- The paper introduces SignCert-PO, a robust policy optimization method that mitigates reward hacking by suppressing completions with fragile advantage signs.
- It employs a certified sign-preservation radius to quantify minimal perturbations needed to flip advantage signs, ensuring reliable gradient updates.
- Empirical results on benchmarks like TL;DR and AlpacaFarm show that SignCert-PO outperforms baselines, especially in low-data and weak RM scenarios.
Mitigating Reward Hacking in RLHF via Advantage Sign Robustness
Introduction
This paper addresses reward hacking in Reinforcement Learning from Human Feedback (RLHF), a phenomenon where optimizing policies against imperfect reward models (RMs) leads to divergence between proxy reward and true quality, often degrading the actual performance. The central thesis is that reward hacking emerges from unreliable advantage sign predictions by the RM: if the sign flips, updates accidentally promote suboptimal (or undesirable) completions. The authors introduce a formal measure of reliability, the certified sign-preservation radius (Δj), defined per completion as the minimal RM parameter perturbation that flips the sign of the completion's advantage. Building upon this, they propose Sign-Certified Policy Optimization (SignCert-PO), a lightweight policy optimization algorithm that suppresses completions with fragile advantage signs, thereby systematically mitigating reward hacking.
Certified Sign-Preservation Radius: Theory and Role in Policy Optimization
The certified sign-preservation radius is motivated by the need to locally certify the robustness of each advantage's sign under adversarial perturbations in RM parameter space. RM reliability is therefore measured not at the aggregate or batch level, but per completion, emphasizing heterogeneity in RM robustness across completions.
For linear reward heads—common in practice—the radius admits a closed-form solution:
Δj=∥hψ(x,y(j))−hˉ∥2∣Aj(w)∣
where Aj is the group-relative advantage and hψ(x,y(j)) is the completion's feature embedding. This radius quantifies how much the RM would need to be perturbed (in parameter space) before the advantage sign for completion j becomes unreliable. Completions with low Δj are flagged as unreliable and are down-weighted during gradient updates.
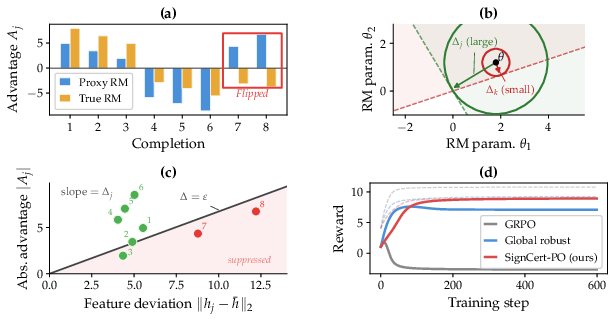
Figure 1: Certified sign-preservation radius (Δj) discriminates between completions with robust and fragile advantage signs; SignCert-PO suppresses low-Δj completions, improving alignment between proxy and true rewards.
SignCert-PO: Methodology
SignCert-PO modifies standard policy gradient updates by reweighting each completion gradient with a coefficient ρj∗=1−ϵ/Δj, where ϵ is either fixed or adaptively set by the empirical quantile of Δj=∥hψ(x,y(j))−hˉ∥2∣Aj(w)∣0 across batches. This reweighting conserves update direction for robust completions while suppressing unreliable updates, preventing the policy from reinforcing completions whose optimality under the proxy RM is easily manipulated.
Unlike ante-hoc adversarial or ensemble-based methods, SignCert-PO is entirely post-hoc: it operates only at the policy optimization stage, requires only RM parameters and on-policy completions, incurs negligible computational overhead, and imposes no requirements for multiple RMs or retention of RM training datasets.
Empirical Analysis
Experiments were conducted on TL;DR summarization and AlpacaFarm benchmarks using Pythia and Qwen2.5 models, evaluating against a suite of baselines including Dr.GRPO, UWO (RM ensembles), BSPO, and AdvPO. Evaluation used the gold-model setup, with a high-capacity gold RM judging policy outputs.
SignCert-PO achieved superior or competitive gold-RM win rates across various model sizes and tasks. The gains were particularly pronounced in settings with limited preference data or when smaller proxy RMs were used, highlighting the utility of local robustness certification under data scarcity or model capacity constraints. SignCert-PO maintained higher proxy RM accuracy during policy optimization, with policies consistently remaining within regions where the RM remained reliable, thus avoiding reward hacking.
