- The paper presents VisionClaw, an innovative system that fuses always-on egocentric multimodal sensing with autonomous task execution on smart glasses, achieving up to 37% task time reduction.
- The system employs a layered architecture combining real-time audio-video processing through Gemini Live with agentic control via OpenClaw for seamless digital interactions.
- Experimental studies indicate significant improvements in usability and reduced cognitive load, while also highlighting challenges in privacy and user trust.
VisionClaw: Always-On, Multimodal, Agentic AI via Smart Glasses
System Architecture and Design
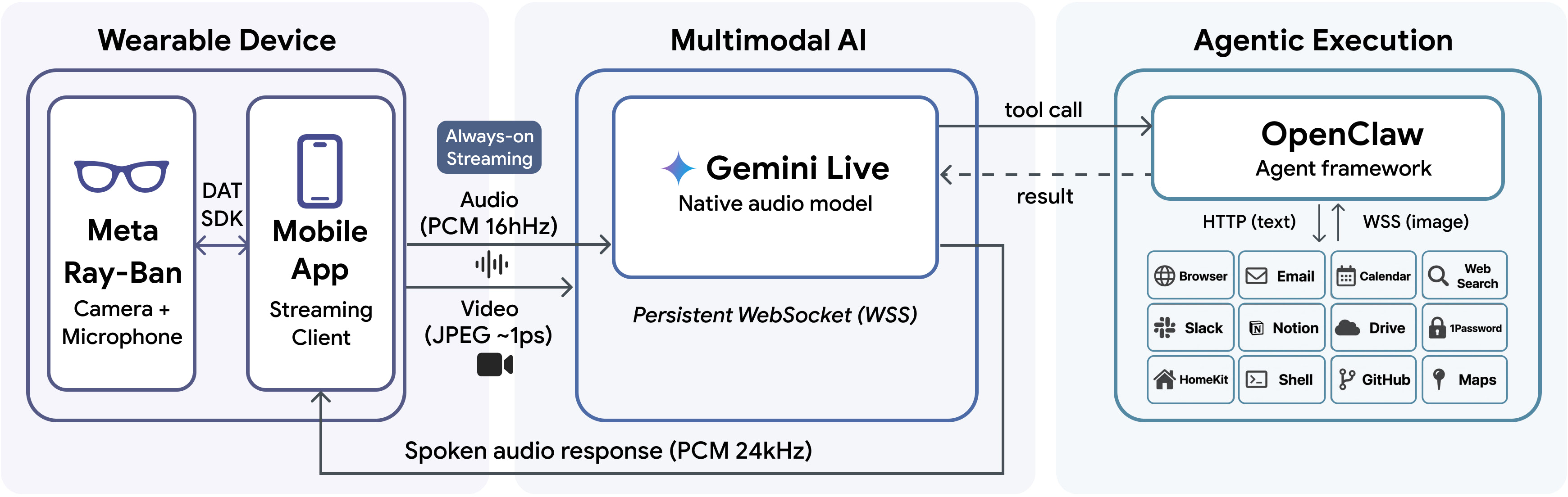
VisionClaw (2604.03486) exemplifies the fusion of egocentric multimodal perception and large-scale AI agentic task execution, operationalized through Meta Ray-Ban smart glasses, Gemini Live for real-time multimodal interaction, and OpenClaw for back-end agentic workflows. The system architecture is structured in three layers:
This architecture allows for seamless, screenless delegation of open-ended real-world tasks (e.g., "add this product to Amazon," "draft an email from this document") directly from physical context, without the user needing to switch devices or explicitly describe their surroundings.
Experimental Evaluation: Laboratory Study
A within-subjects laboratory study (N=12) benchmarked VisionClaw (Always-On + Agent) against two baselines:
- Always-On Only: Smart glasses with Gemini Live for perception and QA, but no autonomous execution.
- Agent Only: Smartphone-based OpenClaw agent with no real-world perception, requiring users to describe context explicitly.
Tasks were grounded in everyday physical artifacts (receipts, papers, books, IoT devices) and included note taking, email composition, product lookup, and device control.

Figure 2: Four representative physical-digital tasks utilized in the user study, encompassing note taking, email drafting, product search/shop, and smart device control.
Results demonstrated that VisionClaw achieves up to 37% reduction in task completion time and 46% reduction in perceived difficulty over baselines. Notably, in email composition, VisionClaw's median completion time was 105.7s vs. 216.4s for Always-On Only and 131.1s for Agent Only. NASA-TLX analysis confirmed significant reduction in mental and temporal demand, as well as user frustration (p<0.05).
