- The paper introduces FAERec, which adaptively fuses collaborative and LLM-derived semantic embeddings to markedly enhance tail-item recommendations.
- The paper leverages dual-level alignment using contrastive learning and cross-correlation minimization to ensure structural consistency between ID and LLM embedding spaces.
- The paper demonstrates substantial improvements, with up to 182.9% gain in NDCG@10, and robust performance across extreme tail and varied popularity item groups.
Fusion and Alignment Enhancement with LLMs for Tail-item Sequential Recommendation
Introduction and Motivation
Tail-item sparsity presents a formidable challenge in sequential recommendation systems, particularly in domains such as e-commerce or media where the majority of items receive minimal user interactions. Traditional SR architectures, notably those rooted in collaborative filtering, prove inadequate in learning robust item embeddings for such tail items. This deficiency critically affects prediction quality and system coverage. Recent integration of LLM-derived item semantics into recommendation workflows has partially ameliorated this, but extant approaches suffer from two primary weaknesses: ineffective fusion of semantic and collaborative signals, and structural misalignment between ID and LLM embedding spaces. "Fusion and Alignment Enhancement with LLMs for Tail-item Sequential Recommendation" (2604.03688) introduces FAERec, a framework prioritizing both adaptive fusion and structural alignment, aiming to rectify these deficiencies and substantially improve tail-item recommendation efficacy.
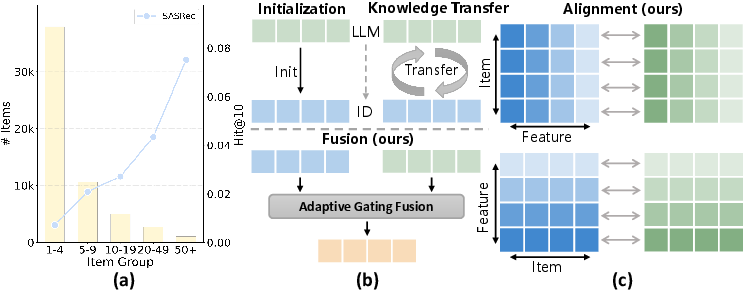
Figure 1: (a) Visualization of the interaction sparsity characteristic of long-tail items and (b,c) performance comparisons highlighting FAERec's advantages over prior LLM-based SR strategies.
Methodology: Adaptive Fusion and Dual-level Alignment
FAERec consists of two principal modules: Adaptive Gating Fusion and Dual-level Alignment. The fusion mechanism employs a dimension-wise gating network to dynamically weight collaborative (ID) embeddings and semantic (LLM) embeddings for each item, enabling precise, context-dependent integration. The LLM embedding extraction is performed via pre-trained APIs (e.g., OpenAI's text-embedding-ada-002), with subsequent dimensionality reduction and projection for compatibility.
To address space discrepancy, FAERec employs dual-level alignment:
- Item-level alignment: Contrastive learning maximizes cosine similarity between corresponding ID and LLM embeddings, enforcing pointwise item-level consistency.
- Feature-level alignment: Inspired by Barlow Twins, FAERec constructs cross-correlation matrices between normalized ID and LLM embedding batches, penalizing off-diagonal correlations to minimize redundancy and enforcing structural consistency across embedding spaces.
A curriculum scheduler dynamically adjusts the weighting between item-level and feature-level objectives during training, preventing premature feature-level optimization that could introduce noise before robust itemwise correspondences are achieved.
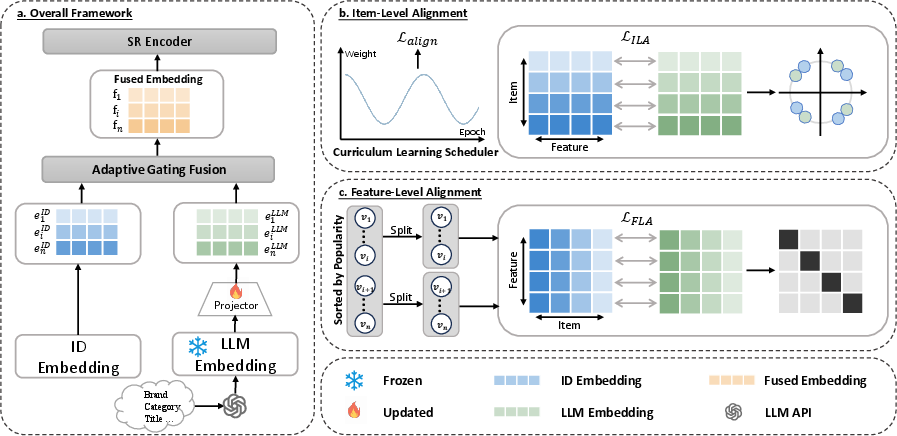
Figure 2: The FAERec architecture illustrating adaptive fusion and dual-level alignment in SR models.
Empirical Evaluation and Results
Experiments are conducted on three datasets (Amazon Beauty, Amazon Grocery, Yelp), each exhibiting extreme sparsity (>99%) for tail items. FAERec is benchmarked with multiple backbone SR architectures (SASRec, FMLP-Rec, LRURec) and compared to both traditional knowledge transfer and recent LLM-based baselines.
