- The paper presents narrative and rhetorical parallelism benchmarks (NARB) to probe analogical reasoning in LLMs using both internal representation analysis and prompted tasks.
- It reveals that narrative reasoning is weakly encoded across layers while rhetorical reasoning is strongly localized in higher layers (peak MAP ~0.93) yet is poorly accessible via prompting in open-source models.
- The findings emphasize a task-dependent dissociation between what models encode and what they output, advocating for combined probing and prompting methods for comprehensive evaluation.
Probing and Prompting Analogical Reasoning in LLMs: Insights from Narrative and Rhetorical Parallelism
Introduction
This paper provides a comprehensive analysis of analogical reasoning in LLMs, with a focus on how such reasoning is represented internally and expressed externally via prompting. The authors introduce the Narrative Analogical Reasoning Benchmark (NARB) and compare model abilities using both probing (linear and nonlinear diagnostic classifiers on internal representations) and prompting (task instructions with ranking outputs). The study examines two parallelism tasks—narrative and rhetorical—revealing a pronounced dissociation between what models encode and what can be extracted through standard prompting.
Analogical reasoning, which requires mapping structural and functional similarities across domains or narratives beyond surface-level features, is a crucial high-order cognitive process for coherent narrative comprehension, causal inference, and literary analysis.
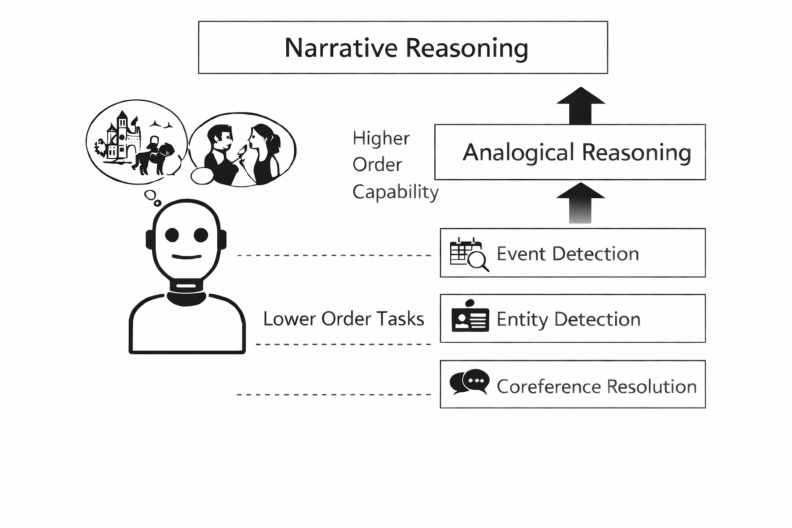
Figure 1: Analogical reasoning is a higher-order capability that requires a combination of lower-level tasks such as entity detection or coreference resolution.
Task and Methodology
The study operationalizes analogical reasoning in two domains:
- Narrative Parallelism: Detecting shared abstract schemas across structurally divergent stories (e.g., mapping “rags-to-riches” arcs independent of thematic or lexical overlap).
- Rhetorical Parallelism: Identifying local stylistic and syntactic symmetry (e.g., antithesis, chiasmus) at the span or sentence level.
Both are framed as ranking problems, not binary classification, requiring models to rank true analogs above distractors in a candidate set. The datasets—ARN for narratives and ASP for rhetorical spans—are partitioned for robust evaluation with cross-validation.
Models probed include open-source Llama-3 variants (1B, 3B, 8B), using activations across layers. Span representations are derived via mean (and max) pooled embeddings. Scoring approaches include non-parametric cosine similarity and low-capacity classifiers (logistic regression, MLP), consistent with probing best practices.
Diagnostic Probing: Layerwise Analysis and Representation
The authors analyze how narrative and rhetorical parallelism are encoded across model layers. ScalarMix aggregates representations from each layer with learned weights, elucidating the progression and localization of relevant information.
