- The paper presents a novel framework integrating static program analysis with LLM-guided repair for accurate C-to-Rust translation.
- It employs dependency-aware code generation and a multi-stage repair pipeline to achieve near-perfect syntactic correctness and high semantic accuracy.
- The approach significantly reduces unsafe code and verbose output, enabling reliable, large-scale migration of legacy C projects.
C2RustXW: Program-Structure-Aware C-to-Rust Translation via Program Analysis and LLM
Motivation and Problem Statement
The transition to Rust for system software is driven by its robust memory safety model and performance guarantees, yet the migration of large-scale C codebases is hampered by non-idiomatic, unsafe code generated by rule-based translators such as C2Rust. These tools preserve unsafe C semantics, resulting in verbose Rust code with poor readability and maintainability. Manual code refactoring post-translation is both labor-intensive and unreliable in achieving idiomatic, safe Rust. Learning-based or LLM-based approaches have struggled with structural consistency and semantic equivalence, especially for multi-file projects and programs with complex dependencies.
C2RustXW Framework Architecture
C2RustXW introduces a program-structure-aware translation paradigm, integrating static program analysis with LLM-based code generation and repair. The pipeline consists of three stages: Rust code generation, syntax checking and fixing, and semantic checking and fixing. Critical to the design is the central abstraction of program structure, including global symbols, function dependencies, control- and data-flow information, and inter-file relationships. Program analysis extracts multi-level structure, which is encoded into textual representations and injected into LLM prompts, guiding both translation and multi-stage program repair.
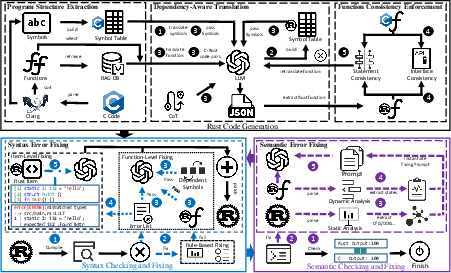
Figure 1: The overall architecture design of C2RustXW, showing the interplay between program analysis, dependency-aware code generation, and structure-guided repair pipelines.
Program Structure Extraction and Representation
C2RustXW defines explicit program structure as a tuple S(P)=(Σ,F,D,G), where Σ (global symbol table), F (functions), D (dependencies), and G (control/data-flow graphs) constitute the structural skeleton. Clang/LLVM is used for C AST extraction and syn for Rust, storing elements in dictionaries, lists, and graphs. These representations are serialized as structured prompts for LLMs, injecting context such as dependent symbol definitions, control/data-flow chains, and runtime states for translation and repair. Dependency information determines translation order and guides interface consistency across functions and files.
Translation and Repair Pipeline
Dependency-Aware Rust Code Generation
C2RustXW translates global symbols first, then functions in call graph topological order for dependency correctness. For each function, its dependencies are resolved from D and Σ, with symbol definitions provided in both C and Rust forms. This prompt-based context ensures accurate interface mapping and avoids mismatched symbol definitions across files. Inter-file dependencies are modeled at the project level, supporting unified cross-file structural consistency.
Syntax Checking and Multi-Stage Repair
Initial translation is validated through cargo compilation. Syntax violations, ranging from parsing failures to deeper type and ownership inconsistencies, are addressed via a hybrid repair pipeline:
- Coarse-grained LLM correction for unparseable code regions
- Rule-based, deterministic fixing at statement-level derived from compiler diagnostics
- Dependency-aware function-level and structure-aware item-level LLM-guided repair, with explicit context from program structure
Prompts include error locations, symbol definitions, and interface constraints. Repairs iterate until syntactic correctness is achieved or a limit is reached.
Semantic Consistency Validation
Semantic correctness is enforced via differential testing: C and Rust programs are executed with equivalent inputs, and output differences drive semantic error localization. Structure-aware analysis utilizes control-flow and data-flow graphs (CFG and DDG) as serialized prompt context. Dynamic runtime state instrumentation supplies fine-grained evidence for behavioral inconsistencies, guiding LLM-based repair prompts that contain input/output pairs, structural evidence, and discrepancy analysis.
Experimental Results
C2RustXW is evaluated on CodeNet, GitHub, and six real-world multi-file C projects. The metrics include syntactic correctness (SynCor), semantic correctness (SemCor), code size (RLOC), unsafe proportion (PUR), and Clippy diagnostics.
- File-Level Translation: C2RustXW attains 100% SynCor on CodeNet and 97.78% on GitHub, with semantic correctness up to 95.45%. Unsafe usage and code size are drastically reduced: unsafe proportions decreased to 24.95% (CodeNet) and 5.75% (GitHub), while code size inflation seen in rule-based baselines is avoided.

Figure 2: Counting sort program translation comparison across C2Rust, GenC2Rust, PLTranslation, and C2RustXW (CodeNet/s787964396.c), highlighting improved safety and idiomatic transformation.
- Project-Level Translation: C2RustXW achieves perfect syntactic correctness and 78.87% average semantic correctness across projects. Unsafe code is reduced from 77.75% (baseline) to 8.48%, and code size is decreased by up to 43.70%. FFI reliance and hybrid builds, characteristic of C2Rust/GenC2Rust, are eliminated.
- Clippy errors are nearly zero, suggesting high code reliability; warnings are primarily stylistic, reflecting deliberate preservation of naming conventions for traceability.

Figure 3: Doubly linked list program translated by C2RustXW (GitHub/doubly_linked_list.c), demonstrating structure-informed conversion of pointer-based data structures to safe Rust abstractions.
Case Study Analysis
Case studies on array boundary handling (counting sort) and pointer-based data structures (doubly linked list) show that rule-based translations propagate unsafe C idioms, while LLM-only approaches suffer from structural inconsistency and incomplete output for larger codebases. C2RustXW's structure-guided prompts enable correct handling of array bounds and safe ownership constructs (Box, Option), eliminating out-of-bounds errors and pointer misuse, thus supporting idiomatic, maintainable Rust.
Practical and Theoretical Implications
C2RustXW demonstrates the necessity of explicit program structure modeling in code migration tasks. By unifying static analysis, dependency modeling, and prompt engineering, it achieves both correctness and safety at scale, alleviating the pitfalls of rule-based and naive LLM approaches. The framework suggests that future AI-assisted program translation should prioritize structured context extraction and prompt injection, moving toward reliable multi-language migration for enterprise-scale systems.
Theoretically, the structure-to-prompt paradigm bridges formal program analysis with LLM generative capabilities, encouraging research on joint LLMs and static reasoning, and fostering directions in code synthesis, refactoring, and automated repair with cross-language correctness guarantees. Further work may extend to richer structural integration, automated idiomatic refinement, and broader support for complex C/C++ idioms in Rust migration.
Conclusion
C2RustXW offers a robust, scalable approach to C-to-Rust translation by integrating program analysis and LLMs within a structure-aware framework. It achieves high syntactic and semantic correctness, markedly reduces unsafe and verbose code, and supports both file-level and project-level migration with dependency-consistent, idiomatic Rust output. The explicit modeling and injection of program structure into LLM prompts is critical for reliable translation and repair, establishing a foundation for advanced cross-language program transformation and migration research (2603.28686).