Serendipity by Design: Evaluating the Impact of Cross-domain Mappings on Human and LLM Creativity
Abstract: Are LLMs creative in the same way humans are, and can the same interventions increase creativity in both? We evaluate a promising but largely untested intervention for creativity: forcing creators to draw an analogy from a random, remote source domain (''cross-domain mapping''). Human participants and LLMs generated novel features for ten daily products (e.g., backpack, TV) under two prompts: (i) cross-domain mapping, which required translating a property from a randomly assigned source (e.g., octopus, cactus, GPS), and (ii) user-need, which required proposing innovations targeting unmet user needs. We show that humans reliably benefit from randomly assigned cross-domain mappings, while LLMs, on average, generate more original ideas than humans and do not show a statistically significant effect of cross-domain mappings. However, in both systems, the impact of cross-domain mapping increases when the inspiration source becomes more semantically distant from the target. Our results highlight both the role of remote association in creative ideation and systematic differences in how humans and LLMs respond to the same intervention for creativity.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question: Can we boost creativity by forcing people (and AI models) to take ideas from a totally different area and apply them to something familiar? The researchers tested a method called “cross-domain mapping,” where you take a feature from one thing (like an octopus) and use it to inspire a new feature for a different thing (like a car). They compared this to a more typical approach: inventing features based on unmet user needs.
What questions did the researchers ask?
- Do cross-domain mappings make ideas more original (creative) for humans? For LLMs, which are AI systems that generate text?
- Are some source–target pairs (like “octopus → car”) more inspiring than others?
- Does being “farther apart” in meaning (more semantically distant) lead to more originality?
How did they do the study?
Human idea generation
- 140 adults were asked to invent features for 10 everyday products (like a backpack, sofa, smartphone).
- There were two ways to invent: 1) Cross-domain mapping: Each product was paired with a random inspiration source (like cactus, beehive, or GPS). First, participants described a property of the source (e.g., “cacti store water”), then turned that into a new feature for the product (e.g., “a backpack that captures moisture and stores it for drinking”). 2) User-need: Participants invented features to solve unmet user needs (e.g., “shoes that cushion joints for long walks”).
- Each target–source pair was done multiple times to create a large set of ideas.
LLM idea generation
- Seven different AI models were asked to do the same tasks, following the same two prompts (cross-domain mapping vs. user-need).
- For consistency, one model rephrased all ideas (human and AI) into short, clear descriptions, without saying how the idea was created.
Rating the ideas
- 1,002 people rated each idea on four things, using 1–5 scales:
- Originality: How new or surprising is it?
- Feasibility: Could it realistically be built today?
- Usefulness: Would it genuinely help people?
- Investment worthiness: Would you invest in it overall?
- Each idea was rated by about 10 people.
Measuring “distance” between domains
- The team also measured how “far apart” each source–target pair was in meaning, using information from their Wikipedia pages.
- Think of every concept (like “octopus” or “car”) as a cluster of sentences on a giant map of ideas. The more different these clusters are, the more “semantically distant” they are.
- They then asked: Do pairs that are more distant tend to produce more original ideas?
What did they find?
