- The paper demonstrates that generation-based extraction in instruct-tuned small language models yields statistically superior emotion vector separation compared to comprehension-based methods.
- It reveals that optimal emotion representations localize around mid-transformer layers, correlating with distinct behavioral regimes such as surgical, repetitive, and explosive outcomes.
- The study finds that RLHF exerts nuanced, model-dependent effects, enhancing extraction efficacy without fundamentally reconfiguring underlying emotion representations.
Extracting and Steering Emotion Representations in Small LLMs: Technical Analysis
Introduction
This work conducts a systematic examination of emotion representations within small LLMs (SLMs, 100M–10B parameters), focusing on extraction and causal intervention via activation steering (2604.04064). Prior studies have established the existence of discrete, linearly extractable emotion vectors in frontier-scale LLMs; however, it remains unresolved whether SLMs exhibit analogous internal structures or whether established extraction techniques—particularly Anthropic’s mean-subtraction method—transfer effectively to this scale. The paper undertakes a comparative evaluation of extraction methodologies, analyzes representational localization across depth and architecture, and probes the behavioral plasticity of SLMs under intervention, generating substantive recommendations for future interpretability efforts.
Methodological Contributions
The study benchmarks 9 models spanning 5 architectural families (GPT-2, Gemma, Qwen, Llama, Mistral). Two extraction approaches are contrasted: comprehension-based (forward-passing pre-authored texts) and generation-based (model-generated emotion-conditioned stories). A fixed set of 20 emotions, balanced across Russell’s valence-arousal axes, anchors the extraction stimuli. Notably, empirically, generation-based extraction achieves statistically superior vector separation (Mann-Whitney p=0.007; Cohen’s d=−107.5) in all instruct-tuned models examined.
The analysis localizes peak emotion vector separation to approximately the middle transformer layers (50% depth), echoing previously documented U-shaped representational concentration in larger models (see Figure 1).
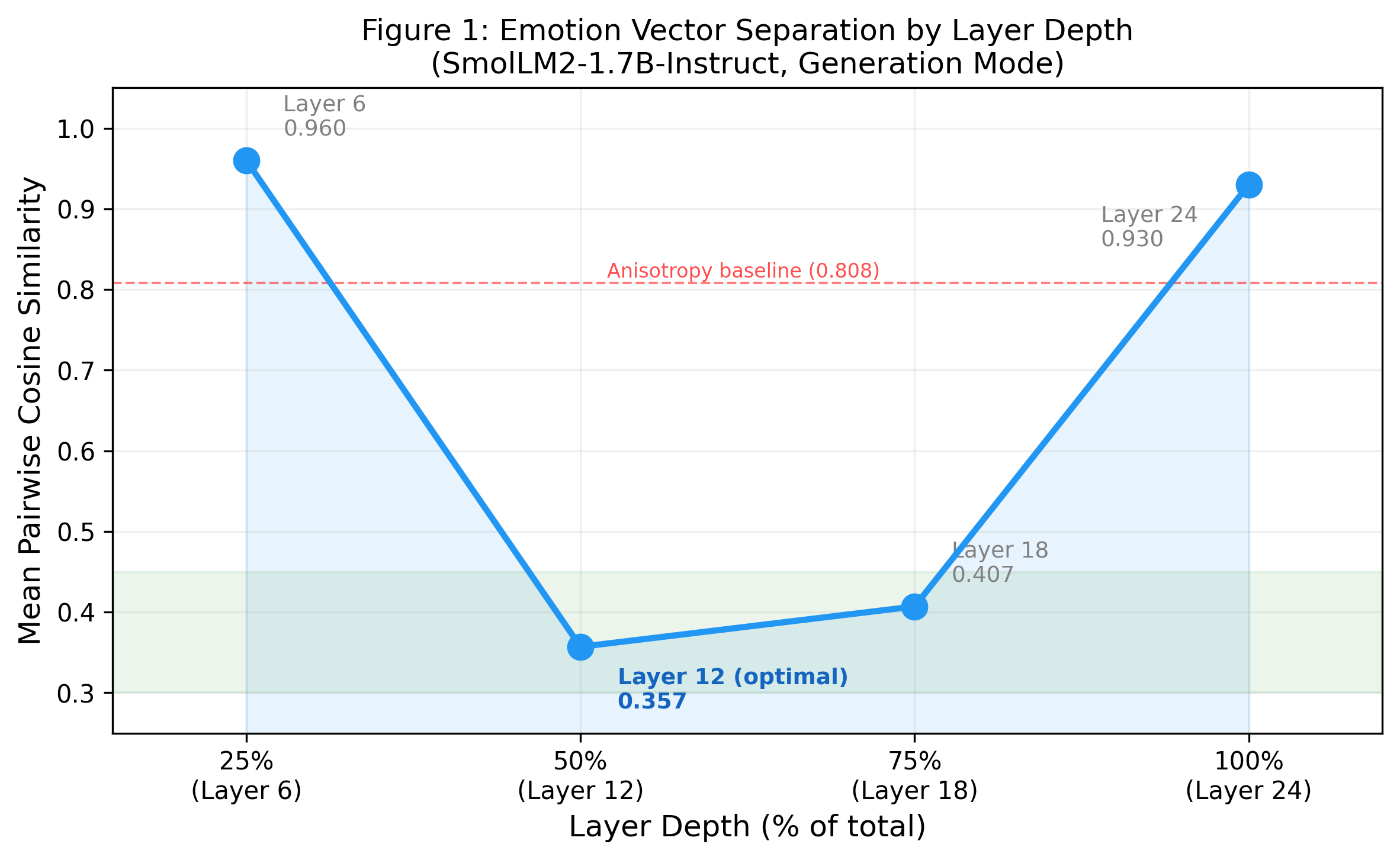
Figure 1: Emotion vector separation by layer depth in SmolLM2-1.7B-Instruct; middle layers maximize separability while initial and terminal layers are dominated by token identity and next-token-prediction features, respectively.
Comprehension-based extraction yields consistently moderate separation, with narrow variance (cosine similarity 0.59–0.67) across all architectures and parameter counts. In contrast, generation-based extraction, effective primarily in instruct-tuned models, exhibits wide variance contingent on both architecture and RLHF procedures (Figure 2).
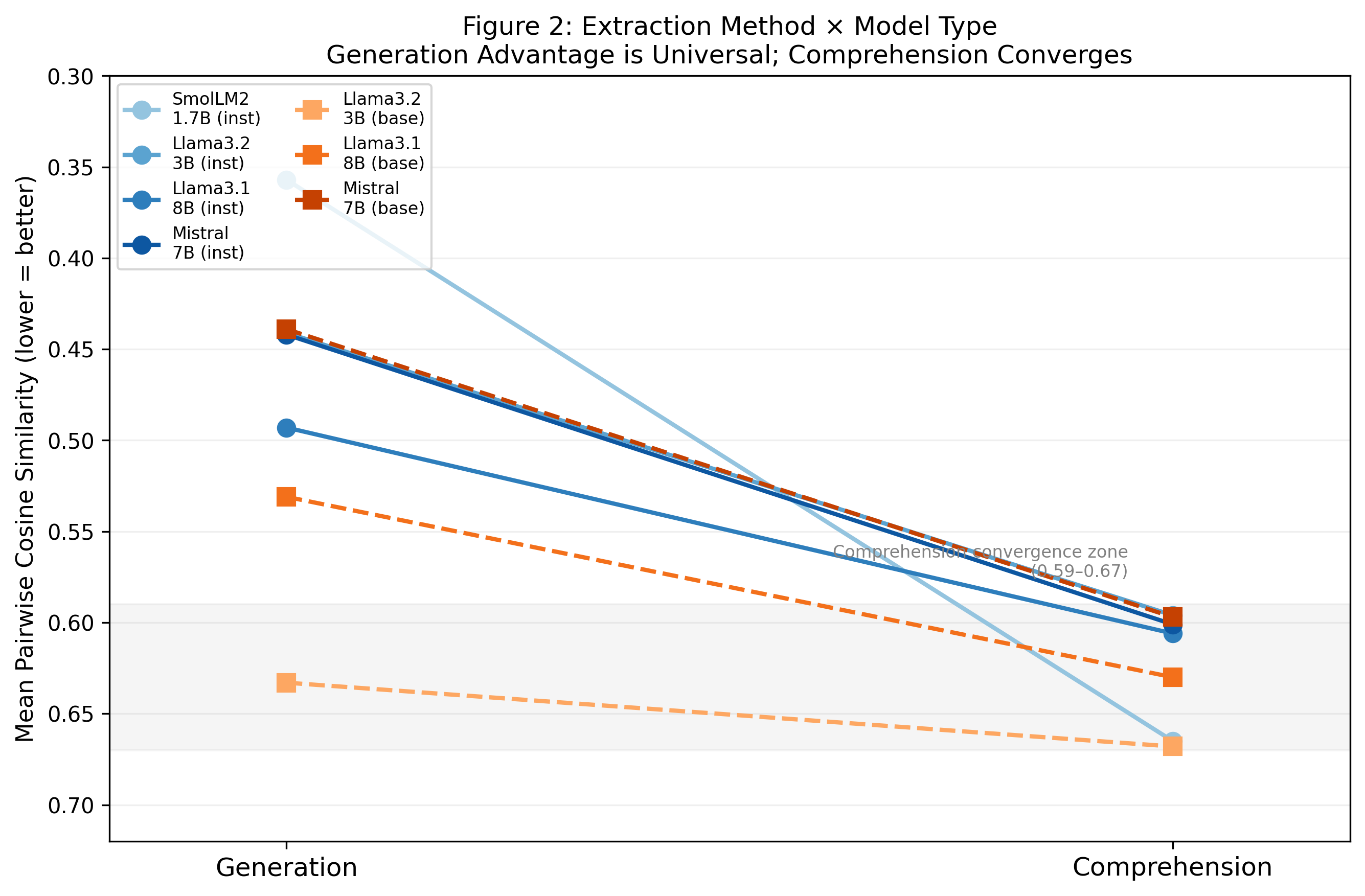
Figure 2: Extraction method impact across model types; generation-based vectors show model-dependent variance while comprehension-based results cluster tightly, underscoring the importance of extraction mode selection.