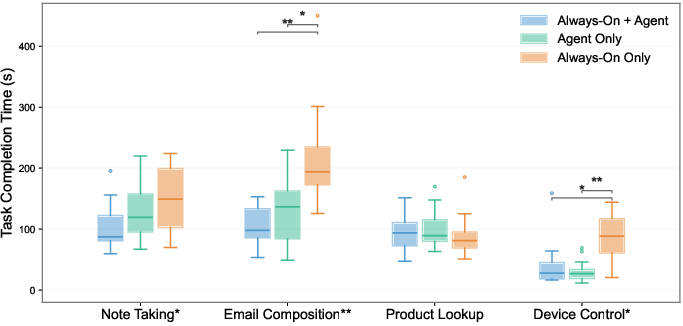
Figure 3: Task completion times; VisionClaw consistently outperforms baselines, with strong statistical significance in text-heavy tasks.
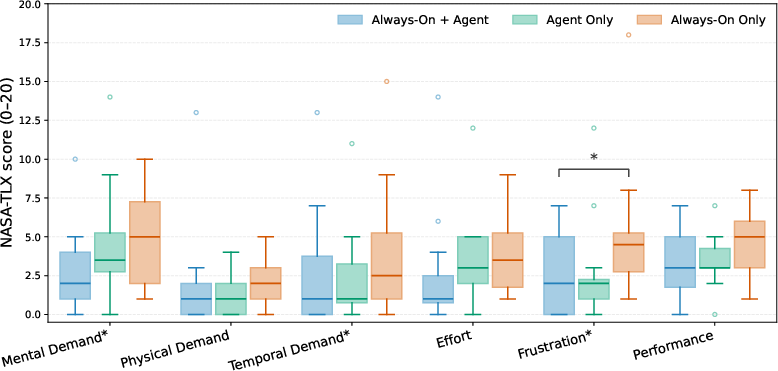
Figure 4: NASA-TLX workload scores highlight significant reductions in cognitive load and frustration with VisionClaw.
Self-authored Likert ratings indicated improvements in perceived control and usefulness, although trust and reliability differences were nonsignificant. Some users remained hesitant to fully delegate high-stakes tasks without explicit verification.
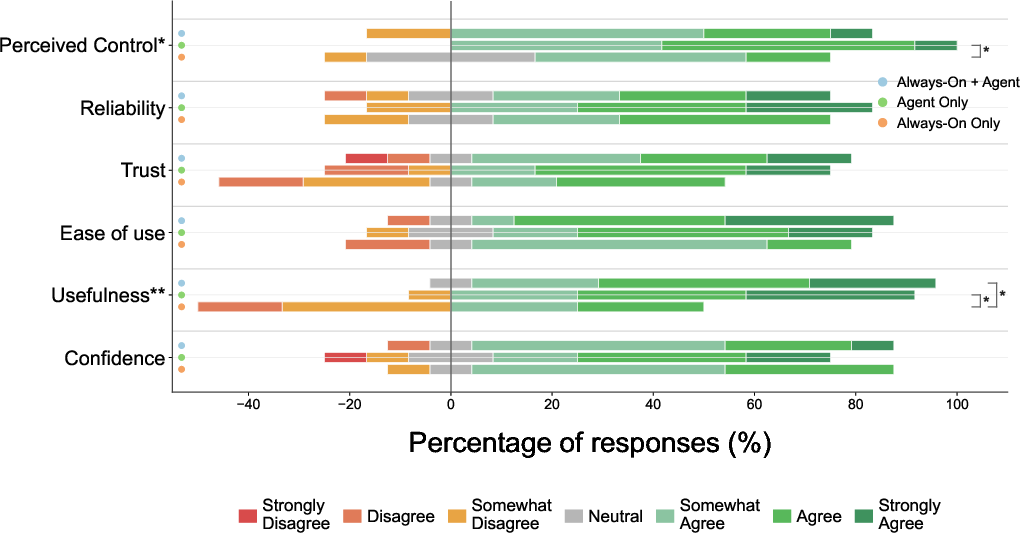
Figure 5: Self-report assessments; VisionClaw is rated as more useful and controllable for integrated, real-world tasks.
Longitudinal Deployment Study: Emergent Patterns and Use Cases
To surface long-term and in-situ interaction dynamics, an autobiographical deployment study (N=4, 555 interactions, 25.8 hours) categorized usage across six archetypes: Communicate, Retrieve, Save, Recall, Shop, and Control.

Figure 6: Exemplars for each primary use case, demonstrating agentic task execution grounded in visual context.
Interaction logs indicate users averaged 10.1 voice-initiated commands per day, with 39% leveraging visual context from the camera. Sessions were distributed throughout daily activity, substantiating the system's utility for ambient, always-on interaction.

Figure 7: Temporal visualization of task session distributions across use case categories in real-world deployment.