Here are the key takeaways:
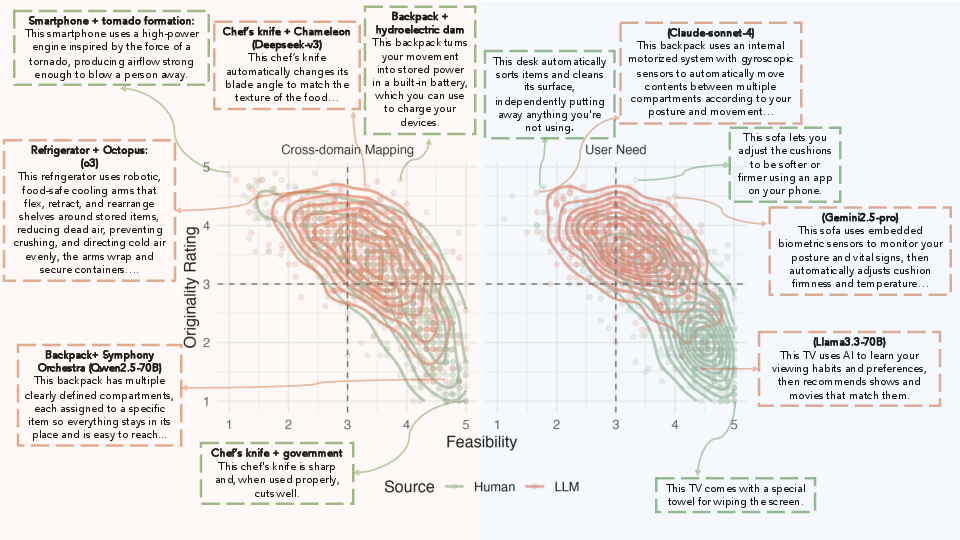
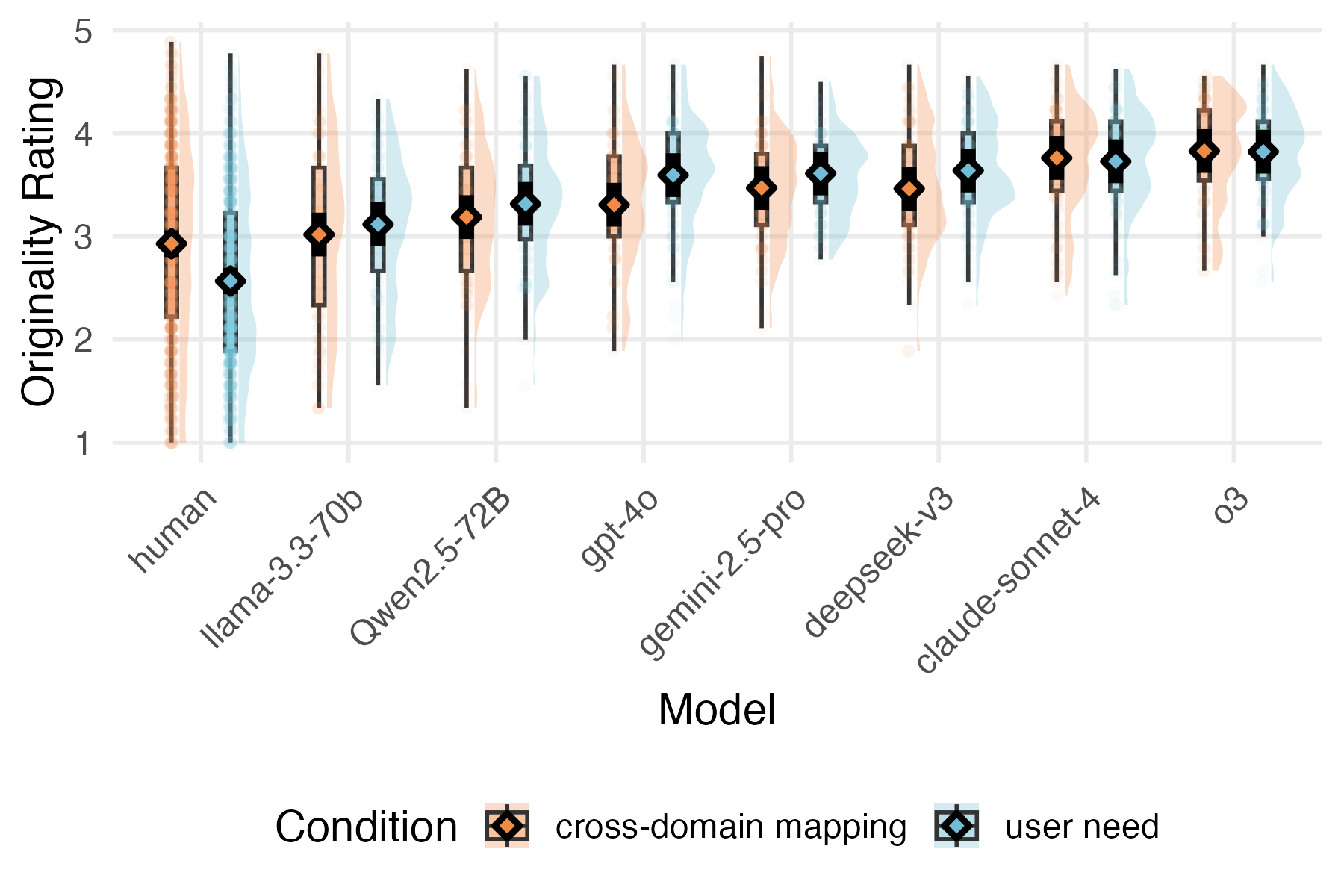
- Cross-domain mapping helped humans be more original. When people had to borrow from a distant source, they produced more surprising ideas than when they focused on user needs alone.
