- The paper introduces a training-free VAD framework that leverages iterative LLM-VLM dialogue to overcome the limitations of static prompts in detecting anomalies.
- It employs spatiotemporal abstraction and a vector memory module to capture subtle, long-term anomaly patterns efficiently while reducing computational cost.
- Experimental evaluations on benchmarks like UCF-Crime, XD-Violence, and UBNormal demonstrate competitive AUC/AP performance using lightweight models.
QVAD: A Question-Centric Agentic Framework for Efficient and Training-Free Video Anomaly Detection
Problem Overview and Motivation
Video Anomaly Detection (VAD), especially in open-set scenarios, presents fundamental challenges due to the diversity and unpredictability of anomalous events in visual surveillance. Traditional methods are constrained by inflexible, static prompts and the reliance on large, resource-intensive Vision-LLMs (VLMs) and LLMs, which preclude their deployment in resource-constrained environments and limit adaptability to new or subtle anomaly types.
The QVAD framework notably redefines VAD as an interactive agentic process, emphasizing dynamic, context-driven dialogue between VLMs and LLMs rather than reliance on increased model capacity. This approach posits that the bottleneck in VAD performance is not model size, but the static nature of visual-semantic queries that fail to adapt to scene-specific ambiguities. QVAD leverages iterative prompt (question) refinement at inference time, empowering lightweight models to achieve competitive performance.

Figure 1: Overview of the QVAD framework, where LLM and VLM agents engage in turn-wise, closed-loop dialogue to iteratively refine anomaly understanding.
Methodology
Spatiotemporal Abstraction
QVAD processes input videos using a sliding window (default: 128 frames, stride: 64), extracting salient events through a two-stage frame selection pipeline. Initially, uniform temporal coverage is achieved by downsampling to 32 frames. A subsequent motion-aware salience step selects the 8 frames with maximal transient motion, ensuring that rare, contextually-rich events are captured while suppressing redundant information. This approach enables memory and compute efficiency for downstream processing.
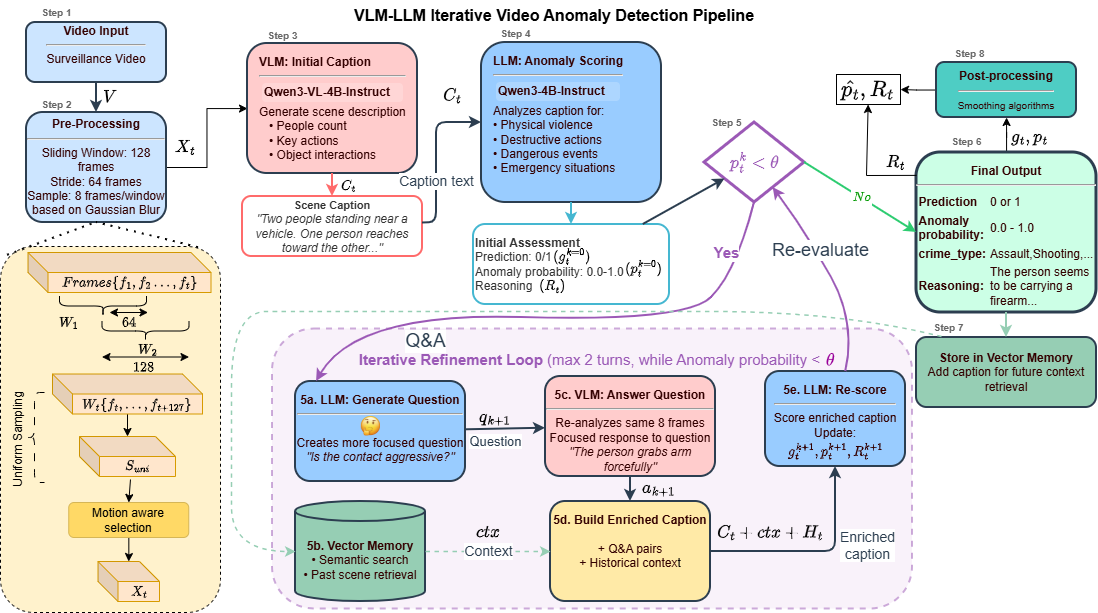
Figure 2: The detailed QVAD architecture, including sliding window, motion-aware frame selection, agentic dialogue, and vector memory.
