- The paper introduces TABLeT, a novel framework that tokenizes 3D fMRI volumes into 27 tokens using a pre-trained 2D DCAE, enabling efficient long-range dynamics modeling.
- It demonstrates that features from natural image autoencoders generalize robustly to fMRI data, yielding high-fidelity reconstructions comparable to bespoke 3D models.
- Empirical evaluations show TABLeT achieves significant memory and speed improvements while extending temporal context for tasks like intelligence regression and ADHD diagnosis.
Introduction and Motivation
Modeling spatiotemporal dynamics in functional Magnetic Resonance Imaging (fMRI) presents fundamental difficulties due to the high dimensionality of 4D fMRI signals. Traditional ROI-based approaches aggregate signals at the region level, leading to loss of fine-grained information, while voxel-based approaches directly process 4D volumes but are limited to short temporal windows due to prohibitive memory and computational requirements. Accurately capturing long-range temporal dynamics (e.g., global arousal waves, infraslow coupling) is critical for numerous brain research applications, yet remains unaddressed by existing paradigms.
This work introduces TABLeT (Two-dimensionally Autoencoded Brain Latent Transformer), a pipeline that enables efficient long-range fMRI modeling by tokenizing fMRI volumes with a pre-trained 2D autoencoder (specifically, a DCAE trained on natural images) and processing these compact tokens using a standard Transformer architecture. Notably, the study empirically demonstrates that natural image autoencoders generalize robustly to fMRI data, yielding high-quality, information-preserving, and computationally efficient token representations.
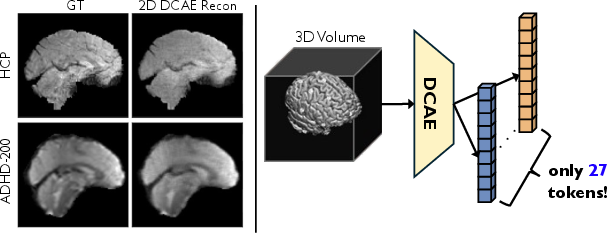
Figure 1: Transferring a 2D natural image autoencoder for tokenizing 4D fMRI data (left) and compressing a 3D fMRI volume into 27 tokens for Transformer modeling (right).
Methodological Framework
2D DCAE-based Tokenization of 3D fMRI Volumes