Notable emergent properties included:
- Multi-turn, Open-Ended Conversation: Users naturally chained queries and actions, blurring the segmentation between information request, memory retrieval, and autonomous task execution.
- Opportunistic Capture and Recall: Information was captured and recalled spontaneously, leveraging persistent egocentric context without deliberate device interaction.
- Screenless, Calm Interaction: Delegating tasks via voice rather than a phone reduced cognitive load, though trust and the need for explicit task confirmation remain active concerns.
- Interaction Evolution: As more personal data and agentic skills became available, users increasingly integrated agentic workflows into routine behavior.

Figure 8: Four recurring patterns observed: chained conversation, opportunistic memory actions, computation in the periphery, and increasing utility with richer personal data.
A comprehensive taxonomy of interaction scenarios, detailed in the appendix, illustrates broad domain transferability (e.g., academic, domestic, retail, and personal productivity).
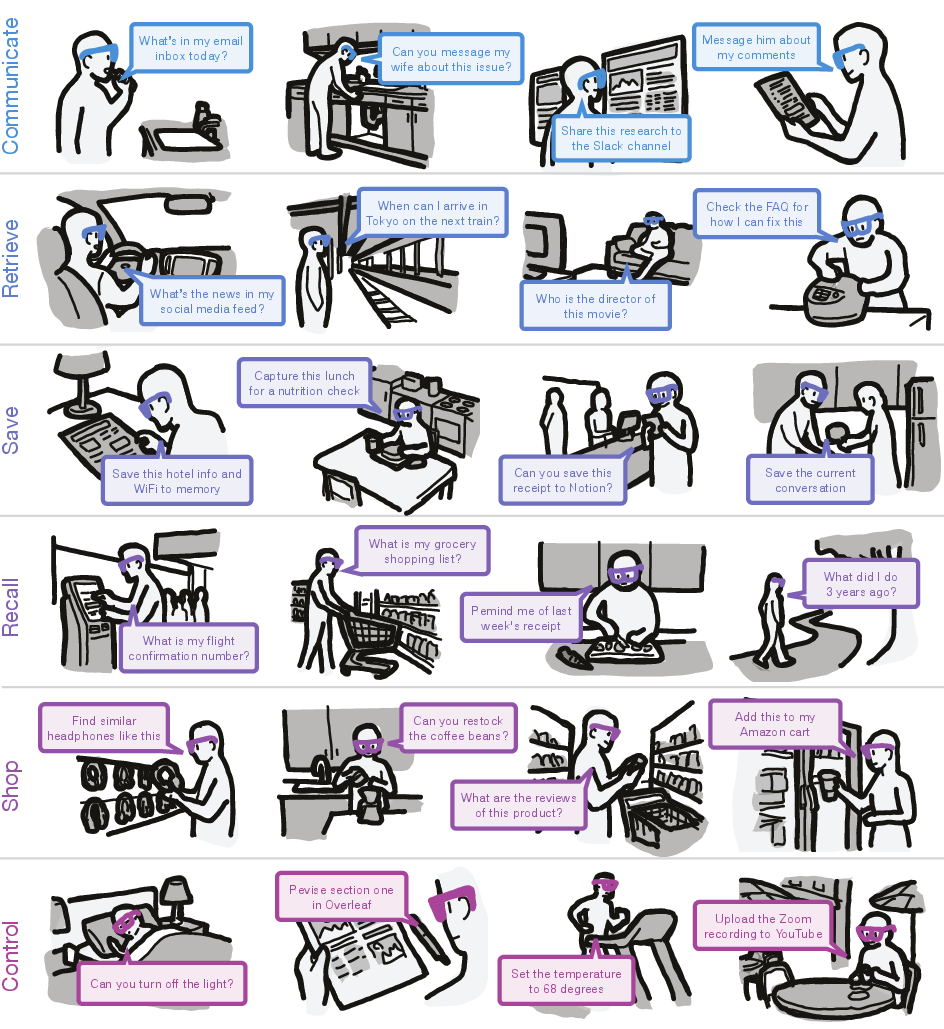
Figure 9: Taxonomy of observed use case categories with illustrated application scenarios.
Discussion: Theoretical Implications and Future Directions
VisionClaw's integration of always-on egocentric perception and agentic task execution precipitates several key theoretical and practical shifts:
Conclusion
VisionClaw demonstrates the feasibility and advantages of tightly coupling persistent egocentric perception with general-purpose agentic task execution in wearable platforms. Empirical results show strong performance and user experience gains in screenless, situated contexts and broad real-world applicability across domains. The findings elucidate fundamental shifts in habitual HCI and agent design, while also foregrounding critical challenges in privacy, model integration, memory architectures, and scalable deployment. This work constitutes a significant step in understanding and enabling ubiquitous, agent-driven multimodal computing.