Empirical Findings
Emotional Structure and Anisotropy
Emotion vector spaces in SLMs, as extracted, do not recapitulate the full valence structure (i.e., negative cosine) found in state-of-the-art LLMs, even when employing generation-based extraction and instruction tuning. The mean pairwise cosine similarity between vectors remains strictly positive; semantically opposite pairs such as happy/sad rarely achieve cosines below 0.3. Critically, this lack of negative values is contextualized against measured representational anisotropy baselines, confirming that observed clustering reflects underlying architectural biases rather than extraction artifactuality.
Strong vector separation (e.g., 0.357 mean cosine for SmolLM2 1.7B-Instruct, significantly below an anisotropy baseline of 0.808) substantiates the legitimacy of extracted features—despite compression toward positive similarity, relative distances encode discriminative affective information.
Behavioral Steering and Regimes
Direct steering along extracted emotion vectors induces robust, causal shifts in model behavior. When projected onto prompts—for instance, GPT-2’s aggression-to-calm intervention—a monotonic, dose-dependent modulation is consistently observed (Figure 3).
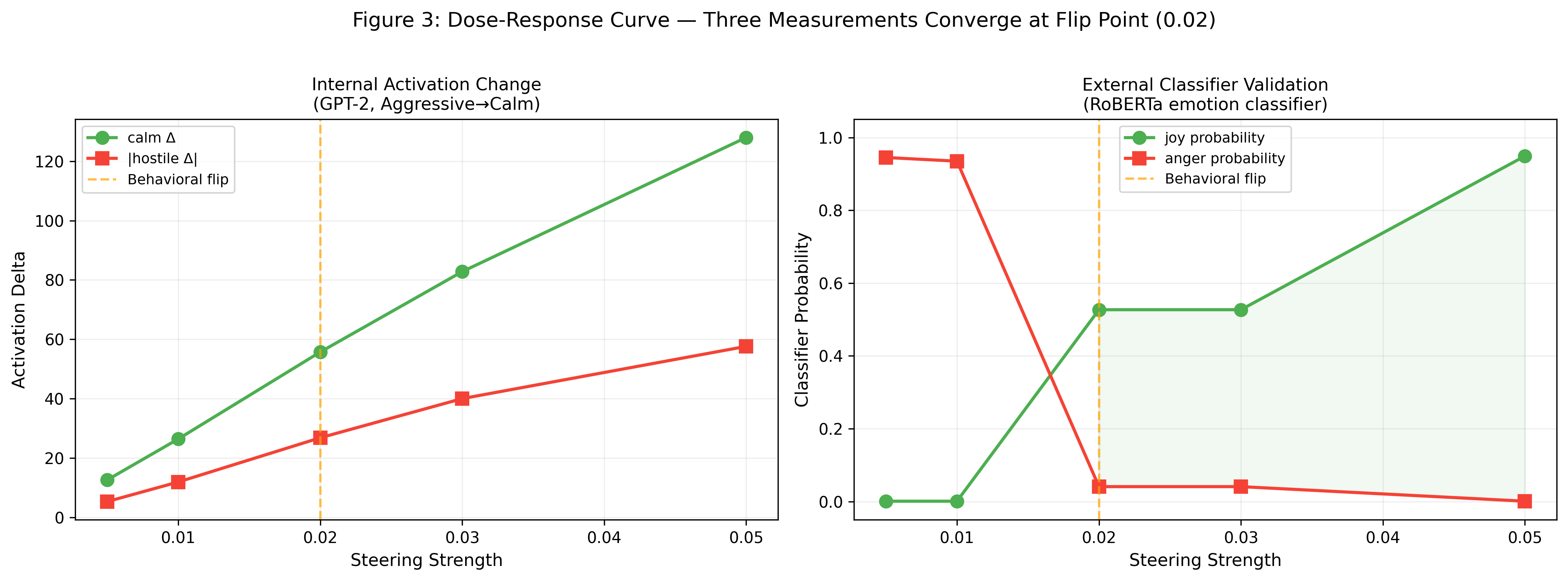
Figure 3: Steering in GPT-2 reveals a dose-response curve with convergent flip points in both internal activations and an independent external classifier, validating causal influence of the targeted vector.
