Scaling Vision Transformers for Functional MRI with Flat Maps
Abstract: A key question for adapting modern deep learning architectures to functional MRI (fMRI) is how to represent the data for model input. To bridge the modality gap between fMRI and natural images, we transform the 4D volumetric fMRI data into videos of 2D fMRI activity flat maps. We train Vision Transformers on 2.3K hours of fMRI flat map videos from the Human Connectome Project using the spatiotemporal masked autoencoder (MAE) framework. We observe that masked fMRI modeling performance improves with dataset size according to a strict power scaling law. Downstream classification benchmarks show that our model learns rich representations supporting both fine-grained state decoding across subjects, as well as subject-specific trait decoding across changes in brain state. This work is part of an ongoing open science project to build foundation models for fMRI data. Our code and datasets are available at https://github.com/MedARC-AI/fmri-fm.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computer models to understand brain activity measured by fMRI. The authors turn complex 3D+time fMRI data into simple 2D “flat maps” (like unfolding the surface of the brain), then train a type of AI called a Vision Transformer to learn patterns from these maps. They show that as you give the model more data, it gets better in a predictable way, and it learns useful features that can help with different brain-related tasks.
Key Questions
The paper asks three main questions, in simple terms:
- How can we best “format” fMRI data so modern AI models can learn from it?
- If we train on a lot of fMRI data, does the model steadily and predictably get better?
- Do the learned features help with practical tasks, like recognizing what a person is doing or identifying traits across different brain states?
Methods and Approach (explained simply)
What is fMRI?
