ProAgent: Harnessing On-Demand Sensory Contexts for Proactive LLM Agent Systems
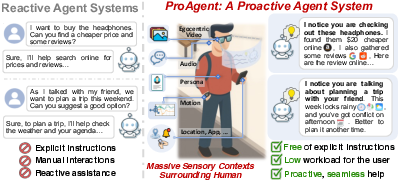
Abstract: LLM agents are emerging to transform daily life. However, existing LLM agents primarily follow a reactive paradigm, relying on explicit user instructions to initiate services, which increases both physical and cognitive workload. In this paper, we propose ProAgent, the first end-to-end proactive agent system that harnesses massive sensory contexts and LLM reasoning to deliver proactive assistance. ProAgent first employs a proactive-oriented context extraction approach with on-demand tiered perception to continuously sense the environment and derive hierarchical contexts that incorporate both sensory and persona cues. ProAgent then adopts a context-aware proactive reasoner to map these contexts to user needs and tool calls, providing proactive assistance. We implement ProAgent on Augmented Reality (AR) glasses with an edge server and extensively evaluate it on a real-world testbed, a public dataset, and through a user study. Results show that ProAgent achieves up to 33.4% higher proactive prediction accuracy, 16.8% higher tool-calling F1 score, and notable improvements in user satisfaction over state-of-the-art baselines, marking a significant step toward proactive assistants. A video demonstration of ProAgent is available at https://youtu.be/pRXZuzvrcVs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ProAgent, a smart assistant that tries to help you before you even ask. Instead of waiting for you to type or speak a command, ProAgent watches and listens through devices like smart glasses and phones, understands what’s going on around you, and offers help at the right time. It’s designed to reduce effort (so you don’t have to keep pulling out your phone) and reduce mental stress (so you don’t miss important info while you’re busy).
Key Objectives
The researchers set out to do three main things:
- Build a proactive assistant that can notice your surroundings and predict when you might need help.
- Use many kinds of sensor data (video, audio, location, motion) plus your personal preferences to figure out what help to give and when.
- Make the assistant efficient, so it works smoothly on wearable devices and doesn’t drain battery or get too slow.
How ProAgent Works
Here’s the system explained in everyday language.
Sensing the world
ProAgent collects information using:
- Video from smart glasses (what you’re seeing).
- Audio (are people talking, what’s being said).
- Motion (from the phone’s sensors: are you walking or standing).
- Location (GPS: where you are and what’s nearby, like stores or bus stops).
Video gives rich detail, but it’s “expensive” (uses lots of power and data). Audio, motion, and location are “cheap” and can run all the time.
Making sense of the sensors: “contexts”
ProAgent organizes all this data into “contexts”:
- Sensory contexts: short, useful summaries of where you are, whether you’re moving, and what’s being heard.
- Persona contexts: simple text about your preferences and traits (for example, “I’m forgetful about schedules,” or “I care about healthy eating”).
These help the system understand both the situation and the kind of help you’d appreciate.
Using “personas” smartly
People have many personas (preferences for different situations). Including all of them in the assistant’s reasoning makes it slow and less accurate. ProAgent avoids this by first guessing the scenario (like shopping or commuting) using quick object detection in the video (for example, “I see shelves and products → probably a store”) and only loads the relevant personas for that scenario. This keeps the assistant fast and focused.
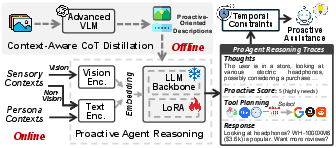
The “brain” of the assistant (a VLM)
ProAgent uses a type of AI called a Vision-LLM (VLM). Think of it as an AI that understands pictures and words together. Instead of using one model to describe the video and another to decide what to do (which would be slow), ProAgent uses a single VLM to:
- Describe what’s happening (“The user is in a store looking at headphones.”).
- Score how much you might need help right now (1 = very low, 5 = very high).
- Pick and call useful tools (like getting the weather, bus times, or calendar info).
- Produce the final help message.
This “think in steps” approach (called chain-of-thought) helps the AI reason more clearly, like explaining its thinking before acting.
Deciding when to help
ProAgent sets a “proactive score” from 1 to 5. If the score is high enough (above a set threshold), it offers help. If not, it stays quiet. You can set how proactive you want it to be (more help vs. fewer interruptions).
