- The paper introduces a novel probabilistic framework that integrates variational Gaussian Processes with 4D Gaussian Splatting to quantify uncertainty in dynamic scenes.
- It employs a composite kernel combining Matern and periodic components to model spatial discontinuities and recurring motion patterns for improved forecasting.
- The method demonstrates robust performance on benchmarks like DyCheck and DAVIS, achieving superior motion regularization and reliable temporal extrapolation.
Probabilistic 4D Gaussian Splatting from Monocular Video via Variational Gaussian Processes
Motivation and Problem Setting
4D Gaussian Splatting (4DGS) has established itself as the dominant paradigm for explicit dynamic scene representation and real-time rendering from monocular video sequences. Conventional 4DGS pipelines optimize time-varying Gaussian primitives through deterministic deformation fields with hand-crafted priors—typically polynomial or rigidity-based constraints uniformly applied to all scene primitives. This approach is fundamentally limited in handling ambiguous motion, occlusion, and unobserved regions, offering no mechanism for uncertainty quantification or principled prediction reliability. As a result, motion regularization in these settings can be both overly restrictive and prone to failure when observations are sparse.
The key contribution of "GP-4DGS: Probabilistic 4D Gaussian Splatting from Monocular Video via Variational Gaussian Processes" (2604.02915) is the introduction of a probabilistic framework that merges non-parametric variational Gaussian Processes (GPs) with 4DGS, thereby enabling uncertainty quantification, motion forecasting, and adaptive prior formation as first-class functionalities.