- fMRI is a way to measure brain activity by tracking changes in blood flow. It produces a 3D picture of the brain every 1–2 seconds over time, so it’s like a 3D movie of the brain.
Making “flat maps” of the brain
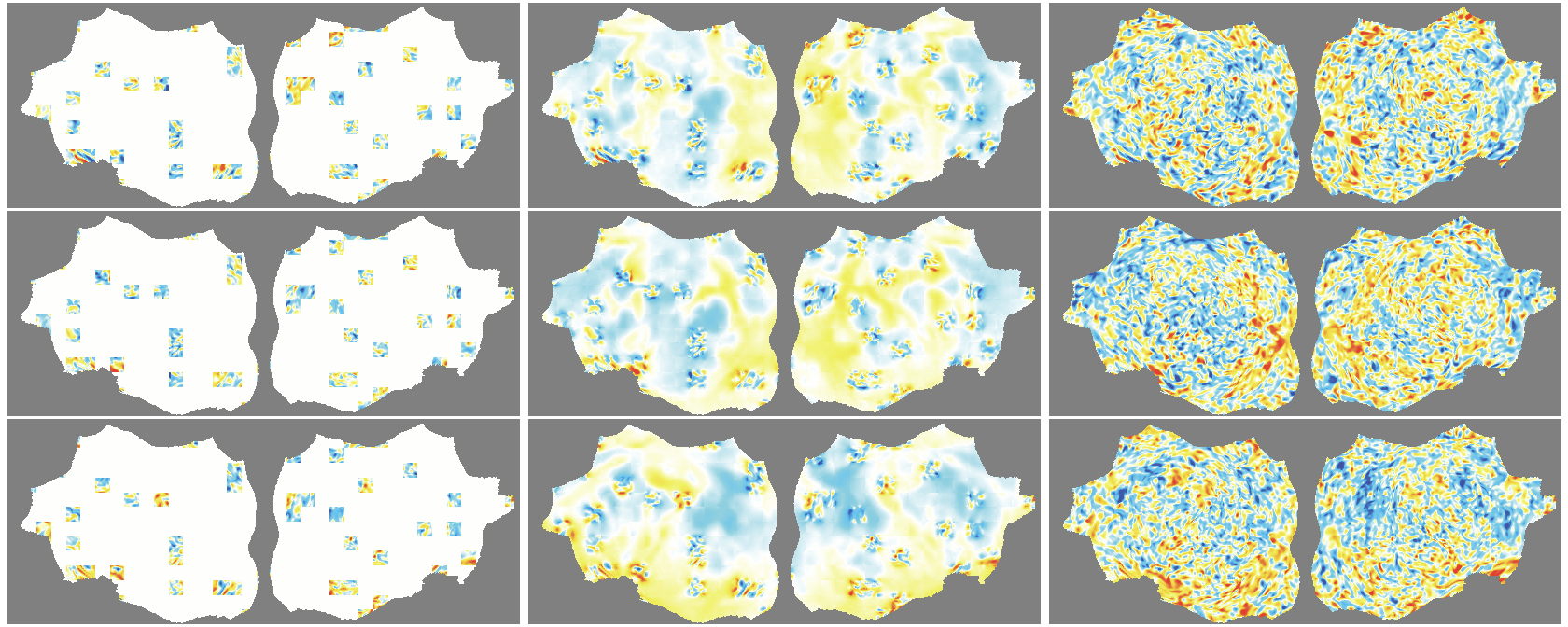
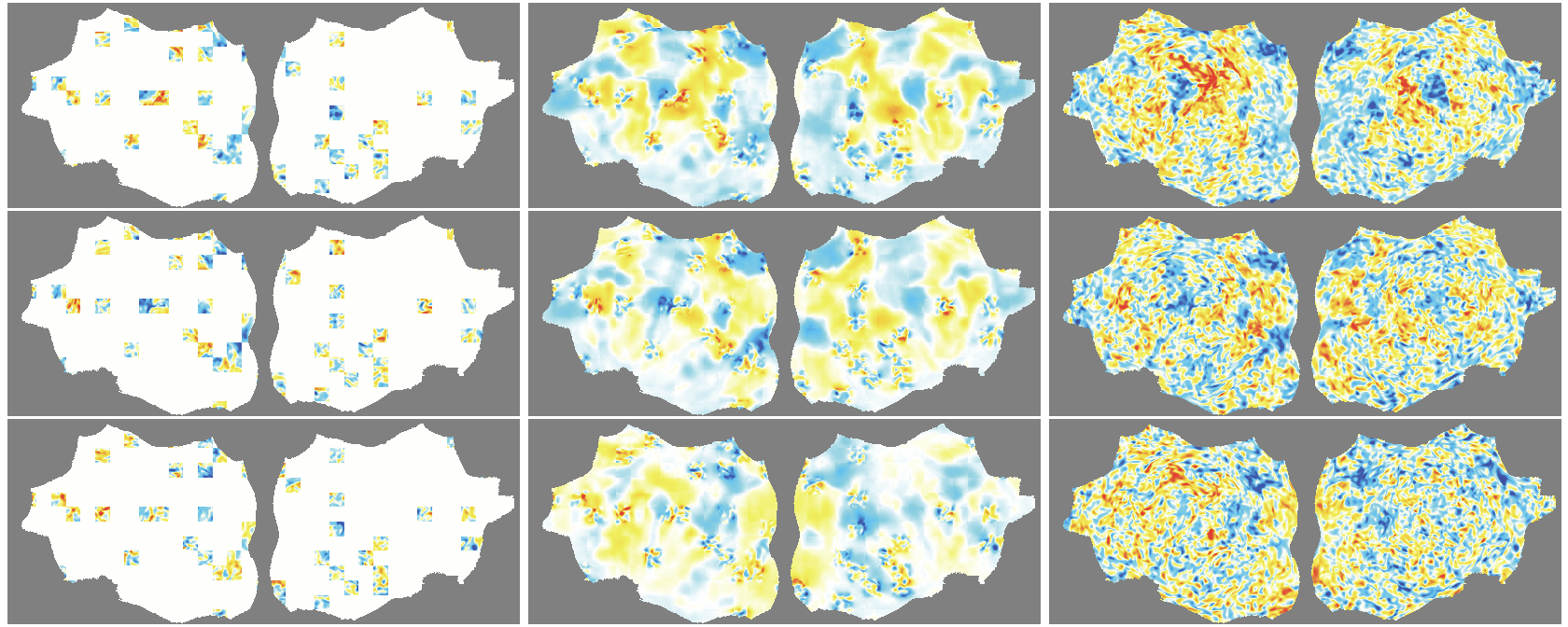
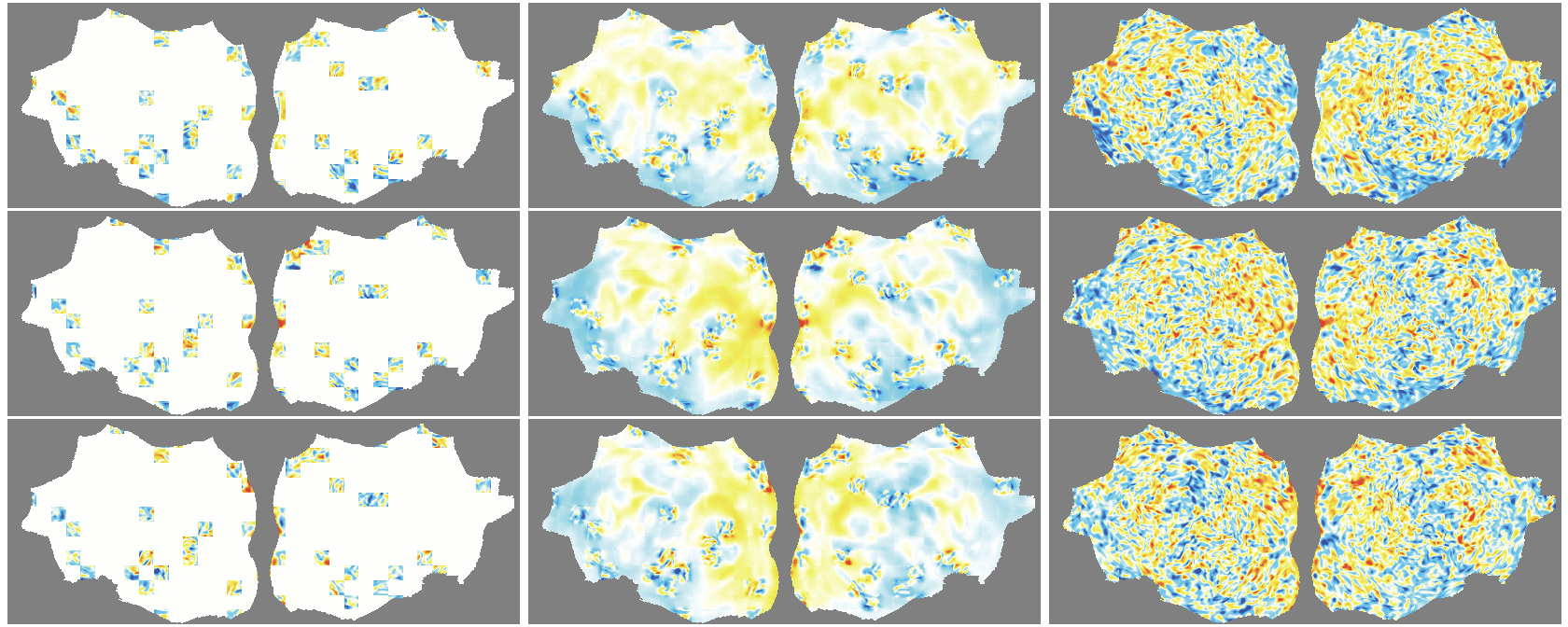
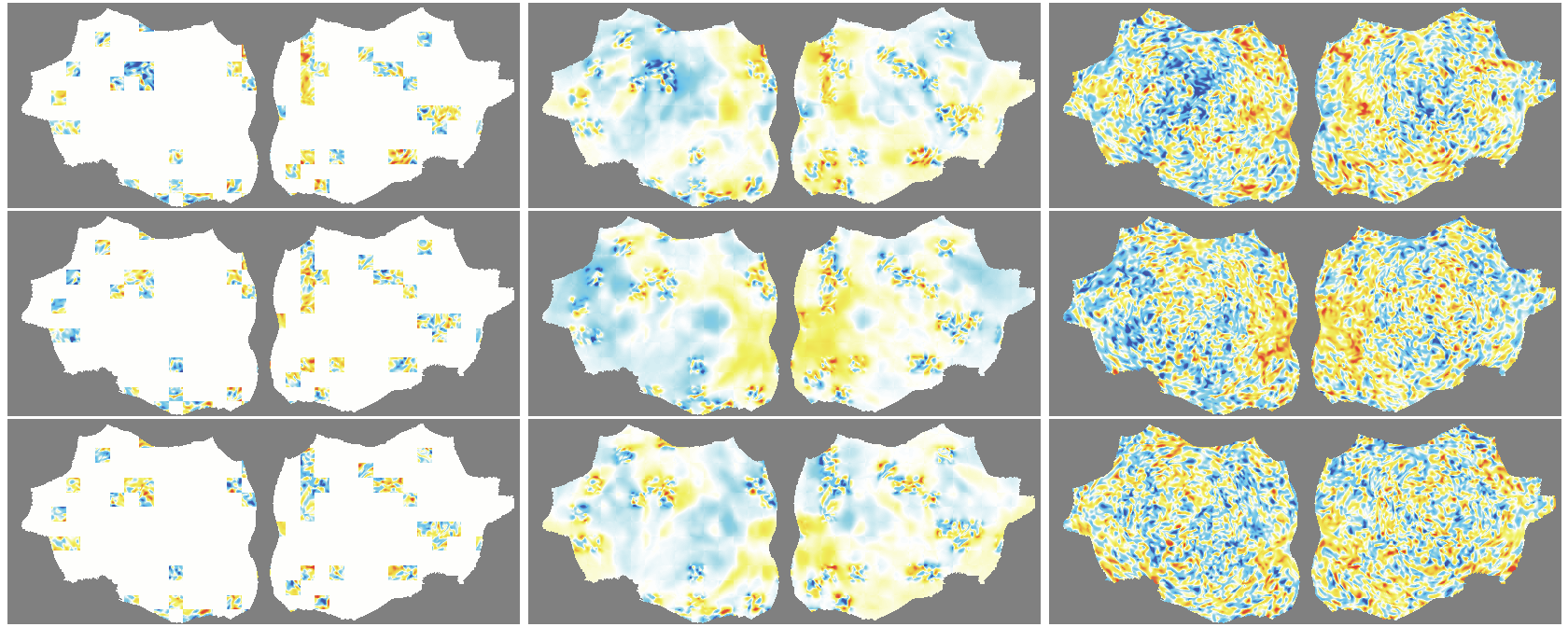
- The outer layer of your brain (the cortex) is folded, like a crumpled sheet. The authors “unfold” this sheet and lay it flat, turning each time point of the fMRI into a 2D image. Imagine peeling an orange and flattening the peel into a map.
Using Vision Transformers and Masked Autoencoders
- A Vision Transformer (ViT) is an AI model originally made for images. It looks at small squares (“patches”) of an image and learns how they relate.
- A Masked Autoencoder (MAE) is trained like a puzzle game: you hide most of the patches (around 90%), and the model must guess the missing parts from the few patches it sees. This trains the model to understand the structure and patterns in the data without needing labels.
- Because fMRI is a movie over time, they use “spacetime patches” that cover both space (image) and time (frames), and they mask patches in tubes over time so the model can’t just copy from neighboring frames.
- They also skip patches that are just empty background and only compute loss on real brain pixels.
Data and Training
- They use a big public dataset called the Human Connectome Project (HCP): 2,291 hours from 1,096 people, resulting in 8.2 million flat-map frames.
- The model is trained to reconstruct the masked patches. After training, they keep the encoder (the part that learns features) and throw away the decoder.
- To test usefulness, they freeze the encoder and add a small “attentive probe” (a lightweight classifier) to do different tasks.
Tasks to Check What It Learned
- HCP cognitive state decoding: guess which of 21 tasks/states a person is in (like different mental activities).
