- The paper demonstrates a robust positive correlation between LLM size and DMN alignment during prompt processing (r=0.58, p<0.05).
- The paper reveals that alignment is stage- and task-dependent, with significant drops following response generation and clear differences between creative and control tasks.
- The paper shows that post-training objectives selectively modulate alignment, where creative fine-tuning enhances neural correspondence while convergent training diminishes it.
LLMs Align with the Human Brain during Creative Thinking
Introduction and Motivation
This paper investigates the correspondence between the internal representations of LLMs and human neural activity during divergent creative thinking, specifically focusing on creativity-relevant brain networks. Previous studies emphasized passive language comprehension tasks or elementary associative reasoning, leaving the neural alignment between LLMs and the human brain during active creative thought underexplored. This work addresses that gap using fMRI data acquired from 170 participants performing both the Alternate Uses Task (AUT), a canonical measure of divergent thinking, and the Object Characteristics Task (OCT), a non-creative control. Alignment is measured using Representational Similarity Analysis (RSA) between LLM activations and task-related fMRI patterns, with a principal focus on the Default Mode Network (DMN) and Frontoparietal Network (FPN).
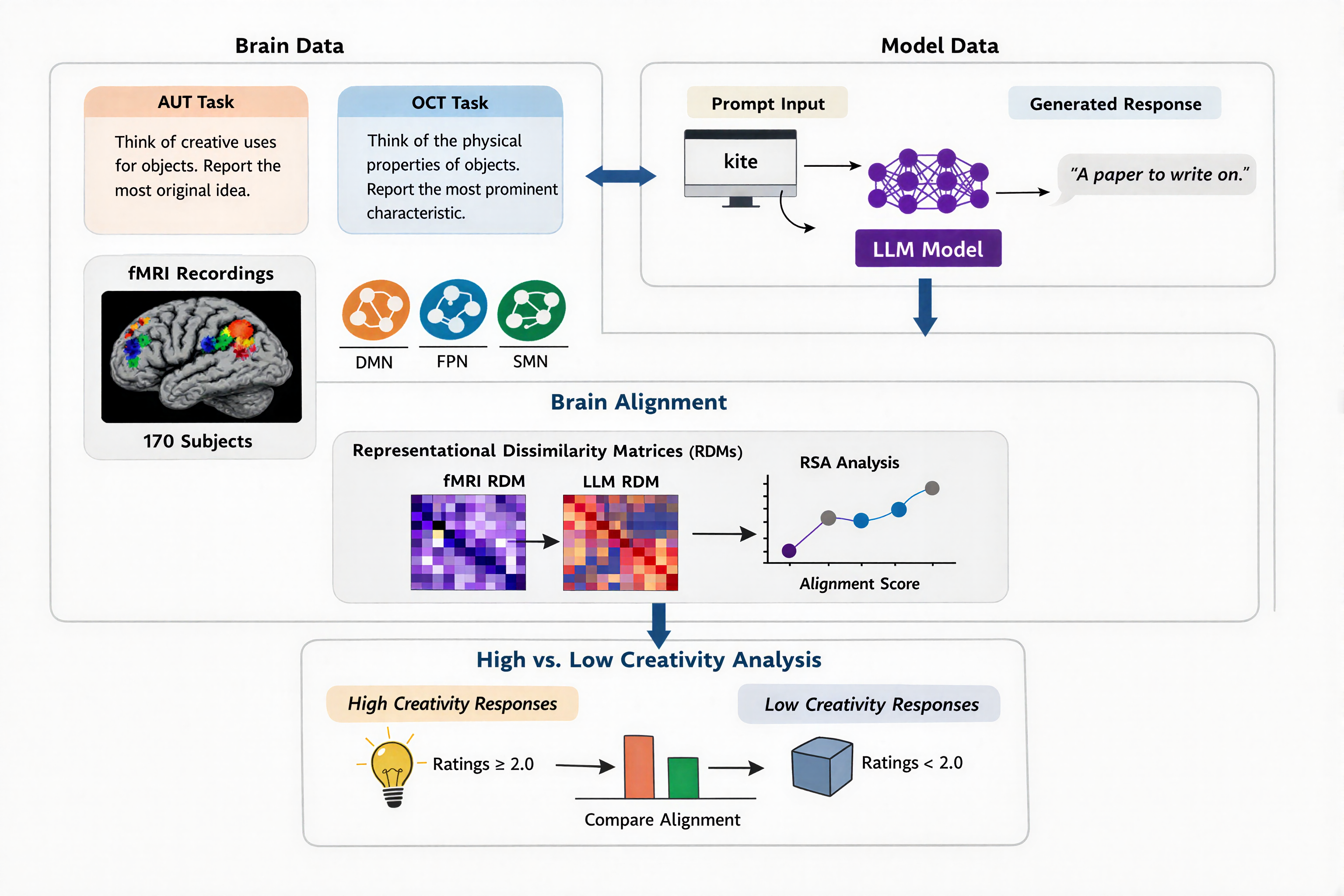
Figure 1: High-level overview of the brain-LLM alignment methodology, including extraction of neural and model representations and their comparison via RSA.
