- The paper presents Gen-SSD, a novel distillation method that embeds the student in the teacher’s generation loop to align supervision with the student’s learnability.
- It introduces generation-time selection using student perplexity, which prunes complex reasoning paths and reduces computation while ensuring concise guidance.
- Experimental results demonstrate significant gains, with improvements up to 5.9 points over standard KD, highlighting Gen-SSD's effectiveness on multi-step reasoning tasks.
Student-in-the-Loop Chain-of-Thought Distillation via Generation-Time Selection
Transferring the advanced chain-of-thought (CoT) reasoning capabilities of large reasoning models (LRMs) to smaller, efficient student models is critical for practical deployment in constrained settings. Traditional knowledge distillation approaches passively transfer complex reasoning trajectories from teacher to student, often resulting in poor student performance due to a mismatch between the complexity of teacher-generated CoT and the student’s learning capacity. Prior work attempts to mitigate this via post-hoc filtering or trajectory simplification, but such approaches operate only after trajectory generation, inherently limiting their ability to align the supervision with the student’s strengths.
Methodology: Gen-SSD Framework
The Gen-SSD (Generation-time Self-Selection Distillation) framework introduces a paradigm shift by embedding the student model into the teacher's sequence generation loop. Generation is performed in chunks; after each chunk, the student evaluates candidate continuations using its own perplexity (PPL), selecting the continuation that is most compatible with its own modeling capacity. If none of the candidates are suitable, generation is terminated early, which both prunes unlearnable reasoning paths and reduces redundant computation.
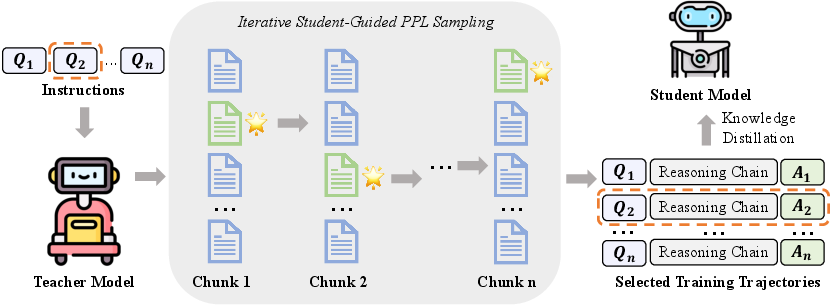
Figure 1: Overview of Gen-SSD. The student guides the teacher's sampling trajectory by selecting among candidate continuations at each chunk based on low PPL, promoting efficient and tailored trajectory generation.
This approach not only produces more learnable and concise supervision but also results in computational savings, as unproductive trajectories are pruned before consuming full generation resources. A lightweight cold-start phase is introduced: the student receives initial fine-tuning on verified reasoning-formatted data to align its output format and PPL estimation with the teacher, ensuring meaningful self-evaluation during subsequent selection.
Experimental Evaluation
Experiments employ QwQ-32B as the teacher and Qwen2.5-Math-1.5B as the student, with evaluation on rigorous benchmarks: American Invitational Mathematics Examination (AIME24/25), AMC23, OlympiadBench, and GSM8K. All assessments are conducted in zero-shot or two-shot prompting regimes, with careful data splits to avoid leakage. Multiple baselines are compared, including standard knowledge distillation (KD), self-distillation, MCC-KD, and MoRSD.
Gen-SSD achieves an average improvement of 5.9 points over Standard KD and up to 4.7 points relative to other advanced baselines. Gains are pronounced on multi-step reasoning tasks, highlighting Gen-SSD's superiority in facilitating structured reasoning transfer. Ablation studies reveal that low-PPL selection consistently outperforms random or high-PPL selection, confirming that learnability, not just correctness, is essential for effective supervision.
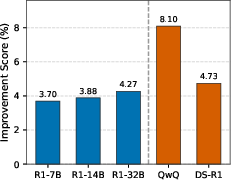
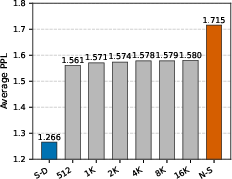
Figure 2: Performance increases of Gen-SSD over Standard KD as a function of teacher model scale, demonstrating substantial gains that correlate with teacher capability.
Additionally, increasing the chunk size or sampling strategy demonstrates that Gen-SSD’s interventions are robust across architectural and dataset configurations, including scenarios with inaccessible (API-based) teacher models, where only solution-level selection is possible.
Analysis of Trajectory Learnability and Structure
Further analysis of selected trajectories reveals that Gen-SSD consistently selects reasoning paths with lower average PPL and shorter token length compared to MoRSD and other post-hoc filtering methods. This indicates that Gen-SSD's intervention leads to the construction of more stable and learnable supervision. Granular investigation of per-chunk PPL trends demonstrates that Gen-SSD trajectories are smoother, with fewer abrupt increases that typify speculative or convoluted reasoning—a recurring failure mode for traditional filtering approaches.