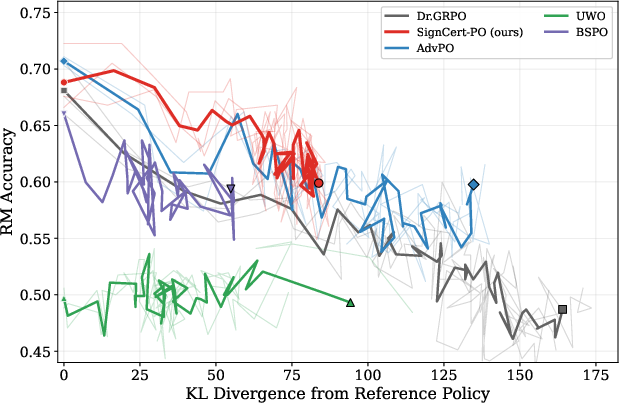
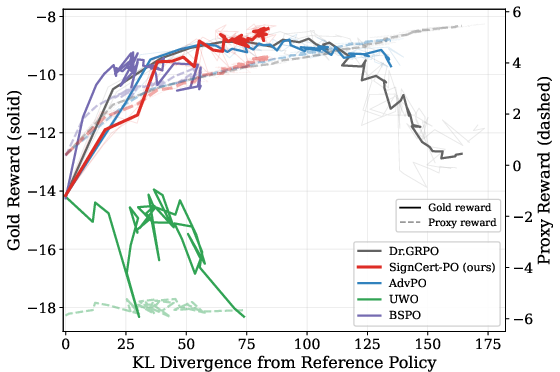
Figure 2: SignCert-PO maintains higher RM accuracy at every KL budget, avoiding reward hacking as shown by the stable gold reward trajectory.
Ablations revealed that as the policy diverges from the reference distribution (i.e., as KL increases), standard Dr.GRPO policies suffered rapid drops in RM accuracy and gold reward. SignCert-PO, however, held both accuracy and reward at lower KL budgets, indicating more conservative, reliable exploration.
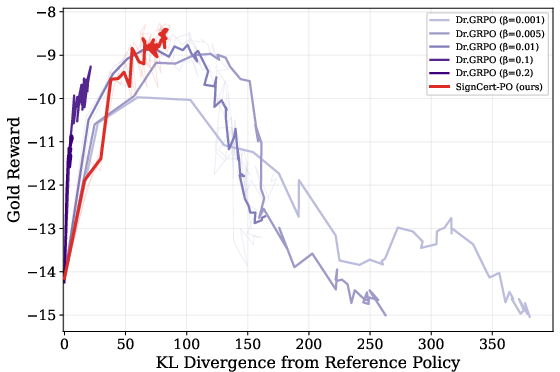
Figure 3: KL coefficient sweeps demonstrate trade-offs between exploration and safety; SignCert-PO achieves optimal gold reward at moderate KL.
Supplementary analysis confirmed that the certified sign-preservation radius is predictive of robustness against broader classes of perturbations, including full-parameter and input embedding perturbations, as well as agreement with the gold RM.
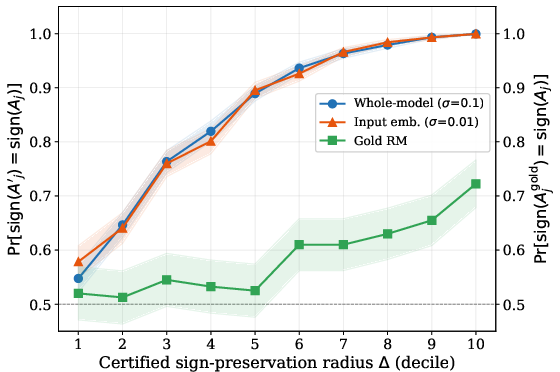
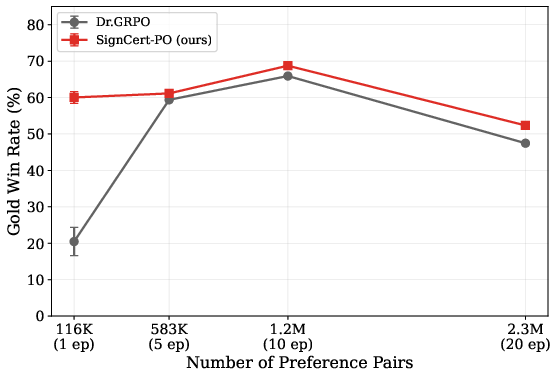
Figure 4: Δj=∥hψ(x,y(j))−hˉ∥2∣Aj(w)∣1 reliably predicts sign robustness beyond linear head assumptions, correlating strongly with sign preservation rates under broader perturbations.
