- The paper presents that fine-tuned 10B-scale LLMs automatically generate high-level test cases, bridging the gap between requirements and testing.
- It details a four-phase methodology including practitioner surveys, dataset construction, LLM evaluation, and qualitative human assessment.
- Quantitative metrics and human evaluations confirm that tailored LLMs enhance relevance and completeness for in-house, confidential test design.
Automatic High-Level Test Case Generation using LLMs
Introduction and Motivation
Automated software testing remains a significant bottleneck in aligning development with business requirements, particularly due to persistent communication gaps between requirement engineers and testers. The paper addresses a core pain point identified via industrial surveys: testers struggle more with identifying what to test, rather than the mechanics of test script development. High-level test cases—abstract specifications describing which functionalities, behaviors, and edge scenarios require validation—emerge as pivotal artifacts for improving requirements-test alignment and promoting early, business-driven validation.
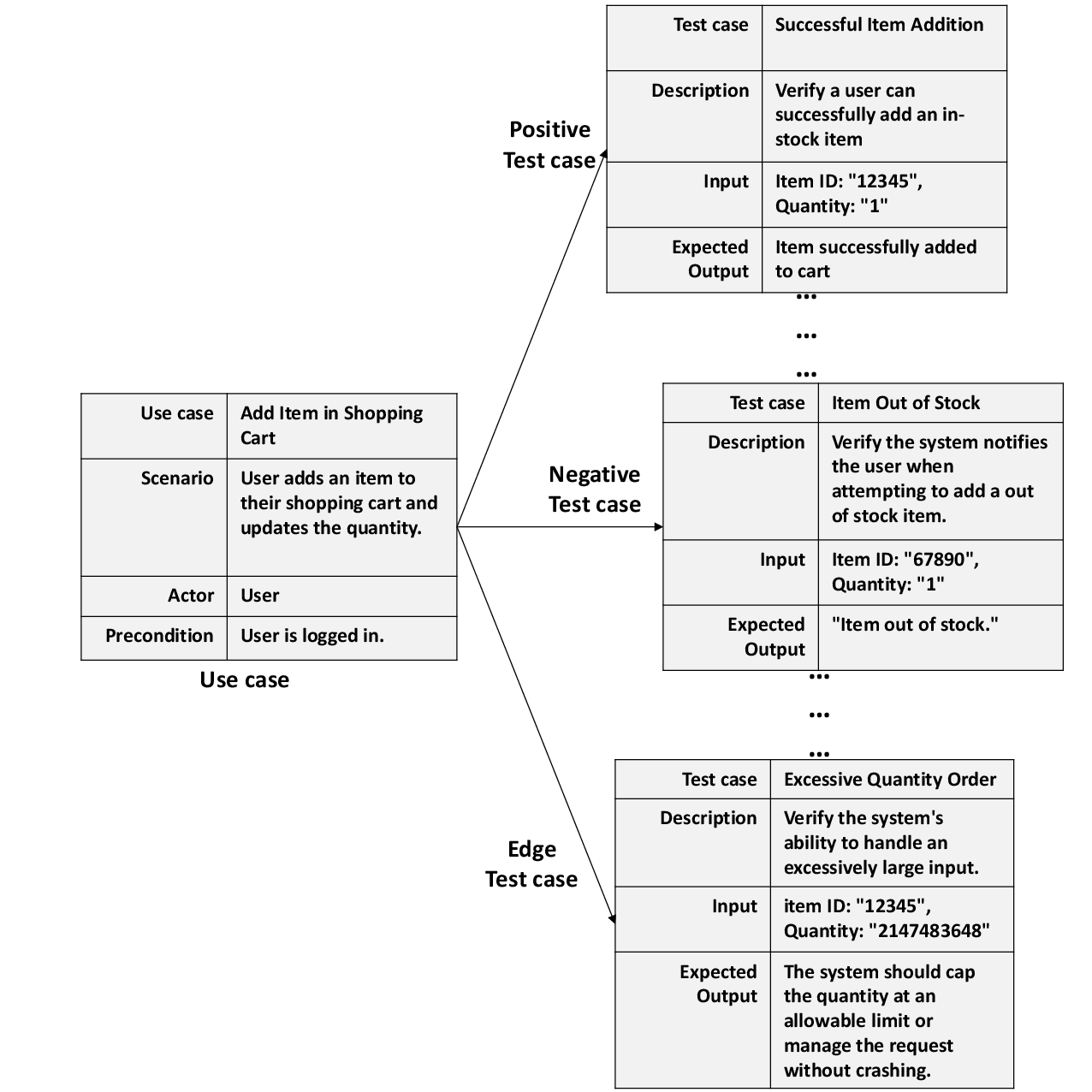
Figure 1: Illustration of mapping a use case such as "Add Item in Shopping Cart" into corresponding high-level test cases encompassing positive, negative, and edge-case scenarios.