Assessment across models unambiguously partitions steering outcomes into three operational regimes, defined by perplexity ratios and qualitative output:
- Surgical: Output remains coherent; semantic transformation is tight and interpretable.
- Repetitive Collapse: Output degenerates into low-diversity text (e.g., token repetition), albeit with low measured perplexity.
- Explosive: Output is high-perplexity and incoherent, often involving cross-lingual leakage in multilingual models (notably Qwen).
Figure 4 visualizes these regimes as a function of steering magnitude and resultant perplexity.
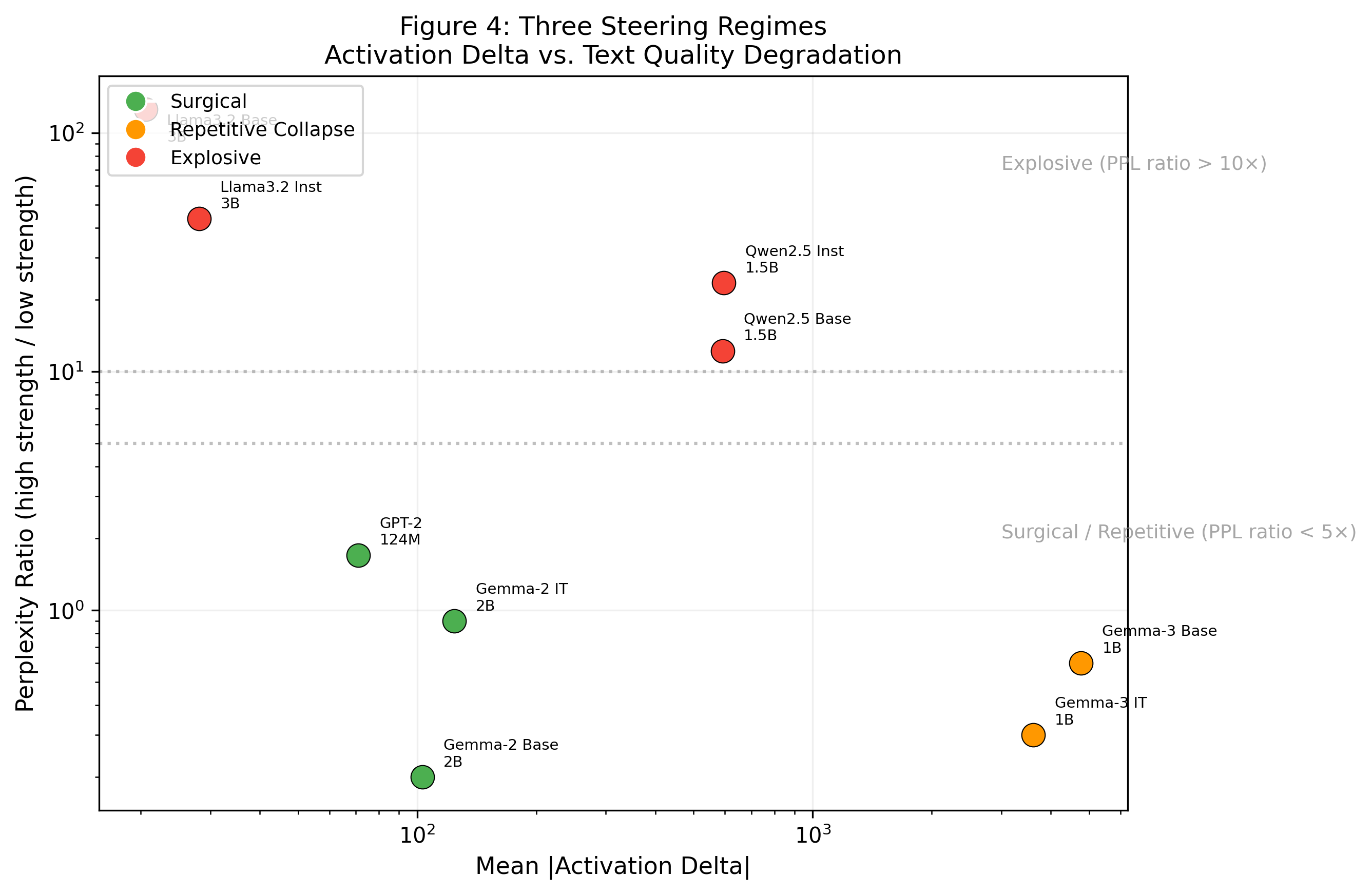
Figure 4: Models divide into surgical (green), repetitive collapse (orange), and explosive (red) steering regimes, reflecting architectural and scale-dependent behavioral boundaries.
RLHF and Architecture Dependency
Instruction tuning (RLHF) reliably amplifies the efficacy of generation-based extraction in Llama and Gemma families, yet its effects are non-uniform and are modulated by architectural constraints. Emotion separation in comprehension-based extractions remains largely invariant to RLHF, signifying surface-level augmentation rather than fundamental reorganization of internal representations.
Model size (within the 1.7B–3B range) does not correlate with improved emotion vector organization or behavioral responsivity, challenging assumptions of linear scaling in representational richness.
Emergent Cross-Lingual and Modal Phenomena
Emotion steering elicits unanticipated behaviors in multilingual and instruction-tuned SLMs. In Qwen2.5, for instance, steering toward emotions such as desperation or hostility induces generation of semantically congruent Chinese phrases rather than direct translations of the English emotion, revealing latent cross-lingual representational entanglement that persists despite RLHF constraints. Similarly, Gemma-3-1B-Instruct produces emoji-laden or neologistic outputs in response to certain emotion vectors, indicating the blending of symbolic and textual modalities under affective activation. These phenomena represent unmitigated behavioral leak paths, potentially relevant for safety assessment in multilingual deployments.
Theoretical Implications
The study’s findings reinforce several theoretical proposals regarding LLM internal structure:
- Layer-localized Composition: Emotion encoding is not uniformly distributed; rather, maximal affective separability arises in mid-network layers, potentially reflecting the locus of abstract semantic synthesis.
- Linearity Boundaries: While SLMs admit linearly extractable emotion vectors, the organization of affective space is less differentiated than in frontier models—a possible function of diminished capacity or architectural bottlenecks.
- Behavior-Representation Decoupling: RLHF predominantly alters output modulation rather than the substrate representation itself, as evidenced by the parallelism with behavioral temperament results in prior Model Medicine work.
- Transfer Limitation: The generative mean-subtraction method, effective at large scale, presupposes an instruction-following interface; models without this training fail to realize emotion-conditioned generations, occluding internal structure in standard extraction pipelines.
Methodological Guidelines and Limitations
Optimal extraction in SLMs requires (1) generation-based extraction for instruct-tuned models, (2) middle-layer activation selection, and (3) careful calibration of steering strength to avoid degeneration into the repetitive or explosive regime. However, the analysis is limited to models up to 3B parameters (due to hardware and software compatibility), 20 target emotions (out of 171 in Anthropic’s schema), and one major cross-lingual family (Qwen).
Conclusion
This study demonstrates that SLMs possess causally potent, extractable emotion representations, but methodology must be critically adapted to their architectural and training constraints. Generation-based extraction provides significantly better emotion vector separability than comprehension-based approaches in instruct-tuned SLMs. Internal emotion vectors in SLMs are qualitatively distinct from those in larger models: less well-organized, more anisotropic, and susceptible to steering-induced emergent phenomena such as cross-lingual activation. RLHF’s effects are surface-level and family-dependent. These insights provide a rigorous foundation for progressing model interpretability in limited-capacity, open-weight regimes and underscore practical and safety-relevant phenomena that demand further cross-architectural analysis.