- LLMs were, on average, more original than humans across both tasks. Even without cross-domain instructions, AI models often produced ideas that seemed fresh and unexpected.
- Cross-domain mapping didn’t significantly boost LLM originality overall. It seems LLMs already draw from many associations (including far-away ones) even under the user-need prompt.
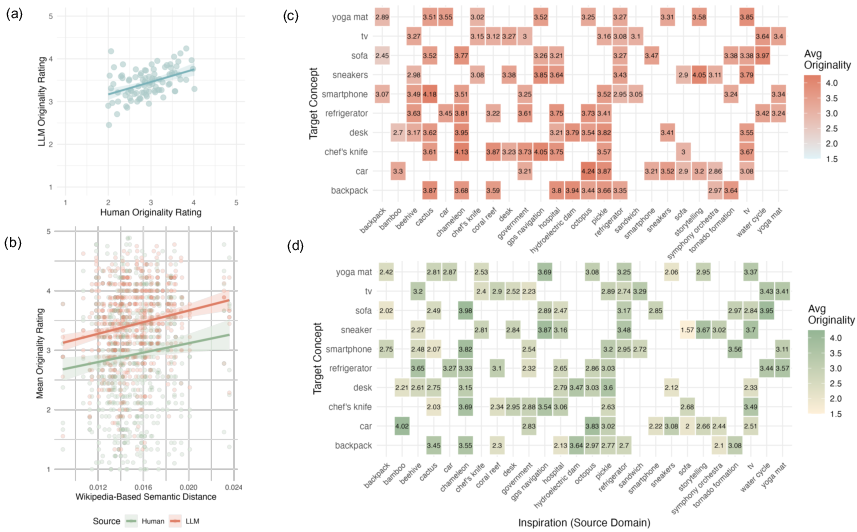
- The farther apart the source and target were in meaning, the more original the ideas. “Remote” pairs (like octopus → car) led to more creative results for both humans and LLMs, compared to closer pairs (like sofa → sneakers).
- There’s a trade‑off: more original ideas often looked less feasible. In other words, the more surprising the idea, the less likely raters thought it could be built right now. Originality didn’t strongly predict usefulness, but usefulness strongly drove overall investment judgments.
- Top human ideas could beat LLMs. In the most original 10% of ideas, humans slightly edged out LLMs—showing that people can still invent standout concepts.
Why does this matter?
This study suggests a practical way to spark creativity in people: deliberately mix ideas from distant domains. It also shows that AI can be highly creative without special prompting, but might benefit most when inspiration sources are really far away.
In simple terms:
- For humans: “Serendipity by design” works—randomly pairing a product with a very different source can break mental habits and produce new ideas.
- For AI: Since LLMs already explore broad connections, the benefit of explicit cross-domain prompts is smaller. Still, very distant pairings tend to help.
- For innovation: Pushing for originality often means accepting lower feasibility at first. That’s normal—many breakthrough ideas seem unrealistic until technology and methods catch up.
Final takeaway
If you want more creative ideas, don’t just tweak what exists—borrow boldly from distant places. Whether you’re a person or an AI, looking far outside the usual box (the “semantic neighborhood”) raises your chances of inventing something truly original.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored in the study and what future researchers could address:
- Rephrasing confound: All ideas (including those generated by the o3 model) were rephrased by o3 before rating, potentially biasing style, clarity, and perceived originality in ways that may favor its own outputs; it is unclear how results change if rephrasing is done by humans or by a neutral ensemble of models.
- Loss of mechanism/context in evaluation: Removing the analogy or user-need framing in the rephrased versions may strip mechanistic details that drive perceived originality, feasibility, or usefulness; the impact of evaluating with vs without the original context remains untested.
