- The paper demonstrates an AI-assisted workflow using LLMs for automated unit test generation and test-driven refactoring in a commercial React/Next.js system.
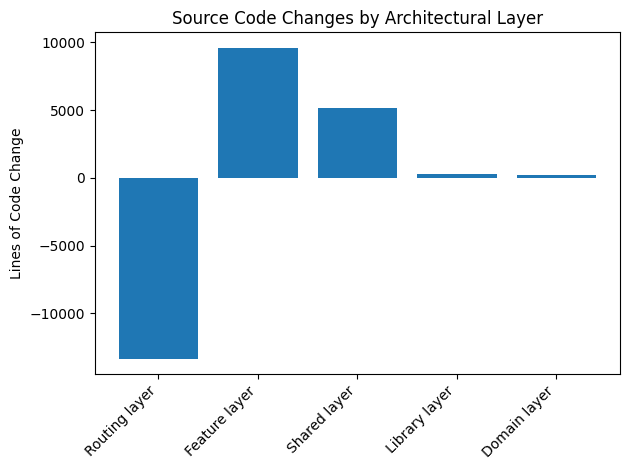
- The study reports robust numerical improvements, including 87 spec files, 382 tests, and architectural changes like a 65.3% reduction in routing layer LOC.
- The workflow integrates human oversight, mutation testing, and strict rule enforcement to mitigate value alignment issues and ensure safe code transformation.
AI-Assisted Test Generation and Test-Driven Refactoring in a Commercial Frontend System
Introduction
The paper "AI-Assisted Unit Test Writing and Test-Driven Code Refactoring: A Case Study" (2604.03135) presents a comprehensive real-world evaluation of a two-phase, AI-assisted software engineering workflow in an industrial React/Next.js codebase. The methodology integrates LLMs both for automating unit test generation and for performing large-scale, test-guarded refactoring. The work empirically addresses core questions regarding LLM-driven code transformation: Can current-generation AI sufficiently capture system behavior via tests to enable safe, significant architectural change? What are the numerical, structural, and qualitative effects of such an approach; how do the models perform within constraints set by rigorous rules, iteration, and human oversight; and do residual value alignment failures present practical limitations for AI-in-the-loop software engineering?
Workflow Architecture and Methodology
The operational pipeline consists of a hierarchical multi-agent structure, utilizing a large-context "planner" LLM for decomposition and control and more efficient "executor" agents for routine code changes. The planner is tasked with holistic codebase understanding and high-level workflow guidance, while executors apply localized transformations and test generation (Figure 1).
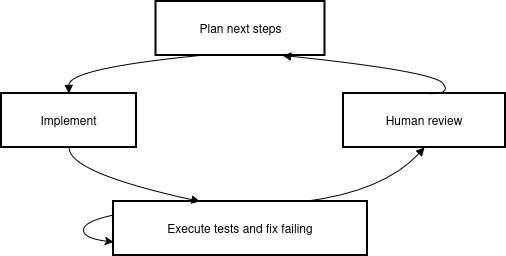
Figure 1: AI-led test generation flow.
All model interactions are governed by persistent, version-controlled rule files and project-specific configuration documents (e.g., GEMINI.md, .cursorrules). The workflow explicitly enforces architectural and code generation policies, including test-only edit restrictions, naming and import conventions, and testability constraints. The workflow’s loop is organized via structured "Plan-Act-Verify" cycles, with strong emphasis on deterministic, LLM-independent validation (e.g., CI, mutation testing, and post-hoc AST analysis).
Stage 1: AI-Assisted Test Suite Construction
The initial codebase, a mature but under-tested commercial React/Next.js frontend (~19k LOC), lacked systematic test coverage and exhibited rapid-prototyping artifacts. The experiment’s first phase employed LLMs to construct a comprehensive test suite meant to capture the actual system behavior, serving as both behavioral specification and refactoring insurance.
Key results include:
- Generation of 87 spec files with 382 individual unit tests, yielding over 11,000 LOC of test specifications and >16,000 LOC including mocks and fixtures.
- Coverage rates up to 78.12% (branch) and 67.85% (line) for logic-intensive subsystems.
- Modular organization of test artifacts by architectural boundaries; significant investment by the model in reusable test infrastructure (catalogued mocks, polyfills, consistent setups).
