- The paper presents an iterative text-to-motion paradigm that combines generation, assessment, and refinement to enhance alignment.
- It employs a progressive three-stage training pipeline with chain-of-thought supervision and GRPO-based reinforcement to boost performance.
- Experimental results on benchmarks like HumanML3D and KIT-ML demonstrate improved R-Precision, FID, and robust adaptation to perturbations.
Interleaving Reasoning in Motion Generation: IRG-MotionLLM
Text-to-motion generation integrates natural language grounding and 3D human motion synthesis, a core challenge in compositional control for animation, AR/VR, and embodied AI. Previous motion-aware LLMs (UniMoLMs) treat understanding (captioning) and generation as isolated tasks, restricting their ability to benefit from complementary multi-modal feedback. This work identifies the assessment and refinement stages—motion-text alignment evaluation and guided correction—as key inductive biases that enable iterative bidirectional knowledge flow between understanding and generation. The proposed IRMoGen paradigm operationalizes this through interleaved reasoning, uniting motion generation, assessment, and refinement in an autoregressive loop until a satisfactory solution is produced.
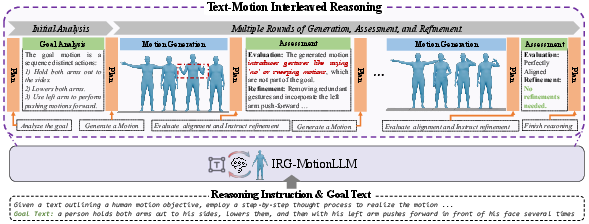
Figure 1: IRG-MotionLLM employs iterative text-motion dialogue for goal analysis, generation, assessment, and multi-step refinement guided by reasoning instructions.
Model Architecture and IRMoGen Paradigm
IRG-MotionLLM follows the VQ-based LLM architectural design, comprising a motion VQVAE (discretizing 3D pose sequences into codebook indices) and a LLM extended to handle text and motion tokens jointly. Unlike prior work, the IRMoGen process is realized as a native chain-of-thought (CoT) reasoning trajectory, aligning with the inherent autoregressive next-token prediction of LLMs. The procedure is instantiated by the IRMoGen-CoT template, prompting the model to alternate between plan formulation, goal analysis, motion generation, assessment, and refinement, iterated until termination criteria (e.g., “no refinements needed”) are met.
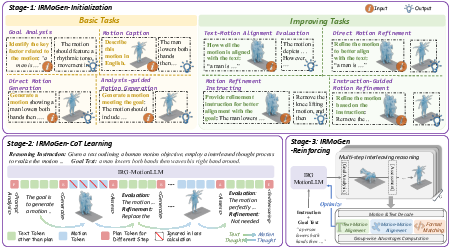
Figure 2: Three-stage training scheme: (top) meta-task initialization with basic and improving tasks; (lower left) CoT template-based alignment; (lower right) GRPO-based RL for multi-round reasoning.

Figure 3: The IRMoGen-CoT template operationalizes iterative generation, assessment, and refinement.
Progressive Three-Stage Training Pipeline
IRG-MotionLLM is developed through a progressive training schedule to overcome the task disconnect, need for structured supervision, and paucity of reasoning-aligned data:
- IRMoGen Initialization (Stage-1): The model is tuned on eight atomic tasks bifurcated into basic (caption, direct generation, prompt analysis, analysis-guided generation) and improving (alignment evaluation, refinement instruction, direct refinement, instruction-guided refinement) categories. This initialization is critical for embedding the necessary interfaces for downstream IRMoGen dynamics, with supervised templates and curriculum over task distributions.
- IRMoGen-CoT Learning (Stage-2): Here, the model is supervised to produce multi-step CoT reasoning traces, explicitly enforcing motion assessment and refinement loops. Only the ground-truth-aligned final motions are included in the loss, and a selective “ignore incorrect” masking is used for intermediate actions, preventing degradation of text-motion alignment.
- GRPO-based Reinforcement (Stage-3): To further unlock the model’s capacity for multi-round reasoning and adaptation, GRPO (intra-group ranking RL) is used with hybrid reward functions: structured CoT adherence, alignment of final motion to textual goal, and match to ground-truth motion. This approach eliminates extrinsic critics and preference data, favoring intra-batch signal.
Automated Data Engine for Interleaved Reasoning Annotations
Given the scarcity of suitable supervision, an automated annotation engine augments extant text-motion datasets with synthetic negative pairs spanning a spectrum of misalignment. This is mediated by a frozen motion encoder, nearest-neighbor mining stratified by similarity, and GPT-4o for semantic analysis and instruction generation. The resulting dataset supports curriculum on challenging multi-stage reasoning traces and enables robust evaluation of the model’s error correction and adaptation capabilities.

