- The paper introduces TCO that leverages camera and depth priors as differentiable constraints to refine multiview 3D reconstruction.
- It decouples geometric consistency and prior adherence by optimizing only the shared decoder via LoRA adaptation, ensuring architecture-agnostic improvements.
- Empirical results demonstrate over 50% error reduction on benchmarks like ETH3D and DTU, outperforming retrained prior-aware methods.
Test-Time Constrained Optimization for 3D Reconstruction with Priors
Introduction
The paper "Learning 3D Reconstruction with Priors in Test Time" (2604.03878) presents a novel framework for leveraging auxiliary scene and camera priors to enhance multiview 3D reconstruction, without modifying or retraining the original Multi-View Transformer (MVT) architectures. The approach, termed Test-time Constrained Optimization (TCO), treats such priors (e.g., camera poses, depth maps, intrinsics) as differentiable constraints on the network predictions. During inference, the framework performs task-specific optimization of the pre-trained network parameters, guided by a self-supervised cross-view consistency objective and penalty terms corresponding to available priors.
This methodology addresses two fundamental challenges in 3D geometric vision: (1) effectively leveraging available priors at inference in a model-agnostic manner, and (2) maintaining architectural flexibility and avoiding costly retraining for every new prior type or network. The method is empirically validated on several 3D vision benchmarks, including ETH3D, DTU, 7-Scenes, NRGBD, and ScanNet, with quantitative and qualitative results that establish strong improvements over image-only MVTs as well as retrained prior-aware feed-forward methods.
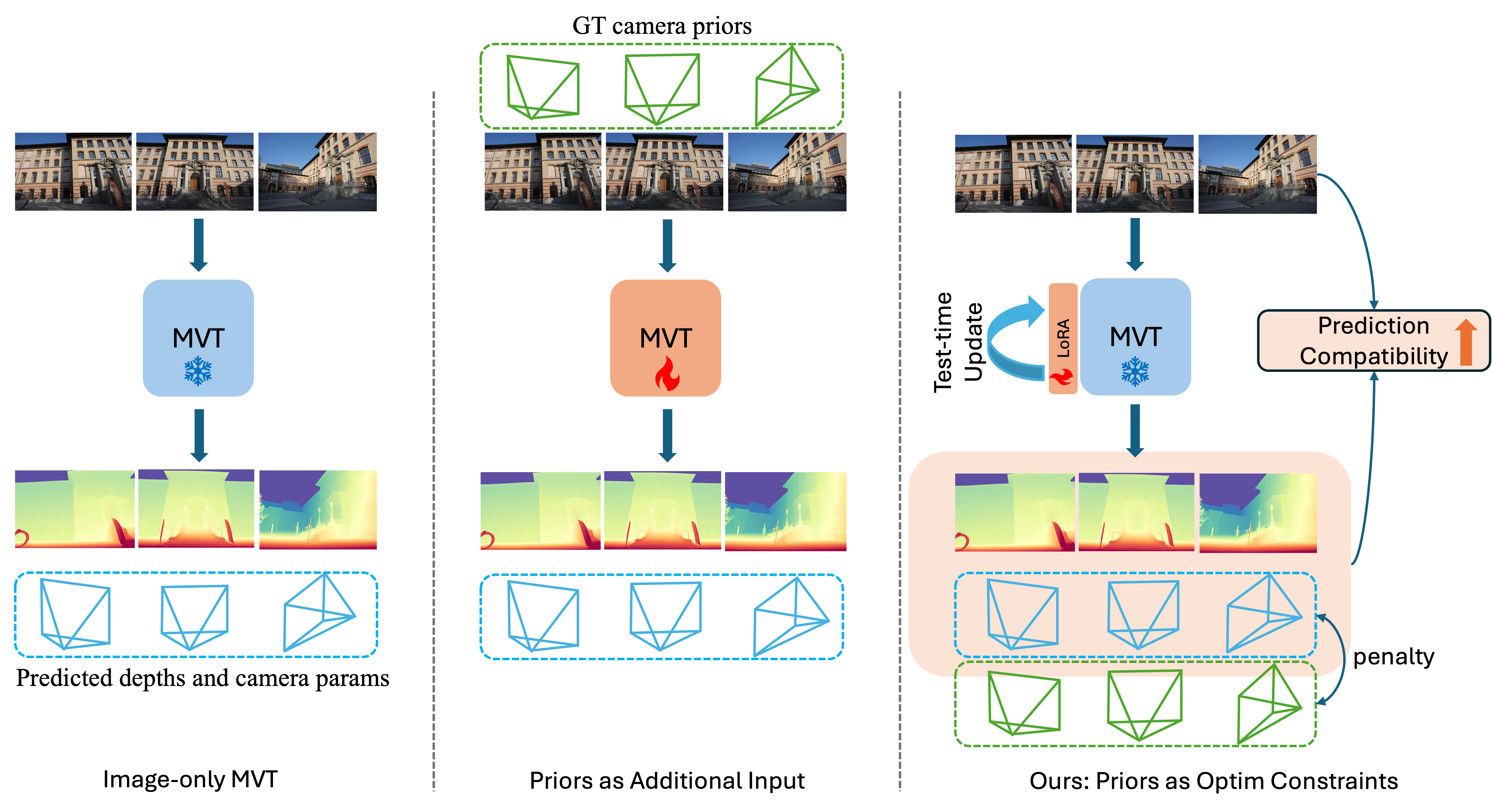
Figure 1: Overview of the TCO framework: standard MVTs output geometry solely from RGB; feed-forward prior-aware approaches retrain MVTs to take priors as input; TCO instead imposes priors as constraints only at test time with no architecture changes.
