Nested Browser-Use Learning for Agentic Information Seeking
Abstract: Information-seeking (IS) agents have achieved strong performance across a range of wide and deep search tasks, yet their tool use remains largely restricted to API-level snippet retrieval and URL-based page fetching, limiting access to the richer information available through real browsing. While full browser interaction could unlock deeper capabilities, its fine-grained control and verbose page content returns introduce substantial complexity for ReAct-style function-calling agents. To bridge this gap, we propose Nested Browser-Use Learning (NestBrowse), which introduces a minimal and complete browser-action framework that decouples interaction control from page exploration through a nested structure. This design simplifies agentic reasoning while enabling effective deep-web information acquisition. Empirical results on challenging deep IS benchmarks demonstrate that NestBrowse offers clear benefits in practice. Further in-depth analyses underscore its efficiency and flexibility.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What Is This Paper About?
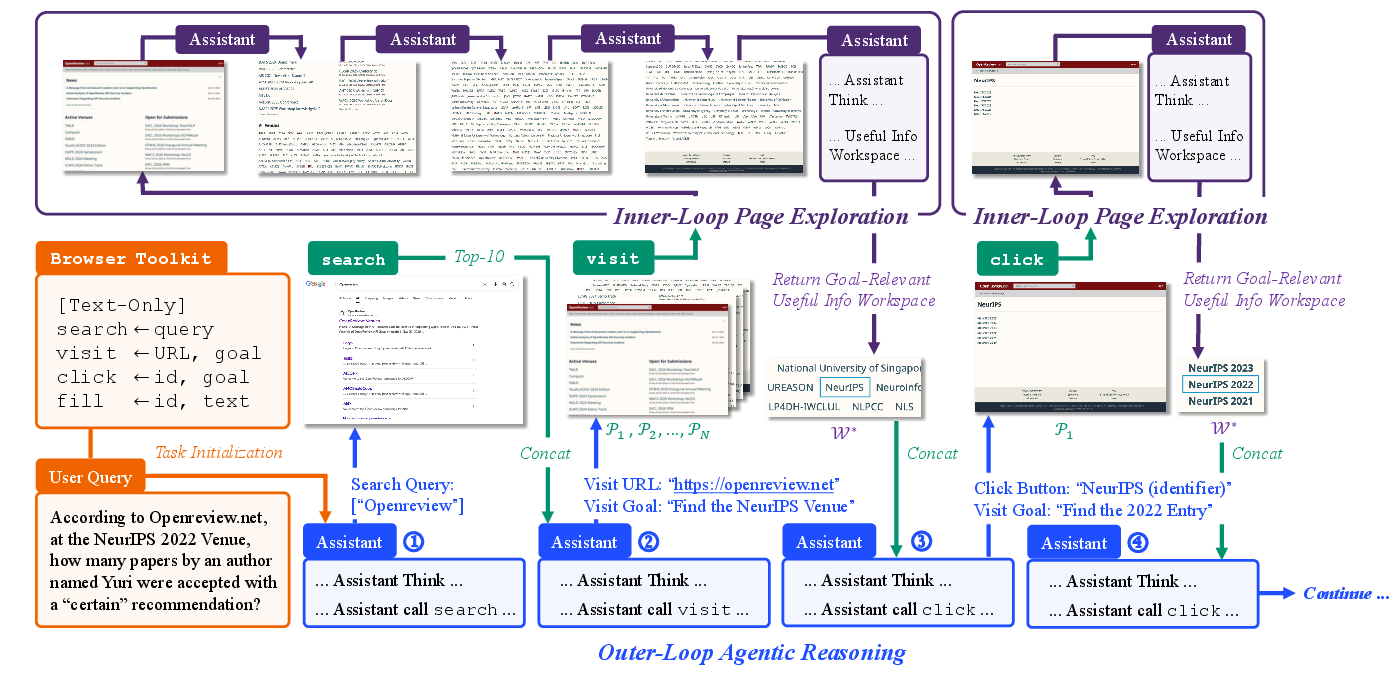
This paper is about teaching AI “research assistants” to use the web more like a real person. Instead of only grabbing short search snippets or downloading a whole page at once, the AI learns to actually “browse” — searching, opening pages, clicking buttons, and filling forms — while keeping its reading focused so it doesn’t get overwhelmed by huge webpages. The authors call their approach Nested Browser-Use Learning, or NestBrowse.