- UK Biobank sex classification: classify male vs female using brain scans.
- NSD CLIP label classification: people watched natural images; from their brain activity, predict an overall label like “photo of dog.” This is harder and out-of-distribution (different dataset than training), and tested on an unseen subject.
Baselines (for comparison)
- Connectome baseline: summarize brain activity by regions and use a simple classifier.
- Patch embedding baseline: embed patches without MAE pretraining and classify with an attentive probe.
Main Findings and Why They Matter
- Predictable improvement with more data: When trained on larger amounts of HCP data, the model’s reconstruction error drops following a strict “power law” (performance improves in a steady, math-defined way). This is a hallmark of strong foundation models.
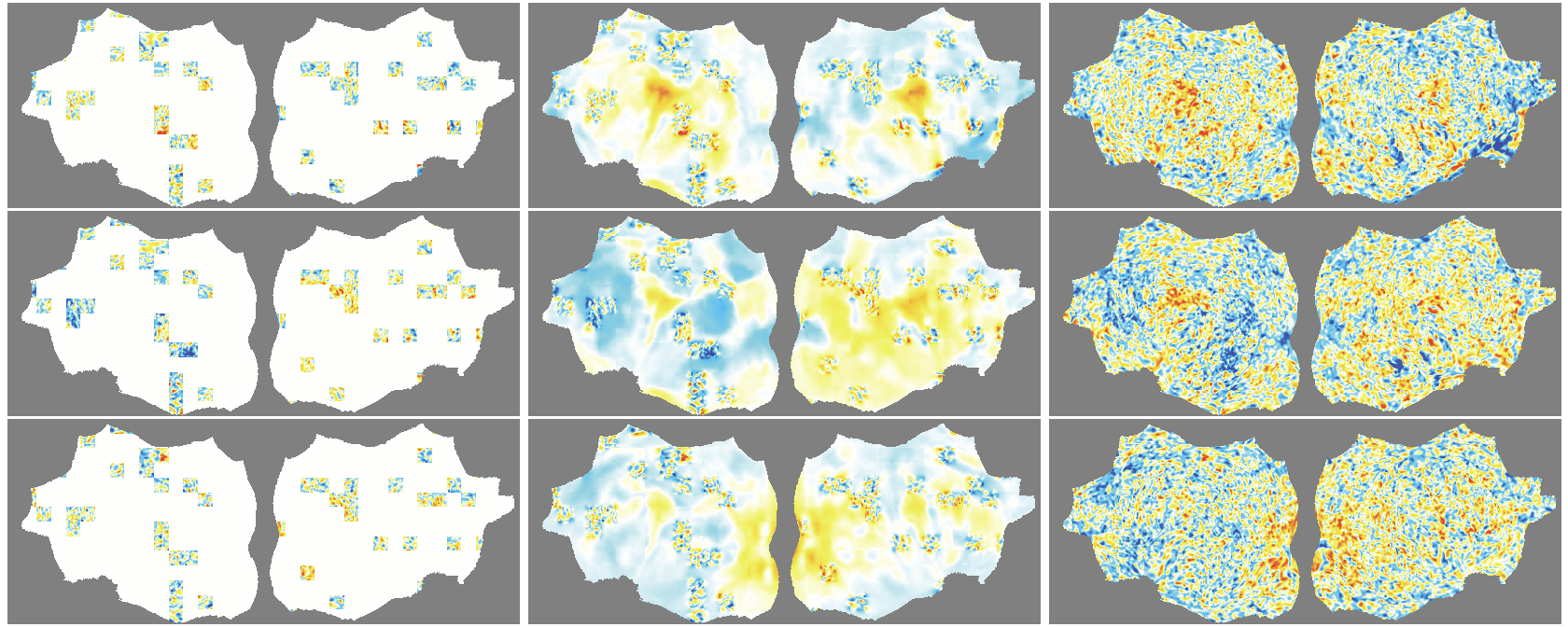
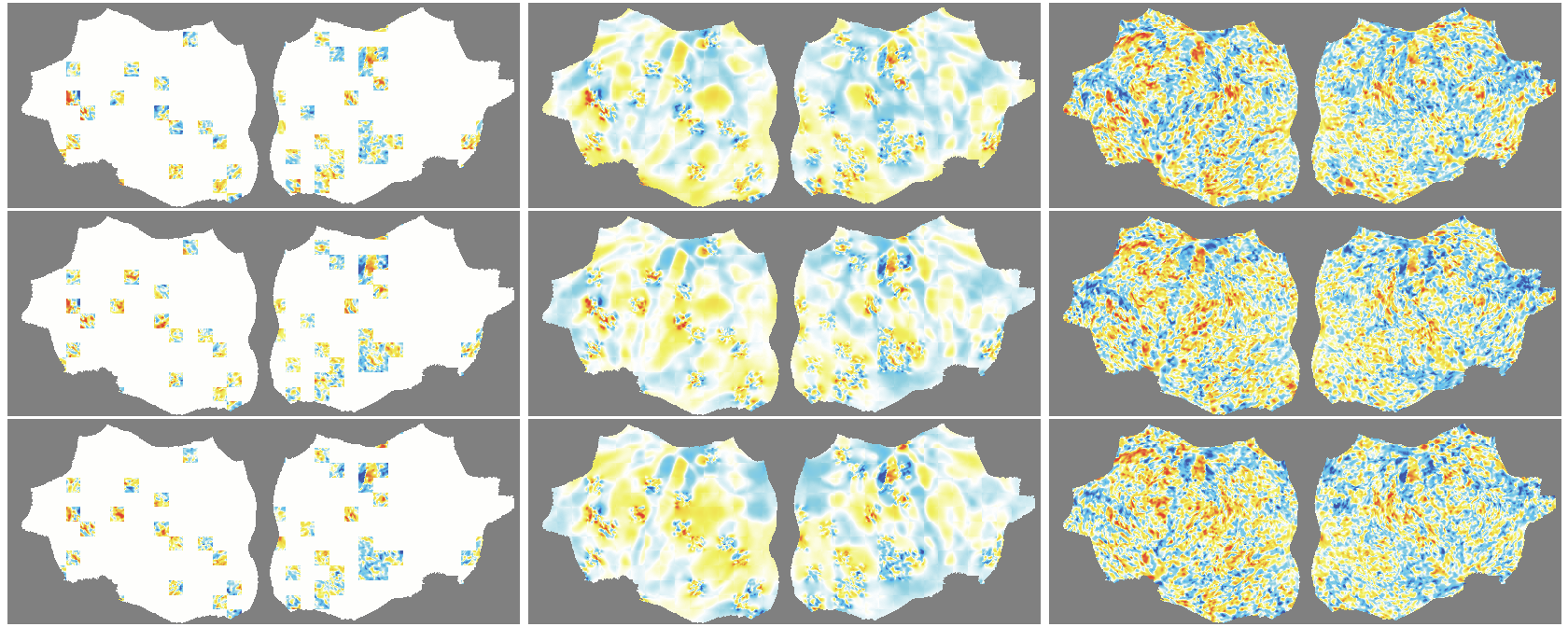
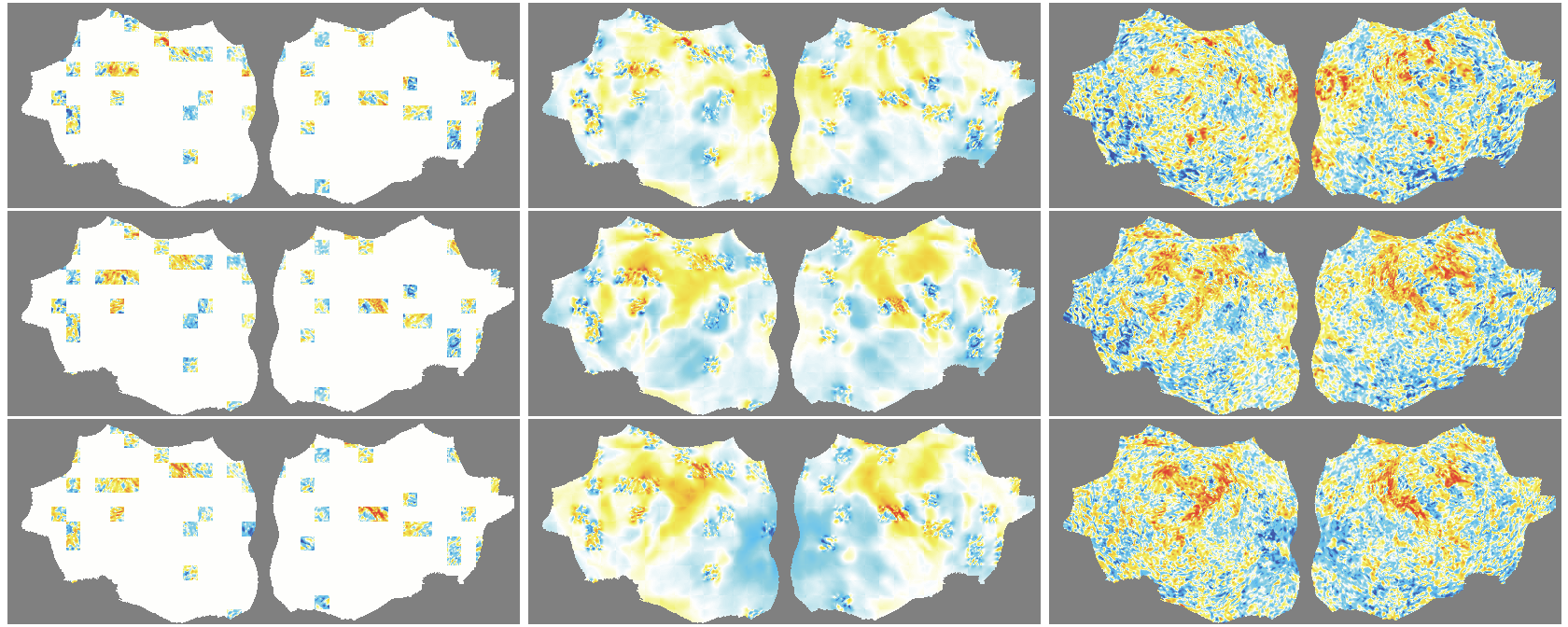
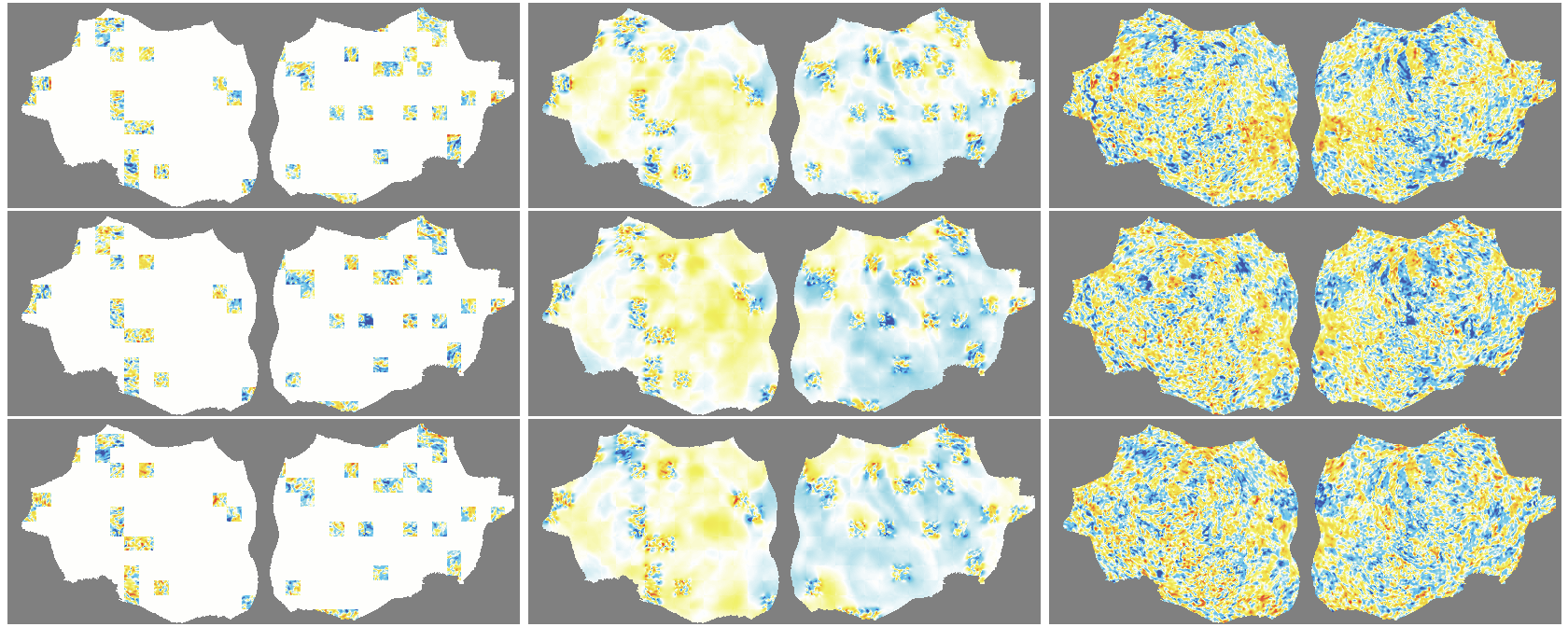
- Denoising effect: The model reconstructs smooth, structured signals and doesn’t try to recreate random noise—useful for cleaning fMRI data.
- Generalization limits: On a very different dataset (NSD), performance improves with more HCP data but starts to slow, suggesting you need more diverse training data to generalize widely.
- Strong downstream performance:
- HCP state decoding: The MAE-based model reaches about 98.8% accuracy, higher than previous reports using similar setups.
- UK Biobank sex classification: About 84.6% accuracy with only short 16-second clips and a frozen encoder, approaching past specialized models that used longer scans and fine-tuning.
- NSD CLIP labels: Over 8× better than chance and more than 2× better than baselines on an unseen subject from a different dataset—promising for cross-subject visual decoding.
- Smaller can be better: A relatively small model (about 12 million parameters) performed about as well as a much larger one, and the largest model did worse—suggesting efficient models may be enough.