Methodology
The core of the TCO framework is the separation of cross-view geometric consistency and explicit prior adherence as two complementary aspects of inference-time network tuning. Given an MVT pre-trained only on RGB images, TCO operates as follows:
- Objective Function: A self-supervised prediction compatibility loss is constructed using differentiable rendering. The consistency among the predictions (e.g., depth, pose, intrinsics from different views) is enforced via a photometric or geometric loss between the renderings of the source and target views. The differentiable renderer 2D Gaussian Splatting (2DGS) produces projections from the predicted scene geometry to target images.
- Priors as Constraints: Available priors (e.g., externally or sensor-derived camera poses, intrinsics, depth maps) are formulated as penalty terms over the model’s outputs, e.g., angular, translation, and focal length discrepancies, or depth alignment loss with scale and shift adjustment.
- Optimization and Fine-Tuning: Only the shared decoder of the MVT is fine-tuned using LoRA adaptation, while all task-specific prediction heads and the encoder remain frozen, maximizing transfer across modalities. The composite loss includes the self-supervised compatibility objective and weighted prior constraints.
This plug-and-play inference scheme is extensible to arbitrary priors and MVT architectures, given only the appropriate loss terms, and can leverage any available auxiliary data at test time.
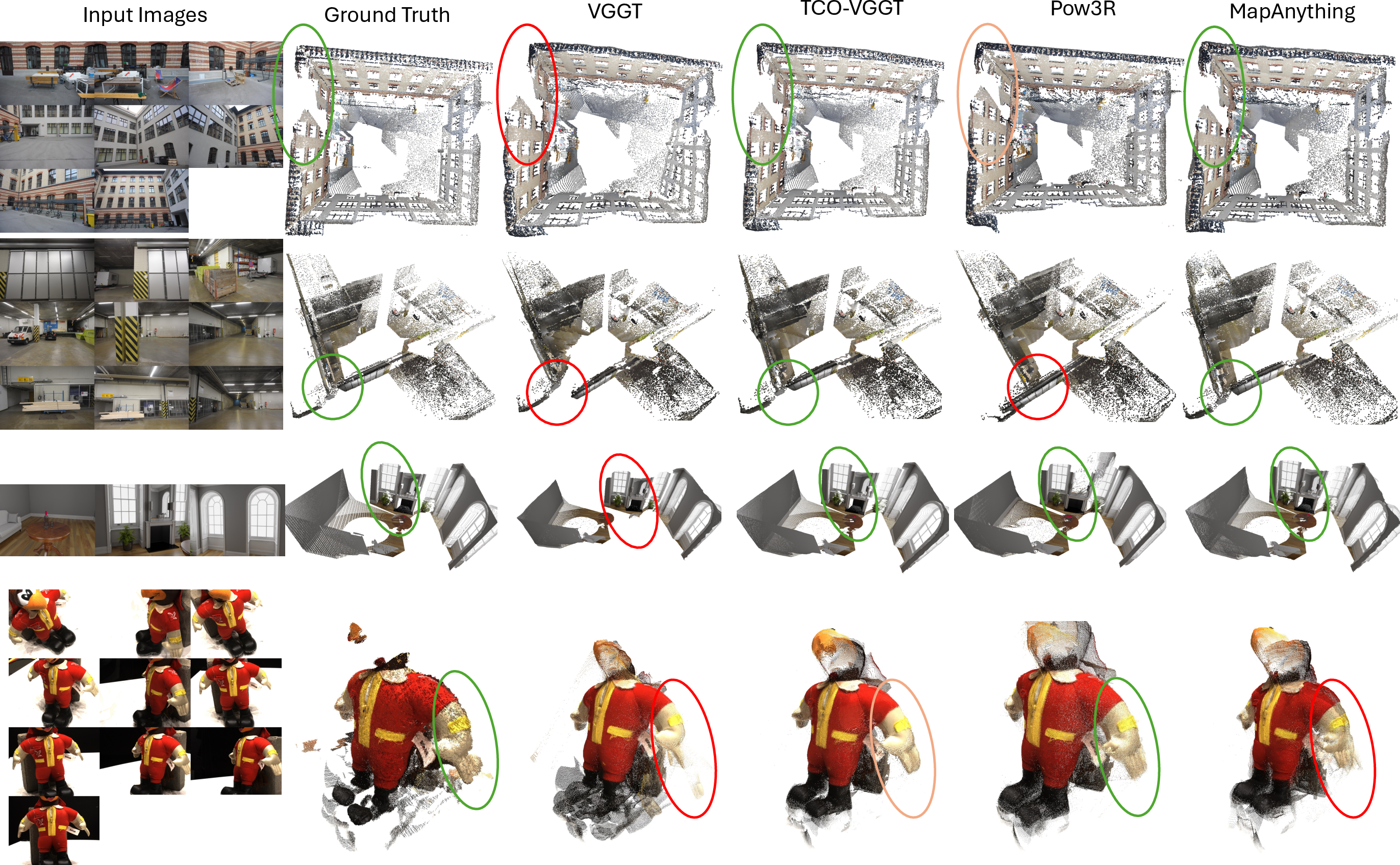
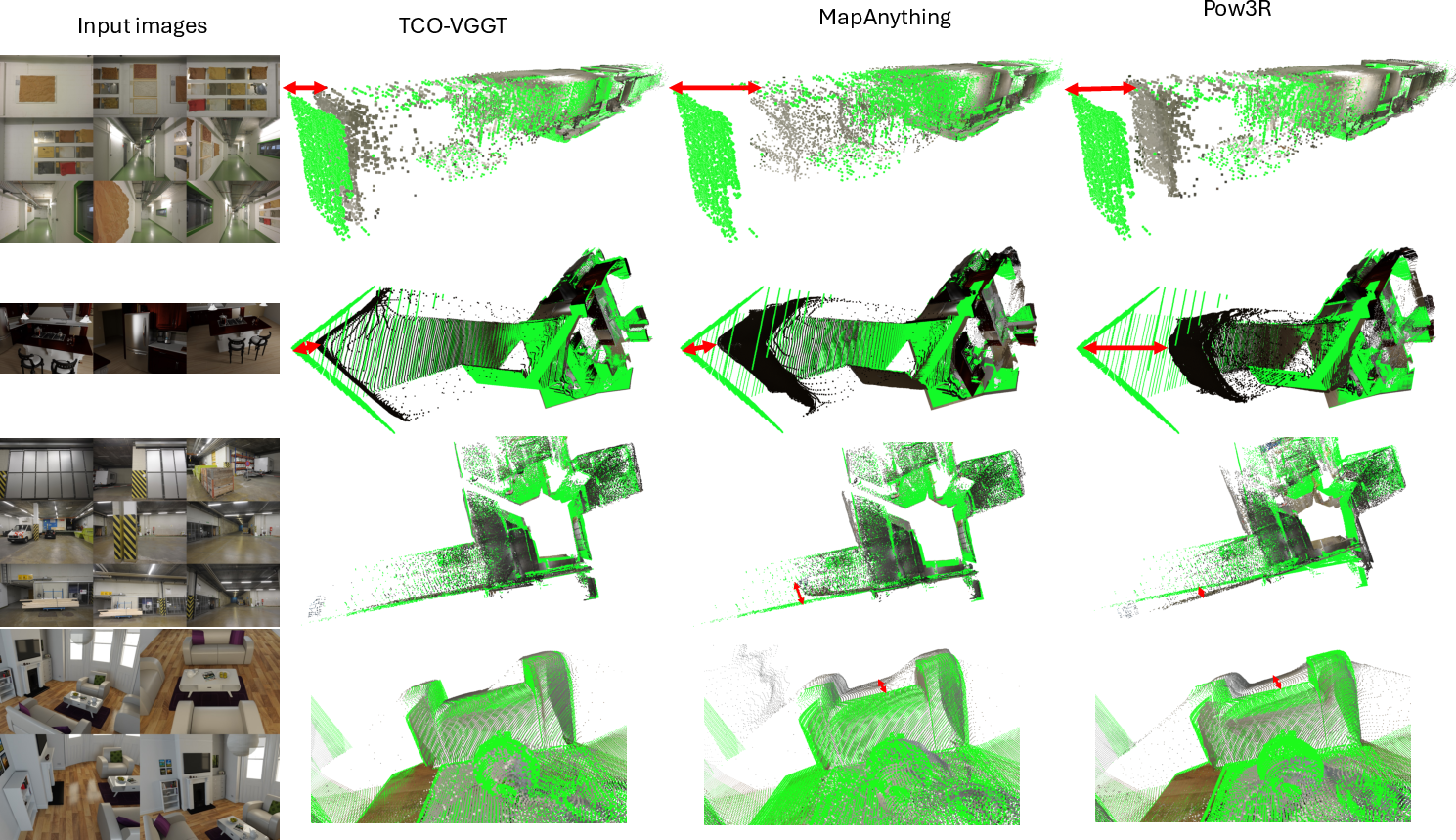
Figure 2: Qualitative comparison: TCO-VGGT (middle column) corrects architectural errors present in image-only reconstructions (left), outperforming both feed-forward prior-aware methods Pow3R and MapAnything (right).
