- The paper introduces AutoReSpec, a framework that uses collaborative LLM strategies to generate formally verifiable Java specifications with high success rates.
- It integrates dynamic prompt generation, iterative refinement, and adaptive model selection to minimize validation calls and reduce runtime.
- Empirical results demonstrate AutoReSpec's superiority, achieving up to 100% success on challenging methods and significantly lowering error rates.
Collaborative Specification Generation with AutoReSpec
Introduction and Motivation
The paper "AutoReSpec: A Framework for Generating Specification using LLMs" (2604.03758) presents a formal and empirical analysis of automated specification synthesis in Java, leveraging LLMs for generating verifiable annotations in the Java Modeling Language (JML). Given the persistent absence of formal specifications in real-world software, and the high manual annotation cost, the paper situates its contribution in the context of prior LLM-based approaches such as SpecGen and FormalBench, which suffer from brittle prompt strategies, inability to recover from validation failures, and lack of adaptivity to program structure.
A compelling motivating example demonstrates that both SpecGen and FormalBench achieve 0% success probability and completeness on a control-heavy Java method (TokenTest02), whereas AutoReSpec's collaborative framework yields 100% success probability and completeness, with fewer validator calls and reduced runtime.
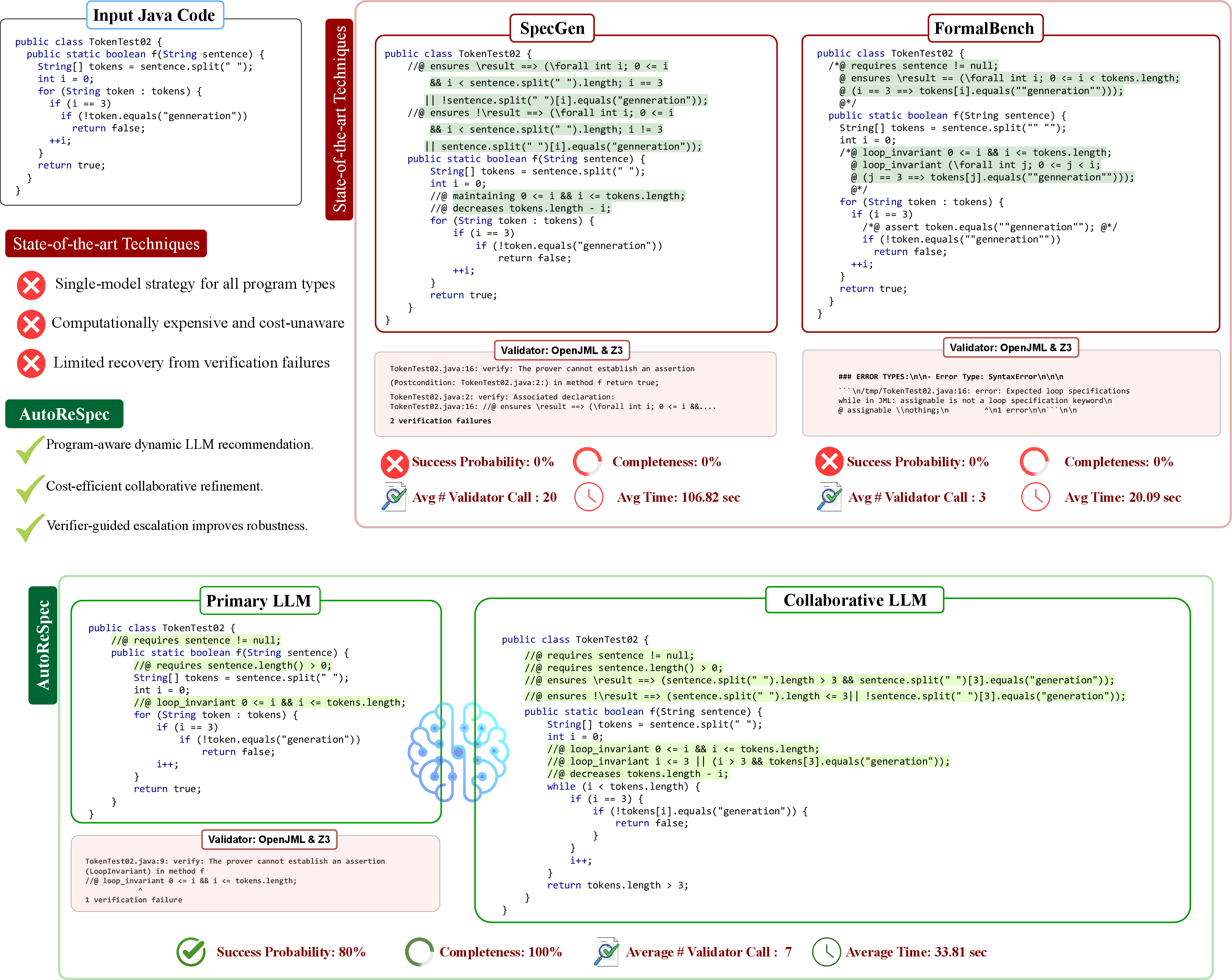
Figure 1: Comparison of prior tools and AutoReSpec on a challenging Java method, highlighting AutoReSpec's pipeline which achieves verifiable specifications and superior metrics.