- Single-shot LLM sampling: Each LLM produced only one generation per target–source pair in the cross-domain condition; the stability of model effects under repeated sampling (varying seeds/temperatures/top‑p) is unknown.
- Non-uniform decoding settings: Temperature was set to 1 “where applicable,” but sampling strategies likely differed across APIs/models; effects attributable to model capability vs decoding configuration are not disentangled.
- Between-subjects human design: Humans were assigned to either cross-domain or user-need prompts between subjects, which reduces power and introduces individual differences; within-subjects or crossover designs could better isolate prompt effects.
- Individual differences in human creativity: No measures of baseline creativity, domain expertise, or associative hierarchy were collected; whether cross-domain prompts benefit specific subpopulations (e.g., high vs low baseline creativity) is unknown.
- Generalizability across domains: Tasks were limited to everyday consumer products; it is unclear whether the findings extend to scientific hypothesis generation, engineering design, artistic domains, or complex systems problems.
- Target and source set coverage: Only 10 targets and 26 sources were sampled; whether results replicate with broader, systematically stratified sets (and balanced coverage of abstract vs concrete, natural vs technological, etc.) is unknown.
- Within-domain vs truly cross-domain mappings: Because targets could also be sources (excluding self-pairs), some pairings may be same-domain; the differential effect of strictly cross-domain vs within-domain mappings (controlling for semantic distance) was not isolated.
- Semantic distance measurement validity: Distance was computed via Wikipedia-based embeddings and a specific quantization/JS divergence pipeline; whether results replicate with alternative distance metrics (e.g., human-perceived distance, WordNet/ConceptNet, citation graphs, or LLM-internal measures) is unknown.
- Distance–originality curve shape: Only a positive linear trend was reported; possible non-linearities (e.g., an inverted‑U where extremely remote inspirations reduce usefulness/feasibility) and distance thresholds that maximize investment-worthiness were not examined.
- Distance vs feasibility/usefulness trade-offs: While originality–feasibility showed a strong negative correlation overall, the relationship between semantic distance and feasibility/usefulness (and investment worthiness) was not analyzed; the “sweet spot” in distance remains unidentified.
- Content-level mechanisms of transfer: Preliminary observations suggest humans favor perceptual/sensorimotor mappings while LLMs favor functional/mechanistic ones, but this was not coded or quantified; which mapping types causally drive originality and investment-worthiness is an open question.
- Prompt engineering for LLM analogies: The cross-domain instruction asked to “translate a property” but did not leverage chain-of-thought, explicit structure mapping, or stepwise analogical alignment; whether richer analogical prompting boosts LLM originality (especially at high semantic distances) is untested.
- Iterative creativity workflows: The study used one-shot ideation; real-world creativity is iterative. How cross-domain prompts affect multi-round critique, combination, refinement, or human–AI collaboration pipelines remains unexplored.
- Human–AI co-creation: Whether LLM-generated cross-domain inspirations, curated by distance or mapping type, can enhance human creativity (and vice versa) is untested.
- Rater reliability and expertise: Inter-rater reliability (e.g., ICC) was not reported, and raters were general crowd workers; whether expert raters (designers, engineers, product managers) or multi-criteria panels would produce different judgments is unknown.
- External/real-world validity: Outcomes were “perceived” originality/feasibility/usefulness; links to downstream metrics (e.g., patent novelty, prototyping cost, expert feasibility audits, user testing) are missing.
- Cultural and linguistic scope: Participants were English-speaking online adults; cross-cultural generalizability in both ideation and evaluation is untested.
- Practice and fatigue effects: Participants generated 10 ideas each, but potential learning, fatigue, or order effects across tasks were not analyzed.
- Potential contamination in LLM training data: Models may have seen similar prompts or product-feature ideas during pretraining; the extent to which observed originality reflects recombination vs memorization is not assessed.
- Calibration of prompt difficulty: The user-need and cross-domain prompts impose different cognitive demands; equivalence in difficulty and time-on-task for humans (and effective parity for LLMs) was not established.
- Source/target familiarity: The role of participants’ or raters’ familiarity with specific targets/sources in shaping originality and feasibility judgments remains unmeasured.
- Optimization of source selection: How to pre-select inspiration sources (by distance, category, or property richness) to systematically maximize originality without sacrificing feasibility is not addressed.