Calling tools
The assistant can use external tools (like apps or APIs) to get info:
- Retrieval tools: safe, read-only info (weather, bus times, current date/time).
- Execution tools: actions that affect things (booking a ride, sending an email). For safety, ProAgent suggests these and asks for your confirmation before doing anything.
Not being annoying
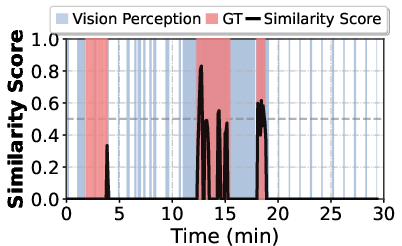
If you’re in the same situation for a while (for example, standing at a bus stop), the assistant could keep repeating itself. ProAgent checks if its message would be too similar to the last one and holds off if it is. You can adjust how sensitive this is.
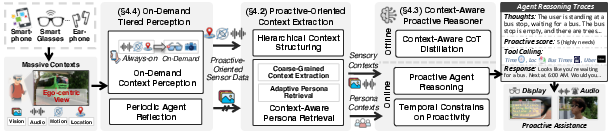
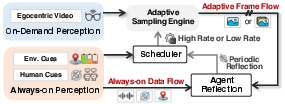
Being efficient: “on-demand tiered perception”
To save battery and keep things responsive, ProAgent:
- Always listens to “cheap” sensors (audio, motion, location).
- Only increases video capture when needed (for example, when you’re moving, near a place of interest, or in a conversation).
- Uses two video modes: low-rate (for calm situations) and high-rate (for fast-changing situations). By default, it stays low-rate and switches up when the cheap sensors or the AI’s own “reflection” suggests it should.
- The AI’s reflection: If it predicts you’re likely to need help soon, it increases video sampling temporarily so it doesn’t miss important moments.
Main Findings
The team tested ProAgent on:
- A public dataset (CAB-Lite) covering everyday scenarios like shopping, travel, chatting, work, and health.
- A real-world testbed with smart glasses, phones, and edge servers.
- A user study with 20 volunteers, producing over 6,000 samples.
Compared to other strong systems they built as baselines, ProAgent:
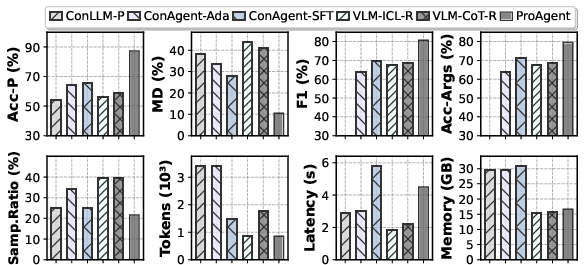
- Predicted help needs more accurately: up to 33.4% improvement.
- Chose and used tools more correctly: 16.8% higher tool-calling F1 score.
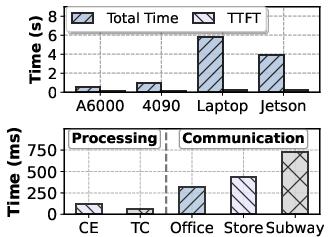
- Used fewer resources: about 1.79x lower memory consumption.
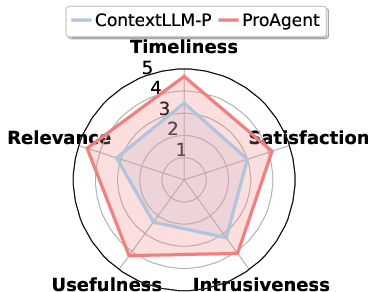
- Made users happier: average satisfaction improved by 38.9% across five areas of proactive service.
In simple terms, it noticed the right moments more often, gave more useful help, ran more efficiently, and people liked it more.
Why It Matters
ProAgent shows a practical path toward assistants that can truly support you in daily life without constant commands. This could:
- Reduce physical effort (less phone fiddling) and mental load (fewer missed chances to get help).
- Improve safety and confidence during busy tasks (like commuting or shopping).
- Help people with specific needs (for example, visual impairments) by offering timely, personalized guidance.
- Make wearables more useful in real-world, fast-changing environments.
In the future, systems like ProAgent could make AR glasses and smartphones feel more like a helpful friend who pays attention and supports you at the right moment—without being pushy or draining your battery.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, structured to guide future research.
