonstrating that MOC traces the Pareto front and respects input preference vectors, while Linear PPO exhibits preference misalignment and dominated solutions.
Controllability and Preference Alignment in LLMs
On RLHF-aligned tasks (e.g., balancing humor and helpfulness, or harmlessness and helpfulness), MOC demonstrates superior monotonic control: its outputs respond faithfully to monotonic permutations of the input preference vector, with Kendall’s tau of $1.0$, outperforming RiC (avg. τ=0.85) and ensemble-based baselines.
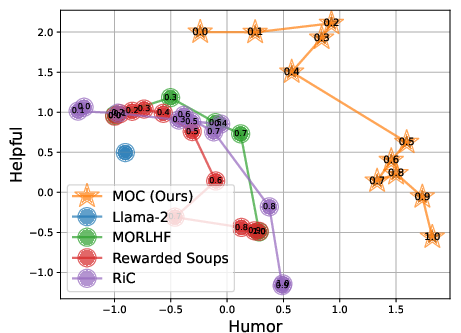
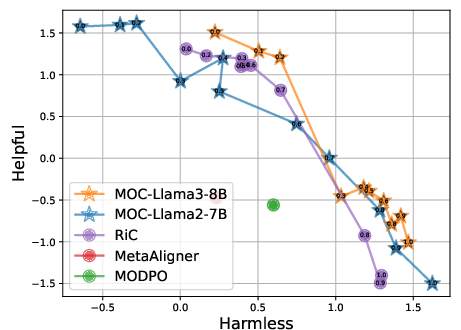
Figure 2: MOC achieves consistent, ordered preference-aware trade-offs, dominating the Pareto front and maintaining controllability; baseline methods yield lower solution quality and inconsistent alignment.
Solution Quality and Diversity
The hyper-volume metric and mean pairwise distance (MPD) substantiate the practical superiority of MOC—illustrating both improved convergence to the Pareto front and increased behavioral diversity. For example, MOC achieves a hyper-volume of $14.176$ in the Humor-Helpful setting (vs $6.692$ for RiC), and MPD of N0 (vs N1 for RiC).
Generalization to Unseen Preferences