- Model-level factors: Differences among LLMs were observed, but the contributions of model size, training data breadth, reasoning capabilities, or system prompts were not decomposed.
- Safety and impracticality screening: High‑originality ideas can be unsafe or ethically problematic; systematic evaluation for safety, liability, or regulatory feasibility was not included.
- Replicability across paraphrasing methods: It remains unknown whether results replicate if ideas are rated verbatim, paraphrased by humans, or paraphrased by a different (or multiple) models.
Glossary
- Affordances: Action possibilities or opportunities for interaction that an environment or object offers to an agent. "aligning with and projecting from the source structure can highlight implicit limitations in the target (constraints) as well as suggest new possibilities for intervention (affordances)."
- Analogy: A reasoning process that aligns relational structures between a source and a target to support inference and insight. "An analogy can support systematic inference, by aligning relational structure between a source and a target -- importing a coherent system of relations that makes previously overlooked aspects of the target problem visible"
- Associative hierarchies: The organization of semantic memory such that some individuals retrieve dominant, close associates (steep) while others more readily access distant associates (flat). "Semantic retrieval is not uniform, but organized into associative hierarchies, such that individuals with steep hierarchies prioritize dominant, conventional associates, whereas those with flatter hierarchies more readily connect distant associates"
- Cosine similarity: A measure of similarity between vectors based on the cosine of the angle between them, commonly used with embeddings. "computing the cosine similarity between each embedding and uniformly distributed points on the surface of the unit sphere and normalising."
- Cross-disciplinary corpora: Large datasets drawn from multiple academic or practical fields used to train models like LLMs. "Trained on massive, cross-disciplinary corpora, LLMs can detect structural parallels across seemingly unrelated fields and generate cross-domain mappings at scale -- something that may drive their creative ability."
- Cross-domain mapping: An intervention that forces mapping of properties or relations from a distant source domain onto a target to spur creative ideas. "We evaluate a promising but largely untested intervention for creativity: forcing creators to draw an analogy from a random, remote source domain (``cross-domain mapping'')."
- Cultural-evolution paradigms: Frameworks that model how ideas evolve and spread through populations over iterative cycles of variation and selection. "in multi-agent or cultural-evolution paradigms, or in humanâAI collaborations."
- Dimensionality reduction technique: A method that transforms high-dimensional representations into a lower-dimensional (or discretized) form while preserving structure. "We use the dimensionality reduction technique from \citet{conklin2025information}, which takes the embeddings and computes a soft quantization for each token"
- D_{KL}: The Kullback–Leibler divergence, a measure of how one probability distribution diverges from a second, reference distribution. "Semantic distance between a target and its inspiration was computed as the JensenâShannon divergence between their distributions ) at each layer, then aggregated."
- Embedding space: A continuous vector space where symbolic units (e.g., sentences) are represented to capture semantic relationships. "By conditioning these estimates , we get a distribution for each concept describing how it is represented in the model's embedding space."
- Estimated marginal means: Model-based means adjusted for other variables in the model, often used to summarize effects. "Diamonds indicate estimated marginal means, with error bars showing 95\% confidence intervals."
- Fixation: A cognitive tendency to stick with familiar representations or solutions, hindering exploration of alternatives. "Humans are notoriously prone to fixation: once a problem is framed in a familiar way, people tend to reuse known solutions within a single domain rather than scanning for distant alternatives across domains"
- Holm-adjusted: Refers to p-values corrected for multiple comparisons using the Holm–Bonferroni method. "Most LLMs were rated as statistically significantly more original than humans after correction for multiple comparisons (Holm-adjusted )"
- Jensen–Shannon divergence: A symmetric, smoothed measure of divergence between probability distributions derived from KL divergence. "Semantic distance between a target and its inspiration was computed as the JensenâShannon divergence between their distributions ) at each layer, then aggregated."
- Likert scales: Ordinal rating scales (e.g., 1–5) used to capture degrees of agreement or evaluation. "They rate each idea on four dimensions using 5-point Likert scales with clearly labeled endpoints, with the order of these ratings randomized between participants"
- Linear mixed-effects model: A statistical model that includes both fixed effects and random effects to account for grouped or repeated measures data. "We assessed originality using a linear mixed-effects model predicting originality ratings from each source of ideas, with random intercepts for participants (since each participant rated multiple ideas) and ideas (since each idea was rated by multiple participants)."