Architecture and Algorithmic Framework
AutoReSpec is architected as a multi-stage pipeline that combines a dynamic LLM recommender, prompt generator, iterative refinement, and collaborative fallback to generate formally verifiable specifications.
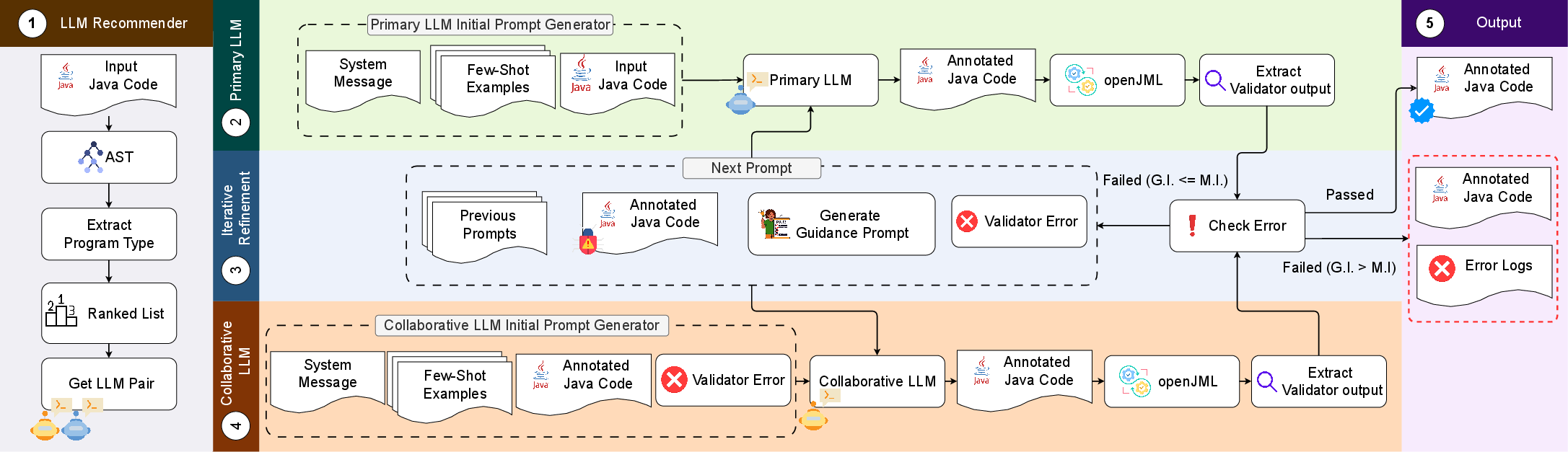
Figure 2: Block diagram of AutoReSpec, showing the analysis, model selection, synthesis, validation, and collaborative error recovery loop.
The workflow proceeds as follows:
- The LLM recommender statically analyzes the input Java code's AST, classifies program type (sequential, branched, single-/multi-/nested-loop), and chooses a model pair (primary and collaborative LLM) based on empirical calibration.
- The prompt generator constructs initial prompts by amalgamating system messages, a program-dependent selection of few-shot examples, and target code.
