- The paper presents LLM4MSR as a novel solution that mitigates embedding collapse and catastrophic forgetting in LLM-based sequential recommendation.
- It employs an MM-RQ-VAE architecture with MMD reconstruction loss and contrastive alignment to integrate collaborative, textual, and visual modalities.
- Experimental results show up to 10.47% improvement in nDCG@5 across multiple Amazon datasets and validate the benefits of frequency-aware fusion.
Empowering LLMs for Sequential Recommendation via Multimodal Embeddings and Semantic IDs
Introduction
This paper addresses two critical limitations in the application of LLMs to Sequential Recommendation (SR): embedding collapse and catastrophic forgetting. Embedding collapse refers to the phenomenon where low-dimensional collaborative embeddings, when projected into the high-dimensional LLM token space, occupy a low-rank subspace, severely limiting model capacity and scalability. Catastrophic forgetting occurs when the quantized code embeddings learned during semantic ID generation are discarded, resulting in the loss of crucial distance information and partial order structure in downstream tasks. The proposed framework, LLM4MSR, systematically mitigates these issues by leveraging multimodal embeddings and semantic IDs, introducing a Multimodal Residual Quantized Variational Autoencoder (MM-RQ-VAE) with Maximum Mean Discrepancy (MMD) reconstruction loss and contrastive alignment, and employing frequency-aware fusion during LLM fine-tuning.
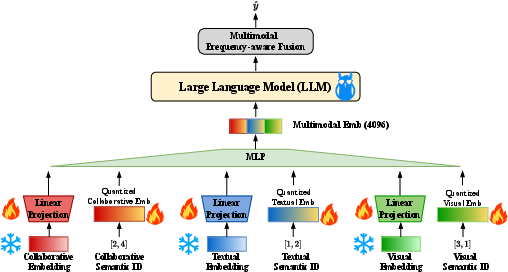
Figure 1: The overall framework of LLM4MSR, illustrating the encoding and fine-tuning stages integrating multimodal embeddings and semantic IDs.
Theoretical Analysis of Embedding Collapse and Catastrophic Forgetting
The paper provides a formal analysis of embedding collapse, demonstrating that the rank of the projected embedding matrix is upper-bounded by the rank of the original collaborative embedding. Empirical results show that over 98% of the dimensions in the LLM token embedding space collapse when only collaborative embeddings are used. For catastrophic forgetting, the authors employ Kendall's tau to quantify the preservation of distance information between behavioral and target item embeddings. Experiments reveal that randomly initialized code embeddings retain less than 6% of the original distance information, confirming severe forgetting.
Multimodal Residual Quantized VAE (MM-RQ-VAE)
The MM-RQ-VAE architecture is designed to encode collaborative, textual, and visual modalities, quantize them into semantic IDs, and reconstruct embeddings that preserve intra-modal distance and inter-modal correlations. The reconstruction loss is formulated using MMD, which, unlike MSE, preserves the full distributional statistics of the original embeddings. Contrastive learning objectives align collaborative embeddings with textual and visual modalities, leveraging the representational power of LLM2CLIP for multimodal encoding.
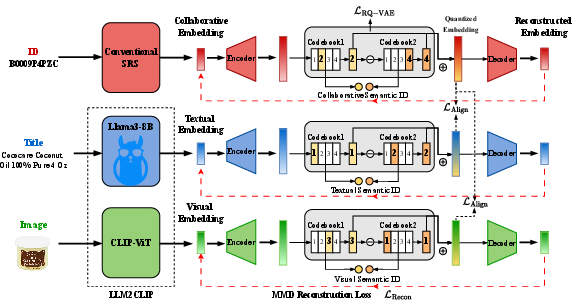
Figure 2: The model architecture of MM-RQ-VAE, showing modality-specific RQ-VAEs, alignment, and reconstruction pathways.
Fine-Tuning with Frequency-Aware Fusion
During fine-tuning, the LLM input is constructed by concatenating the linear projection of original multimodal embeddings and the sum of semantic ID embeddings, followed by an MLP to match the LLM token dimension. The semantic ID embeddings are initialized with the trained code embeddings from MM-RQ-VAE, preserving learned distance information and mitigating forgetting. A frequency-aware fusion module adaptively weights the contribution of each modality based on item frequency, addressing the long-tail distribution prevalent in real-world recommendation datasets.
Experimental Results
Extensive experiments on three Amazon datasets (Beauty, Toys & Games, Sports & Outdoors) demonstrate that LLM4MSR consistently outperforms all baselines, including SASRec, E4SRec, multi-embedding, and multimodal generative retrieval methods. The framework achieves up to 10.47% improvement in nDCG@5 over the best baseline. Singular value analysis confirms that LLM4MSR effectively alleviates embedding collapse, while Kendall's tau measurements show substantial retention of distance information, validating the mitigation of catastrophic forgetting.