Methodological Approach
The study operationalizes brain alignment via the RSA similarity between representational dissimilarity matrices (RDMs) derived from LLM activations at various processing stages and single-trial beta maps extracted from fMRI data in DMN, FPN, and Somatomotor (control) networks. Multiple state-of-the-art open-weight LLMs with parameter scales from 270M to 72B are interrogated, including distinct fine-tuned and post-trained variants (creativity-optimized, human behavior-simulated, and chain-of-thought–fine-tuned models).
Key experimental factors include:
- Extraction of model activations at two stages: "prompt-only" (stimulus presentation, prior to generation) and "prompt+response" (post-generation).
- Evaluation of model alignment with fMRI from both high- and low-creativity human response populations, based on normative ratings of originality.
- Systematic examination of effects of model size, creative task performance (measured by LLM-predicted creativity scores), representational depth, and post-training objectives on neural alignment.
Main Results
The principal finding is a robust positive correlation between model size and DMN alignment during the prompt processing phase (r=0.58,p<0.05). A significant correlation is also observed between model creative task performance on AUT and DMN alignment (r=0.51,p<0.05). This effect is selective: There is little or no corresponding association in the OCT (non-creative) condition, nor in the Somatomotor control network.
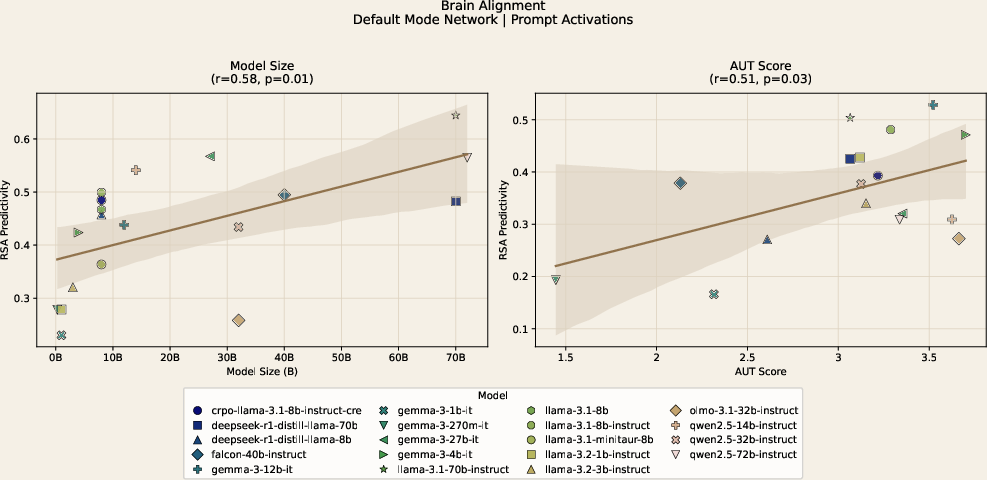
Figure 2: DMN AUT brain alignment results as a function of model size and task performance, with moderate-to-strong positive correlations at the prompt-only stage.
Representational Depth and Hierarchy
Analysis of the locus of maximally aligned model layers demonstrates that peak brain alignment for creative ideation occurs in higher model layers. There is a notable positive correlation between normalized layer index (relative depth) and alignment magnitude (r=0.54,p<0.05), suggesting that the neural signatures of creativity are most closely mirrored by late-stage, high-level representations in the LLM computational hierarchy.