The core of TABLeT is the deployment of an off-the-shelf 2D DCAE, without domain-specific fine-tuning, for fMRI volume tokenization. Each 3D fMRI volume is decomposed into slices along three spatial axes; all slices are passed independently through the frozen 2D DCAE encoder, generating latent representations which are then reorganized and aggregated.
Each axis-wise token matrix is aligned and concatenated, resulting in 27 tokens per 3D volume (for the canonical setting of 96×96×96 fMRI volumes and 32× compression in each spatial direction). Each token has a channel dimensionality of 3072, balancing token count and representational richness.
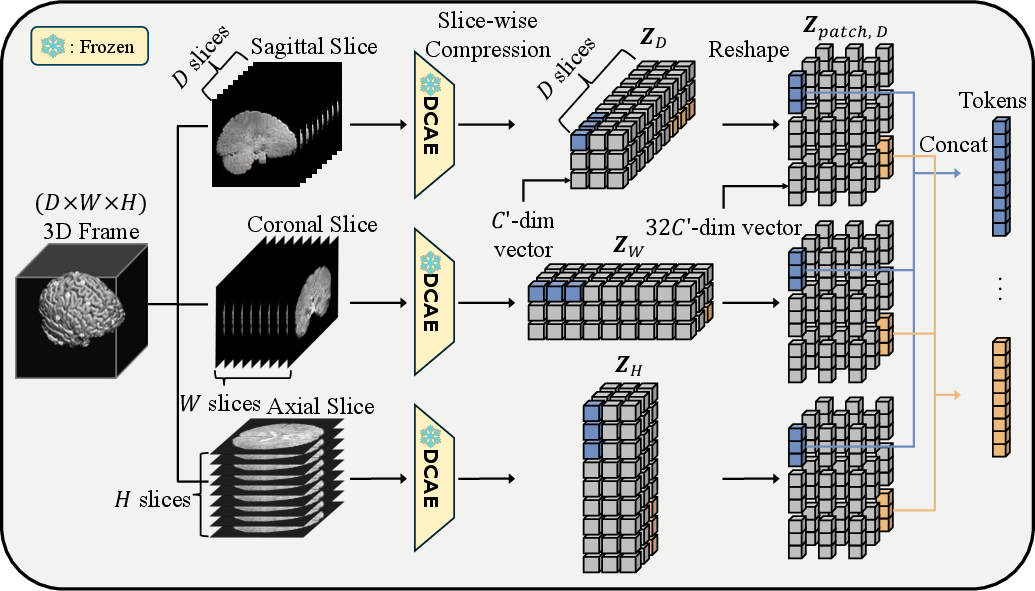
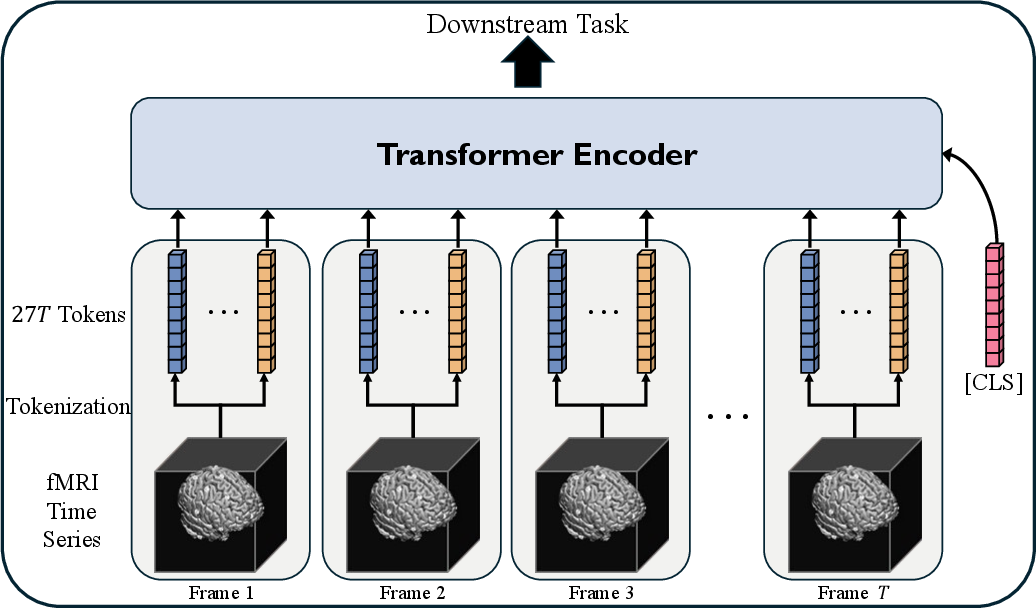
Figure 2: Tokenization process illustrating the slice-wise encoding of a 3D fMRI volume using a 2D encoder.
Aggregation across all three axes yields spatially robust latent codes. This procedure is invariant to the specific aggregation scheme, with comparative studies indicating negligible downstream performance variance across axis configurations.
Once fMRI frames are tokenized, the sequence of tokenized volumes forms the input for a standard Transformer encoder operating in the token-time domain. The model utilizes grouped query attention and rotary positional encoding for efficient long-context processing. Long temporal windows (e.g., T=256) are made possible by the drastic token compression, a substantial improvement over the T=20–$50$ context length of existing efficient voxel-based models (such as SwiFT).
A self-supervised masked token modeling (MTM) pretraining scheme, analogous to masked image modeling in vision, further enhances representation quality and transferability.
Empirical Evaluation
A comprehensive evaluation of tokenization fidelity shows that the 2D DCAE, despite being trained solely on natural images, achieves superior or on-par reconstruction performance compared to a bespoke 3D DCAE trained directly on large-scale fMRI datasets.
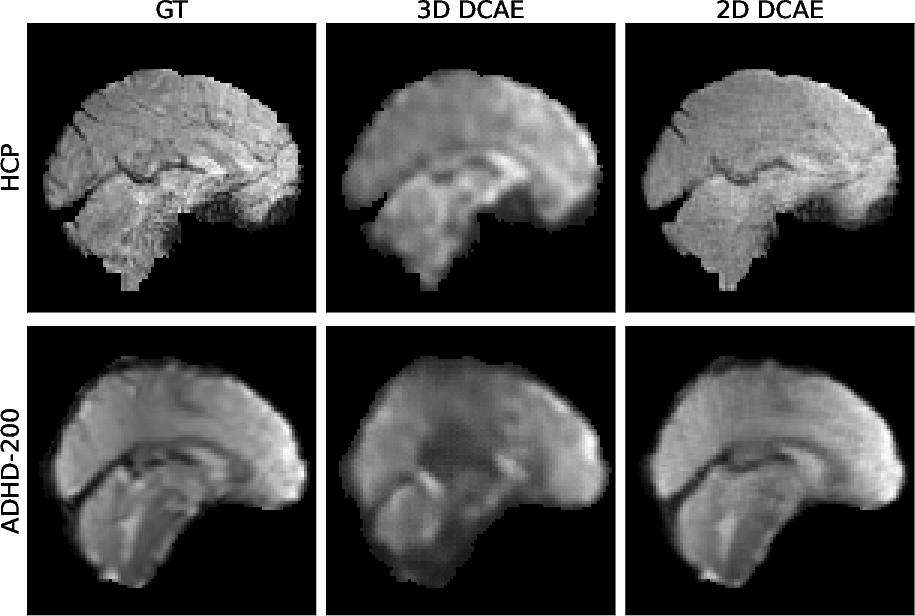
Figure 3: Reconstruction comparison between 2D DCAE and 3D DCAE, both visually and quantitatively.