- Finer temporal patches help: Using smaller time patches (more tokens per input) improves accuracy, similar to known trade-offs in vision transformers.
Implications and Impact
- Bridge to image-based AI: Turning fMRI into 2D flat maps lets you use powerful image/video AI models directly on brain data, without losing important details.
- Foundation models for brain data: The strict scaling law shows that building large, general-purpose models for fMRI is feasible. As data grows and becomes more diverse, these models should get reliably better.
- Practical uses: Better brain representations could help decode mental states, study individual differences, and support future clinical tools for brain and mental health.
- Open science: The authors share code and datasets, inviting others to build on this work. Next steps include adding more diverse data, testing alternative methods, and expanding benchmarks.
Overall, this work suggests a clear path toward robust, general AI models that understand brain activity: represent the cortex as flat maps, train with masked reconstruction on large datasets, and use the learned features for many downstream tasks.
Knowledge Gaps
Below is a single, concise list of the paper’s main knowledge gaps, limitations, and open questions. Each point is concrete enough to guide follow-up work.
- Quantify how the flat-map representation compares to parcellation-based and native 4D volumetric tokenizations under matched compute, data, and training budgets (accuracy, sample efficiency, OOD generalization, and robustness).
- Characterize geometric distortions introduced by cortical flattening and image-grid resampling (e.g., geodesic vs Euclidean distances, local area distortions) and their impact on learned spatial inductive biases and functional network topology.
- Extend the representation to include subcortical and cerebellar signals (currently omitted) and evaluate how their inclusion affects downstream tasks (e.g., sex classification) and generalization.