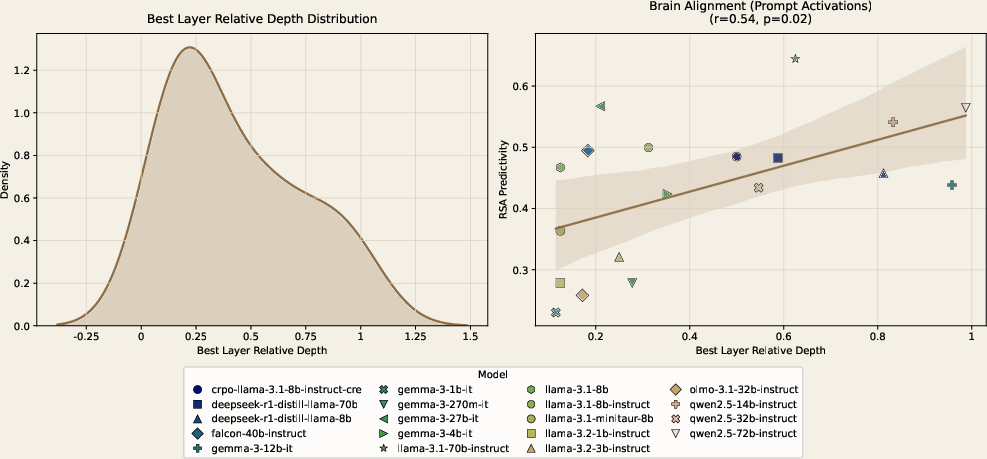
Figure 3: (Left) Distribution of maximally aligned layers, indexed by depth; (Right) correlation of DMN alignment with best-layer relative depth.
Stage-Dependent Dynamics
Alignment effects are highly stage- and task-dependent. They are strong during prompt processing but attenuate following response generation, implying that LLM output generation may diverge from human neural creative dynamics or that convergence in model responses reduces the sensitivity of such analyses.
Selective Modulation by Post-Training Objectives
Fine-tuning and post-training objectives are found to have selective, interpretable effects on model-brain alignment:
Task and Network Specificity
The observed scaling and post-training-dependent effects are absent in both the OCT (object characteristics) control condition and in non-creativity–associated networks, supporting the interpretation that alignment is not a general property of LLM architecture, but is tightly coupled to both task and underlying network neurofunction.
Theoretical and Practical Implications
This work demonstrates that neural alignment between LLMs and the human brain during divergent thinking is nontrivial, reflecting both model scale and computational abstraction. The selective effect of post-training objectives reveals that fine-tuning on convergent reasoning tasks (e.g., chain-of-thought) may degrade or actively invert a model's alignment to creativity-essential neural circuits, while creativity-oriented fine-tuning enhances correspondence to originality-supporting brain activity.
From a practical standpoint, this suggests that current industry paradigms in LLM post-training—which disproportionately reward single-answer reasoning or deterministic task completion—might inadvertently suppress neural and behavioral signatures of generative creative thought. As creative capacity is central for open-ended human endeavors, the introduction of brain-based metrics may provide additional constraints for LLM optimization, enabling more faithful emulation of human cognitive diversity.
Speculations on Future Directions
The application of brain alignment analyses to LLMs unlocks non-behavioral, representational evaluation axes, valuable for model inspection, selection, and debiasing. Incorporating neurofunctional targets during LLM post-training could allow developers to balance the tradeoff between convergent (analytical) and divergent (creative) abilities, especially in domains requiring both robust reasoning and idea generation. Moreover, deeper neuroscientific integration—e.g., targeting network-specific or process-phase–specific brain signatures—may enable new forms of hybrid human-AI cognitive interaction or therapeutic application.
Conclusion
This study provides robust evidence that LLMs partially recapitulate the neural geometry of human creative cognition, with alignment scaling as a joint function of model architecture, task performance, representational depth, and fine-tuning objectives. However, generative output processes in LLMs deviate from human neural dynamics in crucial ways, and this divergence is exacerbated or mitigated by the chosen post-training paradigm. These findings argue for the systematic integration of neuroscientific alignment analyses in the evaluation and development of future LLMs, particularly to maintain and enhance their capacity for divergent creative thought.