By sampling preference vectors from the simplex excluded during training, MOC demonstrates that the learned policy manifold smoothly interpolates over the entire Pareto front. Generalization to such “unseen” trade-offs does not result in reward collapse or preference misalignment.
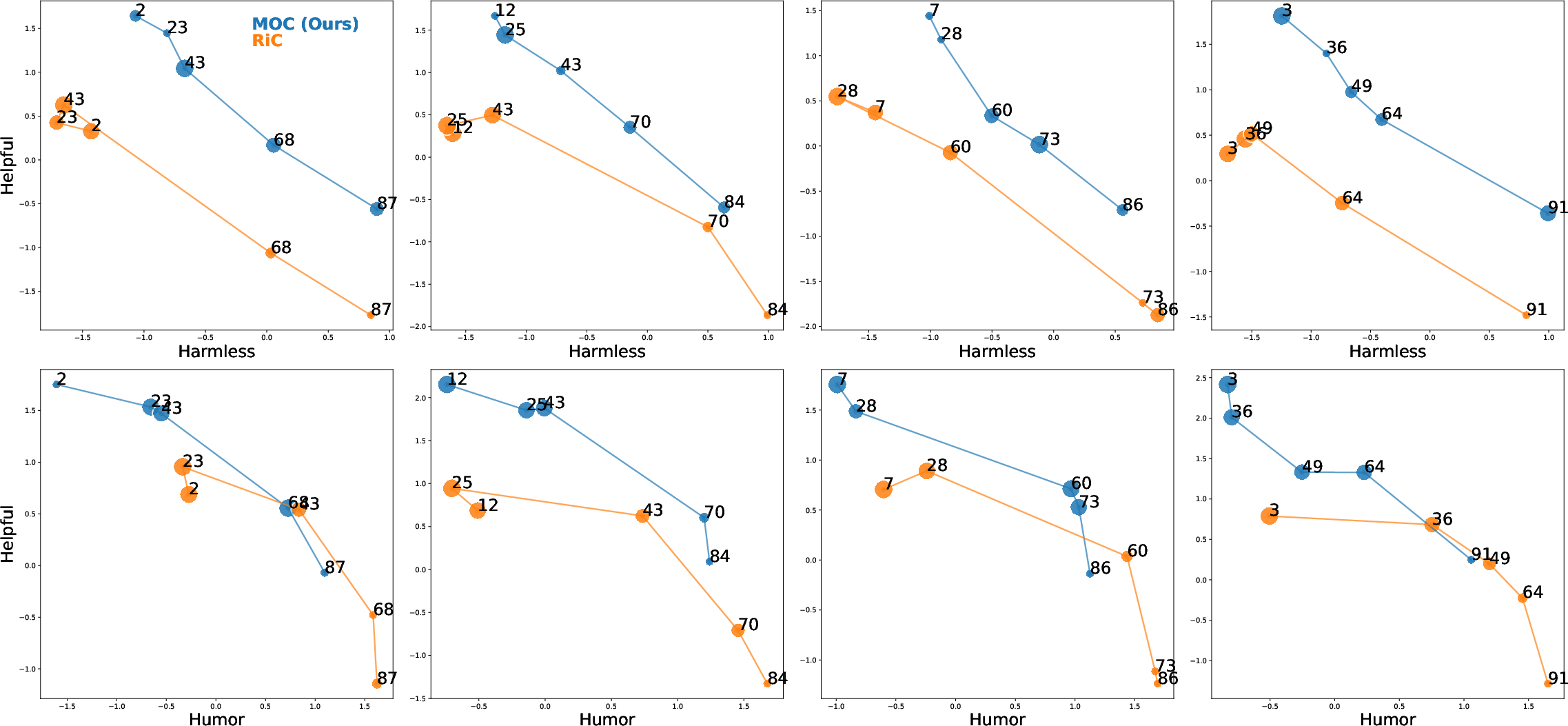
Figure 3: MOC generalizes to four groups of unseen preference vectors (columns), consistently outperforming RiC, accurately tracing the intended reward regions and accommodating diverse, continuous preferences.
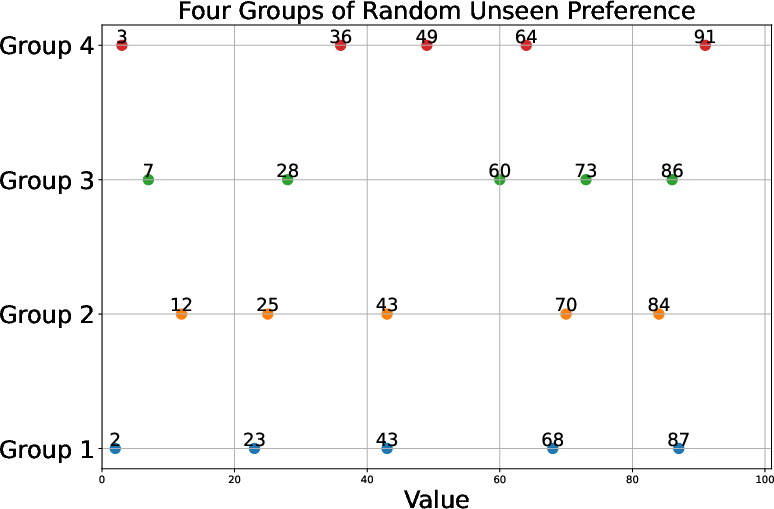
Figure 4: Sampled unseen preference vectors reveal the wide spectrum of test-time controllability required for robust multi-objective LLM control.
Scaling to Larger Models and Objectives
Experiments demonstrate that MOC, when applied to Llama3-8B or Qwen2.5 backbones, continues to dominate both in controllability and hyper-volume, with graceful scaling. In three-objective cases (Harmlessness, Helpfulness, Humor), MOC achieves nearly N2 higher hyper-volume versus the best baseline, confirming robustness beyond the two-objective setting.
Figure 5: MOC with Llama3-8B maintains strong Pareto and controllability performance, outperforming all baselines on RLHF benchmarks.
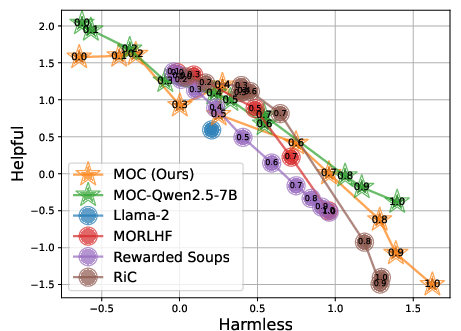
Figure 6: Generalization to alternative LLM backbones such as Qwen2.5 demonstrates architectural agnosticism of the MOC approach.