- Preregistered: Declared and time-stamped study plans and analyses made publicly available before data analysis. "This study was preregistered at Open Science Framework (\href{https://osf.io/fqavu/overview?view_only=65eca78986674d4aa77c38444af31f3c}{link})."
- Random intercepts: Random effects that allow each group (e.g., participant, item) to have its own baseline level in a mixed model. "We examined whether cross-domain prompting increases originality by fitting a linear mixed-effects model predicting originality ratings from idea source (human vs.\ LLM), condition (cross-domain mapping vs.\ user need), and their interaction, with random intercepts for participants and ideas."
- Remote association: A weak or distant semantic link between concepts that can underlie creative insights. "Our results highlight both the role of remote association in creative ideation and systematic differences in how humans and LLMs respond to the same intervention for creativity."
- Semantic distance: A quantitative measure of how dissimilar two concepts are in a semantic representation space. "Across both systems, greater semantic distance between target and inspiration domains predicted higher perceived originality."
- Semantic retrieval: The process of accessing information from semantic memory, influenced by associative structure. "Semantic retrieval is not uniform, but organized into associative hierarchies"
- Semantic space: An abstract space where meaning is represented such that distances reflect semantic relatedness. "traversing longer distances in semantic space or recombining elements drawn from distinct semantic domains"
- Sentence-transformer model: A neural model that maps sentences to embeddings optimized for semantic similarity tasks. "embedded these sentences using a pretrained sentence-transformer model (all-mpnet-base-v2)."
- Soft quantization: A differentiable or probabilistic assignment of continuous embeddings to discrete codebook points. "computes a soft quantization for each token"
- Structure-Mapping Theory: A theory proposing that analogical reasoning works by aligning relational structures between domains. "Structure-Mapping Theory \parencite{gentner1983structure} formalises the cognitive mechanism underlying cross-domain inspiration."
- Unit sphere: The set of points at distance one from the origin in a vector space, often used for normalized vectors. "points on the surface of the unit sphere "
- Unknown unknown: A gap in knowledge where individuals are unaware of what they do not know. "characterized by the classic `unknown unknown' problem"
Practical Applications
Overview
This paper tests “cross-domain mapping” (forcing creators to translate a property from a random, remote source domain into a target problem) as a scalable creativity intervention for both humans and LLMs. Key findings with practical implications:
- For humans, cross-domain mapping reliably increases originality versus a user-need framing.
- LLMs produce more original ideas than humans on average; explicit cross-domain prompts do not significantly boost LLM originality unless the source–target pair is very remote.
- Greater semantic distance between source and target increases perceived originality for both humans and LLMs.
- Originality negatively correlates with feasibility, and usefulness dominates investment-worthiness—highlighting the need for staged workflows that balance divergence and convergence.
Below are actionable applications for industry, academia, policy, and daily life, grouped into immediate versus longer-term horizons. Each item notes relevant sectors, candidate tools/workflows, and dependencies/assumptions affecting feasibility.
Immediate Applications
These can be deployed with today’s tools and evidence.
- Human ideation workshops that use cross-domain mapping to break fixation (industry, consulting, product design, marketing/advertising)
- Workflow: Provide random “inspiration source” cards, ask teams to name a source property, then translate it to the target product/service; prioritize more semantically distant sources for early rounds; converge with feasibility filters later.
- Tools: Printable card decks; a simple web app or Miro/Mural plugin to randomize sources.
- Dependencies: Works best for early-stage ideation; facilitators should manage the originality–feasibility trade-off; applicability beyond consumer products needs moderation by domain experts.
- Distance-guided inspiration engines embedded in design tools (software, product design)
- Workflow: A plugin that, given a target (e.g., “refrigerator”), recommends source domains ranked by semantic distance (e.g., “tornado formation,” “octopus”) to maximize originality.
- Tools: Semantic-distance module using Wikipedia + sentence embeddings (e.g., all-mpnet-base-v2) with Jensen–Shannon divergence; API wrapper for Figma, Notion, Miro.
