- The paper demonstrates that chain-of-thought compression can significantly reduce token count while introducing regressions in trustworthiness dimensions like safety.
- It employs a robust evaluation framework comparing compressed models with their uncompressed counterparts across methods including RL-based distillation and DPO-based alignment-aware compression.
- The study highlights trade-offs where gains in multilingual performance and hallucination resistance often coincide with safety declines, underscoring the need for careful alignment during compression.
Empirical Analysis of Chain-of-Thought Compression and Trustworthiness in LLM Reasoning
Introduction
The paper "Shorter, but Still Trustworthy? An Empirical Study of Chain-of-Thought Compression" (2604.04120) investigates the effects of compressing long chain-of-thought (CoT) reasoning traces in LLMs on key trustworthiness dimensions: safety, hallucination resistance, and multilingual robustness. Existing evaluations of CoT compression largely prioritize task accuracy and computational savings, leaving unexplored whether trustworthiness properties—acquired or reinforced during alignment and post-training—are preserved, degraded, or differentially impacted by compression. This work systematically characterizes these effects through a battery of controlled experiments across model scales, families, and compression paradigms.
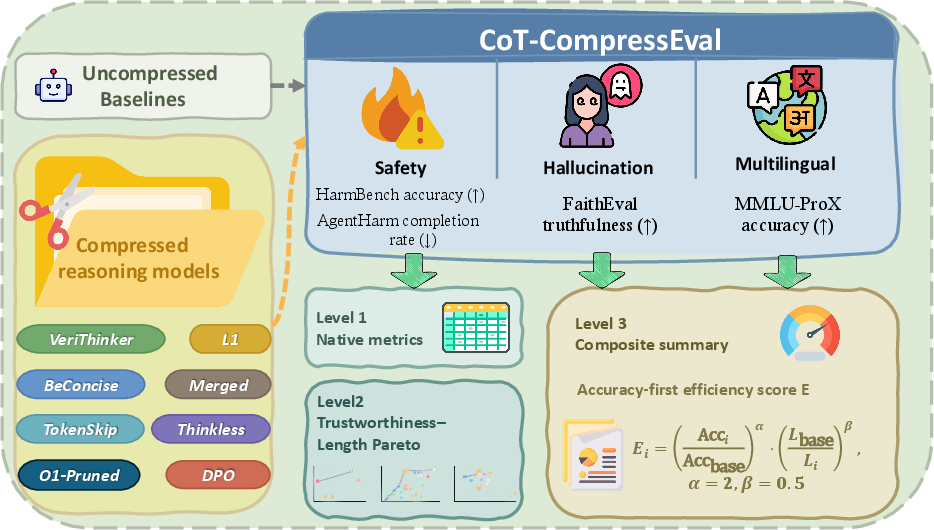
Figure 1: Overview of the evaluation framework. Each compressed model is compared against its matched uncompressed baseline under a uniform protocol across three trustworthiness dimensions.
Methodology and Experimental Protocol
The evaluation is structured around direct within-family comparisons: each compressed model is paired with its uncompressed baseline and assessed using identical prompt formats, decoding configurations, and trustworthiness metrics. The benchmarks cover distinct failure axes:
- Safety: Assessed via refusal accuracy on HarmBench and harmful task completion rates on AgentHarm.
- Hallucination Resistance: Measured through truthfulness rates on the unanswerable subset of FaithEval.
- Multilingual Robustness: Evaluated using accuracy on MMLU-ProX, spanning 29 languages.
Compression paradigms assessed include RL-based distillation (L1), training-free prompt engineering (BeConcise), RL-based depth control (Thinkless), training-free token manipulation (TokenSkip), verification-augmented distillation (VeriThinker), model merging, large-scale pruning, and a new alignment-aware DPO variant.
A normalized per-dimension efficiency score (E) is defined to facilitate fair cross-family synthesis, penalizing accuracy degradation quadratically and discounting length savings due to diminishing interpretability returns. This metric enables multidimensional Pareto analysis.
Major Findings
Trustworthiness Degradation Under Compression
Across Qwen3-8B—the most extensively benchmarked family—CoT compression often introduces significant regressions in at least one trustworthiness dimension. For example, RL-based distillation (L1) achieves mean CoT token savings but reduces HarmBench safety by ∼10 percentage points, while simultaneously boosting MMLU-ProX accuracy by 1–2 points and slightly increasing hallucination resistance.
Pareto Trade-offs
The multidimensional trustworthiness–length Pareto analysis elucidates non-uniform trade-offs:
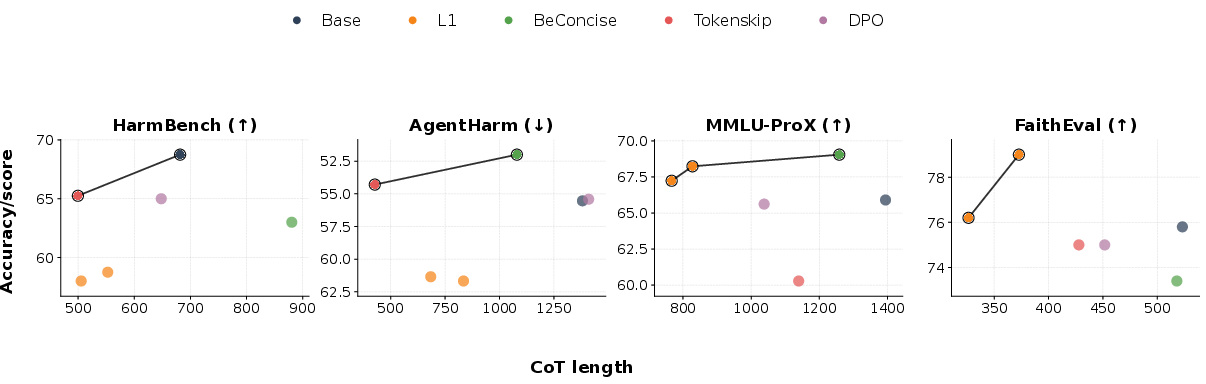
Figure 2: Trustworthiness--length Pareto frontiers for the Qwen3-8B family.