Probabilistic Motion Modeling in GP-4DGS
The core innovation is to model Gaussian primitive deformations—covering both translation and continuous 6D rotation—as vector-valued functions sampled from GP posteriors defined on the spatiotemporal domain (x=(p,t)). To address the heterogeneity between spatial and temporal axes, GP-4DGS constructs a composite kernel: a Matern kernel captures spatial correlations (preferred over RBF for handling discontinuities between disconnected objects), while a periodic temporal kernel handles recurring motion patterns and allows for temporal extrapolation. The output dimensionality comprises 3 for translation and 6 for the 6D rotation encoding, each treated as independent latent GPs.
This principled probabilistic model enables the computation of not only mean deformations but also predictive variances at arbitrary (p,t), allowing rigorous uncertainty maps and principled motion priors, particularly in poorly constrained regions.


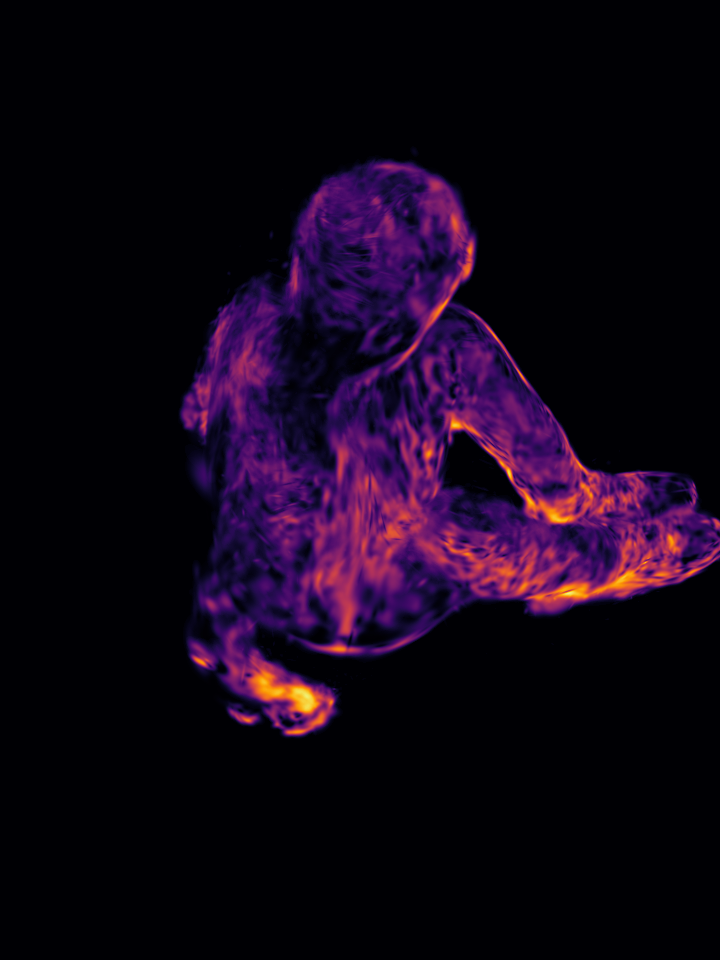
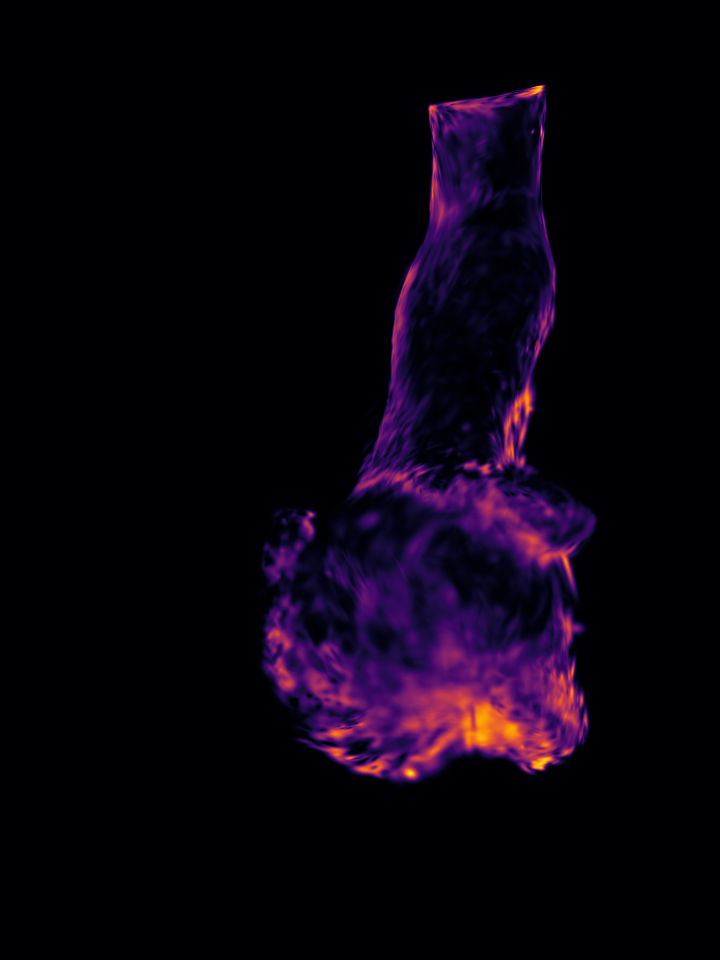


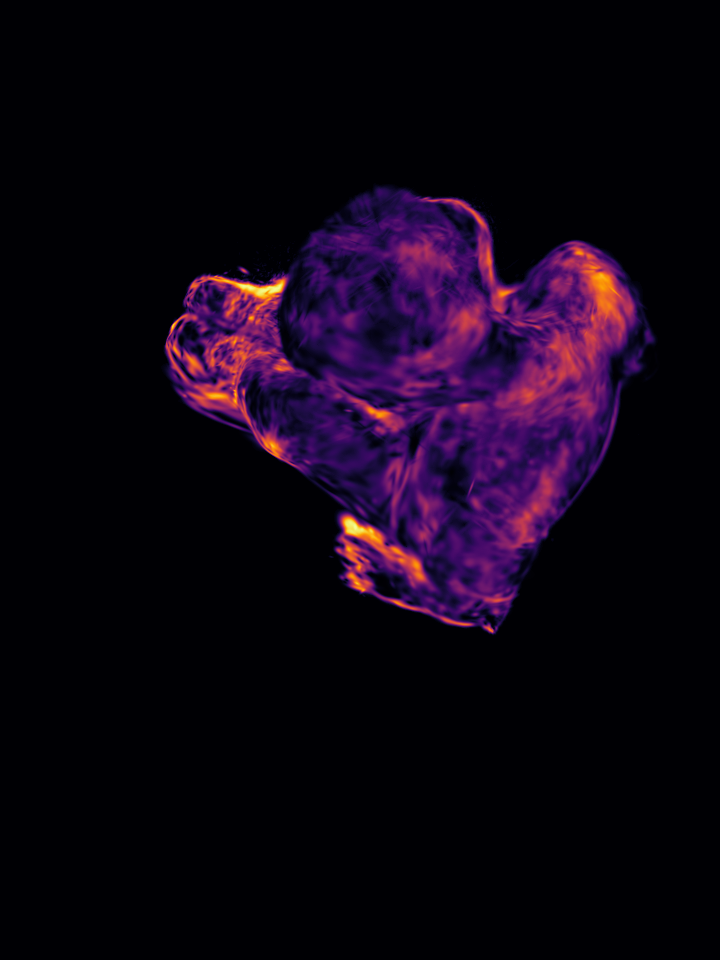
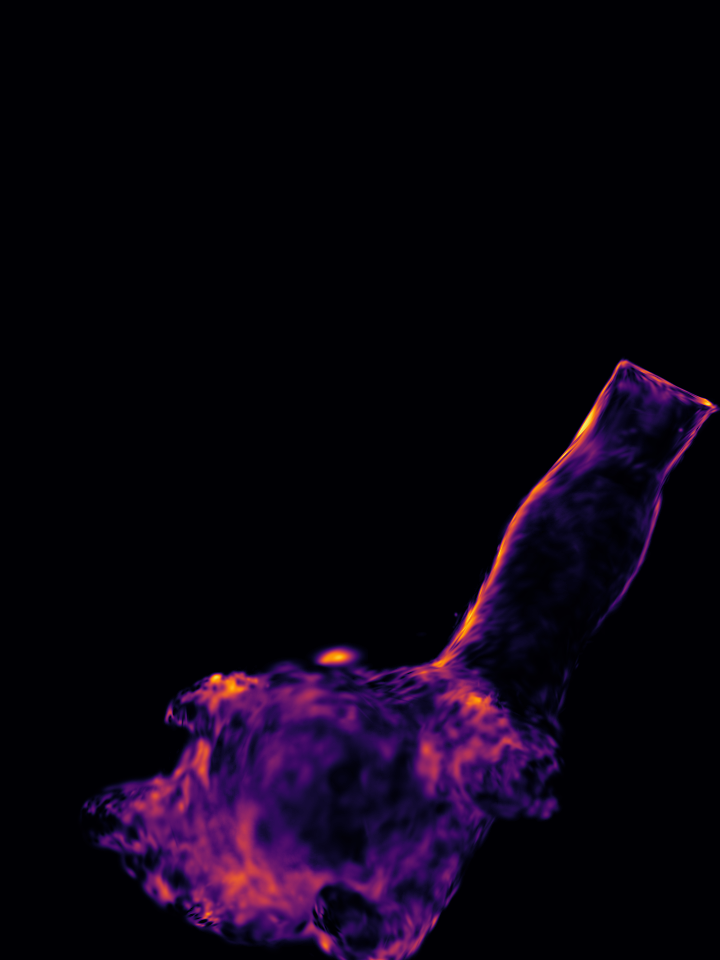
Figure 1: GP-4DGS provides principled uncertainty estimates for motion, a capability inherently lacking in existing 4DGS methods.
Scalability: Variational Inference with Inducing Points
Exact GP inference scales as O(N3) in the number of primitives N, which is computationally infeasible for practical scene sizes. GP-4DGS adopts sparse variational Gaussian Processes with inducing points, reducing complexity to O(NM2+M3) for M≪N. Inducing points are initialized via K-means clustering in a learned time-series embedding space (using Chronos) to capture diverse trajectory patterns and are distributed uniformly along the temporal dimension. The resulting variational GP is trained by optimizing the ELBO, jointly with all kernel and variational parameters.