- Energy, battery, and thermal behavior are not quantified for continuous multimodal sensing and VLM inference on wearable platforms; end-to-end energy–latency–quality trade-offs under varied device constraints remain uncharacterized.
- Privacy and security implications of always-on audio/video capture are not addressed (bystander consent, on-device redaction/anonymization, encryption, retention policies, API key handling, and misuse of execution tools).
- Generalization to open-world scenarios is unclear: the scenario-object bank is tied to nine CAB-Lite categories, with no evaluation on unseen contexts, new object sets, or out-of-distribution environments.
- Persona modeling is static and user-authored; no mechanism exists for continual, privacy-preserving adaptation from behavior, feedback, or outcomes, nor for resolving conflicting personas or quantifying retrieval errors.
- The context-aware persona retrieval uses coarse object detection and TopK similarity; its robustness to misdetections, visually similar scenes, and multilingual or text-light contexts is not evaluated.
- Proactive need labels are self-annotated and subjective; there is no validation against independent annotators or objective measures of cognitive load reduction (e.g., NASA-TLX, eye-tracking, dual-task performance).
- Long-term deployment effects (habituation, trust, fatigue, behavior change) and sustained acceptance over weeks/months are not studied; the user study is short and demographically limited (n=20, average age ~24).
- On-demand tiered perception relies on heuristics (motion, POI proximity, conversation) and a simple reflection rule; formal optimization of sampling policies against energy–recall curves, adaptive thresholds, and ablations are missing.
- The sampling scheduler’s fixed “5 s high / 60 s low” rates lack adaptive control under dynamic battery/network/compute constraints; no sensitivity analysis or per-scenario tuning guidelines are reported.
- Tool-calling reliability is underexplored: error handling, API failures, permission management, partial results, retries, and recovery strategies are not described or evaluated.
- Safety-critical contexts (driving, medical decisions, hazardous environments) are not addressed; risk assessment, fail-safes, confirmation UX, and liability implications of proactive suggestions remain open.
- The temporal constraint based on BERT similarity (threshold=0.5) may fail with paraphrasing or subtle context shifts; calibration methods, per-user tuning, and alternatives to avoid over-suppression are not evaluated.
- The CoT distillation uses thoughts generated by an advanced VLM; the risk of propagating hallucinations/bias, and causal impact of this distillation versus SFT/ICL baselines (with thorough ablations) are not quantified.
- Multilingual robustness is not evaluated: ASR accuracy, VAD reliability, cross-language personas and contexts, and non-English tool arguments can degrade performance.
- Robustness to sensor noise/failure (GPS drift, IMU bias, occluded video, noisy audio), network outages, and graceful degradation/fallback modes are not characterized.
- Scalability and orchestration across many concurrent users and devices (edge–cloud scheduling, load balancing, model placement, cost control) are unaddressed.
- Interoperability with diverse hardware (different AR glasses, smartphones, sensors) and portability of the pipeline beyond Jetson Orin/laptop servers are not demonstrated.
- The fixed toolset (20 APIs) limits scope; methods for discovering, selecting, and safely integrating large or evolving tool ecosystems (schema induction, permissioning, sandboxing) are not explored.
- Metrics focus on trigger accuracy and tool F1/arguments; comprehensive UX outcomes (intrusiveness, appropriateness of timing, situational awareness, error costs) and task-level impacts are not systematically measured.
- Adversarial resilience is not considered: audio injection, sensor spoofing, or contextual manipulation could induce over-proactivity or unsafe tool calls; defenses and monitoring are open.
- Personalization of proactivity thresholds and temporal constraints is manual; learning user-specific policies from feedback (online learning, bandits, RL) while preserving privacy remains an open direction.
- Multi-user and social contexts are underexplored (who to assist in group interactions, social acceptability of prompts, bystander impact); disambiguation and etiquette policies are missing.
- Legal/regulatory compliance (GDPR/CCPA, HIPAA for health-related guidance) is not discussed; data minimization and auditability requirements need articulation and technical support.
Glossary
- Acc-Args (Arguments Accuracy): A metric assessing whether an agent correctly formats and fills tool-call parameters. "we adopt F1-score to compare tool names between the predicted and ground-truth tool sets and Acc-Args (Arguments Accuracy) to determine whether the agent correctly parses the toolsâ arguments."