Empirical Evaluation
Point Map Estimation
Comprehensive experiments on sparse-view and wide-baseline datasets (ETH3D, DTU, 7-Scenes, NRGBD) demonstrate that TCO with camera and/or intrinsics priors reduces reconstruction errors by over 50% relative to base models. In every evaluated setting, TCO not only surpasses feed-forward models with retrained prior input pipelines (e.g., Pow3R, MapAnything), but also yields architecture-agnostic gains when applied to different MVT backbones (VGGT, π3). Notably, TCO achieves:
Camera Pose Estimation
In camera pose estimation (ScanNet), where the prior is a set of depth maps, TCO optimizes the pose predictions by satisfying geometric constraints, consistently outperforming base and retrained prior-aware approaches across baseline separations. For example, with sparse keyframes, the Absolute Trajectory Error (ATE) is reduced from 0.0094 (VGGT) to 0.0072 (TCO-VGGT), illustrating effective cross-modality transfer under the TCO scheme.
Test-Time Optimization Analysis
The ablation studies confirm that only adapting the shared decoder (and not the prediction heads) is key to extracting the synergistic potential of prior constraints and self-supervised consistency. TCO remains robust to moderate prior noise, and the performance scales with the number of test-time optimization steps but plateaus beyond moderate iterations.
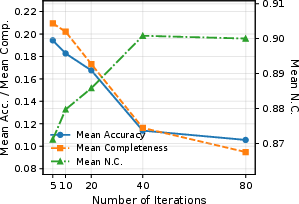
Figure 4: TCO performance scaling curve on ETH3D: test-time optimization yields rapid gains in early iterations, stabilizing as the number of steps increases.
Differentiable Rendering and Compatibility
Using 2DGS for the prediction compatibility objective is integral: the paper justifies heuristic parameter choices for opacity, radii, and parameterization, finding that rather than directly optimizing the renderer, constraining the MVT via predicted geometry leads to sharper improvements.
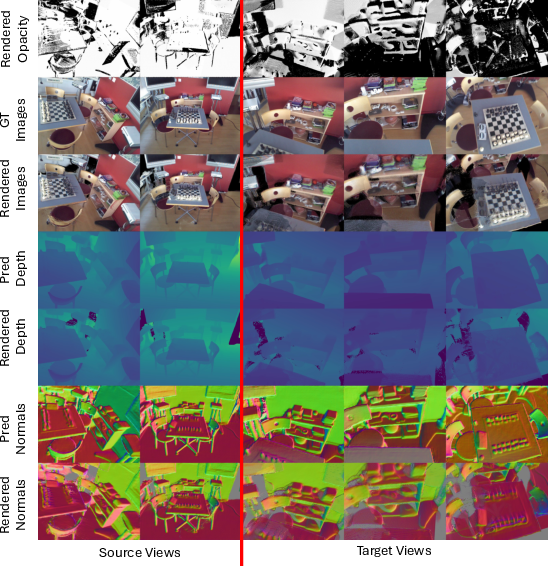
Figure 5: Visual results from 2DGS rendering pipeline, where heuristic parameterization (from MVT predictions) yields rendered images, depth, and normals closely matching ground-truth.
Implications and Future Directions
The TCO framework introduces a principled paradigm for test-time inference in vision models leveraging geometric priors. The practical advantages are clear: prior data can be exploited without costly retraining or architecture engineering. Theoretical implications further suggest that cross-modal self-supervised losses and plug-and-play constraints at test time are broadly applicable to other tasks, including SLAM, object pose estimation, or neural rendering, given the modular formulation.
Open challenges include reducing test-time computational overhead—current optimization incurs higher wall-clock inference time compared to pure feed-forward operation—and extending the scheme to broader prior types (e.g., semantics or partial geometry). The integration with reinforcement learning or energy-based methods for further test-time adaptation remains a promising direction.
Conclusion
Test-time Constrained Optimization provides an efficient, model-agnostic, and practical means of harnessing externally-available priors to boost the performance of pre-trained 3D MVTs at inference. By decoupling architecture design from the choice of priors and focusing on cross-view compatibility, TCO advances both the state-of-the-art on standard benchmarks and the theoretical landscape of flexible, plug-and-play geometric perception (2604.03878).