What Questions Did the Researchers Ask?
They set out to answer a few simple questions:
- Can we give an AI a very small set of browser skills that still cover almost everything it needs to do on the web?
- Can we organize the AI’s work so it thinks and plans at a high level, while skimming pages in a separate, tidy way that only keeps the useful bits?
- Can one model learn both parts at the same time and actually perform better on tough web research tasks?
How Does It Work?
Think of the AI like a careful detective with two “loops” (two modes of working). One loop plans the investigation; the other loop skims pages and takes notes.
- A minimal browser toolkit: The AI only learns four actions, like a person using a browser:
- search: ask a search engine for results
- visit: open a web page
- click: press a button or link on the page
- fill: type into a box or form (like a search bar or login field)
These four are enough to reach both “static” info (already on the page) and “dynamic” info (which appears only after you click or type).
- A “nested” workflow:
- Outer loop (plan and act): The AI thinks about the goal, decides which tool to use next (search, visit, click, fill), and keeps track of the overall progress — like a detective planning the next step.
- Inner loop (skim and extract): When it opens or changes a page, it doesn’t dump the entire page into its memory. Instead, it skims the page piece by piece, keeps only the parts related to the goal, and throws away the rest. It’s like taking notes from a long article — just the relevant facts, not every word.
Why skip scrolling or page-wide “find”? Because the important part isn’t seeing everything; it’s finding just what matters for the goal.
- How it’s trained:
- Imitation learning: The model learns by studying good examples of browsing and note-taking.
- Rejection sampling: If an example is messy (wrong format, impossible tool use, or wrong final answer), they throw it out. This helps the AI learn from high-quality habits.
- Multi-task learning: The AI learns two skills at once — outer-loop planning and inner-loop note-taking — so they work smoothly together in one brain.
What Did They Find, and Why Is It Important?
They built two versions of their AI (a smaller 4-billion-parameter one and a larger 30-billion-parameter one) and tested them on several tough web research benchmarks in English and Chinese (like BrowseComp and GAIA). The key takeaways:
- Strong performance, even for the small model: With just four tools and the nested approach, the small model beat or matched many bigger systems that only used simple search and page fetch.
- Less clutter, better thinking: Extracting only goal-related bits from pages kept the AI’s memory from overflowing, so it could keep going on long tasks instead of getting stuck.
- Each part helps the other: Better page-skimming (inner loop) improved overall task success (outer loop). Good notes make good decisions.
- Simple beats complicated: They tested different setups and found that a minimal set of tools plus goal-focused extraction outperformed bulkier or noisier approaches.