- Acc-P (Proactive Accuracy): A metric measuring how accurately the system identifies moments that require proactive services. "we use Acc-P (Proactive Accuracy) and MD (Missed Detection) to evaluate the systemâs accuracy in identifying moments that require proactive services and its miss detection rate."
- API-based function calling framework: An architecture that allows the agent to invoke external tools or services via defined APIs. "We implement the agent with an API-based function calling framework~\cite{li2023api}, with a tool set from~\cite{yang2025contextagent}, containing 20 tools."
- Augmented Reality (AR) glasses: Wearable displays that overlay digital content onto the user’s view to deliver assistance. "We implement \mbox{ProAgent}~on Augmented Reality (AR) glasses with an edge server"
- BERT: A transformer-based LLM used here to compute similarity between textual outputs. "ProAgent calculates the semantic similarity between consecutive outputs using BERT~\cite{devlin2019bert}"
- BLEU: An n-gram precision-based metric used to evaluate similarity between generated and reference texts (here, captions). "two metrics (i.e., BLEU~\cite{papineni2002bleu} and ROUGE~\cite{lin2004rouge}) to compare caption similarity"
- Chain-of-Thoughts (CoT): A prompting/reasoning technique where the model produces explicit intermediate reasoning steps. "The reasoner first generates an explicit description of the current vision inputs using Chain-of-Thoughts (CoT)~\cite{wei2022chain}"
- Context-aware CoT distillation: A training approach that fine-tunes a model to produce CoT-style reasoning grounded in contextual inputs. "we develop a context-aware CoT distillation approach to fine-tune the VLM."
- Context-aware persona retrieval: A method to select and supply only scenario-relevant user personas to the reasoner to reduce noise and overhead. "we develop a context-aware persona retrieval approach that adaptively integrates personas into proactive reasoning."
- Context-aware proactive reasoner: The VLM-based component that maps sensory and persona contexts to proactive decisions and tool calls. "ProAgent employs a context-aware proactive reasoner using VLMs"
- Edge server: A nearby compute node that offloads heavy processing from resource-constrained devices. "We implement ProAgent on AR glasses with an edge server"
- Egocentric video: First-person video captured from the user’s perspective, used as a rich visual context source. "such as egocentric video, audio, and motion data."
- Execution-based tools: External tools that perform actions (e.g., sending an email) and may require user confirmation before execution. "we categorize these tools into retrieval-based and execution-based tools."
- F1-score: The harmonic mean of precision and recall; here used to evaluate correctness of predicted tool names. "we adopt F1-score to compare tool names between the predicted and ground-truth tool sets"
- Hierarchical contexts: Multi-level representations of sensor-derived and user-specific (persona) information for reasoning. "derive hierarchical contexts that incorporate both sensory and persona cues."
- IMU (Inertial Measurement Unit): A sensor measuring motion/acceleration, used to infer user movement states. "uses the smartphoneâs IMU to determine the userâs motion state"
- In-context learning (ICL): Adapting model behavior using examples supplied in the prompt rather than updating weights. "We employ prompts and in-context learning (ICL)~\cite{dong2022survey} with ten examples to adapt them to proactive reasoning."
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning method that injects low-rank adapters into large models. "apply Low-Rank Adaptation (LoRA)~\cite{hu2022lora} to reduce training cost."
- Missed Detection (MD): A metric capturing how often the system fails to trigger when proactive service is needed. "we use Acc-P (Proactive Accuracy) and MD (Missed Detection) to evaluate the systemâs accuracy in identifying moments that require proactive services and its miss detection rate."
- Multimodal LLMs (MLLMs): LLMs that process multiple modalities (e.g., text and images) for tasks like UI understanding. "Several studies employ screenshots and multimodal LLMs (MLLMs) for UI understanding"
- On-demand tiered perception: A sensing strategy that keeps low-cost sensors always-on and activates high-cost sensors only when needed. "ProAgent first adopts an on-demand tiered perception strategy"
- Points of Interest (POIs): Notable nearby locations (e.g., bus stops, supermarkets) inferred from geospatial data. "identify nearby points of interest such as bus stations and supermarkets"
- Proactive score: A scalar rating (e.g., 1–5) estimating the user’s need for immediate proactive assistance. "The reasoner generates a proactive score based on the current contexts."
