- The paper introduces a three-stage pipeline comprising teacher adaptation, knowledge transfer, and student refinement.
- It leverages an instance-aware pixel-level contrastive loss with debiased negative sampling to sharpen mask boundaries under low-label conditions.
- Empirical results on Cityscapes and ADE20K show the distilled student model outperforms both zero-shot VFMs and adapted teachers in accuracy and efficiency.
Semi-Supervised Foundation Model Distillation for Instance Segmentation
Motivation and Problem Statement
Vision Foundation Models (VFMs) offer strong transfer performance across diverse dense prediction tasks, yet their heavy computational footprint hinders deployment in latency- and resource-constrained environments. The annotation cost for pixel- and instance-level mask supervision remains prohibitive, especially in settings like autonomous driving or robotic perception. Prior semi-supervised knowledge distillation (SSKD) approaches either treat VFMs as fixed feature extractors, target coarse semantic segmentation, or inadequately leverage the complex structure of unlabeled data for mask refinement, resulting in poorly separated adjacent instances and suboptimal accuracy in low-label regimes.
The paper "Training a Student Expert via Semi-Supervised Foundation Model Distillation" (2604.03841) introduces an end-to-end pipeline for compressing large VFMs into compact instance segmentation experts, leveraging limited labeled data alongside a pool of unlabeled images. The framework synergizes domain adaptation via self-training and pixel-level contrastive calibration, contrastive knowledge transfer with debiased negative sampling, and a supervised student refinement stage.
Framework Overview
The proposed pipeline unfolds in three stages:
- Teacher Adaptation: The VFM teacher is adapted to the target domain via self-training, incorporating pixel-level contrastive regularization to improve mask boundaries and spatial consistency.
- Knowledge Transfer: The adapted teacher's knowledge is distilled into a lightweight student via a unified multi-objective loss, employing instance-aware pixel-wise contrastive sampling.
- Student Refinement: The student is fine-tuned using only labeled data to mitigate pseudo-label bias and sharpen segmentation boundaries.
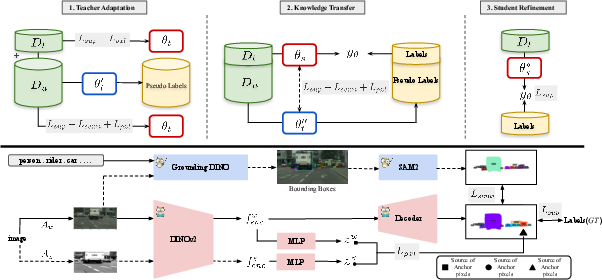
Figure 1: Three-stage pipeline for distilling VFMs into efficient instance segmentation experts; detail highlights anchor pixel sampling and contrastive objective.
Central to the approach is an instance-aware pixel-wise contrastive loss, which fuses mask and class scores to extract informative negatives and enforce clear inter-instance margins. The negative sampling strategy ensures that repulsion focuses on genuinely distinct instances, improving feature discrimination and mask separation.
Instance-Aware Pixel-wise Contrastive Loss
The backbone of the method is a pixel-level NT-Xent contrastive objective. Each anchor pixel's positive pair is matched across weak/strong image augmentations at identical spatial locations. Negatives are sampled across both views, but unlike prior methods, the joint mask-class probability distribution guides negative selection, targeting spatially and semantically distinct pixels likely belonging to different instances.
Let zweak,zstrong be ℓ2-normalized embeddings at resolution N, and y[b,p] the concatenated pseudo-probability embedding for pixel identity and class. The dissimilarity sdeb between anchor (b,p) and candidate negative (b′,q) is a clipped inner product of normalized mask-class embeddings, with negatives sampled in proportion to this score. The theoretical analysis demonstrates that, provided the negative pool predominantly contains true negatives (p>0.5), the expected inter-instance margin increases with the contrastive weight, improving separation even under label scarcity and noisy pseudo-labels.
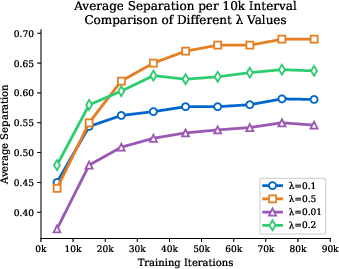
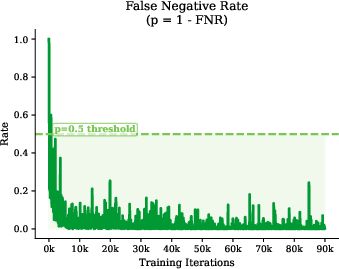
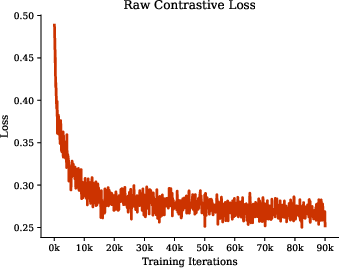
Figure 2: Empirical margin Δemp increases linearly with contrastive weight λpxl, validating expected margin growth.
Empirical Results
Quantitative Evaluation
Experiments on Cityscapes and ADE20K validate the pipeline against strong baselines under ℓ20 labeled regime. The student architecture (DINOv2-S + DPT-S + Transformer decoder) is ℓ21 smaller than the composite teacher ensemble (Grounding-DINO-Large + SAM2-L), yet achieves superior mask AP and mask APℓ22. Key results:
- On Cityscapes:
- Student expert achieves +11.9 AP over zero-shot VFM, and +3.4 AP over adapted teacher.
- MaskAPℓ23 rises to 58.7 post-refinement.
- On ADE20K:
- Student outperforms zero-shot teacher by +8.6 AP and adapted teacher by +1.5 AP.
The pipeline outperforms SSKD baselines (e.g., Guided Distillation, PAIS, Sℓ24M, Depth-Guided), particularly under low-label fractions, maintaining robust gains up to ℓ25 supervision.
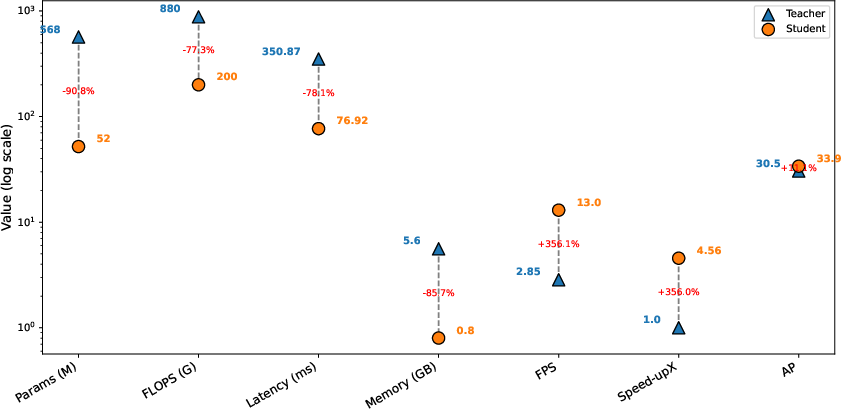
Figure 3: Log-scale efficiency comparison between teacher and student models.
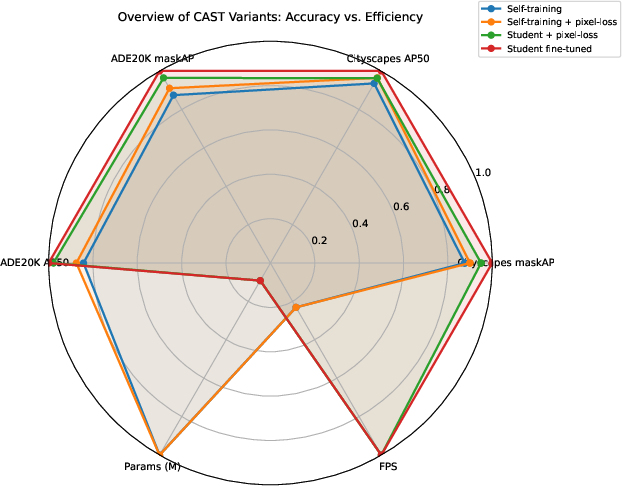
Figure 4: Performance-complexity radar chart highlighting favorable trade-offs for student expert.
Qualitative Results
Visualizations reveal qualitative improvements:
- The adapted teacher produces sharper and more spatially consistent pseudo-labels post self-training and contrastive calibration.
- Student predictions show reduced pseudo-label bias, enhanced boundary crispness, and better separation of adjacent instances.