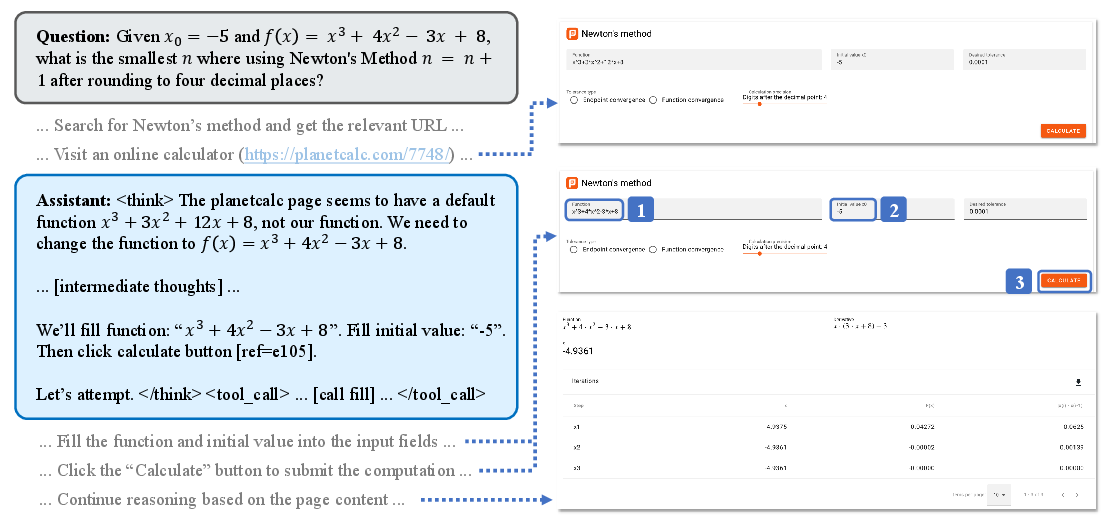
- Real “web use,” not just reading: In a case study, the AI didn’t try to calculate a tricky number in its head; it opened an online calculator and used it. That’s like using the web’s built-in tools, not just reading web pages.
This matters because it shows that smart design (good tools and a neat workflow) can matter more than simply making the model huge. It also unlocks the “dynamic web” — places where you must click, log in, or interact to get the answer.
What’s the Bigger Impact?
- More capable web agents: AI can navigate complex sites, handle forms, and pull out exactly what’s needed, making it more reliable for research, study help, and investigations.
- Efficiency over size: Smaller, cheaper models can perform strongly if they use the web wisely, which makes advanced AI tools more accessible.
- Beyond static pages: Treating the web as a giant toolbox (calculators, converters, interactive tables) opens up new ways for AI to solve problems.
- Future directions: Today, NestBrowse uses text-only pages. In the future, adding images or videos (for charts, screenshots, or diagrams) could make it even more powerful — but also more complex.
Overall, NestBrowse shows a practical and elegant way to make AI better at real browsing: plan smartly, interact simply, and only keep what matters.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and opportunities for future work that the paper leaves open. Each point is concrete and actionable.
- Multimodal browser-use: The system is text-only; evaluate and integrate vision (e.g., screenshots, layout understanding), audio/video, and OCR for image-embedded text, with benchmarks that require non-textual cues.
- Omission of scroll and in-page search: Provide empirical analyses on tasks that require infinite scroll, lazy-loaded content, pagination, and on-page find; quantify when these actions are indispensable and how to include them minimally.
- Action coverage beyond click/fill: Assess whether minimal actions should include hover, drag-and-drop, keyboard shortcuts (e.g., Enter, Tab), dropdown selection changes, file upload, right-click menus, and copy/paste; design and test a principled extension set.
- Back/forward/history and URL manipulation: Investigate navigation primitives (back, forward, open in new tab, modify query parameters) and their impact on task success and efficiency.
- Segmentation policy for inner-loop page processing: Specify and compare segmentation strategies (DOM blocks, viewport-length chunks, semantic clustering); study the effect of granularity on recall, precision, and latency.
- Definition and training of the extraction function f: Detail the architecture and training signals for goal-relevant extraction; compare rule-based, retrieval-based, and neural summarization variants and measure trade-offs.
- Provenance preservation: Ensure inner-loop outputs retain source locators (URL, DOM path, timestamps) for verification and auditing; evaluate citation fidelity and support evidence linking in final answers.
- Handling web variability and blockers: Systematically address cookies/GDPR banners, pop-ups/modals, CAPTCHAs, paywalls, and authentication; implement robust detection, bypass strategies, and evaluate success rates.
- Headless rendering fidelity and bot detection: Quantify cases where headless Playwright yields content different from real-user browsers or is blocked; measure impact on accuracy and propose mitigations.
- Cross-browser/platform generalization: Test across Chromium, Firefox, WebKit, and mobile web; analyze portability and performance differences.