- Reverse geocoding: Converting latitude/longitude coordinates into human-readable place names or POIs. "uses GPS coordinates together with reverse geocoding to identify nearby points of interest"
- Retrieval-based tools: External tools that fetch information (e.g., weather) instead of executing user actions. "we categorize these tools into retrieval-based and execution-based tools."
- ROUGE: A recall-oriented metric for text overlap, here used to assess caption similarity. "two metrics (i.e., BLEU~\cite{papineni2002bleu} and ROUGE~\cite{lin2004rouge}) to compare caption similarity"
- Scenario-object bank: A mapping from detected object sets to scene categories used to infer scenarios for persona retrieval. "constructs a scenario-object bank , where each entry consists of a set of detected objects paired with a scene category ."
- Semantic embeddings: Vector representations capturing meaning, used for similarity comparisons between contexts. "where denotes using a pretrained model to obtain semantic embeddings."
- Semantic similarity: A measure of how close two pieces of text (or embeddings) are in meaning. "based on semantic similarity between and each entry's object set"
- Supervised fine-tuning (SFT): Updating model weights on labeled data for a target task. "directly applying supervised fine-tuning (SFT)~\cite{achiam2023gpt} on sensor data and proactive labels"
- Temporal constraint mechanism: A strategy to prevent repetitive or redundant proactive prompts within a short timeframe. "employs a temporal constraint mechanism to avoid prompting users repeatedly within a period of time."
- Top-k retrieval: Selecting the k most similar items from a database based on a similarity metric. "retrieve the top- most similar entries from the object-scenario bank "
- Visual LLM (VLM): A model that jointly processes visual inputs and text for reasoning and generation. "ProAgent employs a VLM that integrates visual context extraction and agent reasoning into a unified process"
- YOLO-v5: A real-time object detection model used here for efficient coarse-grained context extraction. "we employ YOLO-v5~\cite{jocher2022ultralytics}, pretrained on the Objects365 dataset"
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be built now by leveraging ProAgent’s on-demand tiered perception, proactive-oriented context extraction, context-aware persona retrieval, and VLM-based proactive reasoner with tool-calling.
- Consumer micro-assistance during daily routines (Mobility, Productivity, Consumer software)
- What: Hands-free prompts for transit arrivals when approaching a stop, weather/clothing suggestions before leaving, calendar conflict alerts surfaced during an ongoing conversation, time-sensitive reminders (e.g., “leave now to make your meeting”).
- Tools/products/workflows: Transit/Maps APIs, CityWeather, Calendar API; workflow: low-cost sensing (GPS/IMU/audio) → persona retrieval → VLM reasoner → tool call → AR-glasses overlay with temporal constraints.
- Dependencies/assumptions: Accurate GPS and place recognition, stable edge connectivity to call APIs (or cached data), user consent for ambient audio, battery-aware sampling; retrieval-based tools are preferred for low risk.
- In-store shopping copilots (Retail, E-commerce)
- What: Product comparison, price checks, reviews, and coupon suggestions when the user looks at an item; grocery substitutions that respect dietary preferences in the persona.
- Tools/products/workflows: Product DB/review APIs, barcode/label OCR, store maps; persona-based preference filtering.
- Dependencies/assumptions: Store policies permitting camera use, up-to-date product/review data, reliable object detection; latency low enough to be helpful at the shelf.
- Conversation and meeting augmentation (Enterprise software, Education)
- What: Real-time meeting context reminders (agenda, shared action items), proactive follow-up prompts, live translation or definition lookups during chitchat or lectures.
- Tools/products/workflows: On-device VAD + speech-to-text, Calendar/CRM/Issue-tracker APIs, translation; temporal constraints to avoid over-notifying.
- Dependencies/assumptions: Consent and privacy compliance for recording, robust transcription in noisy settings, low-latency inference on edge.
- Wellness and routine adherence nudges (Wellness/Healthcare-lite)
- What: Time- and context-aware hydration or movement prompts, posture reminders, medication time nudges, high-level dietary guidance while eating (e.g., highlighting ingredients).
- Tools/products/workflows: Local reminders, Apple Health/Google Fit, OCR for labels; persona controls (e.g., dietary goals).