- Dependencies: Wikipedia-based distance can be swapped for domain-specific corpora; distance alone is not quality—include quick human screening.
- Cross-domain prompt packs for LLM-assisted brainstorming (software, education, product teams)
- Workflow: Prompt template that explicitly requires (1) naming a concrete property of the source and (2) translating it to the target, with a “distance knob” selecting remote sources.
- Tools: Prompt libraries for general LLMs; toggle between “user-need” and “cross-domain” frames; few-shot examples to favor functional/mechanistic transfers.
- Dependencies: The study showed limited average gains for LLMs; ensure source–target pairs are highly remote to see value.
- Stage-gated “diverge with distance, converge with feasibility” pipelines (industry R&D, innovation teams, venture studios)
- Workflow: Early sprint emphasizes high-distance analogies; mid-stage reframing/refinement; late-stage feasibility/usefulness scoring and prototyping.
- Tools: Kanban templates; dashboards that visualize originality vs feasibility; team prompts for critical appraisal.
- Dependencies: Requires discipline to manage transition from divergent to convergent phases; success metrics beyond perceived originality are needed.
- Normalized evaluation of ideas to reduce framing/style bias (innovation management, academia)
- Workflow: Use neutral rephrasing (LLM-based) to remove prompt framing before rating; collect crowd or internal ratings on originality, feasibility, usefulness, investment-worthiness.
- Tools: Lightweight rephrase service + rater task templates (e.g., Prolific); “Shark Tank”-style rating forms.
- Dependencies: Rater pools and instructions influence judgments; ratings are proxies—not market outcomes.
- Creative pedagogy: analogical thinking drills (education)
- Workflow: Assign students cross-domain mapping tasks with graded semantic distance; follow with reflection on feasibility trade-offs.
- Tools: Classroom card decks; LMS-integrated randomizer; rubric aligned to originality/feasibility/usefulness.
- Dependencies: Needs instructor guidance to connect analogies to course content; assessment rubrics should account for speculative ideas.
- Marketing and campaign concepting via remote analogies (marketing/advertising)
- Workflow: Generate metaphors and narratives by mapping from distant domains (e.g., “symphony orchestra” → service choreography).
- Tools: Distance-guided source selector; copywriting LLM prompts using explicit property-to-feature mapping.
- Dependencies: Brand safety and audience resonance checks; avoid overreliance on novelty at the expense of clarity.
- Bio-inspired brainstorming for robotics and hardware (robotics, manufacturing)
- Workflow: Use biological or physical systems as sources (octopus, beehive, water cycle) to spark mechanism-level concepts; triage with engineering feasibility reviews.
- Tools: Source domain library with mechanistic summaries; template prompts for functional analogy.
- Dependencies: Requires engineering oversight; not a substitute for simulation or prototyping.
- Patent strategy and prior-art expansion via distant fields (legal/IP, R&D)
- Workflow: Use distance-ranked sources to broaden novelty search and avoid obviousness; craft claims that bridge remote concepts.
- Tools: Semantic-distance explorer; LLM-aided claim drafting with analogy rationale.
- Dependencies: Legal review essential; embeddings should include patent corpora for accuracy.
- Personal “serendipity practice” for everyday problem-solving (daily life, coaching)
- Workflow: Daily journal prompt that picks a random distant domain and asks for a property-to-solution mapping for a personal task (time management, home organization).
- Tools: Mobile app or calendar bot; micro-prompts; spaced practice reminders.
- Dependencies: Benefits rely on regular use; expectations should focus on ideation, not immediate practicality.
Long-Term Applications
These require more research, scaling, domain adaptation, or integration with other systems.
- Distance-aware co-creative systems that adapt to user and task (software, product development)
- Concept: Interactive assistants that modulate source distance based on user feedback, task domain, and observed originality–feasibility balance; escalate remoteness early and auto-taper.
- Tools: Reinforcement learning on human feedback (RLAIF/RLHF) for “distance scheduling”; per-domain safety and feasibility models.
- Dependencies: Requires datasets linking distance to real-world outcomes; user modeling and robust UI.
- Domain-specific semantic distance models (healthcare, finance, energy, engineering)
- Concept: Replace general Wikipedia embeddings with sector corpora (e.g., clinical guidelines, grid operations) to propose truly relevant remote sources.