- Ablate preprocessing choices—surface template alignment, TR resampling to 1s, per-vertex z-scoring, per-frame z-scoring/global signal normalization—and measure their effects on both pretraining loss and downstream performance.
- Test sensitivity to the choice of group template (fsaverage vs fsLR), cross-subject alignment quality, and functional alignment methods (e.g., hyperalignment/MindAligner) to reduce inter-subject variability in the flat-map domain.
- Explore geometry-aware position embeddings (e.g., mesh/geodesic-aware encodings) or mesh-native tokenization instead of square image patches to better respect cortical topology.
- Systematically vary and report spatial patch size, patch overlap, token count, and mask ratio (beyond temporal size) to map speed/accuracy trade-offs and their interaction with fMRI noise characteristics.
- Compare MAE to alternative SSL objectives tailored to fMRI (e.g., contrastive/DINOv2, JEPA/CLIP-style joint embedding, cluster-predict masked modeling) and different decoder capacities; identify which objectives best translate to downstream gains.
- Establish compute-optimal scaling laws by jointly varying dataset size, model size, training steps, and optimizer/hyperparameters; estimate exponents and verify stability across seeds and datasets.
- Test whether data diversity (across tasks, rest/movie paradigms, scanners, field strengths, clinical cohorts) alleviates the OOD reconstruction saturation seen for NSD; quantify the role of diversity vs sheer scale.
- Measure the relationship between masked reconstruction loss improvements and downstream probe performance to diagnose pretext–target mismatch (e.g., are we optimizing a denoising objective that plateaus for decoding?).
- Evaluate fine-tuning strategies (full/partial, adapters, LoRA) vs frozen attentive probes, including few-shot/multi-task adaptation, to quantify the headroom unlocked by updating the encoder on target tasks.
- Assess robustness to domain shifts (scanner, field strength 3T vs 7T, TR variability, motion, physiological noise) and implement domain adaptation (e.g., test-time adaptation, invariance penalties).
- Quantify subject identity leakage and demographic confounds (e.g., fingerprinting, head/vascular differences), and evaluate fairness/bias across sex, age, and site with controlled analyses.
- Report statistical uncertainty (CIs, multiple seeds), calibration, and significance testing for all benchmarks to support reliable comparisons and reproducibility claims.
- Interpret learned features: analyze attention maps, token saliency, and network-level representations; test alignment to known cortical systems (e.g., Yeo networks) and task-evoked patterns for neuroscientific validity.
- Investigate longer temporal contexts and different temporal encoding schemes (causal vs bidirectional, continuous-time embeddings) beyond 16 s clips; study how sequence length affects temporal integration and decoding.
- Compare tube masking to alternative spatiotemporal masking strategies (random, block, dual masking from VideoMAE v2) and quantify their influence on both reconstruction and OOD transfer.
- Examine the impact of excluding “empty” background patches on positional biases and learning dynamics; test alternative losses that down-weight background rather than removing patches entirely.
- Provide detailed compute/memory benchmarks (training/inference time, GPU hours, throughput) and practical scalability analyses as patch size and token count vary.
- Standardize evaluation protocols and splits to enable apples-to-apples SOTA comparisons (especially for HCP and UKBB); assess cross-dataset generalization rather than in-distribution performance alone.
- Strengthen the NSD-CLIP benchmark: validate label assignment quality, include top-k/retrieval metrics, and compare against cross-subject alignment baselines (e.g., hyperalignment) and image–feature regression approaches.
- Investigate uncertainty estimation and calibration (e.g., temperature scaling, Bayesian heads) for clinically relevant tasks; define thresholds for safe deployment and misclassification analysis.
- Clarify release of pretrained weights, training scripts, and derived flat-map datasets (licensing, harmonization steps) to facilitate reproducibility and community benchmarking.
- Explore cross-modal pretraining (e.g., text/behavioral labels, natural-language supervision) to move toward true “foundation” capabilities that generalize across tasks and modalities.
- Study how MAE’s implicit denoising interacts with fMRI-specific noise (physiological/motion) and whether it suppresses clinically relevant signal; include controlled simulations and real-data ablations.
Practical Applications
Overview
This paper introduces a practical way to adapt modern computer vision architectures to functional MRI (fMRI) by converting 4D volumetric data into videos of 2D cortical “flat maps” and training spatiotemporal masked autoencoders (MAEs) based on Vision Transformers (ViTs). The authors demonstrate strict power-law scaling of masked-reconstruction performance with data size, strong downstream decoding (e.g., near-ceiling task-state classification), useful speed/accuracy trade-offs via patch size control, and promising cross-subject/out-of-distribution generalization. These findings and methods enable concrete applications across sectors.
Immediate Applications
The following items describe applications that can be deployed now with the paper’s code, data, and approach, given typical institutional computing resources and standard fMRI pipelines.
- Task compliance and cognitive state QA for fMRI experiments (Healthcare, Academia, Software)
- Use case: Real-time or post-hoc monitoring of whether participants are in the intended cognitive state during task scans (e.g., verifying attention or task engagement).
- Tools/workflow: Flat-map conversion (surface-based preprocessing + pycortex), fm-MAE encoder to extract embeddings, “attentive probe” classifier for 21-state decoding; integrate as a QA module in fMRI labs or hospital research units.
- Assumptions/dependencies: Surface-preprocessed data (e.g., HCP-style pipelines), adequate GPU for inference, adherence to TR normalization; applicability strongest for in-distribution protocols.
- Implicit denoising and quality control of fMRI data (Healthcare, Imaging Software Vendors)
- Use case: Reduce unstructured noise and flag artifacts by comparing masked-reconstruction outputs to raw data; triage low-quality scans or motion-contaminated frames.
- Tools/workflow: fm-MAE reconstruction as an “implicit denoiser,” framewise reconstruction error as a QC metric; plugin for
fMRIPrep, FreeSurfer/FSL-based workflows. - Assumptions/dependencies: Proper masking of background patches; denoising should be audited to avoid “hallucination” of structure (risk of spurious reconstruction).
- Low-label transfer learning for new decoding tasks (Academia, Neurotech R&D)
- Use case: Build classifiers for novel task states or simple phenotypes (e.g., sex classification) with minimal labeled data by freezing the fm-MAE encoder and training an attentive probe.
- Tools/workflow: Pretrained fm-MAE encoders; frozen features + lightweight probe; small curated labeled datasets (tens of thousands of clips).
- Assumptions/dependencies: Domain shifts reduce performance; small models suffice (12M parameters perform well), but cross-dataset diversity matters.
- Naturalistic vision experiment support via zero-shot semantic decoding (Academia, Media/Neuromarketing)
- Use case: Evaluate responses to complex natural scenes; approximate semantic labels (e.g., “photo of dog”) from fMRI with limited subject-specific data.
- Tools/workflow: NSD-like pipeline; CLIP label sets; fm-MAE features + attentive probe for label prediction; per-subject alignment where feasible.
- Assumptions/dependencies: Out-of-distribution generalization is moderate; labels are coarse and ambiguous; requires careful interpretation.
- Speed/accuracy tuning for fMRI inference (Healthcare IT, Software)
- Use case: Adjust temporal patch size to trade accuracy for throughput depending on clinical/research needs and GPU budget.
- Tools/workflow: Patch size as a runtime parameter (e.g., smaller p_t → more tokens → higher accuracy at higher compute cost).
- Assumptions/dependencies: Robustness validated for short clips (~16s); broader temporal windows may be needed for specific phenotypes.
- Standardized flat-map tokenization for cross-study comparability (Academia, Standards Bodies)
- Use case: Adopt the 2D flat-map representation to retain cortical fidelity while enabling vision-model tooling; improve reproducibility across labs.
- Tools/workflow: Surface-based preprocessing, pycortex flattening, fixed-resolution grids (e.g., 224×560), standardized masking of empty patches.