- L1 variants lie on the Pareto frontier for multilingual robustness and hallucination resistance, but are Pareto-dominated on safety.
- TokenSkip and BeConcise retain safety near baseline but degrade multilingual performance.
- No single compression method universally dominates; improvement in one trustworthiness axis is frequently offset by regression in another.
This confounds the use of naive scalar metrics for model selection, as such aggregation can obscure critical safety or robustness losses.
Normalized Efficiency Quantification
Per-dimension normalized efficiency scores E consistently reveal that standard compression techniques—most notably distillation and RL depth control—tend to produce E<1 in safety, despite achieving or surpassing break-even in other dimensions (e.g., EHB=0.81 for L1-Qwen3-8B-Exact; EMX=1.39). This effect is method- and model-dependent, with method-specific degradation profiles reproducibly identified across model families.
Alignment-Aware CoT Compression
As an existence proof, the paper introduces a DPO-based alignment-aware compression protocol. By incorporating concise-but-high-quality human feedback exemplars into the reward signal during training, DPO-optimized variants yield:
- An average 19.3% reduction in reasoning token count on rigorous math benchmarks.
- Safety, multilingual, and hallucination metrics within 1–3 percentage points of the uncompressed baseline—demonstrating that the trade-off between efficiency and trustworthiness is not fundamental but algorithm-contingent.
Pruning at larger model scales also sometimes leads to favorable trustworthiness and efficiency profiles (e.g., QwQ-32B O1-Pruned).
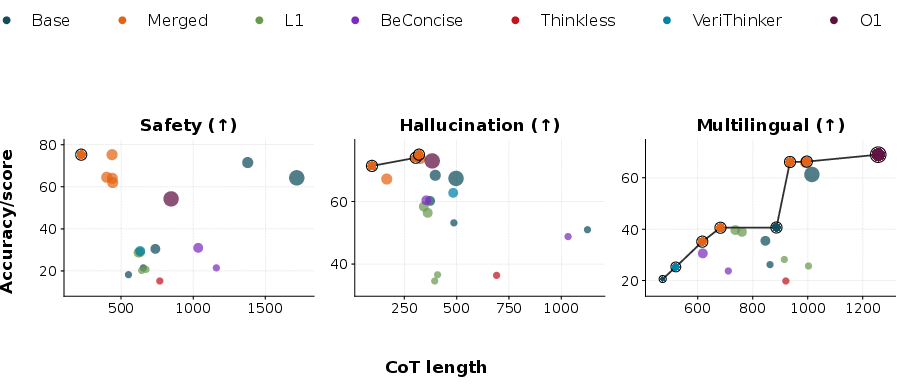
Figure 3: Trustworthiness--length Pareto frontiers across all model groups. Colors denote compression methods; marker size denotes model scale.
Recurring Degradation Patterns
Empirical analysis identifies robust and reproducible trends:
- Asymmetric Regression: Compression frequently alters trustworthiness axially, e.g., L1 distillation on Qwen3-8B results in safety decline with simultaneous improvement in multilingual and hallucination metrics.
- Method-Specific Profiles: The type and severity of trustworthiness regression depends strongly on compression paradigm—even with identical base architectures.
- Cross-Model Variability: The trustworthiness dimension most affected varies by base model size and training, highlighting the necessity for per-dimension, within-family evaluation.
Theoretical and Practical Implications
These findings have direct bearings on LLM deployment and research:
- Protocol Recommendation: Task accuracy and token cost metrics are insufficient proxies; model compression should always be co-evaluated on safety, hallucination, and multilingual robustness.
- Reporting Practice: Both absolute within-family deltas and per-dimension efficiency scores are required to transparently communicate practical and scientific impacts.
- Algorithmic Direction: Explicitly incorporating trustworthiness into compression objectives (as with DPO) facilitates the development of models that are efficient, robust, and safe.
- Mechanistic Speculation: The results suggest that compression perturbs internal representations relevant for alignment and safety (e.g., RLHF-internalized parameter directions); in some cases, truncation may remove critical deliberation buffers from reasoning traces.
Limitations and Future Directions
The study is constrained by the reproducibility of public model releases and the use of automated judgment for ground-truthing safety and hallucination. Extension to larger ensembles, more diverse models, and human-in-the-loop verification is necessary to fully generalize these findings.
Future work may investigate fine-grained mechanistic causes underlying trustworthiness regressions, design new compression paradigms with alignment guarantees, and explore adaptive multi-objective optimization for trade-off balancing.
Conclusion
This study provides systematic empirical evidence that CoT compression in LLMs often induces non-trivial, dimension-specific trustworthiness regressions even when task performance is unchanged. The results call for the re-conception of efficiency optimization in LLMs: preserving trustworthiness must be treated as a primary design constraint, not a peripheral consideration. Alignment-aware compression, as demonstrated by the DPO variants, establishes the feasibility of maintaining trustworthiness under length reduction. Henceforth, efficiency evaluations of CoT reasoning models must integrate robust, multidimensional trustworthiness assessment as standard protocol.