- The primary LLM generates specifications, followed by validation via OpenJML. If the validation fails within the refinement budget, validator feedback is parsed and injected back into subsequent prompts for iterative improvements.
- Upon exhaustion of primary refinement, the collaborative LLM is invoked, receiving only the final invalid specification and its associated error trace, enabling focused recovery.
- Prompt truncation and memory reset tactics are employed to keep context windows manageable and avoid LLM hallucinations.
This collaborative conversational prompting strategy is driven by model calibration for each program type, ensuring cost-efficient and robust specification synthesis.
Experimental Design and Benchmarking
Evaluation is conducted using a diverse benchmark of 72 Java programs, comprising challenging cases from SpecGenBench, SV-COMP, and real-world OpenJML GitHub issues. The dataset includes multi-method classes with varied control flow, data types, and specification constructs, providing a rigorous test bed for scalability and realism.
Metrics include:
- Number of Passes (NP), normalized as Success Rate (SR)
- Success Probability (SP)
- Completeness (C via mutation analysis)
- Number of Verifier Calls (Nval)
- Evaluation time
Statistical validation is performed using McNemar's test for paired outcomes and Wilcoxon signed-rank tests.
Empirical Results and Numerical Highlights
AutoReSpec demonstrates strong performance across multiple axes:
- On SpecGenBench, collaborative prompting and dynamic model selection achieves NP=119/120, SP=69.32%, and C=60.33%, outperforming SpecGen (100%0) and FormalBench (substantially lower) with the same iteration budget.
- On the full 72-program benchmark, AutoReSpec achieves 100%1, 100%2, 100%3, and 100%4, cutting evaluation time by 100%5 compared to prior tools.
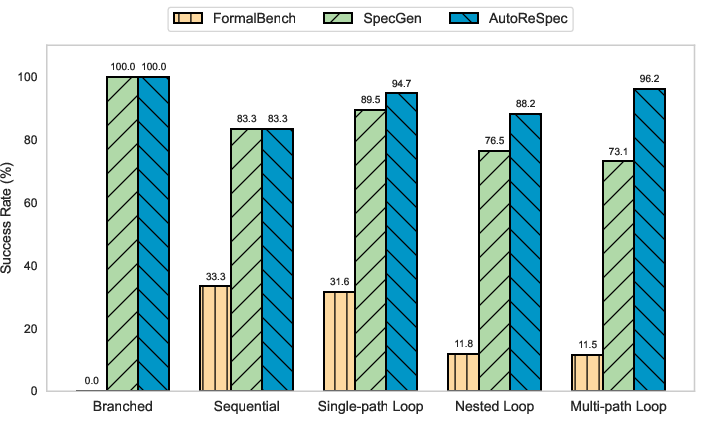
Figure 3: Pass percentage (100%6) for AutoReSpec, SpecGen, and FormalBench across program types, showing especially strong improvement for loop-heavy programs.
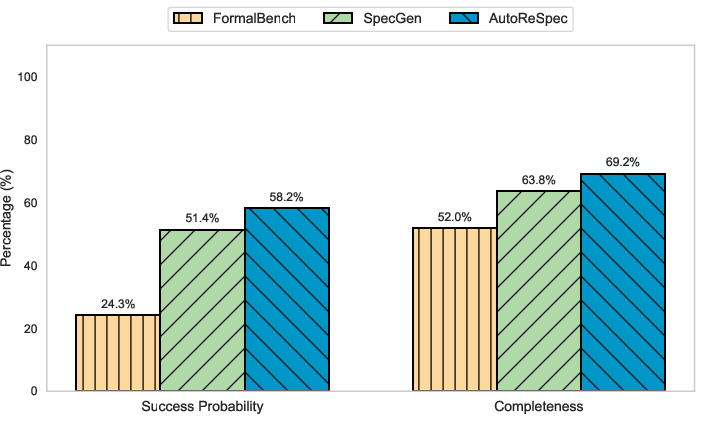
Figure 4: AutoReSpec achieves superior average success probability and completeness compared to benchmarks.
Efficiency is evidenced by marginally lower average evaluation time and API cost per class, owing to the adaptive selection of LLMs and reduction in redundant validation calls.