- Dependencies/assumptions: Not clinical-grade advice; clear scope to avoid medical claims; user-configurable proactivity thresholds.
- Accessibility for low-vision users (Assistive technology)
- What: Scene description, sign/label reading, bus number recognition, simple path guidance in stations; proactive surfacing of relevant info nearby (e.g., “Platform 3—next train in 2 minutes”).
- Tools/products/workflows: OCR, transit APIs, coarse navigation cues; audio/tactile feedback via glasses/phone.
- Dependencies/assumptions: Ambient audio recording legality, adequate lighting and camera quality, manageable latency; careful UX for cognitive load.
- Smart home/office micro-automation suggestions (IoT)
- What: Contextual prompts to start meetings, adjust lighting/thermostat on arrival, set “focus” scenes when seated at the desk; confirmations for execution-based actions.
- Tools/products/workflows: Home Assistant/SmartThings/Hue APIs; execution gating (confirm-before-act).
- Dependencies/assumptions: Device integrations and local network access; mis-trigger mitigation via temporal constraints and threshold tuning.
- Safety nudges for pedestrians and micromobility (Mobility/Safety)
- What: Context-aware route suggestions, attention cues when near crossings or construction zones, reminders to remove earbuds in high-risk zones.
- Tools/products/workflows: Maps/road-work feeds, IMU/GPS-based motion states; short, unobtrusive alerts.
- Dependencies/assumptions: Risk of false positives; carefully tuned thresholds to avoid distraction; not for driving scenarios.
- Privacy-preserving edge deployments and IT integration (IT/Edge AI)
- What: On-prem/edge inference with LoRA-adapted VLMs (e.g., Jetson Orin) to minimize data egress; proactive sampling scheduler to reduce captured video volume while maintaining recall.
- Tools/products/workflows: Ollama/edge inference stacks, device MDM, ops dashboards for token/latency/memory budgets.
- Dependencies/assumptions: Edge GPU availability, model licensing, MLOps for updates; clear data retention policies.
- Academic prototyping and evaluation (Academia, HCI)
- What: Rapid experimentation with proactive agents using CAB-Lite and real-world data collection workflows; user studies on cognitive load and satisfaction; benchmarking with Acc-P, F1 (tool-calling), Acc-Args.
- Tools/products/workflows: Open-source LoRA fine-tuning scripts, persona retrieval pipeline, testbed with AR glasses + phone; IRB-approved data collection app.
- Dependencies/assumptions: Dataset/tool access, ethics approvals, participant recruitment; consistent annotation protocols.
Long-Term Applications
These use cases are promising but require further research, scaling, domain-specific validation, or regulatory approval before wide deployment.
- Autonomous task execution with strong safety interlocks (Finance, Mobility, Productivity)
- What: Agent moves from “propose + confirm” to trustworthy auto-execution of purchases, bookings, and emails based on context; multi-factor authentication and policy constraints.
- Tools/products/workflows: Payment rails, commerce APIs, enterprise email and approvals; policy and safety guardrails; audit trails.
- Dependencies/assumptions: High tool-calling accuracy, robust argument parsing, secure identity binding, organizational policy acceptance and legal review.
- Industrial safety and workflow copilots (Manufacturing, EHS)
- What: Proactive PPE compliance checks, hazard detection, step-by-step SOP guidance triggered by context in factories/warehouses; incident-prevention nudges.
- Tools/products/workflows: Domain-tuned visual models, OT/CMMS integrations, AR work instructions; edge compute at the facility.
- Dependencies/assumptions: Domain data and evaluation, low false-alarm rates, safety certifications, worker councils/union input, on-device processing constraints.
- Clinical-grade patient support and perioperative assistance (Healthcare)
- What: Context-aware medication reconciliation prompts, early-risk alerts during daily living, sterile-field and instrument tracking nudges in OR settings via AR.
- Tools/products/workflows: EHR integrations (FHIR), medical device data, secure on-prem inference; human oversight workflows.
- Dependencies/assumptions: HIPAA/GDPR compliance, FDA/CE approvals, clinical trials demonstrating efficacy and safety, rigorous bias and error analysis.
- Vocational training and lab safety coaching (Education/EdTech)
- What: Context-aware feedback in labs and skilled trades; real-time safety reminders, step validation, and competency tracking via AR.
