- The paper introduces DepTrans, a dual-module approach combining reinforcement-aligned syntax training and dependency-guided iterative refinement to enhance C-to-Rust translation.
- It employs compiler-feedback reinforcement learning and static dependency analysis to improve syntactic correctness, semantic preservation, and code safety.
- Experimental results demonstrate significant gains in compilation success and computational accuracy over traditional rule-based and LLM-based methods.
Dependency-Guided Repository-Level C-to-Rust Translation with Reinforcement Alignment: A Technical Overview
Introduction and Problem Setting
The automation of C-to-Rust migration is pivotal for meeting the rigorous demands of memory safety in system-level software without incurring performance penalties. While Rust's ownership system ensures strong safety guarantees, legacy C codebases continue to dominate critical infrastructure. Traditional rule-based transpilation tools, such as C2Rust, achieve surface-level syntactic conversion but routinely generate Rust outputs replete with unidiomatic patterns and unsafe constructs. More recent LLM-based approaches show promise in idiomaticity, yet face intractable challenges when scaling to repository-level migration: contextual fragmentation across files, brittle dependency resolution, and paucity of parallel C-Rust datasets hinder both syntactic correctness and functional equivalence.
DepTrans Architecture
The DepTrans system introduces a synergistic architecture that tackles both model-level deficits and inference-time contextual reasoning for large-scale, cross-file C-to-Rust translation. Its core comprises two tightly integrated modules: Reinforcement-Aligned Syntax Training (RAST) and Dependency-Guided Iterative Refinement (DGIR).
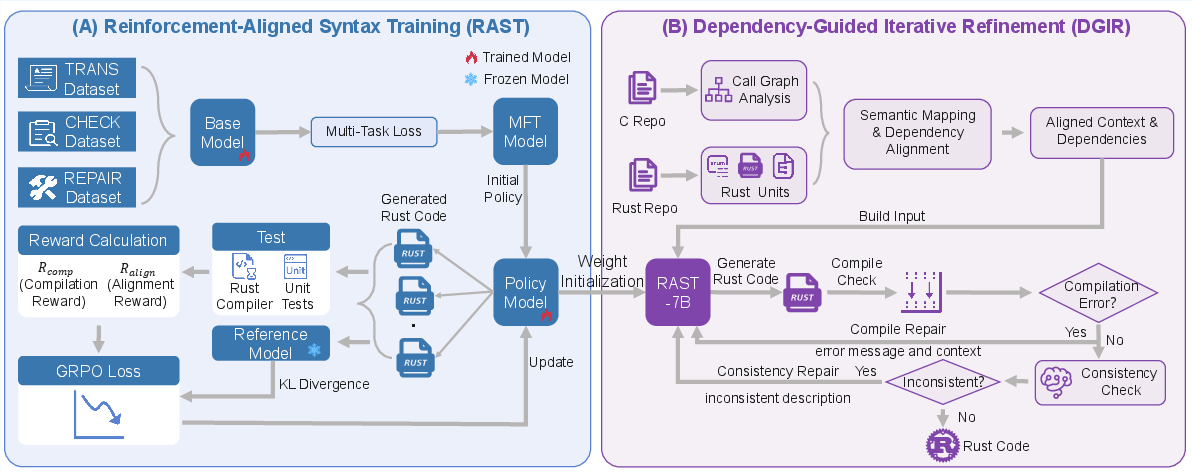
Figure 1: Overview of DepTrans, integrating Reinforcement-Aligned Syntax Training with Dependency-Guided Iterative Refinement for repository-level C-to-Rust translation.
Reinforcement-Aligned Syntax Training (RAST)
RAST is a two-stage procedure designed to imbue the code LLM with both strong syntactic proficiency and repository-level dependency comprehension:
- Multi-Task Fine-Tuning: The pre-trained model is fine-tuned on a custom-constructed dataset using three interrelated objectives: (1) C-to-Rust translation (semantic equivalence), (2) syntax error detection (diagnostic capacity), and (3) code repair (guided self-correction). Each sample is tagged for its task and optimized under a unified autoregressive objective, fostering cross-task information flow and translation-detection-repair synergy.