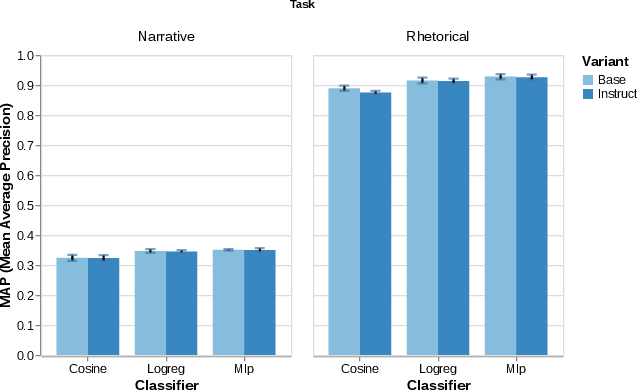
Figure 2: MAP for narrative (left) and rhetorical (right) parallelism tasks across classifier architectures and model variants on Llama-3.2-1B; MLP yields highest performance, especially for rhetorical parallelism.
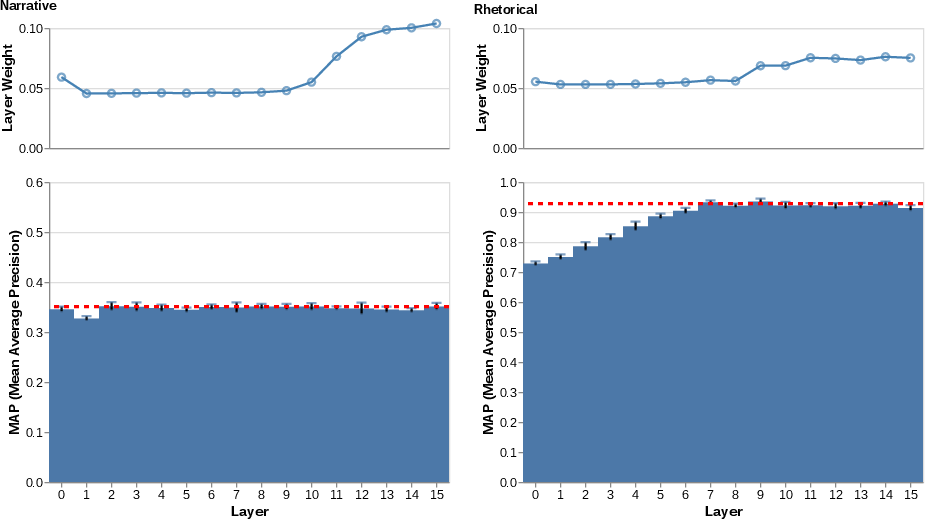
Figure 3: Individual layer performance vs. all-layers configuration for narrative and rhetorical parallelism in Llama-3.2-1B; rhetorical information becomes more discriminative in higher layers, narrative information is more uniformly distributed.
Key findings:
- Narrative parallelism: Information is broadly distributed across the network. Single layers yield indistinguishable performance relative to the full combination, with MAP ≈0.35. There is no clear layer specialization.
- Rhetorical parallelism: Strong layerwise progression is observed, with later layers (8–15) encoding substantially more decodable structure (peak MAP ≈0.93). However, a trivial distance-only baseline (spatial proximity) exceeds all learned and embedding-based methods (MAP ≈0.98), indicating that locality remains the dominant factor in the dataset’s structure.
Prompted experiments contrast open-source Llama models (1B/8B Instruct) and commercial LLM APIs (Claude Opus, GPT-5.2). Models are given sets of anchor-candidate pairs to score and rank.