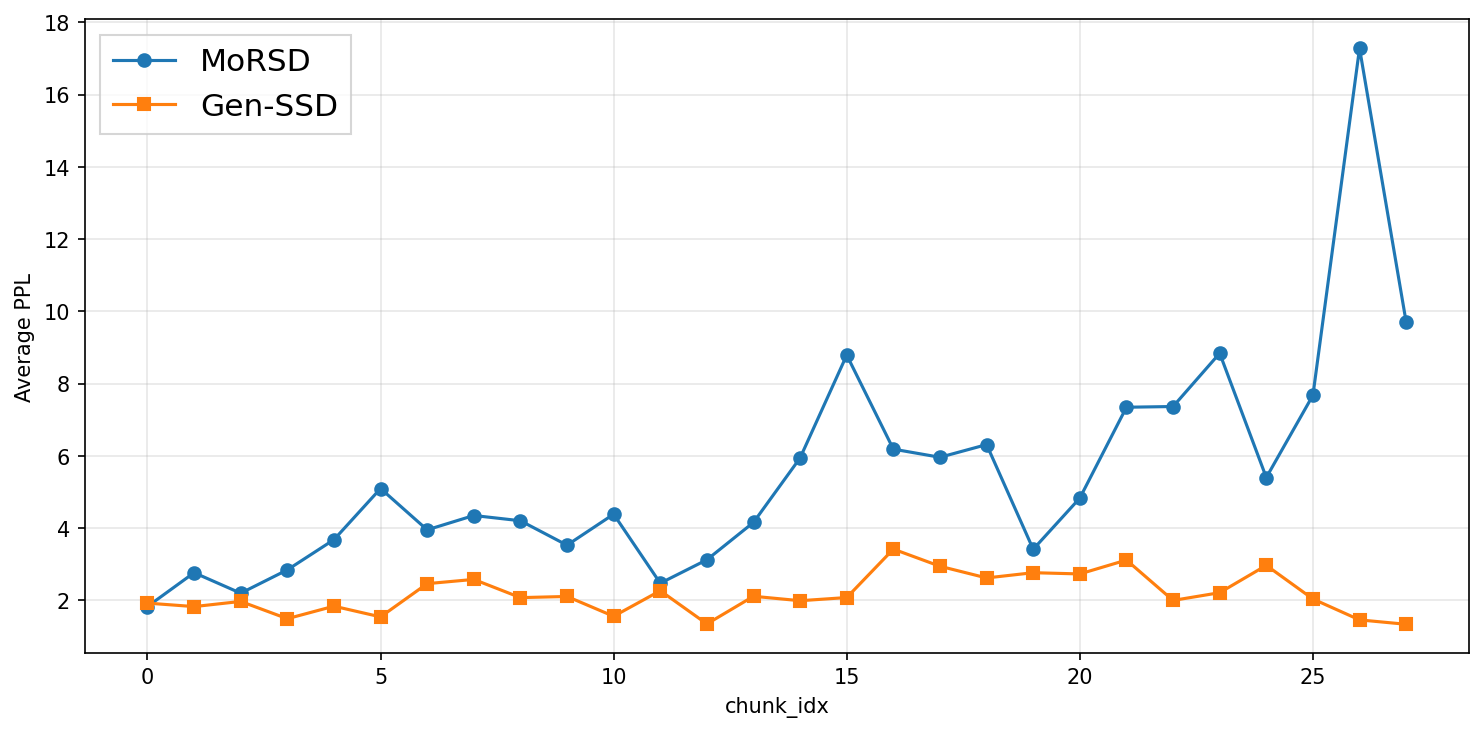
Figure 3: Comparison of PPL trends between Gen-SSD and MoRSD, illustrating smoother and more stable reasoning steps in Gen-SSD selections.
Empirical and qualitative inspection of high-PPL segments shows MoRSD and standard KD often preserve speculative language and reasoning detours, burdening the student with trajectories misaligned with its capacity. In contrast, Gen-SSD produces streams that converge more directly to solutions, thus improving trainability.
Implications and Future Directions
This work substantiates the effectiveness of student-in-the-loop, generation-time supervision for knowledge distillation in high-complexity reasoning domains. By allowing the student to guide the teacher’s trajectory expansion, the distillation process produces supervision that is both aligned with the student’s ability and cost-efficient in terms of computation. These findings suggest several broader implications:
- Practical Deployment: Smaller models equipped with Gen-SSD distilled supervision achieve significantly higher reasoning performance, enabling more practical adoption of advanced reasoning capabilities in resource-constrained or production settings.
- Distillation Paradigm Shift: The integration of student-aware signals during generation opens new avenues for controllable, adaptive supervision, moving beyond fixed, teacher-centric or post-hoc data engineering.
- Scalability and Generalization: Experiments demonstrate that Gen-SSD generalizes across diverse reasoning tasks and remains effective with both open-source and API-limited teacher models.
- Theoretical Significance: The strong empirical results challenge the prevailing notion that richer or longer reasoning traces from the teacher inherently produce more capable students; instead, careful alignment with student learnability via continuous supervision is critical.
Future research could explore reinforcement learning–based selection in tandem with Gen-SSD, apply the method to scientific and multimodal reasoning, and investigate student-in-the-loop generation dynamics for further optimizing the distillation cost/benefit curve across other domains.
Conclusion
Gen-SSD establishes a robust, student-aware approach to chain-of-thought distillation that systematically outperforms prior frameworks by leveraging generation-time selection. By aligning the supervision space with the student's learnability in a closed feedback loop, Gen-SSD sets a new direction for cost-efficient, high-fidelity distillation of advanced reasoning into compact models (2604.02819).