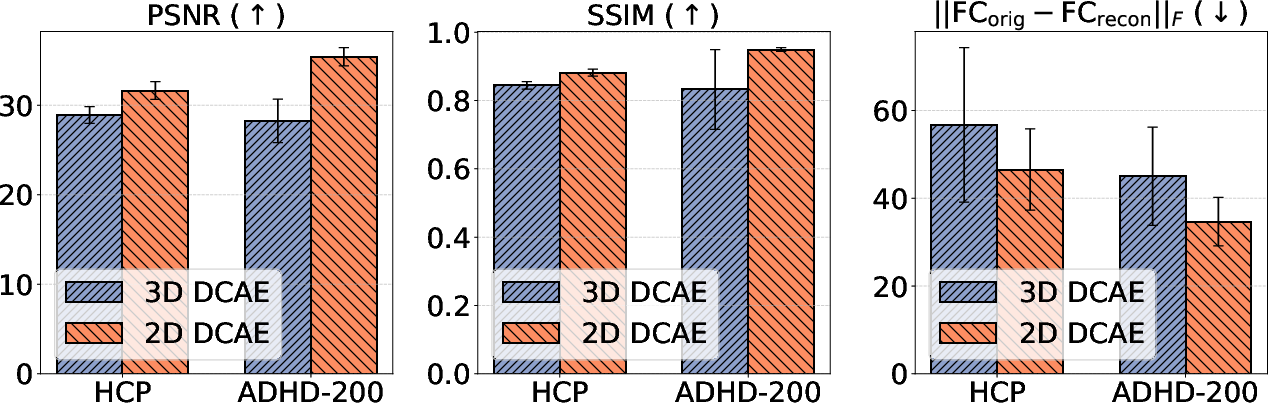
Figure 4: Quantitative assessment of information preservation by 2D vs. 3D DCAE; metrics include voxel-wise PSNR/SSIM and functional connectivity matrix deviation.
Fine-tuning the DCAE on fMRI data is counterproductive, degrading both low-level and high-level representation fidelity, further supporting the generality and robustness of features acquired from large-scale natural image data.
TABLeT achieves consistently competitive or superior performance across diverse tasks—sex and age classification (UKB/HCP), intelligence regression (HCP), and ADHD diagnosis (ADHD-200)—compared to both ROI-based and state-of-the-art voxel-based baselines (e.g., SwiFT, TFF). The model not only enables longer context windows, critical for tasks leveraging long-range temporal information, but also yields computational and memory savings.
The efficacy of long-context modeling is particularly pertinent for tasks such as intelligence regression and naturalistic stimulus classification, corroborated by ablation studies on the impact of temporal window size.
Sample Efficiency and Computational Cost
Empirical analysis demonstrates a 7.33-fold reduction in peak memory usage and nearly 4-fold improvement in training speed versus competing voxel-based approaches for comparable input scales. Moreover, TABLeT supports tenfold longer temporal context modeling for the same hardware constraints.
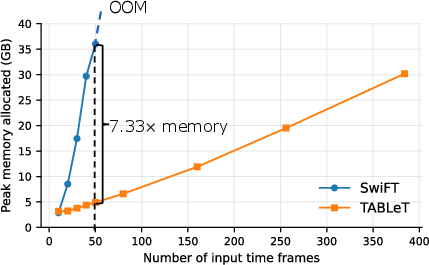
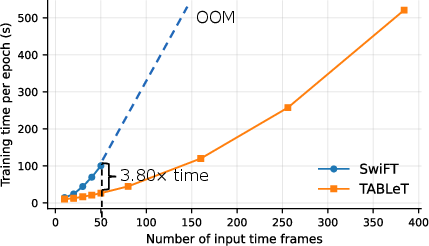
Figure 5: TABLeT exhibits substantial reductions in GPU memory overhead compared to SwiFT with increasing temporal window size.