- Multi-tab and parallel browsing: Explore concurrent tab management, scheduling, and merging evidence streams; quantify gains in long-horizon tasks.
- Memory and long-horizon constraints: Study sensitivity to the 100-tool-call cap and 128K context limit; design persistent/episodic memory and compression policies to extend horizons safely.
- Workspace management: Define pruning, deduplication, and prioritization policies for the inner-loop workspace; evaluate overflow handling and its effect on downstream reasoning.
- Caching and reuse: Introduce page/content caching across turns and tasks; measure reductions in latency, bandwidth, and redundant actions.
- Reliability and error recovery: Develop structured error handling for failed actions (timeouts, non-interactable elements, stale DOM); evaluate recovery strategies and their impact on success rates.
- Safety and compliance: Assess potential side effects of fill/click on live services (e.g., submitting forms); propose sandboxing, rate-limiting, and ethical safeguards; measure adherence to robots.txt and site policies.
- Training data coverage and diversity: The training relies primarily on SailorFog-QA-V2 (English); evaluate multilingual/multidomain training sets (Chinese, legal, medical, transactional) and their impact on generalization.
- Bias from rejection sampling: Requiring correct final answers for trajectory acceptance may bias toward easy or shortcut strategies; compare with reward modeling, offline RL, or curriculum learning that tolerates partial success.
- Lack of reinforcement learning: Investigate RL or hybrid IL/RL for optimizing tool-use efficiency, exploration, and long-term planning under sparse rewards.
- Hyperparameter sensitivity: Systematically ablate λout/λin, segmentation size, search top-k, tool-call caps, and context limits; publish sensitivity curves and recommended settings.
- Evaluation methodology: Reduce reliance on LLM-as-a-Judge (GPT-4.1) by adding exact-match/regex checks, human evaluation, inter-rater agreement, and statistical significance testing; report confidence intervals.
- Benchmark breadth: Extend beyond GAIA (text-only subset) and BrowseComp to include transactional workflows, authenticated sessions, and multimodal tasks; measure robustness under realistic constraints.
- Formal minimality/completeness claim: Provide a formal model of web interaction and prove (or refute) that {search, visit, click, fill} is minimally complete for information access; identify edge cases that break completeness.
- Detecting and leveraging embedded web utilities: Generalize the calculator case to discover and safely use diverse embedded tools (tables with filters, code runners, spreadsheets); design detection heuristics and utility-use policies.
- Query planning and search engine diversity: Study query reformulation strategies, multi-engine search (Bing, DuckDuckGo), locale/language effects, and top-k selection; quantify gains from adaptive search.
- Robustness to adversarial or noisy pages: Evaluate susceptibility to misleading content, advertisements, SEO spam, and dynamically injected noise; add filters and calibration signals to safeguard reasoning.
- Hallucination and faithfulness in extraction: Measure precision/recall of inner-loop extraction with ground-truth annotations; implement uncertainty estimates and fallback mechanisms (e.g., selective raw content injection) when confidence is low.
- Latency and resource profiling: Report wall-clock time per task, average number of actions, bandwidth, and compute overhead; compare NestBrowse vs. naïve/alternative strategies under identical conditions.
- Reproducibility and deployment details: Release full environment configs (Playwright versions, user agents, network settings), seeds, and trajectories; quantify variability across runs and sites that change over time.
- Data contamination checks: Audit training/evaluation datasets for leakage (overlap with benchmarks) and report contamination metrics.
- Integration with external memory/RAG: Explore hybrid designs that combine browser-use with retrieval-augmented generation, long-term memory, and tool-aware knowledge stores; measure complementary gains.
- Ethical and legal considerations: Address compliance with website terms, GDPR, copyright, and responsible data use; propose auditing frameworks for agent behaviour at scale.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now, leveraging the paper’s minimal browser toolkit (search, visit, click, fill), nested outer/inner loops, and multi-task imitation learning to keep agent contexts compact and focused.