Methodology and Dataset Construction
The paper proceeds through four phases:
- Practitioner survey to confirm and characterize the requirement-testing gap;
- Creation and curation of a use-case to high-level test case dataset (n=1067), designed for both training and evaluation;
- Assessment of LLM architectures—pre-trained and fine-tuned—for test case generation;
- Human evaluation for qualitative benchmarking.

Figure 2: Workflow depicting the four phases: survey, dataset construction, LLM evaluation, and human validation.
Core to this effort is a curated dataset spanning 168 real-world and student-driven software projects. Test case quality was ensured through a combination of faculty supervision and manual validation, particularly for cases synthesized from tools like UiPath and GPT-4o. The diversity across domains (e-commerce, finance, healthcare, etc.) ensures coverage of real-world variability.
LLM-driven High-Level Test Case Generation
Prompt Engineering and LLM Selection
The paper rigorously analyzes the efficacy of multiple LLMs: GPT-4o, Gemini, LLaMA 3.1 8B, and Mistral 7B. A one-shot prompt engineering template is used, in which a "canonical" example of a use case with associated test cases is provided to the LLM, followed by a target use case for which test cases are requested.
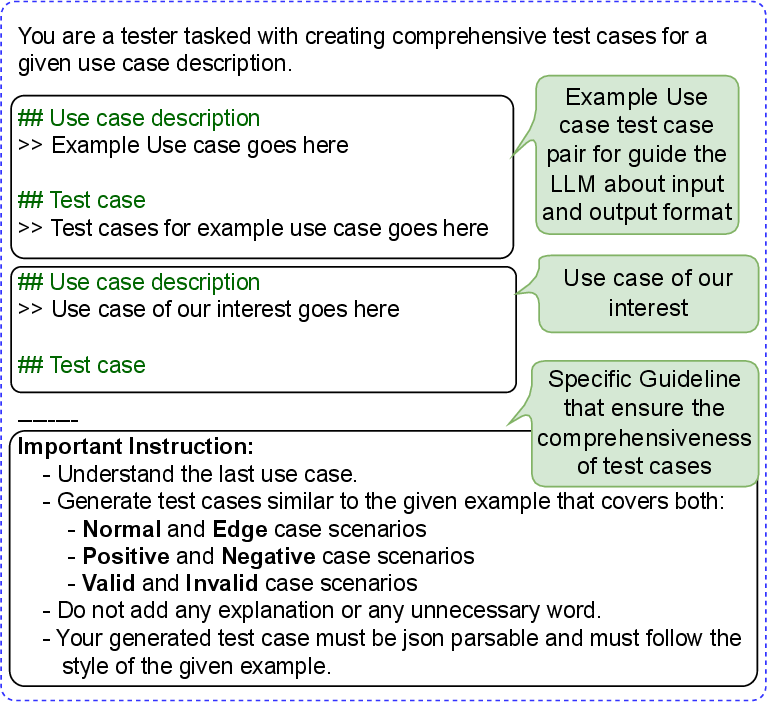
Figure 3: Example of a one-shot prompt engineering strategy for high-level test case generation from a use case.
Parameterization (e.g., temperature, top-p) is controlled for determinism in model output. For local deployability, LLaMA and Mistral models are both used in their pre-trained and QLoRA-finetuned forms, directly responding to the industrial requirement for data privacy.