- Assumptions/dependencies: Cortex-focused signal; subcortical activity is less represented; consistent templates (fsLR/fsaverage) and resampling choices affect comparability.
- Compute planning and dataset scaling strategy (R&D Management, Policy)
- Use case: Use observed scaling laws to plan data collection and compute budgets; prioritize data diversity over sheer volume when targeting OOD generalization.
- Tools/workflow: Learning curves and power-law fits; sensitivity analyses by model size and patch size.
- Assumptions/dependencies: Current scaling is shown for HCP-like data; generalization requires broader populations and sites.
Long-Term Applications
The following applications are feasible but require further research, data diversity, validation, and/or regulatory pathways before deployment.
- Clinical decision support for precision psychiatry and neurology (Healthcare, Policy)
- Use case: Predict clinically relevant phenotypes (e.g., depression subtypes, early neurodegeneration, treatment response) from fMRI embeddings; aid diagnosis and care pathways.
- Tools/workflow: Diverse pretraining across multi-site clinical datasets; fine-tuned decoders with calibrated uncertainty; integration with EHR and structured reports.
- Assumptions/dependencies: Regulatory approval (medical device software), large representative datasets, careful handling of confounds (global signal, site effects), fairness and bias audits.
- General-purpose cross-subject visual decoding and communication aids (Healthcare, Neurotech, Assistive Tech)
- Use case: Robust brain-to-image or brain-to-semantic decoding across subjects for assistive communication (e.g., locked-in patients).
- Tools/workflow: fm-MAE + cross-subject alignment frameworks; multimodal priors (e.g., CLIP, diffusion models); per-patient calibration workflows.
- Assumptions/dependencies: Ethical safeguards and consent; high-field fMRI or alternative modalities; sustained validation on OOD subjects; latency constraints.
- Closed-loop neurofeedback and neuromodulation guided by foundation embeddings (Healthcare, Robotics/BCI)
- Use case: Real-time estimation of cognitive states to drive neurofeedback, TMS/tDCS targeting, or adaptive therapy.
- Tools/workflow: Low-latency embeddings from fm-MAE; real-time pipelines; control algorithms using state classifiers.
- Assumptions/dependencies: fMRI latency and cost limit routine use; translation to faster modalities (EEG/MEG/fNIRS) via cross-modal distillation likely required.
- Multimodal “brain-and-body” foundation models (Healthcare, Wearables, Software)
- Use case: Unified embeddings from fMRI, structural MRI, EEG/MEG, fNIRS, physiology; longitudinal health tracking and risk prediction.
- Tools/workflow: Cross-modal pretraining (JEPA/contrastive/MAE hybrids); standardized BIDS + flat-map conventions; deployment as an embedding service (“fmri-fm-as-a-service”).
- Assumptions/dependencies: Data harmonization across modalities and sites; robust domain adaptation; scalable privacy-preserving training.
- Automated protocol optimization and scan triage (Healthcare Operations, Imaging Vendors)
- Use case: Use reconstruction losses and embedding stability to auto-adjust acquisition parameters, recommend rescans, or flag when diagnostic utility is compromised.
- Tools/workflow: On-scanner QC inference modules; feedback to technologists; dashboards for radiology QA.
- Assumptions/dependencies: Vendor integration; prospective trials; generalization across scanner models and sequences.
- Population-level neuroepidemiology and policy planning (Policy, Public Health)
- Use case: Aggregate embeddings across cohorts to track population brain health, inform mental health services, and guide funding/priorities.
- Tools/workflow: Secure federated analysis; embedding-level meta-analyses; bias and privacy controls (differential privacy).
- Assumptions/dependencies: Governance frameworks for brain data; standardized consent for foundation-model reuse; cross-country data-sharing agreements.
- Personalized “brain fingerprinting” for authentication and forensics (Finance/Security, Policy)
- Use case: Identity verification via functional connectivity or fm-MAE embeddings.
- Tools/workflow: Fingerprint extraction pipelines; match-scoring systems.
- Assumptions/dependencies: Significant ethical, legal, and privacy concerns; risk of misuse; unlikely to be acceptable without stringent regulation.
- Education and workforce development (Academia, Training)
- Use case: Curricula and hands-on labs using open code/datasets to train practitioners in neuro-AI foundation models.
- Tools/workflow: Course modules around flat-map tokenization, MAE pretraining, attentive probes; reproducible notebooks; cloud credits.
- Assumptions/dependencies: Continued open-science support; stable hosting of datasets and models.
- Commercial neuroimaging SDKs and plugins (Software, Imaging Vendors)
- Use case: Productize flat-map MAE encoders and probes as SDKs for third-party neuroimaging suites.
- Tools/workflow: APIs for embedding extraction, QC scoring, decoding services; configurable patch sizes and model variants for edge GPUs.
- Assumptions/dependencies: Ongoing model maintenance; customer datasets may require domain adaptation; support for diverse preprocessing pipelines.
- Ethical and regulatory frameworks for brain foundation models (Policy, Standards)
- Use case: Standards for tokenization (flat-map conventions), risk management for decoding capabilities, transparency, and auditability requirements.
- Tools/workflow: BIDS extensions for flat maps; model cards; dataset documentation; bias/robustness benchmarks.
- Assumptions/dependencies: Multistakeholder consensus; harmonization with medical device and AI regulations; enforcement mechanisms.
Cross-cutting assumptions and dependencies
- Reliance on surface-based preprocessing (e.g., FreeSurfer/FSL/fMRIPrep) and consistent cortical templates (fsLR/fsaverage).
- The flat-map focus emphasizes cortical signals; subcortical coverage may need complementary approaches.
- OOD generalization hinges on data diversity across sites, populations, and tasks; current HCP-trained models show saturation on some OOD sets.
- Masked-autoencoder denoising can smooth noise but must be safeguarded against spurious reconstructions; clinical use requires rigorous validation.
- Practical deployment benefits from smaller models (12M parameters) and tunable patch sizes; hospital GPUs can likely handle inference on short clips.
- Privacy, consent, and ethical considerations are paramount for any decoding of mental content or identity-related features.