Figure 4: Negative text-motion pair mining and annotation pipeline utilizing motion encoder-based retrieval and LLM-powered assessment and refinement signals.
Experimental Results
IRG-MotionLLM is evaluated on HumanML3D and KIT-ML benchmarks using standard metrics: R-Precision, FID, MM-Dist, and Diversity. The following empirical claims are substantiated:
- Integration of assessment and refinement tasks is essential—performance improvements are negligible without these (e.g., R-Precision Top-1 only increasing from 0.496 to 0.500 with just basic tasks, but reaching 0.504 with all tasks included).
- IRMoGen-CoT supervision yields consistent gains—Stage-2 outperforms Stage-1 (Top-1 R-Precision 0.526 vs. 0.504; FID 0.111 vs. 0.141). Masking of intermediate non-matching motions prevents alignment collapse.
- GRPO RL further boosts alignment and reasoning length—Stage-3 achieves Top-1 R-Precision 0.535 and increases average reasoning steps (Figure 5), demonstrating that multi-round assessment/refinement trajectories are beneficial and stably adopted post-RL.
Comparisons with VQ-based LLMs, mask modeling, and diffusion models highlight that IRG-MotionLLM narrows or eliminates the gap with state-of-the-art dedicated generators, delivering competitive or superior R-Precision and MM-Dist (Tables 1, 2). This holds across both official and less-easily-gameable evaluation protocols.
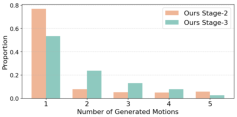
Figure 5: Distribution shifts toward longer reasoning traces and more intermediate generations after GRPO RL tuning.
Qualitative Analysis
The model is capable of multi-step correction, robustly recognizing and rectifying mismatches between generated motions and textual goals (Figure 6). Even when prompted with perturbed or adversarial initial conditions, IRG-MotionLLM converges towards aligned outputs, outperforming naive or static-generation baselines.

Figure 6: Qualitative demonstration: By natively reasoning over misalignment and applying stepwise refinements, IRG-MotionLLM achieves superior goal adherence compared to baselines.
Ablation and Robustness
- Allowing a greater number of refinement rounds directly increases alignment.
- Efforts to “hack the evaluator” are mitigated by cross-evaluator comparisons and inability to trivially overfit reward functions.
- Perturbation studies confirm reasoning robustness—the model does not rigidly follow fixed traces but adapts and recovers from adverse initializations (Figures 12, 15).
Theoretical and Practical Implications
The IRMoGen paradigm introduces a bridge between unconditional generative modeling and instruction-following composition. By interleaving task components within a unified autoregressive policy, IRG-MotionLLM demonstrates that multi-turn text-motion dialogue substantially improves controllability and alignment. The paradigm also aligns with trends in multimodal CoT and self-improving AI through feedback-based refinement. Importantly, the model can function as a reward model for RLAIF or as a module for motion agent frameworks, not merely a generator.
Practical applications include more reliable text-driven character animation, tools for robot learning through structured feedback, and improved semi-automatic annotation in motion datasets. The robustness to perturbations indicates strong transfer potential.
Limitations and Future Directions
While effective, the VQ-based approach may limit fine-grained detail; future work should integrate advanced quantization techniques (e.g., RVQ) or mix-of-experts architectures. IRMoGen currently prioritizes text-motion alignment but does not natively assess physical plausibility—incorporating dynamic realism or energy-based rewards is a promising avenue. Finally, both the base LLM and training corpora may be scaled, potentially leveraging giant motion-language datasets, to enhance coverage and zero-shot generalization.
Conclusion
IRG-MotionLLM demonstrates that iterative, structured reasoning across motion generation, assessment, and refinement significantly enhances 3D text-to-motion synthesis. By formalizing interleaved reasoning and coupling it with robust training dynamics and supervision, the model achieves new state-of-the-art performance in UniMoLMs. This work establishes a strong baseline for integrating feedback-driven, dialogical procedures in multi-modal generation as well as providing blueprints for future scalable, alignment-aware embodied AI systems.