- Deep Research Copilot for Analysts (software, finance, media, consulting): Automates multi-step evidence gathering across dynamic sites (reports, filings, blogs, forums), synthesizing goal-relevant snippets rather than entire pages.
- Tools/products/workflows: “Agentic Research” workspace; goal-aligned page extractor; context-budget controller; Playwright-based headless browser integration.
- Assumptions/dependencies: Access to Google search; websites without heavy anti-bot measures; legal allowance for scraping; stable DOM snapshots; text-only browsing suffices.
- Competitive Intelligence and Market Monitoring (finance, e-commerce, energy): Tracks competitors’ product pages, pricing widgets, release notes, and investor updates that load client-side or behind tabs/forms.
- Tools/products/workflows: Scheduled agents that “visit–click–extract” updates; evidence diffing; alert pipelines (Slack/Email).
- Assumptions/dependencies: Rate-limit handling; site terms of service; predictable dynamic elements; no CAPTCHA or strong bot detection.
- Regulatory and Policy Change Tracking (policy, finance, healthcare, energy): Monitors government/regulator portals (often dynamic, form-driven) for new rules, notices, public comments, and tariff changes.
- Tools/products/workflows: “RegTech sweeper” agents; governance dashboards; change summaries anchored to goal-relevant excerpts.
- Assumptions/dependencies: Textual access is sufficient; login not strictly required; agency portals permit automated access.
- Web ETL for Dynamic Sites (software/data engineering): Extracts structured, goal-specific content from SPA pages, pagination behind buttons, and form-driven workflows.
- Tools/products/workflows: Dynamic Web ETL pipelines; “visit/click/fill” macros; schema mappers to data warehouses.
- Assumptions/dependencies: Playwright compatibility; deterministic loading; minimal need for visual cues; careful handling of JavaScript timing.
- Customer Support Knowledge Retrieval (software/support): Pulls precise answers from help centers, community threads, and dynamic FAQs without flooding contexts with redundant page text.
- Tools/products/workflows: Tier-1 agent assistant; “useful_info” workspace injection to ticket systems.
- Assumptions/dependencies: Text-only extraction covers most FAQs; consistent DOM structure; no paywalled content.
- Legal and Due Diligence Evidence Gathering (legal, finance): Locates and synthesizes filings, case summaries, ownership records, and form-mediated registry results.
- Tools/products/workflows: Evidence notebooks; chain-of-custody logs with serialized tool calls/responses; audit exports.
- Assumptions/dependencies: Compliance with data usage/legal constraints; source reliability; reproducible tool traces.
- Fact-Checking and Misinformation Debunking (media, policy): Assembles goal-aligned excerpts from primary sources (press releases, official datasets) and dynamic widgets to verify claims.
- Tools/products/workflows: “Claim-to-evidence” pipelines; provenance tagging; LLM-judge fallback for fuzzy matches.
- Assumptions/dependencies: Judge models for answer verification; reliable source identification; text suffices for verification.
- Academic Literature and Institutional Info Search (academia): Navigates university, grant, and conference pages (often tabbed/filtered) to extract deadlines, eligibility, and calls.
- Tools/products/workflows: Research admin assistant; nested exploration of segmented pages; citation-ready summaries.
- Assumptions/dependencies: Most academic portals are text-forward; consistent filters/forms; permissive access.
- SEO and Content Strategy Assistant (marketing): Gathers SERP results, competitor content structure, and site internal linking exposed via clicks/tabs for strategy briefs.
- Tools/products/workflows: SERP-to-brief workflows; topic cluster maps; content gap detection.
- Assumptions/dependencies: Google SERP access; site structures not heavily obfuscated; safe scraping practices.
- Procurement & Vendor Risk Checks (enterprise): Extracts certifications, compliance statements, and policy pages hidden behind tabs/forms from supplier sites.
- Tools/products/workflows: Vendor onboarding agent; automated evidence folders with goal-aligned excerpts.