FAERec consistently demonstrates substantial improvements. On SASRec, FAERec achieves up to 178.8% improvement in NDCG@10 for tail items on Beauty, and up to 182.9% on Grocery—results which are considerably higher than other LLM-based and collaborative baselines (see Table 1 in the paper). RLMRec-Con, a prior state-of-the-art for knowledge transfer, is consistently outperformed in both the overall metrics and for tail-item groups. Ablation studies further affirm the efficacy of each FAERec module, with marked performance drops when adaptive gating fusion or alignment components are omitted.
Hyperparameter and Group Analyses
Extensive sensitivity analysis (Figure 3) reveals optimal values for the feature-level alignment redundancy weight λ (0.005–0.01) and alignment loss weight α (0.3–0.4), with both influencing overall and tail performance non-trivially. FAERec’s robustness across parameter sweeps underscores its practical adaptability.
Group analyses stratified by item popularity illustrate that FAERec not only excels for extreme tail but provides improvements across all popularity segments, further evidencing its broad applicability. However, a seesaw effect emerges for very popular items, indicating a maximal gain for tail-oriented groups at some cost to head-item performance, an inherent trade-off in long-tail optimization.

Figure 3: Sensitivity analysis illustrating performance variation with λ and α hyperparameters.
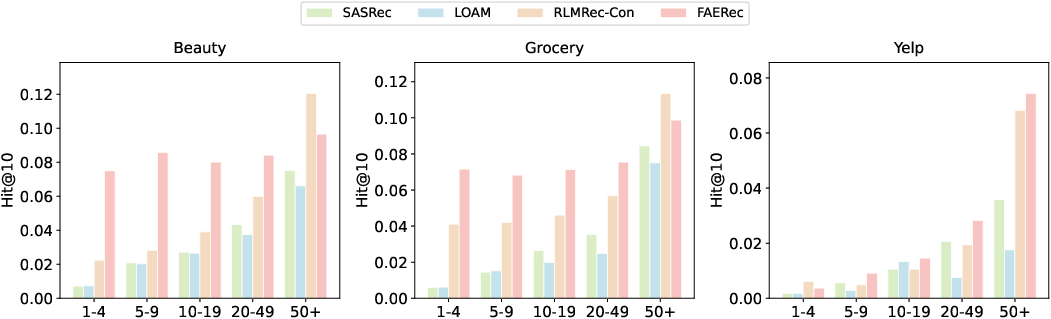
Figure 4: Group-wise performance comparison showing FAERec’s improvements across item popularity spectra.
Structural Visualization
t-SNE visualization (Figure 5) demonstrates the post-alignment structural consistency between ID and LLM embeddings achieved by FAERec. Prior methods (e.g., LLMInit, LLM-ESR) show independent, scattered distribution; RLMRec-Con achieves rough alignment; FAERec yields uniform, tightly coupled embedding spaces, facilitating improved representation and generalization.
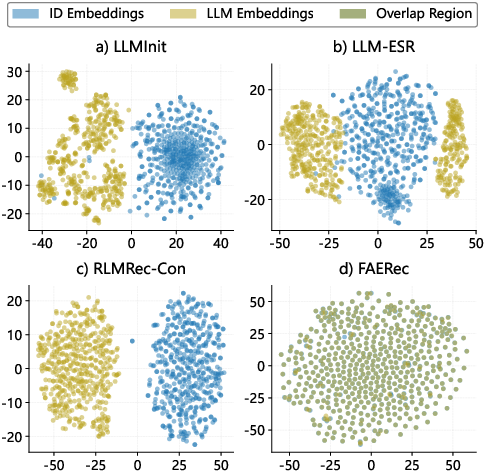
Figure 5: t-SNE visualization of ID and LLM embedding spaces—FAERec achieves high structural alignment.
Diversity and Generalization
FAERec considerably enhances recommendation diversity, as measured by Coverage@10 and Tail_Coverage@10 metrics. It also generalizes seamlessly to NARM, LightSANs, and gMLP backbones, maintaining large accuracy gains and diversity levels across all architectures and datasets.
Implications and Future Directions
FAERec’s methodology of adaptive fusion and embedding space alignment signifies a paradigm shift from semantic knowledge as auxiliary to semantic knowledge as integral and structurally consistent within SR models. The approach is model-agnostic, allowing for straightforward integration with a spectrum of architectures, furthering its practical applicability. The improved diversity and tail-item recall are critical for systems seeking maximized item coverage and long-term user engagement.
Theoretically, FAERec’s dual-level alignment compels further exploration into cross-modal embedding consistency, curriculum scheduling in representation learning, and hybrid optimization strategies that balance conflicting objectives (tail vs. head). Practically, leveraging precomputed LLM embeddings and efficient fusion mechanisms favors real-world deployment with modest computational overhead, especially for domains with rapidly expanding item catalogs.
Potential future directions include finer-grained personalization of fusion weights, extension to user-side tail scenarios, longitudinal tracking of diversity effects on user retention, and application of joint optimization with additional modalities (visual, acoustic). Adversarial training for further embedding robustness and continual learning schemes may also be investigated.
Conclusion
FAERec delivers a comprehensive solution for tail-item sequential recommendation via the fusion of collaborative and semantic signals combined with structural alignment, achieving strong numerical results across diverse benchmarks. Its framework establishes item, feature, and structural consistency, setting a new standard for the integration of LLMs in recommendation pipelines, and providing empirical and theoretical motivation for continued advancements in long-tail item modeling.