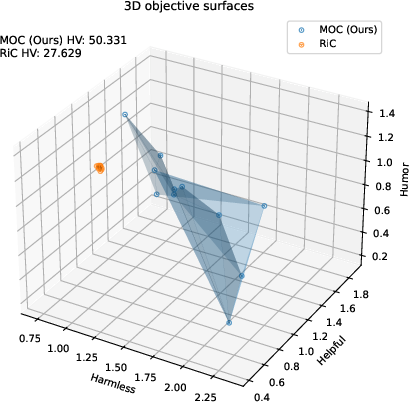
Figure 7: In three-objective optimization, MOC covers the full 3D Pareto surface, while baseline solutions cluster suboptimally.
Additional Datasets and Scalability
Further evaluations on the Reddit Summary task (Summary/Faithful reward models) and six-objective Fruit-Tree tasks validate that MOC is robust to increases in both objective dimension and reward heterogeneity, achieving superior hyper-volumes and maintaining diverse trade-offs.
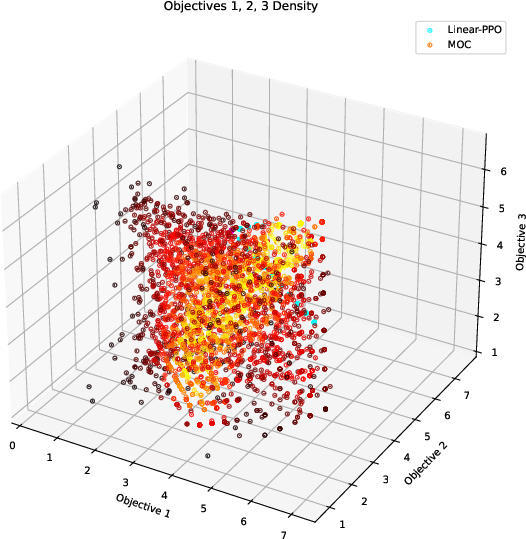
Figure 8: In the six-objective Fruit-Tree task, MOC solution distributions dominate baselines, evidencing effective high-dimensional multi-objective control.
Ablation: Necessity of Bi-Objective Optimization
Ablations confirm the necessity of simultaneously optimizing for both solution quality and explicit controllability. Dropping the controllability constraint significantly impairs preference alignment (Kendall’s tau drops by N30.4); omitting multi-objective optimization reduces Pareto coverage.
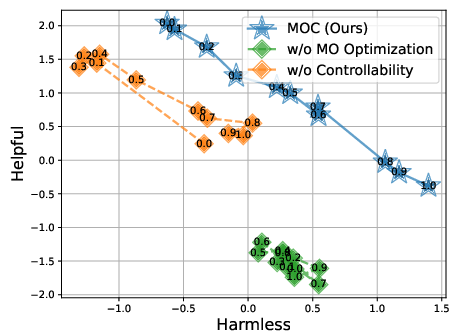
Figure 9: Removing either objective from the MOC loss degrades either controllability (preference alignment) or solution set quality.
Theoretical and Practical Implications
The MOC framework formulates the first efficient, explicit multi-objective policy-optimization approach for LLMs that:
- Achieves continuous, monotonic controllability of model outputs through a single, once-trained parameterization.
- Avoids the computational impracticality of model ensembling, explicit multi-objective reward conditioning via large discrete tables, or reliance on scalarization which collapses objectives and restricts Pareto exploration.
- Demonstrates robust interpolation across the preference simplex, confirming the learnability of continuous preference-conditioned policy manifolds.
- Maintains computational efficiency on par with standard RLHF, leveraging surrogate bi-objective optimization and convex quadratic solvers.
- Is compatible with high-capacity, modern LLM backbones and is broadly applicable across disparate alignment tasks.
Future Directions
The precise, numeric preference vector interface underlying MOC provides a natural control layer atop which intuitive, user-facing interfaces (e.g., natural language instruction-to-vector translation) can be built, allowing non-expert users to specify high-level alignment intent interpretable by the model. This opens paths for fully personalized and contextually adaptive LLM-based systems, where fine-grained, multi-dimensional alignment is achieved through modular translation from natural user queries.
Conclusion
MOC delivers strong empirical results and possesses a theoretically grounded methodology for preference-driven, multi-objective LLM alignment. It enables continuous, monotonic, and data-efficient control over model behavior across user-defined reward manifolds, setting a robust baseline for future research in personalized, preference-controllable language generation and safety-aligned AI systems.