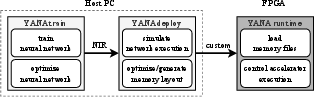
- The paper introduces YANA, an open-source FPGA-based SNN accelerator that bridges simulation-to-hardware gaps using a five-stage event-driven pipeline.
- The accelerator supports arbitrary connectivity and incorporates hardware-aware training and deployment to exploit both temporal and spatial sparsity.
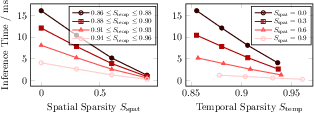
- Experimental evaluations on the SHD dataset show nearly linear inference scaling with increasing sparsity, confirming its resource-efficient processing.
YANA: An Open-Source Digital SNN Accelerator Bridging the Simulation-to-Hardware Divide
Motivation and Problem Context
The field of neuromorphic computing, driven by the promise of Spiking Neural Networks (SNNs), seeks energy-efficient real-time inference for temporally sparse data streams. The anticipated "Neuromorphic Advantage" derives from algorithmic properties such as sparse neuronal activations, temporal coding, and brain-inspired processing dynamics. However, a major barrier persists: the simulation-to-hardware gap. Most neuromorphic hardware remains proprietary, inaccessible, or limited in flexibility. This impedes HW/SW co-design, constrains algorithmic exploration, and prevents robust, hardware-validated benchmarking across the research community.
Existing FPGA-based SNN accelerators generally enforce constraints dictated by deep learning (DL) paradigms, such as layered, feed-forward connectivity and dense, clock-driven updates. These architectural choices hinder the exploitation of event-driven sparsity and recurrent topologies that are fundamental to SNNs. Therefore, there is a critical need for accessible, fully event-driven, and programmable neuromorphic accelerators that can handle arbitrary SNN graphs within open-source workflows.
YANA Architecture Design
YANA (Yet Another Neuromorphic Accelerator) directly addresses these limitations via an FPGA-based digital SNN accelerator and a tightly integrated software stack. The design is built upon the following architectural and algorithmic choices:
- Event-driven, five-stage pipeline: YANA processes event packets in a strictly event-driven manner; unused cycles incur no computational cost. The five stages—input, synapse, neuron, axon, and output—operate in a highly pipelined, tightly-coupled fashion, with all computation synchronized by input event flows rather than periodic clock triggers.
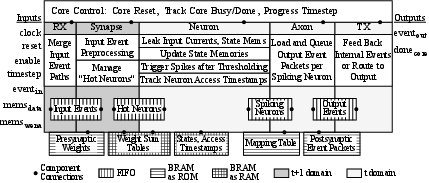
Figure 1: High-level block diagram of the YANA core detailing the five-stage event-driven processing pipeline.
- Support for arbitrary connectivity: Connections between any neuron pairs are possible via point-to-point addressing, enabling native support for complex recurrent or irregular SNN graphs.
- Timestep progression and deferred updates: Timestep advancement is workload-driven, allowing "faster-than-real-time" processing during batch inference. Neurons are marked as "hot" only on event receipt, deferring leak integration and updates. Membrane potential integration uses a look-up table (LUT) for the leak term, supporting precise fixed-point hardware implementation without runtime exponentiation overhead.
- Resource-efficient parameterization: The design is parameterized to allow optimal trade-off between on-chip resource usage and network scaling. On KR260 FPGA, a core utilizes 740 LUTs, 918 registers, 7 BRAMs, 24 URAMs, and supports up to 217 synapses and 210 neurons.
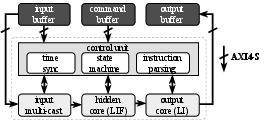
Figure 2: YANA system integration with AXI4 buffers, control unit, input multicasting, and separated input/hidden/output cores for processing.
Integrated Software Framework
A critical component of YANA is the open-source, modular software platform supporting the full SNN workflow:
The use of NIR as an IR ensures broad compatibility, facilitating future integration with other frameworks in the neuromorphic ecosystem.
Experimental Evaluation: Exploiting Sparsity
YANA's architectural claim—that it can exploit both temporal and spatial sparsity event-wise—was evaluated on the Spiking Heidelberg Digits (SHD) dataset. One-hidden-layer SNNs (100 LIF neurons) were deployed to FPGA. Temporal sparsity was varied by dropping input events, spatial sparsity by pruning weak synaptic weights. Inference performance was measured as average latency over multiple trials.
In high-sparsity regimes, the total runtime is dominated by the static overhead of the pipeline and control, but overall results demonstrate highly efficient exploitation of sparsity, with inference times on the order of 1–16ms for ∼500–1000ms-long input sequences.
Discussion and Implications
YANA delivers an accessible, programmable, and event-driven neuromorphic hardware research platform. By supporting arbitrary SNN connectivity and directly exploiting event sparsity, it enables both the implementation and hardware validation of advanced SNN algorithms that go beyond DL-constrained designs. Its open-source release, hardware-aware training pipeline, and emphasis on community compatibility are poised to drive benchmarking, innovation, and HW/SW co-design within neuromorphic research.
- Power efficiency—a central promise of SNN and neuromorphic hardware—remains to be quantified rigorously on deployment hardware. This will require empirical measurement and architectural enhancements (e.g., clock gating, power domain isolation).
- Structured layers and scalability are current limitations; though the architecture can express complex connectivity and weight sharing natively, support for convolutional layers and many-core NoC scaling are future roadmap items.
- Research impact: YANA provides a path toward robust, open benchmarking and rapid prototyping of event-driven SNN designs, closing the feedback loop that has previously been available only to those with access to proprietary hardware.
Conclusion
YANA represents a substantive step toward democratizing neuromorphic hardware research, bridging the simulation-to-hardware gap by providing a flexible, event-driven, FPGA-based SNN accelerator and integrated software framework. Its demonstrable ability to exploit sparsity directly on hardware and to accommodate arbitrary network graphs offers strong empirical support for neuromorphic architectures as a practical engineering solution. As open-source ecosystems solidify and power/throughput metrics are benchmarked, platforms such as YANA will be instrumental in translating the theoretical neuromorphic advantage into realized system-level gains.