- The paper presents a novel method that leverages a BART transformer to generate syntactically and semantically correct unit test cases.
- It utilizes a comprehensive dataset of 780K Java test cases and incorporates focal context to improve test quality.
- Evaluation shows 95% syntactical correctness and enhanced readability, outperforming traditional test generation methods.
Unit Test Case Generation with Transformers and Focal Context
Introduction to the Approach
The paper presents an approach for automating unit test case generation by leveraging a sequence-to-sequence transformer model, specifically a BART model, to learn from developer-written test cases. This approach is distinct in its use of real-world data to inform the model about best practices for creating test cases that are syntactically and semantically sound. The key innovation lies in framing the unit test case generation task as a sequence-to-sequence learning problem, using BART's capabilities for denoising and translation.
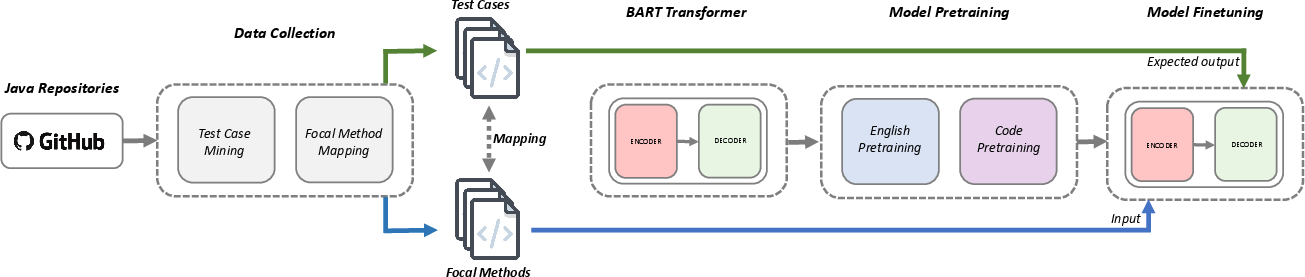
Figure 1: We mine test cases from GitHub and map them to the corresponding focal methods, pretrain a BART Transformer model, and finetune the model on the unit test case generation task.
Data Collection and Preparation
The authors collected a substantial dataset of 780K Java test cases from open-source projects on GitHub. These test cases were mapped to their corresponding focal methods using heuristics based on testing best practices, ensuring the dataset was of high quality. This mapping was crucial for training the transformer model in a supervised manner.
The dataset was split into training, validation, and test sets while ensuring no overlap between sets from the same repository to prevent data leakage. The comprehensive preprocessing ensured that the training examples represented realistic coding scenarios, which is critical for model generalization.
Model Architecture and Training
The paper employs BART, a denoising autoencoder Transformer that reconstructs input sequences corrupted by noise. For this task, BART was pretrained on both English and Java code corpora, leveraging its ability to learn the semantic and syntactic properties of languages.
During pretraining, English texts and Java source codes were used, with different strategies such as token masking and sentence permutation applied to create noise in the input sequences. This pretraining was crucial for improving the model's initial fluency, ensuring that it could handle both natural language and source code effectively.
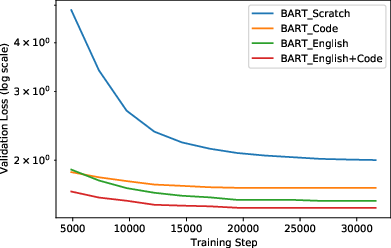
Figure 2: Validation loss demonstrates a positive effect from English and code pretraining.
Focal Context Enhancements
The research introduces the concept of focal context—details outside of the focal method, such as class names and constructors, which can provide additional semantic clues. Various focal context configurations were evaluated, with the model using different levels of additional contextual information.
Augmenting the focal method with class names, constructors, and methods significantly improved the model's performance, as evidenced by reduced validation loss and increased ingredient space, leading to more accurate and readable test cases.
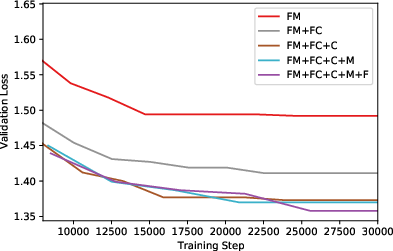
Figure 3: Additional focal context improves task loss, highlighting the model's use of extended contextual information.
Evaluation and Results
The model was evaluated using both automated metrics and developer surveys. It showed strong performance in generating syntactically correct test cases, with 95% of the cases being correct after minimal post-processing. In comparative studies, it outperformed GPT-3 in generating meaningful test cases and provided competitive test coverage compared to EvoSuite.
In a developer survey, a significant majority preferred the readability and effectiveness of the generated test cases over those by traditional methods, indicating a strong alignment with human developer expectations.
Conclusion and Future Work
This study demonstrates the potential of transformer-based models in generating realistic and comprehensive unit tests. The approach not only automates test generation but also generates code that is closer to human standards of readability and correctness.
Future work will aim to incorporate project-level contexts and support multiple testing frameworks to enhance the model's adaptability across various development environments. Deploying this system in IDEs like VSCode and integrating it with cloud services is a promising direction for real-world application.
These advancements underscore the shift towards AI-based models that understand and emulate human-like code generation, moving beyond coverage-focused methods towards semantic and practical code contributions.