- Assumptions/dependencies: Public pages accessible; stable page elements; legal/compliance sign-off.
- Public Health and Safety Alerts Aggregation (healthcare/public sector): Monitors advisories, recalls, and dynamic dashboards (e.g., case counts, weather alerts) to produce focused summaries.
- Tools/products/workflows: Alert collectors; threshold-based notifications; evidence attachment for traceability.
- Assumptions/dependencies: Textual dashboards; predictable update cadence; no visual-only charts required.
- Personal Research Assistant for Travel/Shopping/Forms (daily life): Finds policies, fees, or availability hidden behind tabs and form inputs; invokes web utilities like calculators when needed.
- Tools/products/workflows: “Click–fill–extract” micro-flows; itinerary and cost calculators; booking pre-checks.
- Assumptions/dependencies: No complex authentication; sites allow automated interaction; text suffices over visuals.
- Web App QA: Goal-Aligned Content Verification (software QA): Validates that key content appears under specific user actions (e.g., clicking “Details” reveals required fields).
- Tools/products/workflows: Test agents with structured tool serialization; regression snapshots of “useful_info.”
- Assumptions/dependencies: Stable selectors; deterministic UI state; non-visual assertions acceptable.
- Cross-lingual Research Transfer (academia/industry): Despite English-only training, agents generalize to Chinese benchmarks; useful for bilingual evidence synthesis.
- Tools/products/workflows: Dual-language research assistants; cross-market monitoring.
- Assumptions/dependencies: Adequate tokenization/transliteration; site content predominantly textual; occasional translation support.
Long-Term Applications
These use cases require further research, scaling, or development (e.g., multimodal perception, stronger reliability guarantees, robust anti-bot adaptation, or transactional capabilities).
- Multimodal Web Agents (software, robotics, education): Extend nested browsing to vision/audio for charts, infographics, maps, and UI affordances that are visually encoded.
- Tools/products/workflows: VLM-enhanced “inner loop”; visual DOM synthesis; screenshot-to-goal extraction.
- Assumptions/dependencies: Robust VLMs; privacy safeguards; GPU-cost budgeting; site permission for image capture.
- End-to-end Transactional Agents (policy, finance, e-commerce): Execute full workflows (account creation, payments, filings) via click/fill plus secure authentication and identity verification.
- Tools/products/workflows: Secure credential vaults; human-in-the-loop approvals; compliance-grade audit trails.
- Assumptions/dependencies: Strong identity, fraud prevention, and consent; integration with 2FA/CAPTCHA solvers; legal frameworks.
- Standardized Browser-Action Protocols and Benchmarks (industry/academia): Common action/serialization standards for tool-integrated reasoning across agents and browsers.
- Tools/products/workflows: “Nested Browser Agent SDK”; shared trajectory formats; public leaderboards for deep IS tasks.
- Assumptions/dependencies: Community adoption; cross-browser compatibility; governance bodies.
- Enterprise Agentic Research Platforms with Knowledge Graphs (software): Fuse goal-aligned page extraction with graph construction and continual updates for institutional memory.
- Tools/products/workflows: Dynamic knowledge graph ETL; hypothesis-to-evidence linking; queryable provenance.
- Assumptions/dependencies: Scalable storage/indexing; data governance; change detection at scale.
- RegTech Auto-Compliance Sweepers (finance, healthcare, energy): Continuous monitoring that maps new rules/guidance to internal controls and evidence with minimal manual triage.
- Tools/products/workflows: Policy-to-control mapping; remediation suggestions; regulator-ready evidence packs.
- Assumptions/dependencies: Domain ontologies; reliable semantic linking; organizational integration.
- Personalized Bureaucracy Navigators (policy/daily life): Agents that guide users through complex government services, forms, and eligibility checks, adapting to local rules.
- Tools/products/workflows: Rule-aware “fill” strategies; dynamic checklist generation; escalation to human support.
- Assumptions/dependencies: Updated policy data; multilingual support; inclusive design; secure data handling.