Synergistic GP-GS Optimization
GP-4DGS introduces an alternating optimization strategy: Stage 1 selects primitives with high visibility confidence and fits the GP to their trajectories, regularized by injected spatial Gaussian noise; Stage 2 leverages the GP posterior to regularize 4DGS motion, propagating mean predictions and penalizing deviations from the GP. This synergy self-reinforces: confident motion observations reinforce the GP, which in turn regularizes less-constrained regions, leading to robust convergence under sparse or ambiguous input.












Figure 2: Qualitative comparison of novel view synthesis on the DyCheck dataset. GP-4DGS shows more accurate geometry compared to baselines, particularly in regions with less observation.
Dynamic Scene Reconstruction and Quantitative Results
GP-4DGS demonstrates superior performance on DyCheck and DAVIS monocular benchmarks, where it delivers improved mPSNR, mLPIPS, and mSSIM metrics—particularly on sequences with reduced viewpoint overlap and severe occlusions. The approach is robust to rapid non-rigid motions and can preserve sharp structural details even in sparsely observed or disoccluded regions.

Figure 3: Qualitative comparison on the DAVIS dataset under extreme viewpoint shifts from training view. Unlike the baseline, the spatiotemporal GP prior effectively regularizes the scene by faithfully propagating motion constraints into poorly observed regions.