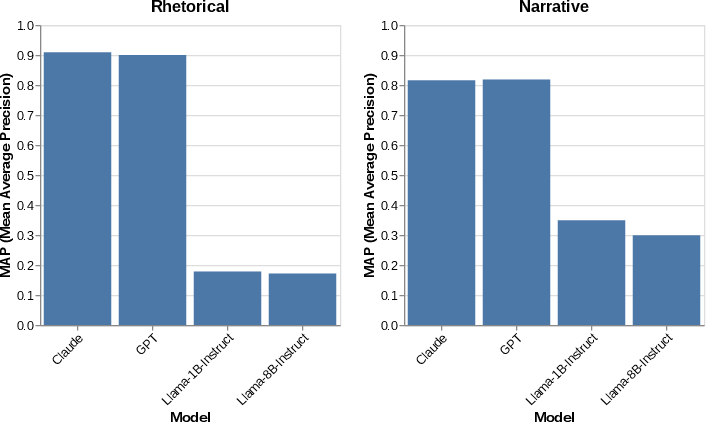
Figure 4: MAP on prompted ranking across different models; closed-source models vastly outperform open-source Llama variants.
The results demonstrate a stark task-dependent dissociation:
- Narrative parallelism: Both probing and open-source prompting converge at low performance (MAP ≈0.35), suggesting marginal model competency. Closed-source models achieve a dramatic increase (MAP ≈0.82).
- Rhetorical parallelism: While probing exposes very strong linear decodability (MAP ≈0.93), open-source Llama models’ prompting performance is exceptionally weak (MAP ≈0.18)—a 5x reduction—whereas closed-source models approach probing-level results (MAP >0.90).
Interpretation and Implications
The findings yield several salient insights into LLM representation and behavior:
- Probing ≠ Prompting: Probing reveals linearly decodable knowledge that may be inaccessible via downstream task prompting, notably for rhetorical parallelism in open models; direct access via prompting is therefore neither necessary nor sufficient evidence for/model competency.
- Task-dependence: The alignment (or lack thereof) between probing and prompting is highly task-dependent. For narrative analogy, poor performance in both reflects weak encoding of abstract narrative structure; for rhetorical analogy, impressive internal representations are not surfaced except in larger or closed-source models.
- Layer structure: Rhetorical parallelism is localized at higher layers, paralleling semantic abstraction. The trivial success of distance-based methods for rhetorical datasets highlights the need for careful design to avoid confounds and to ensure evaluation targets genuine analogical reasoning rather than structural proximity.
- Open vs. closed models: Closed-source models (GPT-5/Claude Opus) appear to have both richer representations and better mechanisms for surfacing them via prompts, indicating differences not just in pretraining data/scale but also instruction-following protocol and possibly architectural idiosyncrasies.
Broader AI and Practical Considerations
This work underscores both the potential and the current limitations of LLMs for higher-order cognitive tasks. Specifically, while transformers can encode sophisticated rhetorical structures, access to these abilities via prompting is contingent on instruction-tuning, scale, and possibly training protocol. For narrative analogical reasoning, improvements are required at both representation and output levels; current open source models lag in abstract schema induction.
For practical deployment—e.g., in narrative comprehension, educational tools, creative writing assistance, or scientific analogizing—sole reliance on prompt-based assessment will systematically underestimate model competency, while probing is insufficient for functional evaluation.
Methodologically, the NARB suite establishes a blueprint for benchmarking abstract reasoning that is less vulnerable to shortcut learning and dataset artifacts compared to binary or paraphrase-style evaluation.
Conclusion
The study exposes a critical asymmetry between what LLMs “know” (as measured by their internal states) and what they “say” (as measured by prompted outputs), and demonstrates that neither probing nor prompting alone is a reliable indicator of model capability for abstract analogical reasoning (2604.03877). Task properties strongly mediate how representational knowledge maps onto actual behavior. The joint use of probing and prompting is essential for comprehensive evaluation. Future advances in model architecture, training, and evaluation are required to (i) reduce reliance on superficial locality cues, (ii) unlock latent high-level reasoning abilities, and (iii) ensure that sophisticated internal representations are both robust and accessible via intended interfaces.