- Compiler-Feedback Reinforcement Learning: To further align model outputs with Rust's strict type system, the policy is refined with Group Relative Policy Optimization (GRPO) using compiler- and test-driven rewards. The hybrid reward function combines syntactic validity (reward from diagnostic error count) and functional alignment (unit test pass rate or CodeBLEU for repository-level samples), with balanced weighting to prevent degenerate behavior.
Dependency-Guided Iterative Refinement (DGIR)
DGIR operationalizes structural inference throughout translation:
- Cross-Language Dependency Alignment: Employs static analysis (Tree-Sitter) to construct the global call graph and dependency set in C, categorizes and pools the analogous Rust entities, and uses embedding-based semantic alignment (BGE-M3) to map dependencies across languages. This yields granular, dependency-aware context for each translation unit.
- Consistency-Guided Translation Refinement: The system incrementally translates and iteratively repairs translation artifacts via compiler diagnostics and self-consistency verification between C source and Rust output. Context is carefully curated (verbatim or summarized as needed) to maximize effective utilization of the LLM context window, mitigating hallucination and ensuring code executability.
Training Corpus and Benchmarking
To address data scarcity, the authors assemble a two-tiered dataset ecosystem: an 85k-sample function-level corpus for multi-task learning and fine-tuning, and a 145-instance repository-level benchmark specifically targeting cross-file dependencies. Rigorous filtration and hybrid function alignment (using BGE-M3, LLM-based reranking, and manual audit) ensure high-quality parallelism and functional alignment in repository-level samples. The function-level corpus leverages data deduplication and clustering (BGE-M3 embeddings, k-means) to sustain sample diversity and prevent overfitting to common code idioms.
Experimental Analysis and Empirical Findings
DGIR consistently outperforms baselines across datasets and model families: on DCBench—a repository-scale, high-dependency benchmark—the Qwen2.5-Coder-32B+DGIR configuration achieves 57.2% compilation success and 41.4% computational accuracy, an improvement of 19.3 and 15.2 percentage points over the best baseline, respectively. Even resource-constrained models show strong relative gains: Qwen2.5-Coder-7B's CA improves from 17.9% (File Context) to 28.3% with DGIR.
RAST-7B—the RAST-optimized 7B parameter model—achieves 60.7% compilation and 43.5% CA, notably surpassing several baseline models of much larger capacity. This manifests the effect of joint multi-task and RL-based compiler alignment, allowing small models to rival or surpass unaligned 32B+ models.
Ablation studies confirm every DGIR submodule is essential: removing structured dependency modeling, compiler feedback, or iterative repair all lead to substantial degradation. Notably, ablation of consistency checks heavily impacts functional correctness in larger models, pointing to the unique benefit of LLM-powered consistency verification.
Reward weighting in RAST is critical: compilation-only RL induces degenerate "panic!"-heavy outputs (97.9% CSR, 0% CA), while alignment-only sacrifices compilability. Balanced weighting (1:1 compilation:test) achieves optimal joint performance.
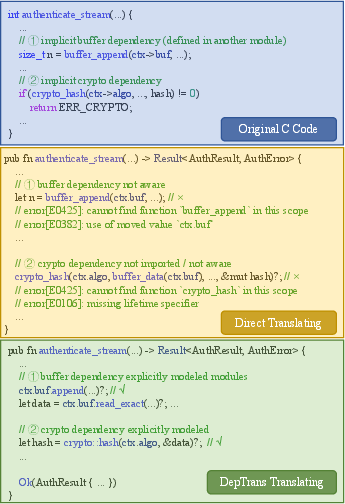
Figure 2: Case study: the authenticate_stream translation, where DepTrans resolves cross-module dependencies and strict borrowing rules, outperforming baseline LLM outputs.
Real-world, enterprise-scale applicability is demonstrated on HWBench (Huawei internal projects), with DGIR+RAST-7B matching or exceeding the build rate of much larger models (7/15 projects built).