Task-specific Considerations and Ablations
Substantial positive correlations are observed between temporal context size and accuracy for certain tasks—e.g., intelligence prediction and movie classification—while tasks dominated by spatial patterns (e.g., demographic attribute discrimination) see more modest gains.
Ablation studies on axis aggregation, aggregation schemes, masked pretraining, and different task types (e.g., dynamic vs. resting state) support the robustness of TABLeT's architecture and provide guidelines for application-specific deployment.
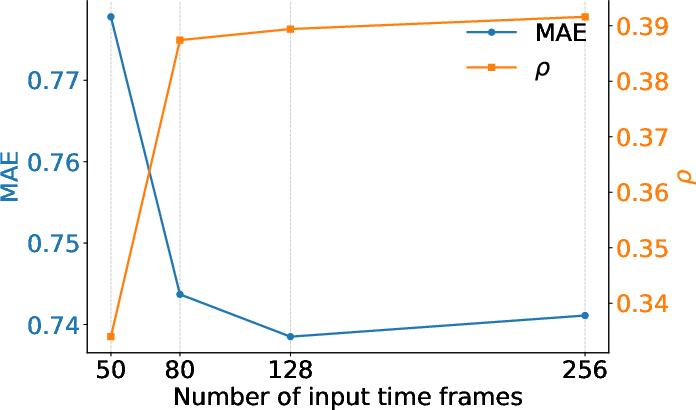
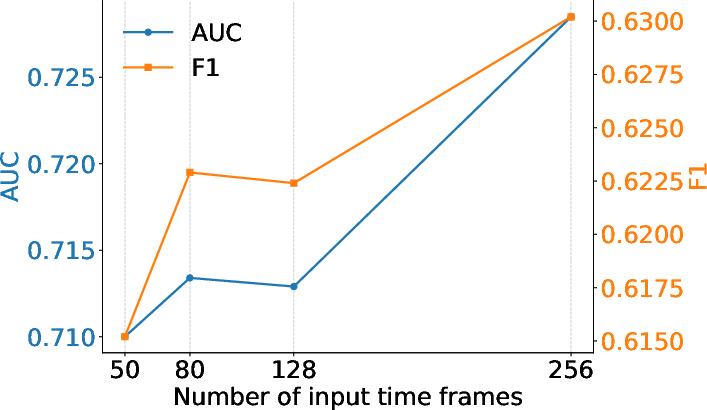
Figure 6: Influence of T (input sequence length) on HCP-Intelligence task performance, illustrating the benefit of long-range temporal context.
Theoretical and Practical Implications
TABLeT demonstrates that cross-domain feature transfer from the natural image domain to brain imaging is both feasible and beneficial, enabling computationally efficient and high-fidelity representation learning for fMRI data without expensive medical-domain pretraining or fine-tuning. This finding motivates further investigation into the universality of visual representations across broader medical imaging modalities.
The masked token modeling approach for self-supervised pretraining enables more scalable and transferable representations, supporting transfer learning scenarios in resource-limited clinical and cognitive neuroscience settings.
TABLeT's computational efficiency unlocks longer-range modeling for neuroscientific phenomena characterized by slow or widely distributed dynamics, which have been difficult to study with existing architectures.
Limitations and Future Directions
While TABLeT's frame-wise, slice-based tokenization captures spatial structure effectively, it ignores explicit temporal interactions at the tokenization stage. Capturing fine-grained temporal dependencies during tokenization may further enhance performance for highly dynamic tasks. Architectures jointly modeling intra- and inter-token spatial-temporal dependencies, or adopting more brain-compatible spatial token aggregation mechanisms, remain promising future directions. Systematic investigation of which neuroscientific tasks and phenomena most benefit from long-context modeling is also warranted.
Conclusion
TABLeT presents a substantial advance in the efficient modeling of fMRI spatiotemporal dynamics, combining cross-domain feature transfer from natural image-based autoencoders with scalable Transformer architectures and self-supervised pretraining. The work offers not only a practical framework for brain-data modeling under hardware constraints but also key empirical observations regarding cross-domain representation learning for neuroimaging. TABLeT points toward a new class of scalable, interpretable, and transferable models for studying complex brain dynamics.
Figure 7: Validation loss curve demonstrating successful and stable training of the 3D DCAE used for comparative evaluation.