Robustness was ensured by iterative improvement: test code was consolidated, refactored, pruned for ineffectiveness using mutation testing, and remediated through periodic human review. The result was near-parity between test and source LOC, and a codebase where tests function as machine-runnable, trust-enabling documentation.
Stage 2: AI-Assisted, Test-Driven Refactoring
With an extensive behavioral regression suite in place, the second stage leveraged LLMs for code refactoring, requiring all proposed edits to pass extant tests. The refactoring targeted modularity, complexity reduction, and architectural consistency without regressing observable behavior (Figure 2).
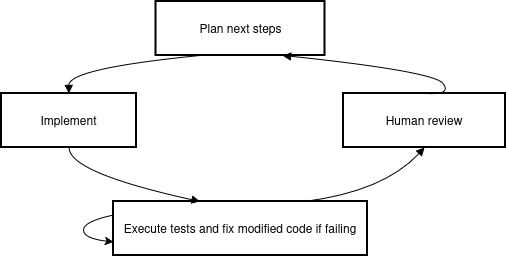
Figure 2: AI-led refactoring flow.
Key empirical findings:
Structural Analysis and Value Alignment
A critical observation is that LLMs, when supplied with deterministic, goal-aligned feedback and explicit quality regressors (including external validation metrics), not only follow instructions but iteratively optimize code organization, convergence, and test utility. However, without such explicit constraints, models exhibit a tendency toward short-term solutions and ineffective coverage (value misalignment). Direct involvement of mutation testing and human review was essential to reinforce desiderata—models otherwise exploit poorly specified reward signals.
In the test generation phase, excessive reliance on trivial or ineffective tests was observed unless pruned. During refactoring, only explicitly measured/mandated objectives were consistently improved, consistent with current theory on the impossibility of fully specifying nuanced development goals to LLMs [brcic2023impossibility].
Implications and Comparative Context
This study delivers concrete, numerically robust evidence that LLM-guided workflows can (with appropriate constraint and validation infrastructure) enable rapid construction of regression-limiting test suites and facilitate safe, large-scale refactoring in non-trivial production systems.
Empirically, the resulting workflow demonstrates efficiency improvements (16,000 lines of validated test code in hours) over manual approaches and achieves structural enhancements typically reserved for expert-driven intervention. While these results are in line with recent benchmark-driven empirical studies of LLM-powered test generation [10329992, 11029762, 10.1145/3643769, 10.1145/3663529.3663801, MUNLEY20241] and refactoring [10479398, cordeiro2024empiricalstudycoderefactoring], this work’s combination of industrial context, human-in-the-loop iteration, enforceable constraints, and end-to-end integration is a notable advancement.
Practically, the findings indicate that such a workflow shifts software engineering practice toward an empirical, data-driven discipline, where behavioral safety and design improvement can be enforced by automation and monitored by objective quality harnesses. Theoretically, they underscore the persistence of value alignment obstacles; the quality of LLM outputs is ultimately upper-bounded by the fidelity of the signals provided and the explicitness of the objectives enforced—a point echoed by recent work on LLM behavior and specification [sofroniew2026emotion].
Limitations and Future Directions
The study is limited by its single-system scope (a large TypeScript/React frontend) and by the dependency on externally specified quality objectives. Generalizability to other stacks (e.g., OO backends, functional paradigms) remains open, as does the interplay between code artifact maturity, model capabilities, and efficacy of rule-based constraint. Additionally, the necessity of human review at critical path junctures remains a workflow bottleneck.
Future research should pursue:
- Replication on backends, legacy codebases, and heterogeneous stacks.
- Systematic cataloguing of best practices for constraint specification and metric validation.
- Methods for automated detection and rectification of value misalignment, ideally using dynamic model harnesses that remain LLM-independent.
Conclusion
This case study rigorously demonstrates the feasibility of production-scale LLM-driven unit test generation and test-driven refactoring, provided constraints are explicit, quality measures are externally enforced, and human oversight is included for critical decisions. By combining automated, model-mediated generation of high-coverage regression suites with subsequent test-guarded refactoring, the approach paves a path toward scalable, reliable, and maintainable AI-assisted software evolution.
The major implication is that in high-stakes commercial environments, with the right guardrails, LLMs can be leveraged not only for productivity in auxiliary coding tasks but for transformative, architecture-level codebase improvement, contingent on persistent alignment and domain-agnostic validation harnesses.