- Scientific Discovery Assistants (academia): Orchestrate long-horizon research (hypothesis generation, dataset location, protocol synthesis) using nested browsing and goal-aligned extraction.
- Tools/products/workflows: Lab-ready research plans; replication package assembly; cross-source triangulation.
- Assumptions/dependencies: Domain-specific plugins; verifiable reasoning; peer-review integration.
- Managed Dynamic Web ETL with Anti-bot Adaptation (software): A service layer that robustly handles bot defenses, rate limits, and site changes while preserving goal alignment.
- Tools/products/workflows: Adaptive scrapers; retry/backoff strategies; site-specific extractors learned via imitation/RL.
- Assumptions/dependencies: Legal compliance; partnerships; resilient infrastructure.
- Education: Agent-Led Research Training (education): Curriculum and tools that teach students structured, goal-driven browsing and evidence curation via nested loops.
- Tools/products/workflows: Classroom sandboxes; graded trajectories; meta-cognitive feedback.
- Assumptions/dependencies: Pedagogical alignment; safe web environments; assessment standards.
- Security and Privacy Auditing Agents (software/security): Inspect sites for data exposure, consent flows, and privacy notice compliance via structured interactions.
- Tools/products/workflows: Compliance scanners; report generators; remediation tracking.
- Assumptions/dependencies: Legal authorization; clear audit scopes; handling of visual-only banners.
- Cross-lingual and Low-Resource Extensions (global policy/academia): Train agents across languages and scripts to support global research and governance.
- Tools/products/workflows: Multilingual pretraining; localized tool arguments; language-aware segmentation.
- Assumptions/dependencies: Diverse data; cultural context modeling; evaluation beyond LLM-as-a-judge.
- Verification-Centric Agents (software/policy): Replace LLM-judge evaluation with formal verification, rule-based checking, and source-consistency audits.
- Tools/products/workflows: Verifiable reasoning traces; constraint solvers; trust frameworks.
- Assumptions/dependencies: Mature verification stacks; community standards; performance/coverage trade-offs.
- Memory-Augmented, Long-Horizon Research Agents (software): Persistent memory of evidence workspaces over months, enabling progressive refinement and re-use.
- Tools/products/workflows: Retrieval-augmented inner-loop histories; episodic memory; project-level orchestration.
- Assumptions/dependencies: Scalable memory stores; drift detection; governance of evolving evidence.
Notes on Feasibility and Dependencies
- Core dependencies: Headless browser automation (e.g., Playwright), reliable DOM parsing into LLM-readable segments, access to search, and sufficient context windows.
- Key assumptions: Text-only extraction captures critical information; sites permit automated access; anti-bot mechanisms are manageable; answer verification (currently via LLM-as-a-judge) is acceptable.
- Constraints: No visual modality in current design; CAPTCHAs/2FA/logins may block automation; legal and ethical compliance for scraping; rate limits and site variability; robustness to page length and JavaScript timing.
- Risk mitigations: Human-in-the-loop review for critical domains; audit logs of tool calls/responses; provenance-attached summaries; adherence to site terms and data privacy regulations.
Glossary
- Action-space complexity: The size and granularity of the actions available to an agent; larger or more fine-grained action spaces increase decision difficulty. "increased action-space complexity substantially amplifies the decision burden"
- Agentic reasoning: Autonomous, goal-directed reasoning that interleaves thought with tool use. "This design simplifies agentic reasoning while enabling effective deep-web information acquisition."
- Client-side rendering: Generating and updating page content in the browser via scripts rather than server-side HTML. "including client-side rendering, dynamic content loading, form-mediated workflows, multi-step navigation, and page-internal online functionalities"
- Deep information-seeking (IS) tasks: Web-based tasks requiring iterative exploration and synthesis of hard-to-find information. "Deep information-seeking (IS) tasks \citep{webwalker, bc_en, xbench} require agents to acquire and integrate hard-to-find information from external sources through iterative reasoning and exploration."