Performance is evaluated using BERTScore (RoBERTa-based), prioritizing semantic equivalence over surface-form overlap—a critical aspect when substitutive wording is permissible but semantic coverage must be preserved.
Results:
- GPT-4o: BERTScore F1 = 88.43%
- Gemini: BERTScore F1 = 87.92%
- raw LLaMA 3.1 8B: BERTScore F1 = 79.85%, after fine-tuning: 89.94%
- raw Mistral 7B: BERTScore F1 = 82.86%, after fine-tuning: 90.14%
Fine-tuned LLaMA 3.1 8B and Mistral 7B outperform larger pre-trained models like GPT-4o and Gemini using only 10B-scale parameterizations. This is a substantial result for private deployment scenarios.
Human Evaluation: Quality, Failure Modes, and Coverage
A controlled survey with 26 industry and academic experts (double-blind, randomized order) assessed readability, correctness, completeness, relevance, and usability.
- LLM-generated test cases (GPT-4o, LLaMA 3.1 8B) scored above 3.5/5 in all dimensions, with human-authored cases scoring highest, but LLMs sometimes exceeding humans in readability.
- Completeness—especially regarding edge/negative cases—remains a challenge for both AI and human authors.
- Notable failure modes in LLM-generated tests:
- Hallucination: Irrelevant scenario inclusion.
- Redundancy: Duplicate case rephrasings.
- Incompleteness: Missed edge validations (e.g., missing input constraint checks).
A trade-off was observed: LLaMA's fine-tuning led to more focused (relevant but potentially incomplete) cases, whereas GPT-4o tended to favor completeness at the expense of relevance.
Contextual Enhancements and RAG
The paper explored two augmentation strategies:
- Contextual prompting: Adding project/module summaries to prompts produced negligible gains, indicating well-written use cases already encode most context needed.
- Retrieval Augmented Generation (RAG): Supplying more relevant prior examples as prompt context had only marginal effects due to heterogeneity across projects. Intra-project in-context learning could mitigate this limitation.
Limitations, Threats to Validity, and Practical Deployment
The experimental setup is comprehensive—balancing 80/20 train-test splits with project-wise partitioning to enforce strict evaluation on unseen domains. Quality assurance for the dataset and double rater human evaluations with weighted Cohen’s kappa (0.42) are noted.
Key practical implications:
- Open-source, 10B-scale LLMs—fine-tuned on domain use-case data—are a viable enterprise option for in-house, confidential AI-powered test design.
- The LLM approach is well-suited for test-driven and requirements-driven development workflows; automated high-level case generation can precede code, thus supporting early bug/requirement misalignment detection.
- Automated high-level test generation is a significant time saver and risk mitigator, especially for organizations lacking experienced testers or with rapidly changing requirement sets.
Implications for AI and SE Practice
This work demonstrates that LLM-based test case synthesis is feasible and scalable for high-level test cases—abstracting from the level of code to business logic validation. The robustness of LLMs in generating semantically rich scenario validations, including positive, negative, and edge cases, means their deployment bridges the requirements-test gap.
The results underscore the necessity of fine-tuning even performant pre-trained models for tightly constrained domains or privacy-centric deployments. The transition from generic SaaS access (e.g., GPT-4o) to private, locally-deployed models reduces risk and operational cost.
The primary bottleneck, as evidenced, is not in LLM capacity but in coverage and proper negative/edge-case mining. Advances in curriculum learning and in-domain, edge-case-focused training may further close this gap.
Future Research Directions
- Targeted curriculum learning to incentivize edge and negative case identification.
- Domain-adaptive fine-tuning for regulated sectors (e.g., healthcare, finance) to further boost relevance and coverage.
- Deeper integration with software development pipelines for real-time use-case-to-test-case generation.
- Systematic exploration of prompt/rag-based techniques in intra-project settings for higher fidelity in scenario mapping.
Conclusion
This paper establishes automated high-level test case generation using LLMs as a robust, practical aid for requirement-driven software testing. The introduction of a substantial, validated benchmark dataset, paired with empirical evidence showing fine-tuned mid-scale LLMs can equal or exceed larger pre-trained models, presents a compelling path forward for confidential, automated, and scalable quality assurance workflows in software engineering.