Figure 5: Student predictions post-distillation exhibit reduced pseudo-label bias and improved instance boundaries.

Figure 6: Qualitative instance segmentation results on ADE20K.

Figure 7: Teacher attention maps before and after adaptation; post-adaptation maps are localized and foreground-focused.
Ablation Studies
Exhaustive ablations confirm the contribution of each component:
Theoretical and Practical Implications
Theoretically, the instance-aware negative sampling in pixel-level contrastive loss demonstrably increases empirical inter-instance margin and maintains high probability of true negative selection even under noisy pseudo-labels.
Practically, the approach enables efficient deployment of specialized, compact models for dense prediction tasks, reducing annotation costs and compute requirements. The modularity and transferability of the framework suggest scalability to broader perception domains (medical imaging, robotics, video), and potential integration with diverse foundation model ensembles.
Future Directions
Possible avenues for extension include:
- Unifying or simplifying the multi-stage training pipeline via curriculum or meta-learning strategies.
- Generalization to new domains (e.g., satellite imagery, medical segmentation) and modalities.
- Systematic evaluation of backbone and decoder variants for further efficiency gains.
- Exploration of knowledge transfer from heterogeneous ensembles of foundation models.
Conclusion
This paper establishes a principled pipeline for semi-supervised distillation of VFMs into compact instance segmentation experts. By combining self-training, pixel-level contrastive calibration, and final supervised refinement, the method surpasses both adapted teachers and prior SSKD baselines on dense segmentation benchmarks, with strong theoretical justification for its margin growth properties. The approach advances efficient low-label adaptation for high-capacity vision foundation models, with broad practical applicability and potential for further research in scalable, specialized visual perception.