- Dynamic information: Content exposed only through browser-level interactions or state changes. "dynamic information $\mathcal{I}_{\text{dynamic}$, exposed only via browser-level interactions such as client-side rendering, incremental loading, or user-triggered actions."
- Form-mediated workflows: Web processes that require filling and submitting forms to access functionality or information. "including client-side rendering, dynamic content loading, form-mediated workflows, multi-step navigation, and page-internal online functionalities"
- Goal-relevant page content extraction: Selecting and returning only page content pertinent to the current task goal. "Compressed applies goal-relevant page content extraction while retaining the original toolkit."
- Headless browser backend: A non-UI browser controlled programmatically for automation and scraping. "We implement a headless browser backend"
- Intra-page exploration: Systematic within-page analysis to extract information relevant to a goal. "an inner loop is instantiated for intra-page exploration."
- LLM-as-a-Judge protocol: Using an LLM to automatically assess the correctness of answers. "we adopt an LLM-as-a-Judge protocol \citep{llmasajudge} using GPT-4.1"
- Meta tool-use: Leveraging interactive utilities embedded in web pages as tools beyond static retrieval. "browser-use can be viewed as a form of meta tool-use"
- Multi-step navigation: Sequential navigation across multiple interactions/pages to accomplish a task. "multi-step navigation"
- Multi-task imitation learning: Training a model to imitate expert behaviors across multiple objectives simultaneously. "we develop a multi-task imitation learning formulation"
- Negative log-likelihood objective: A standard training loss equal to the negative log probability of target tokens. "We optimize a token-level negative log-likelihood objective:"
- Nested Browser-Use Framework: A two-level design with an outer reasoning loop and an inner page-exploration loop. "we introduce the Nested Browser-Use Framework that decouples browser interaction into an outer loop of tool-integrated reasoning and an inner loop of intra-page exploration"
- Nested Browser-Use Learning (NestBrowse): The proposed learning approach that equips agents with minimal browser tools and a nested interaction paradigm. "Nested Browser-Use Learning (NestBrowse)"
- Outer loop: The top-level cycle where the agent reasons and calls tools in a ReAct-style paradigm. "The outer loop follows a standard ReAct-style function-calling paradigm."
- Page-internal online functionalities: Interactive features within a page (e.g., calculators, widgets) beyond static content. "including client-side rendering, dynamic content loading, form-mediated workflows, multi-step navigation, and page-internal online functionalities"
- Page-transition actions: Operations that move the agent to a new page state and trigger inner-loop exploration. "Page-transition actions trigger an inner loop for intra-page exploration, which extracts and returns goal-relevant content to the outer loop, forming a nested interaction structure."
- Pass@1 metric: Accuracy measured using only the first attempt for each example. "All resumlts are reported using the pass@1 metric."
- Playwright: A browser automation framework for programmatic web interaction. "in Playwright for programmatic web interaction"
- ReAct-style function-calling paradigm: An agent pattern that interleaves free-form reasoning with tool/function calls. "These agents typically follow a ReAct-style function-calling paradigm"
- Rejection sampling: Filtering generated trajectories by rejecting those that violate format, validity, or correctness criteria. "we apply rejection sampling \citep{wu2025webdancerautonomousinformationseeking} to the generated trajectories"
- Semantic DOM snapshot: A structured representation of a page’s HTML and interactive elements for machine reading. "semantic DOM snapshot that exposes interactive-element identifiers"
- Tool-call hallucinations: Model errors where nonexistent tools or invalid arguments are produced. "Tool-call hallucinations. We reject trajectories that contain invalid tool names or tool arguments that cannot be correctly executed."
- Tool-integrated reasoning (TIR): A paradigm where models use external tools interleaved with reasoning to solve complex tasks. "Tool-integrated reasoning (TIR) equips models with external tools and enables them to interleave reasoning with tool invocation to solve complex tasks"
Collections
Sign up for free to add this paper to one or more collections.