Closed-Loop Agentic Dialogue
At each window, context abstraction initiates with the VLM generating an initial high-level caption from the visual input using a standard prompt. The LLM then produces an initial anomaly estimate—including probability and structured reasoning—based on this caption. If uncertainty persists (probability below threshold θ, typically 0.7), the LLM generates a targeted, context-dependent question, which the VLM answers with a focused, semantically-scoped caption. This Q&A loop iterates (typically two turns), maintaining and augmenting a dialogue history Ht for each window until anomaly likelihood converges or a maximum turn limit is reached.
This approach enables explicit disambiguation of subtle or context-dependent activity (e.g., distinguishing running for exercise from fleeing), with each LLM question functioning as an action that actively probes scene uncertainty.


Figure 3: Qualitative comparison of static (Turn 0) versus agentic (Turn 1/2) prompting, showing correction of initial false negatives via targeted question generation.
Vector Memory for Temporal Semantics
QVAD integrates a vector memory module, which encodes previous window-level captions, decisions, and context into fixed-dimension embeddings for dense retrieval. During dialogue, the LLM accesses this historic context to improve long-term temporal reasoning, facilitating anomaly detection in scenarios characterized by prolonged or recurring irregularities (e.g., extended loitering, or recurring suspicious item interactions).
Scoring and Post-Processing
QVAD aggregates multiple, possibly overlapping window-level predictions for each frame using max pooling, applies score calibration, and enforces temporal smoothness with multi-scale Gaussian filtering, followed by robust post-processing (as per VERA [ye2025vera]). Final anomaly scores thus reflect both immediate evidence and temporal context.
Experimental Results
QVAD was evaluated on standard surveillance benchmarks (UCF-Crime, XD-Violence), open-set/scene datasets (UBNormal, ComplexVAD), and compared to both training-free and weakly/semi-supervised SOTA methods. Key results include:
- UCF-Crime: 84.28% AUC (4B/4B, training-free), matching or closely approaching heavier agentic and tree-based models, with model footprints as low as 8B parameters (or 4.2 GB using a 1.7B/2B configuration).
- XD-Violence: 68.53% AP, robust to visually prominent events.
- UBNormal: 79.6% AUC (1.7B/2B), surpassing previous agentic and tree-based baselines by 4+ points, confirming superior open-set anomaly generalization.
- ComplexVAD: 68.02% AUC, outperforming VADTree, validating multi-turn dialogue in long-horizon, fine-grained scenarios.