- Tools: Fine-tuned sentence encoders; knowledge graphs; hybrid symbolic–neural distance measures.
- Dependencies: Data access and curation; validation against domain experts.
- Multi-objective creativity optimizers that navigate originality–feasibility frontiers (industry, R&D)
- Concept: Generators that explicitly target Pareto-efficient ideas: first maximize distance/originality, then jointly optimize feasibility/usefulness via simulation or expert rules.
- Tools: Bayesian optimization/evolutionary search; domain simulators; cost/constraint models.
- Dependencies: Requires realistic feasibility proxies; careful calibration to avoid mode collapse.
- Scientific discovery and hypothesis generation across disciplines (academia, pharma, materials)
- Concept: Tools that propose cross-domain hypotheses (e.g., mechanisms from ecology applied to epidemiology) prioritized by distance and mechanistic alignment.
- Tools: Literature graph mining; mechanistic analogy prompts; evidence-tracing chains.
- Dependencies: Expert curation; downstream experimental validation; handling of false positives.
- Cross-agency policy innovation via analogical transfer (public policy, urban planning)
- Concept: Structured use of distant-domain analogies (e.g., circulatory systems → traffic flow) to ideate interventions; prioritize by feasibility and equity impact.
- Tools: Government innovation playbooks; distance dashboards; civic prototyping labs.
- Dependencies: Stakeholder engagement; rigorous pilot evaluation; ethical review.
- Workforce training in analogical reasoning and anti-fixation (HR, L&D)
- Concept: Longitudinal curricula that build skills in selecting and mapping remote sources; measure gains with standardized originality/feasibility tasks.
- Tools: Adaptive learning platforms; assessment banks; team-based exercises.
- Dependencies: Validation at scale; tailoring to roles (engineering vs design vs policy).
- Iterative, multi-agent human–AI creativity pipelines (software, research labs)
- Concept: “Cultural evolution” workflows where ideas mutate, recombine, and are critiqued by agents specialized for distance, feasibility, and usefulness; humans act as editors.
- Tools: Agentic frameworks; critique-and-revise loops; provenance tracking.
- Dependencies: Orchestration costs; alignment with team processes; evaluation benchmarks.
- Evidence-to-impact bridges: linking ratings to real outcomes (industry, academia)
- Concept: Longitudinal studies that track whether distance-induced originality predicts successful products, publications, or policies.
- Tools: A/B tests in innovation funnels; telemetry and KPI linking; causal evaluation methods.
- Dependencies: Access to sensitive performance data; time horizons; confound control.
- Safety, ethics, and IP governance for cross-domain ideation (policy, legal)
- Concept: Guardrails to prevent harmful analogies (e.g., misuse of biological mechanisms), clarify ownership for LLM-assisted analogies, and ensure fair credit in human–AI teams.
- Tools: Risk taxonomies; review checklists; provenance and consent logs.
- Dependencies: Regulatory frameworks; cross-jurisdictional harmonization; stakeholder input.
- Sector-specific testbeds for bio-inspired and remote-design prototypes (robotics, energy, mobility)
- Concept: Consortia that turn high-distance analogies (e.g., octopus-inspired adhesive mobility) into early prototypes with shared data on feasibility and cost.
- Tools: Shared IP pools; prototyping kits; simulation sandboxes.
- Dependencies: Funding; safety certifications; partner alignment.
- Education standards and assessments for creativity via distance (education policy)
- Concept: Integrate distance-based analogical tasks into standardized creativity assessments and curricula; provide teacher training and resources.
- Tools: Open content libraries; validated rubrics; teacher PD programs.
- Dependencies: Curriculum adoption cycles; psychometric validation; equity considerations.
Notes on general assumptions and dependencies across applications:
- Evidence is strongest for consumer product ideation; transfer to high-stakes domains (e.g., healthcare, critical infrastructure) demands domain oversight.
- LLM benefits from cross-domain prompts appear when source–target pairs are highly remote; adaptive source selection is key.
- Semantic distance boosts originality but can harm feasibility—workflows must explicitly manage this trade-off.
- Ratings are perception-based proxies; downstream piloting and measurement are necessary to validate real-world value.
Collections
Sign up for free to add this paper to one or more collections.