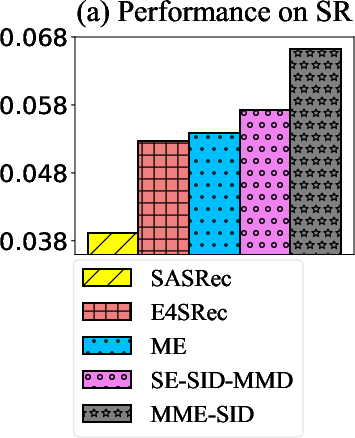
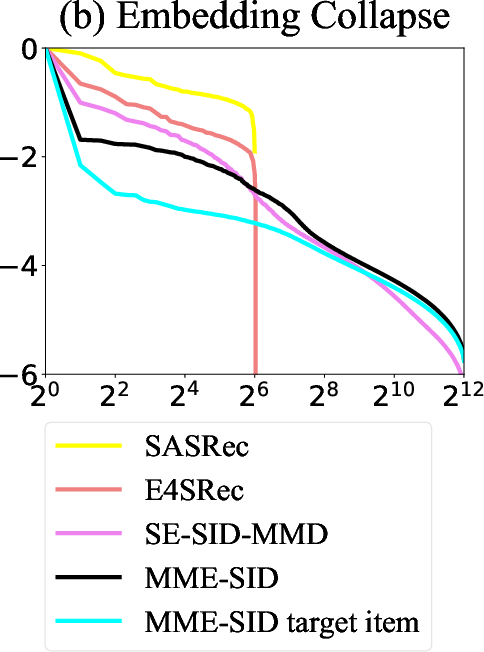
Figure 3: (a) Sequential recommendation performance (nDCG@20) and (b) embedding collapse measurement (singular value spectrum) on the Beauty dataset.
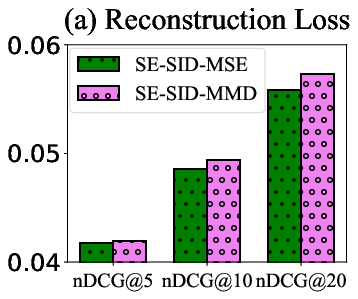
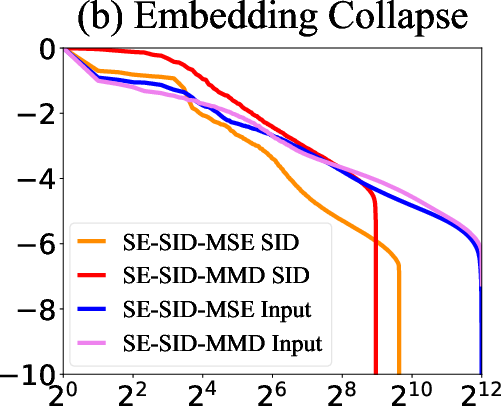
Figure 4: Comparison of MMD and MSE as reconstruction loss on (a) recommendation performance and (b) embedding collapse.
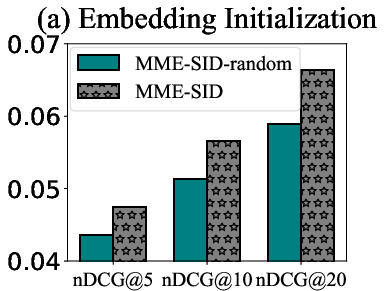
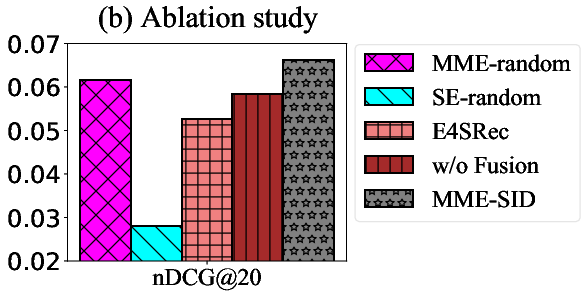
Figure 5: (a) Impact of code embedding initialization on nDCG@k and (b) ablation study results on nDCG@20 for the Beauty dataset.
Ablation and Analysis
Ablation studies confirm that the performance gains of LLM4MSR are not merely due to increased parameterization but stem from the synergistic integration of multimodal embeddings, semantic IDs, and frequency-aware fusion. Random initialization of code embeddings leads to catastrophic forgetting and degraded performance, while removal of the fusion module reduces accuracy, underscoring its importance.
Implications and Future Directions
The findings have significant implications for the design of LLM-based recommender systems. The integration of multimodal embeddings and semantic IDs, coupled with MMD-based reconstruction and contrastive alignment, provides a principled approach to overcoming scalability and knowledge retention challenges. The frequency-aware fusion mechanism offers a practical solution for handling long-tail item distributions. Future research may explore more sophisticated multimodal encoders, hierarchical fusion strategies, and scalable quantization techniques for industrial-scale SR systems.
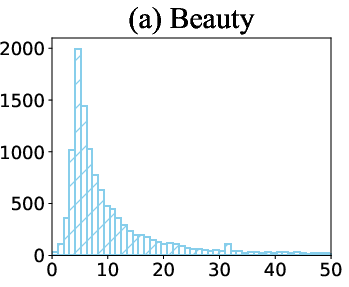
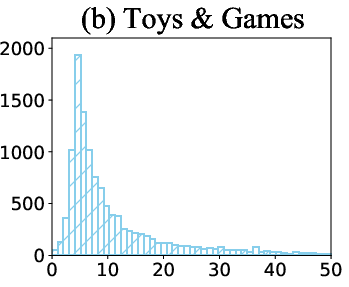
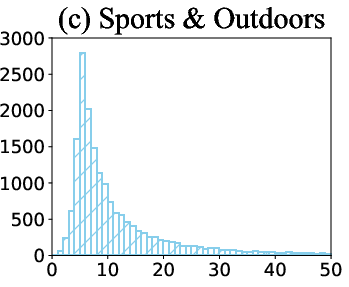
Figure 6: Distribution of item frequency in Beauty, Toys & Games, and Sports & Outdoors datasets, illustrating the long-tail nature of real-world recommendation data.
Conclusion
LLM4MSR presents a comprehensive solution to embedding collapse and catastrophic forgetting in LLM-based sequential recommendation. By leveraging multimodal embeddings, semantic IDs with trained code embeddings, and frequency-aware fusion, the framework achieves superior recommendation accuracy and scalability. The theoretical and empirical analyses provide a robust foundation for future advancements in LLM-driven recommender systems, with practical relevance for large-scale, multimodal, and dynamic environments.