Glossary
- 4D convolution: A convolution over three spatial dimensions plus time, used to process fMRI volumes as 4D signals. "use an initial 4D convolution to transform the high-resolution 4D time series to a lower resolution 4D grid of embedding vectors"
- attentive probe: A lightweight classifier that pools sequence features via cross-attention with a learned query, used to evaluate frozen encoder representations. "We use an attentive probe to evaluate the quality of our learned representations"
- brain parcellation: Dividing the brain into predefined regions to aggregate signals and reduce dimensionality for analysis. "from a standard brain parcellation"
- connectome: The network of brain connections, often represented via functional connectivity for modeling or classification. "The first is a connectome baseline"
- cortical folding: The pattern of gyri and sulci in the cortex that constrains spatial organization and functional mapping. "localization of fMRI signal to gray matter, cortical folding, anatomical and functional networks"
- cortical surface mesh: A tessellated representation of the cortical surface onto which fMRI signals are mapped for surface-based analysis. "mapped to a group template cortical surface mesh (e.g.\ fsaverage, fsLR)"
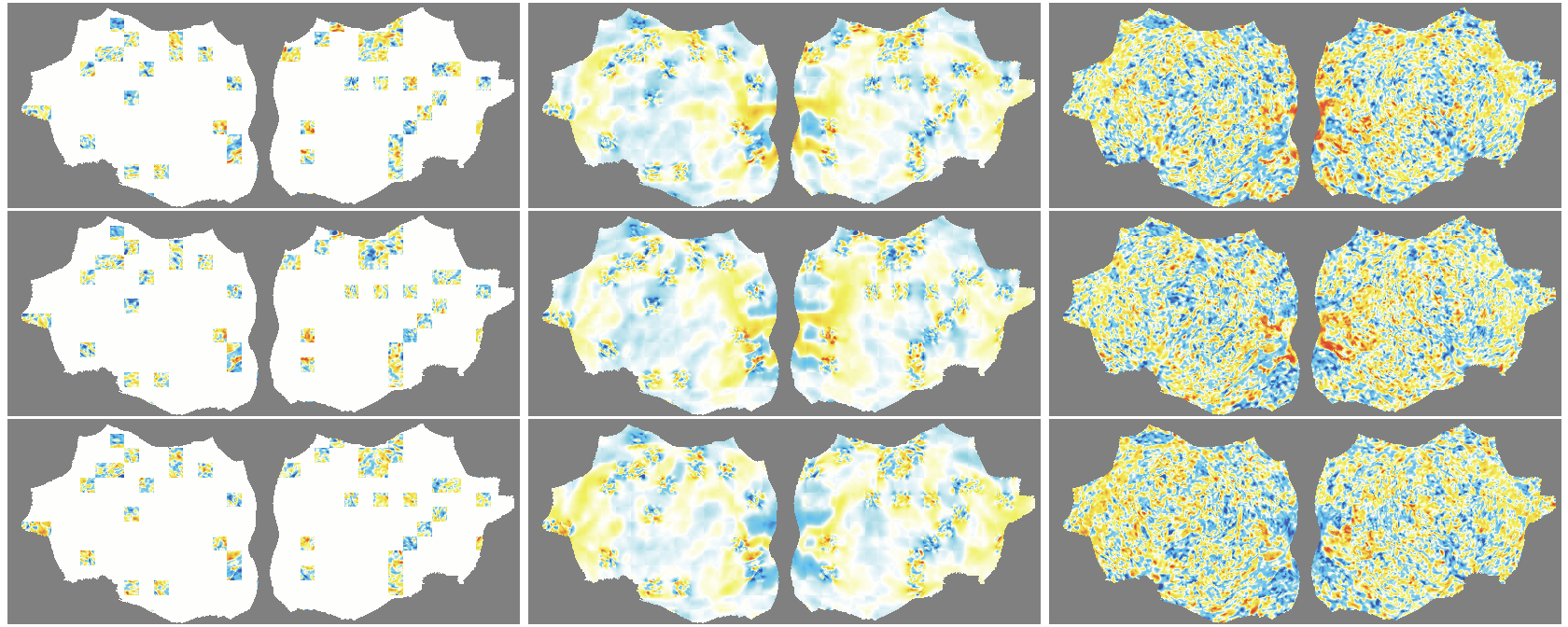
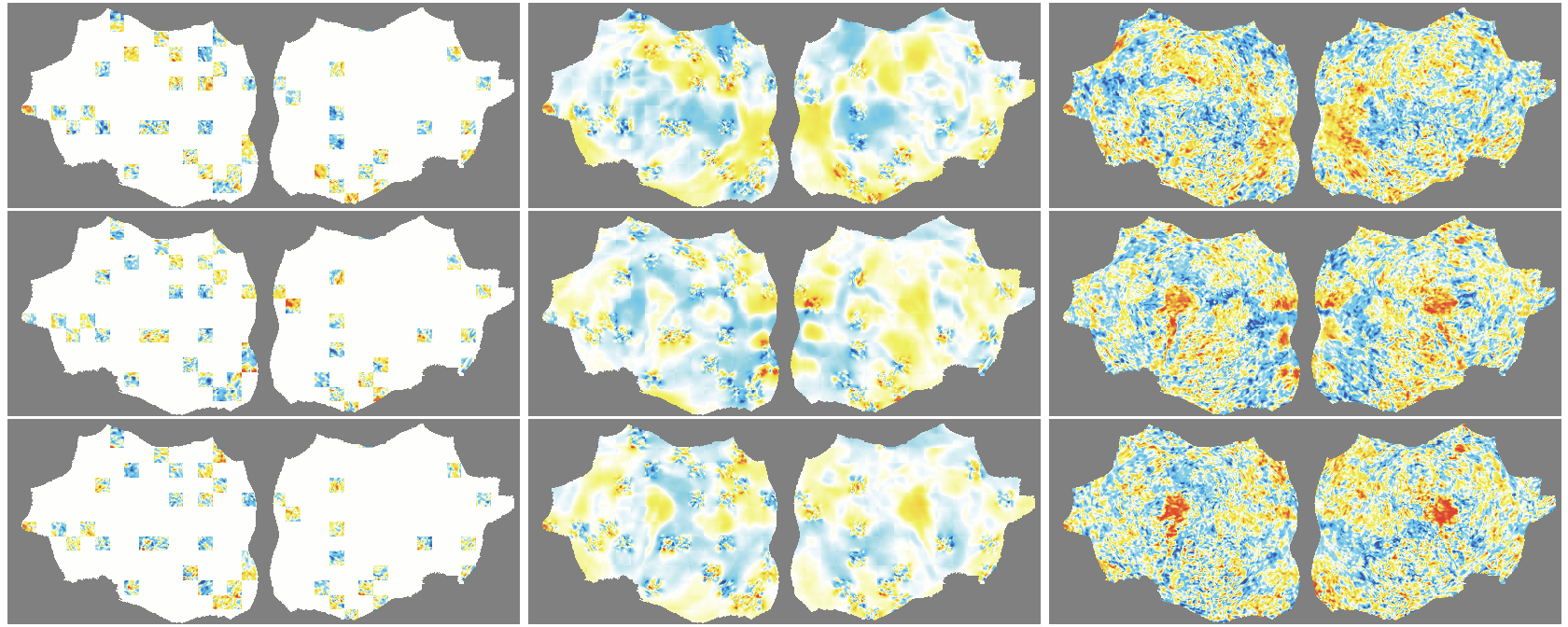
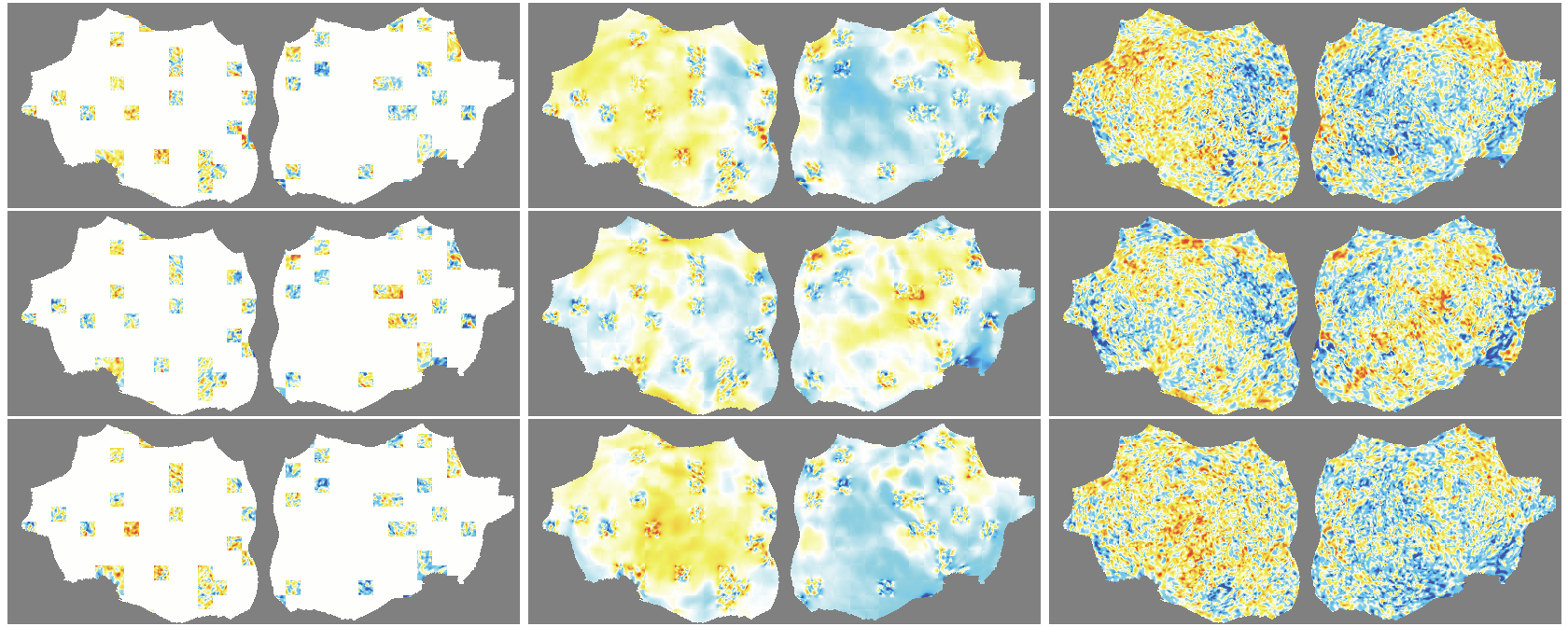
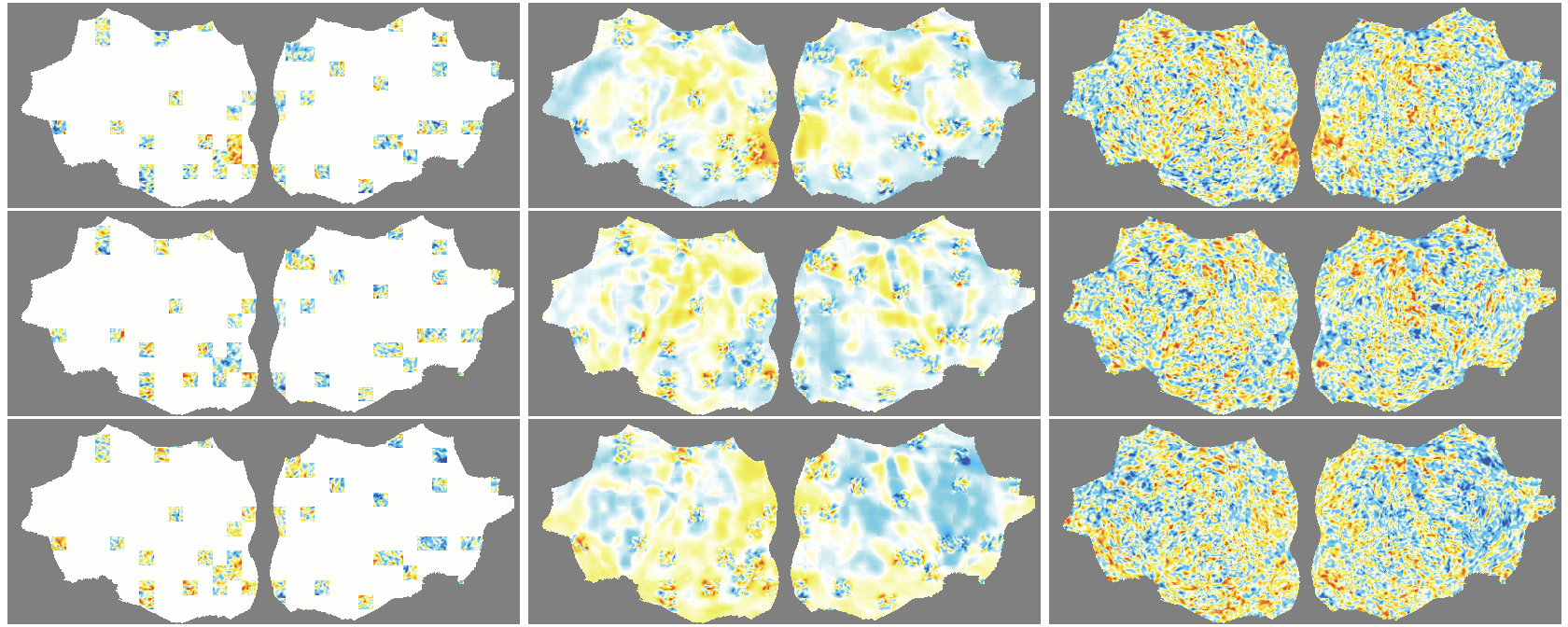
- flat map: A 2D representation of cortical activity obtained by flattening the cortical surface for image-like modeling. "We transform the 4D volumetric fMRI data into videos of 2D fMRI activity flat maps."
- foundation model: A large, flexible model trained with self-supervision on broad data, producing transferable representations across tasks. "There is growing interest in training foundation models on large-scale fMRI data"
- functional connectivity matrix: A matrix quantifying statistical dependencies (e.g., correlations) between brain regions over time. "we compute a functional connectivity matrix using the Schaefer 400 parcellation"
- functional MRI (fMRI): A neuroimaging technique measuring brain activity indirectly via blood-oxygen-level dependent signals. "Functional MRI (fMRI) exploits properties of nuclear magnetic resonance to record a noisy 3D map of a person's brain activity"
- global signal variation: Whole-brain fMRI fluctuations that can confound analyses and are often normalized away. "To reduce global signal variation \cite{Power2017}, we further normalize each frame to zero mean unit variance across the spatial grid."
- gray matter: Cortical tissue rich in neuronal cell bodies where most fMRI signal is localized. "localization of fMRI signal to gray matter"
- Human Connectome Project (HCP): A large public dataset of human brain imaging used for pretraining and evaluation. "We pretrain our flat map MAE (fm-MAE) using 2.3K hours of publicly available preprocessed fMRI data from the Human Connectome Project (HCP)"