These outcomes are achieved without any parameter updates, annotation-dependent prompt tuning, or large-scale training, and are reproducible at real-time (5–6 FPS) rates on modern consumer GPUs or edge-grade devices.
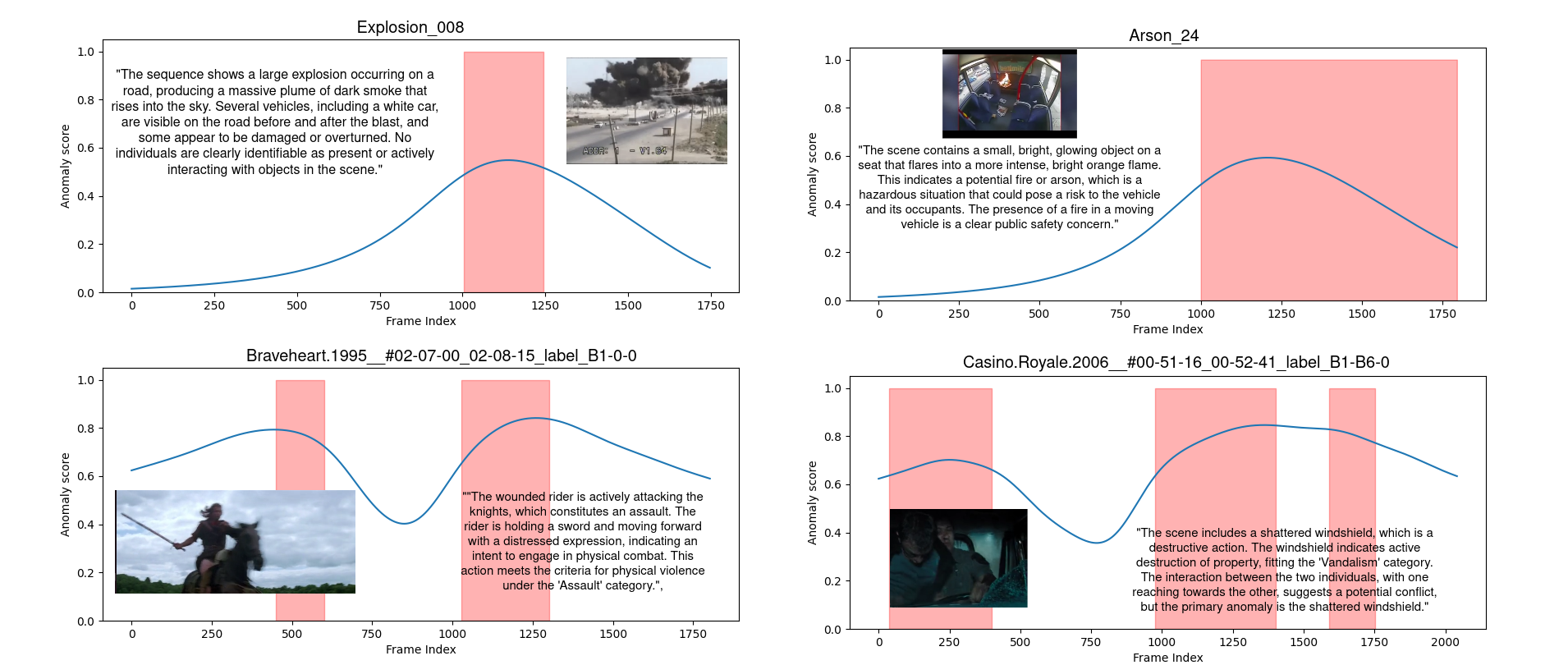
Figure 4: Examples of QVAD-generated anomaly scores and LLM reasoning for UCF-Crime and XD-Violence videos, illustrating tight alignment of anomaly probability with semantically salient explanations.
Detailed Analysis and Ablation
- Turns: Performance increases monotonically with Q&A depth, saturating after two dialogue steps, particularly for subtle anomalies. For visually salient events, static prompting suffices, but agentic refinement yields largest gains on context- or interaction-based anomalies.
- Model Size: Smaller models (1.7B–4B) retain most of the performance of larger ones, enabled by agent-guided prompting, allowing operation with as little as 4.2 GB VRAM.
- Vector Memory: Ablation confirms that semantic retrieval (long-term context) is essential for high open-set accuracy, raising AUC on UCF-Crime by ~2.6 points over naïve baselines.
- Efficiency: QVAD achieves significantly lower latency and memory requirements than all strong baselines, with effective real-time throughput.
Practical and Theoretical Implications
QVAD demonstrates that high-fidelity, training-free VAD is possible without resorting to impractically large foundation models, contingent on the dynamic optimization of the VLM–LLM interface. This insight alters prevailing design assumptions—emphasizing the structure of interaction and context management over sheer scale—and points to future directions where agentic reasoning, context-aware prompting, and memory-augmented architectures become the primary lever for real-world-efficient, explainable, and generalizable VAD.
The modular, dialogue-driven strategy positions QVAD for straightforward adaptation to related multimodal video analysis domains (e.g., action segmentation, event forecasting, video TTA) and highlights synergies with retrieval-augmented generation paradigms, paving the way for scalable, low-latency multimodal inferencing on edge hardware.
Conclusion
QVAD introduces a question-centric agentic framework that leverages LLM-facilitated iterative prompting and vector memory to enable lightweight, training-free video anomaly detection at high performance and low resource cost. By shifting focus from model capacity to the adaptivity of inference-time interaction, QVAD achieves SOTA results for both conventional and open-set VAD, rendering practical deployment on edge hardware feasible, and informing future system design for context-adaptive, explainable agentic AI in multimodal domains.