Temporal Extrapolation and Probabilistic Interpretability
Through its principled kernel design, GP-4DGS can extrapolate motion trajectories beyond the observed training window without ad hoc modifications. In held-out test settings (with last 5/15 frames reserved), GP-4DGS achieves substantially higher PSNR for future frame synthesis compared to linear extrapolation, with strong gains for cyclic and periodic scenes. Ablation studies indicate that periodic mean and kernel components are complementary: periodic mean boosts long-range extrapolation for periodic motion, while a periodic kernel suffices for robust short-range prediction on both periodic and aperiodic scenes.

Figure 4: Motion extrapolation results from GP-4DGS. The GP-based model naturally predicts future motion by querying the model at timesteps beyond the training range.
Uncertainty Quantification and Trajectory Regularization
The GP posterior variance is propagated through all transformation dimensions, and uncertainty maps effectively localize ambiguous regions (such as occlusions or disocclusions). GP-4DGS achieves lower AUSE-MSE than deterministic or naive uncertainty baselines, with the difference magnified on high-quality frames. Trajectories reconstructed under GP guidance are noticeably less noisy and maintain physical plausibility, especially under sparse observation regimes.

Figure 5: Trajectory comparison on the (left) paper-windmill and (right) block scene. GP guidance effectively regularizes motion trajectories, reducing noise and producing physically plausible motion patterns, compared to the baseline approach.
Kernel Design and Inducing Point Distribution
The use of a Matern kernel allows the GP to account for spatial discontinuities—critical for scenes with multiple disconnected or interacting objects. The combination of spatial and temporal kernels prevents global prediction collapse if any coordinate is unobserved. Inducing point selection based on time-series embeddings enables the GP to efficiently represent high-variance, semantically critical trajectories, and ablation shows a clear ELBO advantage over random or velocity-based initialization.
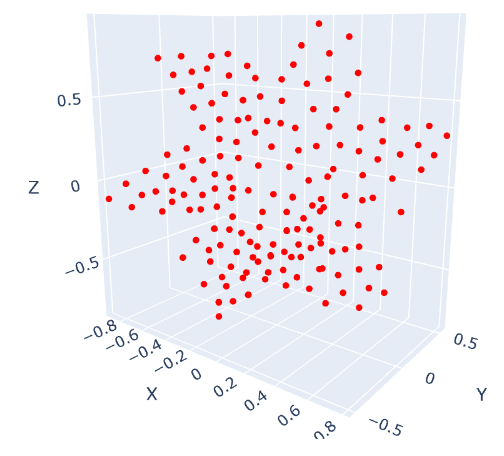
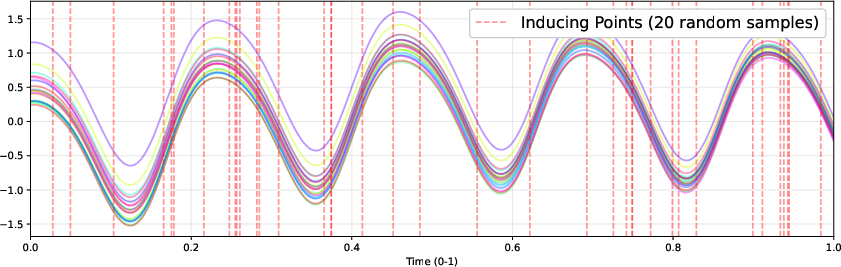
Figure 6: Canonical space. Visualization of spatial distribution of inducing points, demonstrating comprehensive scene coverage and avoidance of bias toward specific motion clusters.
Implications and Future Directions
The integration of variational GPs with explicit continuous-time neural graphics pipelines constitutes a significant advancement in the interpretability and reliability of dynamic reconstruction. The ability to obtain uncertainty-aware, adaptive motion priors directly from image evidence mitigates the risk of artifacts in poorly observed regions and extends to long-horizon prediction and planning, which is critical for downstream applications in embodied AI, robotics, and simulation-intensive digital twinning.
Potential future extensions include hierarchical or deep GPs for greater expressive power, dynamic kernel adaptation for multi-scale dynamics, and feedback control for active data acquisition based on uncertainty maps generated by the GP posterior. Extensions to multi-camera, multi-object scenarios, and explicit handling of topological scene changes are also immediate next steps.
Conclusion
GP-4DGS (2604.02915) establishes a rigorous probabilistic foundation for dynamic scene representation in explicit 4DGS architectures. By unifying non-parametric GP-based motion modeling with differentiable graphics and variational inference, the method achieves state-of-the-art dynamic reconstruction, interpretable uncertainty quantification, and robust extrapolation. This paradigm substantially improves robustness, interpretability, and adaptability in neural scene representations for both research and real-world deployment.