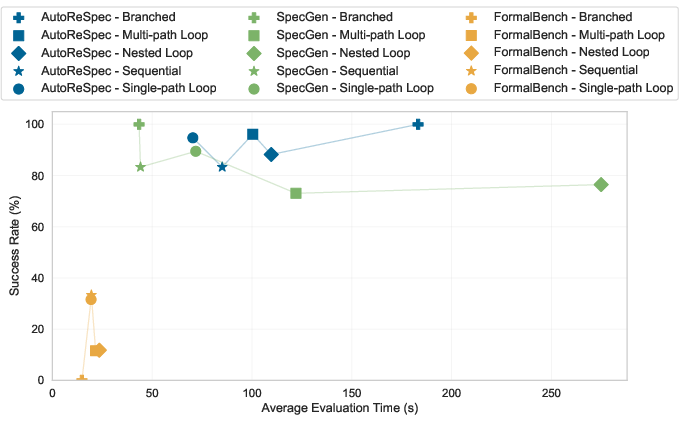
Figure 5: Runtime and success rate measurements, indicating AutoReSpec's efficient scaling and practical evaluation times.
Error analysis reveals that AutoReSpec reduces struggle ratios for verification error types—especially postcondition and loop-invariant errors—by significant margins relative to SpecGen (e.g., 100%7 vs.\ 100%8 for postcondition errors).
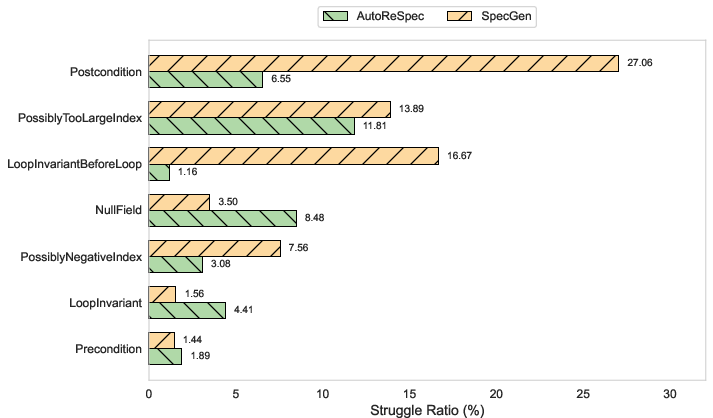
Figure 6: Distribution of top error types; AutoReSpec shows consistent reductions in struggle ratios for challenging error classes.
AutoReSpec sits at the confluence of LLM-driven specification synthesis and prior static/dynamic contract mining. By integrating verifier-guided conversational refinement, adaptive prompt construction, and collaborative model fallback, it addresses limitations of previous approaches that rely on static prompts and single-model strategies.
Theoretical implications include:
- Evidence that LLM performance in specification synthesis is program-type dependent and benefits from adaptive strategies.
- Structured collaboration and validator-guided refinement operationalize LLM reasoning in formal verification contexts, suggesting pathways for cross-language and multi-module extension.
Limitations are identified primarily in LLMs' propensity for misinterpreting complex control flow and null-safety contexts; improvements in underlying model architectures and further calibration may address these deficits. The OpenJML verifier, as well as mutation completeness measures, impose additional constraints on generality and measurement accuracy.
Practical Implications and Future Directions
Practically, AutoReSpec enables scalable formal specification and annotation for Java code, with empirical evidence of improved verification outcomes and computation efficiency. The open-source release, VS Code integration, and leaderboard support reproducibility and adoption. Extensions to other specification languages (ACSL, Viper), incorporation of lightweight static checks, and multi-module system scaling are on the roadmap.
Future directions include broader cross-language support, integration of prompt adaptation strategies based on instantaneous validator feedback, and investigation into model evolution and inference capabilities for more complex specifications, including non-functional properties.
Conclusion
AutoReSpec demonstrates an authoritative framework for LLM-driven specification synthesis, achieving high verification success and completeness through collaborative prompting and adaptive model selection. Its empirical superiority over existing tools is underscored by strong numerical results, improved efficiency, and robust error resolution. The approach and benchmark resources support ongoing advances in automated formal specification and program verification, with implications for scaling LLM reasoning in software engineering domains and future AI systems.