- inductive bias: Built-in modeling assumptions that guide learning toward plausible solutions or structures. "leveraging the inductive bias that local cortical neighborhoods are functionally integrated."
- local window attention: A transformer mechanism limiting attention to local neighborhoods in space-time to reduce computation. "input to a transformer encoder with local window attention"
- masked autoencoder (MAE): A self-supervised model that reconstructs masked portions of inputs from visible parts. "we adopt the spatiotemporal masked autoencoder (MAE) framework"
- masking ratio: The fraction of input tokens or patches that are masked during MAE pretraining. "We use a default masking ratio of 0.9 (48 visible patches per sample)."
- Natural Scenes Dataset (NSD): A 7T fMRI dataset of subjects viewing natural images, used as an evaluation benchmark. "We also implement a new CLIP classification benchmark using the Natural Scenes Dataset (NSD)"
- out-of-distribution (OOD): Data that differ from the training distribution, used to assess generalization. "NSD validation set (out-of-distribution)"
- patch embedding: A learned mapping from image patches (with positional information) to tokens for transformer input. "The second is a patch embedding baseline."
- patchified: Divided into non-overlapping square patches for tokenization and transformer processing. "temporal sequences of ``patchified'' flat maps"
- position embedding: Learned vectors encoding spatial and temporal positions of tokens in sequence models. "the learned ViT position embedding is factorized into temporal plus spatial components"
- pycortex: A Python tool for surface-based visualization and flat-map generation of fMRI data. "created by pycortex"
- regions of interest (ROIs): Predefined brain areas used to aggregate signals or features for analysis. "non-overlapping regions of interest (ROIs)"
- repetition time (TR): The time between successive fMRI volume acquisitions, setting temporal resolution. "resampling to a fixed repetition time (TR) of 1s."
- scaling law: A power-law relationship between dataset size and performance in model training. "obeys a strict power law relationship (i.e. ``scaling law'') with dataset size."
- Schaefer 400 parcellation: A specific cortical parcellation dividing the cortex into 400 regions. "using the Schaefer 400 parcellation"
- spatiotemporal masked autoencoder (MAE): An MAE variant operating over space and time (videos) using spacetime patches. "we adopt the spatiotemporal masked autoencoder (MAE) framework"
- tube masking: A VideoMAE strategy masking continuous tubes across time to avoid trivial temporal interpolation. "we adopt tube masking from VideoMAE"
- Vision Transformer (ViT): A transformer architecture for images/videos that operates on patch tokens. "We train Vision Transformers on 2.3K hours of fMRI flat map videos"
Collections
Sign up for free to add this paper to one or more collections.