Iterative Repair Behavior
The impact of repair depth is systematically evaluated: performance (compilation, CA) improves with more iterations, but so does token consumption. Optimal tradeoff is obtained at 2–3 compiler iterations and 1–3 consistency checks per translation.
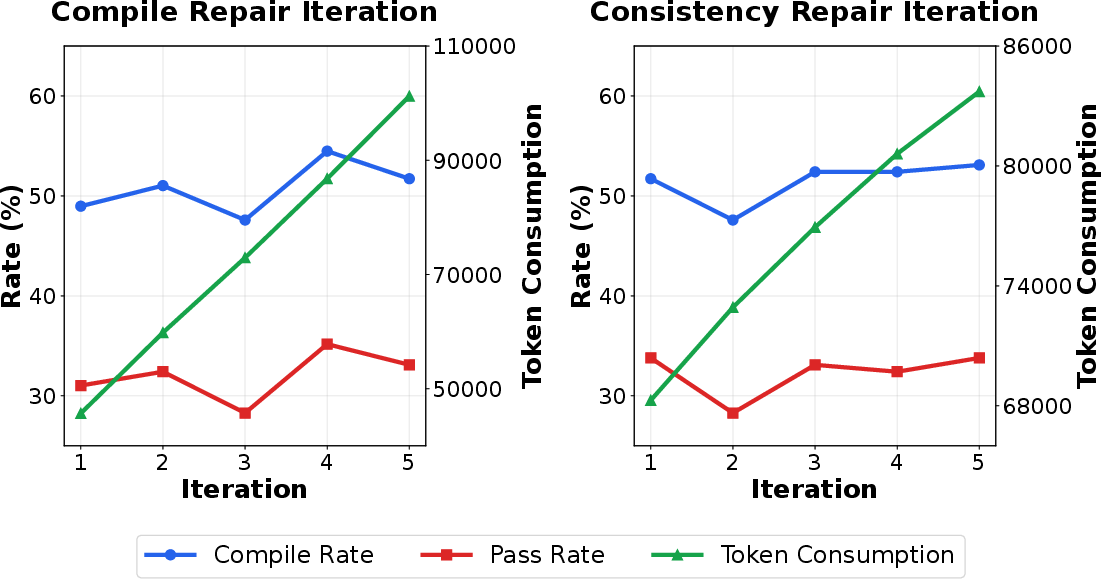
Figure 3: Impact of compilation repair and consistency repair iterations on translation performance and token usage.
DepTrans demonstrates robust code safety. The proportion of unsafe Rust lines stays below 3% across all testbeds, confirming the model's success in producing idiomatic and safe migrations.
On CRust-Bench (100 open-source C projects), DGIR+RAST-7B compiles 27 projects and passes all tests in 5, outperforming previous hybrid and LLM-only pipelines.
Practical and Theoretical Implications
This work establishes the necessity of explicit dependency modeling and RL-based compiler feedback in cross-language repository translation. It demonstrates that proper contextual alignment, semantic retrieval, and self-consistency repair considerably elevate model performance—far beyond brute model scaling or prompt engineering. The approach carries broad significance for automated software security hardening, reducing the human cost in large-scale migration, and sets a precedent for structured, compiler-in-the-loop RL for other code migration or repair tasks.
Future Prospects
Looking ahead, the dependency-guided iterative paradigm could expand to languages and systems featuring even more complex modularization or dynamic linking. Integration with formal verification or fuzzing feedback loops may further close the gap toward fully verified migration at scale. Dataset size, parallelism quality, and task diversity will continue to define achievable upper bounds for such LLM-based systems, motivating additional curation and community benchmarking efforts.
Conclusion
DepTrans represents a multifaceted advancement in repository-level code translation by unifying fine-grained dependency modeling, context-aware translation, RL-aligned syntax training, and iterative LLM self-repair. Its substantial empirical gains in both compilation and functional equivalence, combined with practical scalability to enterprise and open-source settings, position it as a reference architecture for future research in automated program migration, multi-language code intelligence, and compiler-in-the-loop AI training methodologies.