- Tools/products/workflows: Curriculum-aligned prompt libraries, scenario-object banks per discipline, LMS integration.
- Dependencies/assumptions: Domain content partnerships, teacher/admin adoption, robust evaluations of learning outcomes.
- Team-level proactive coordination and shared situational awareness (Enterprise, Public Safety)
- What: Multi-user context fusion to orchestrate handoffs, surface relevant intel to the right teammate, and synchronize actions in field ops or customer support.
- Tools/products/workflows: Cross-user consent, role-aware persona models, secure mesh networking; interoperability with incident/dispatch systems.
- Dependencies/assumptions: Privacy across team members, secure communications, standards for context sharing and auditing.
- Smart city and public-space augmentation (Urban policy, Transportation)
- What: Context-aware public transit/station AR hints, crowd management prompts, and accessibility overlays for visitors and residents.
- Tools/products/workflows: City data platforms, real-time feeds, public kiosks/edge nodes; public safety integration.
- Dependencies/assumptions: Regulations for AR in public spaces, procurement and maintenance, inclusive design and accessibility mandates.
- Fully on-device, always-on private assistants (Semiconductors, Edge AI)
- What: Run the complete proactive stack on glasses-class hardware without offloading, with advanced model compression and energy-aware scheduling.
- Tools/products/workflows: Next-gen NPU/GPU on wearables, quantized VLMs, cross-device collaborative inference with phone/watch.
- Dependencies/assumptions: Hardware advances, model compression breakthroughs, OS-level power APIs.
- Personalized long-horizon learning and federated adaptation (ML research, Consumer)
- What: Continual learning of user personas, routines, and preferences with federated updates; drift/trust calibration; adaptive proactivity thresholds.
- Tools/products/workflows: Federated learning pipelines, private aggregation, long-term memory stores with redaction and forgetting.
- Dependencies/assumptions: Strong privacy guarantees, user control over memory, mechanisms to prevent preference lock-in or bias amplification.
- Regulatory frameworks and standards for proactive agents (Policy, Standards bodies)
- What: Consent norms for ambient sensing, transparency UIs for “why this prompt,” data minimization defaults, tool-call auditing and incident reporting, liability allocation.
- Tools/products/workflows: Standardized consent UX patterns, audit logs, red-teaming protocols; certification programs.
- Dependencies/assumptions: Multi-stakeholder collaboration (industry, regulators, disability advocates), evolving legal consensus.
- Energy-aware, cross-device orchestration of sensing (Energy/IoT, OS vendors)
- What: Cooperative scheduling across watch/phone/glasses/home sensors to minimize energy while preserving proactive recall; dynamic role assignment by battery and thermal budgets.
- Tools/products/workflows: OS-level APIs for shared sensing, standardized event buses, energy policies.
- Dependencies/assumptions: Interoperability across vendors, system-level privileges, user transparency on energy/data use.
- Robotics and embodied collaboration in the home/office (Robotics, Smart home)
- What: Wearable agent proactively dispatches a home robot to fetch items or adjust the environment when it infers need; shared context and task plans.
- Tools/products/workflows: Robot APIs (navigation/manipulation), home digital twin, confirm-before-act execution policies.
- Dependencies/assumptions: Reliable indoor navigation, safety constraints, mixed-initiative planning, human-in-the-loop oversight.
- Real-time financial hygiene and consumer protection (Finance)
- What: Budget nudges in-store, receipt capture and categorization, warning when scanning suspicious QR/URLs, proactive reminders of subscription renewals.
- Tools/products/workflows: Bank aggregation APIs, OCR, secure enclaves for secrets; persona-linked budget rules.
- Dependencies/assumptions: Secure authentication, financial compliance, extremely low false positives to avoid habituation.
Notes common to many applications:
- Key assumptions: availability of multi-modal sensors (AR glasses camera, phone IMU/GPS, audio), reliable edge inference for VLMs, network access to APIs, and user-provided personas. Temporal constraints and adjustable proactivity thresholds are critical to avoid over-notification.
- Primary risks: privacy and consent for ambient audio/video, battery life, false positives/negatives in high-stakes contexts, and dependency on third-party tool/APIs.
- Migration path: start with retrieval-based tools and confirm-before-act workflows; progressively integrate execution-based tools with strong guardrails and auditing.
Collections
Sign up for free to add this paper to one or more collections.