SignCert-PO’s effectiveness was most accentuated with weaker proxy RMs (i.e., less preference data), producing robust improvements when data collection was limited—a critical regime for practical alignment pipelines.
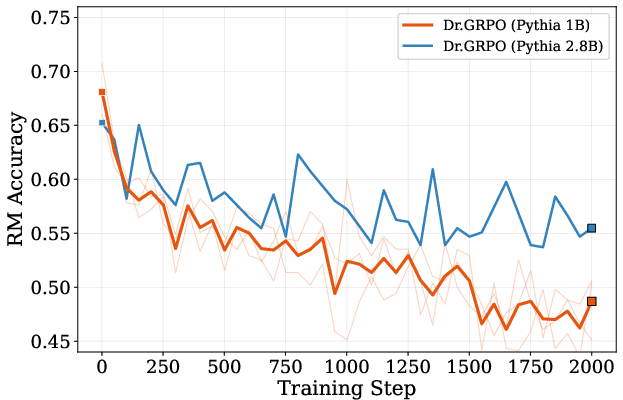
Figure 5: Smaller proxy RMs lose accuracy faster during policy optimization, highlighting the need for robust policy correction.
Theoretical and Practical Implications
SignCert-PO offers a scalable, computationally cheap mechanism for mitigating reward hacking in RLHF pipelines, independent of antecedent RM training design choices. The certified sign-preservation radius is theoretically grounded in randomized smoothing, adapting adversarial robustness certification to the parameter space of reward models. By focusing on the preservation of advantage sign—whose direction governs the reinforcement or suppression of completions—the method localizes robustness correction, overcoming uniform pessimism inherent in global robust optimization or batch-level uncertainty penalties.
SignCert-PO’s isolation from the RM training pipeline makes it compatible with third-party reward models and plug-and-play in production RLHF workflows. Its effectiveness in regimes with small datasets and weak RMs directly addresses practical constraints in preference data collection.
Limitations and Future Directions
While SignCert-PO is theoretically motivated and empirically validated, several assumptions delimit its current scope: (1) reliance on linear RM heads for efficient radius computation, (2) more conservative weight assignment due to per-completion adversary, and (3) no explicit mechanism for shared-direction adversarial coupling. Extension of the sign-preservation radius to general RM architectures, without incurring prohibitive computational complexity from full-parameter gradient norm evaluations, is an open challenge. Analysis of joint or tighter coupled robust optimization formulations, and integration with other forms of uncertainty quantification, are promising directions. Additionally, understanding how SignCert-PO interacts with distributional shifts in large-scale RLHF, and its synergy with other policy regularization techniques, warrants exploration.
Conclusion
SignCert-PO leverages certified sign-preservation radii to mitigate reward hacking in RLHF by suppressing unreliable completions at the policy optimization stage. It achieves improved gold-RM win rates and robustness, notably in data-constrained and low-capacity settings, without requiring modifications to the reward model pipeline or reliance on ensemble methods. Its per-completion robustness certification provides nuanced gradient correction, outperforming global and batch-level penalties. The method is theoretically grounded, modular, and empirically validated, offering a principled approach to improving RLHF alignment and robustness.
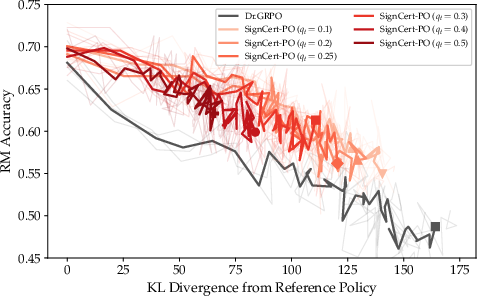
Figure 6: Quantile threshold Δj=∥hψ(x,y(j))−hˉ∥2∣Aj(w)∣2 provides a tunable control on RM accuracy—higher Δj=∥hψ(x,y(j))−hˉ∥2∣Aj(w)∣3 maintains RM accuracy, allowing precise trade-off between exploration and robustness.

