Unified and Efficient Approach for Multi-Vector Similarity Search
Abstract: Multi-Vector Similarity Search is essential for fine-grained semantic retrieval in many real-world applications, offering richer representations than traditional single-vector paradigms. Due to the lack of native multi-vector index, existing methods rely on a filter-and-refine framework built upon single-vector indexes. By treating token vectors within each multi-vector object in isolation and ignoring their correlations, these methods face an inherent dilemma: aggressive filtering sacrifices recall, while conservative filtering incurs prohibitive computational cost during refinement. To address this limitation, we propose MV-HNSW, the first native hierarchical graph index designed for multi-vector data. MV-HNSW introduces a novel edge-weight function that satisfies essential properties (symmetry, cardinality robustness, and query consistency) for graph-based indexing, an accelerated multi-vector similarity computation algorithm, and an augmented search strategy that dynamically discovers topologically disconnected yet relevant candidates. Extensive experiments on seven real-world datasets show that MV-HNSW achieves state-of-the-art search performance, maintaining over 90% recall while reducing search latency by up to 14.0$\times$ compared to existing methods.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Unified and Efficient Approach for Multi-Vector Similarity Search — Explained Simply
What is this paper about?
This paper looks at how computers quickly find the most relevant items (like documents, images, or passages) that match a search question. Instead of representing each item as a single “summary number list” (a single vector), the paper focuses on using many small “number lists” per item (multi-vectors), which keeps more details. The authors introduce MV-HNSW, a new, fast, and accurate way to search through these detailed, multi-part representations.
What questions are the researchers trying to answer?
In simple terms, they ask:
- How can we search detailed items (made of many parts) quickly, without losing important matches?
- Can we build an index (like a smart map) that’s designed for items with many parts, instead of forcing tools made for single-part items?
- How can we measure “how close” two detailed items are in a fair and efficient way?
- How can we avoid missing good results that are not directly linked in the index?
How did they approach the problem? (Methods in everyday language)
Think of each document as a book made of chapters or sentences, and each part gets its own “fingerprint” (a vector). A user’s query also has multiple fingerprints (for its words or phrases). The goal is to find the books whose parts match the query parts best.
Here’s what they built and improved:
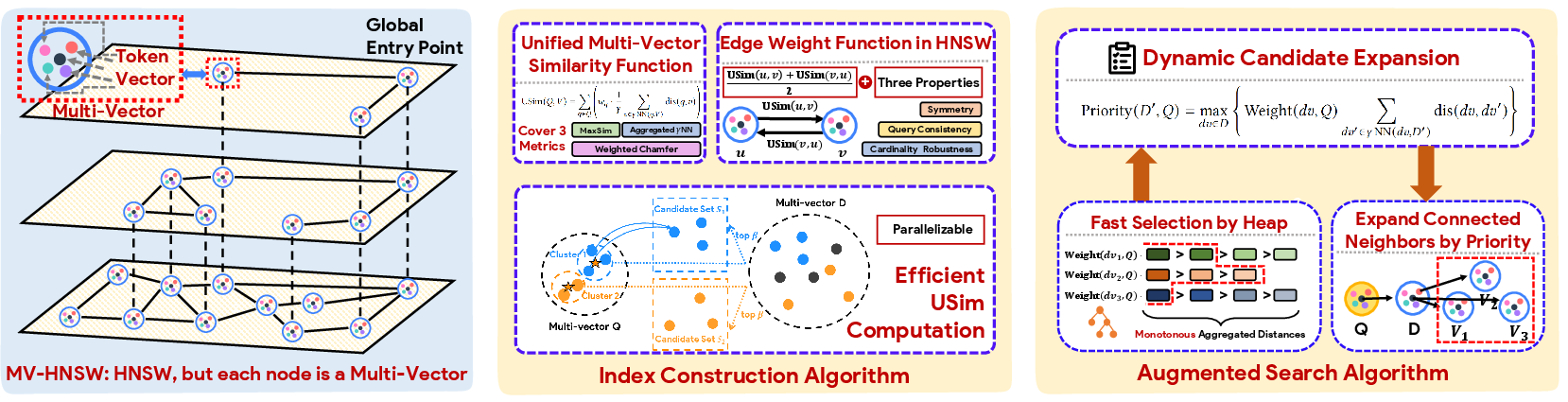
1) A multi-level “map” for multi-part items (MV-HNSW)
- Imagine a city map with layers: highways at the top, then big roads, then local streets. You start on top to get close quickly, then move down to find precise locations.
- MV-HNSW is a layered graph where each node is a whole item (like a document), and edges connect items that are similar.
- This is different from older methods that treated each small part separately. Here, the whole item is the unit—so the index “understands” that parts belong together.
2) A fair way to measure closeness between two multi-part items
- They designed a new edge-weight (connection strength) between two items that:
- Treats both items fairly (symmetry: A close to B means B is close to A).
- Doesn’t unfairly favor long items with more parts (cardinality robustness).
- Ensures that if two items are connected strongly, they will act similarly for many queries (query consistency).
- Earlier multi-vector metrics didn’t satisfy these three properties, which led to missed results or unstable search.
3) Faster similarity checking using grouping
- Checking similarity between “every part of the query” and “every part of an item” is slow.
- They speed this up by:
- Grouping the query’s parts into clusters (like grouping your shopping list by “fruits,” “dairy,” etc.).
- For each group, they find a small set of promising parts in the item and then check only inside those small sets.
- This keeps accuracy high while cutting down the work.
4) Smarter search that can leap to good results (even if not directly connected)
- Sometimes the best answers aren’t directly linked on the map because the index was built without knowing future queries.
- To fix this, they precompute an “Auxiliary Navigation Table” (ANT): for each part, it records which other items have parts closely related to it.
- During search, when they visit an item, they use ANT to “jump” to other likely relevant items, guided by a simple priority score. This helps uncover good answers that were topologically distant.
What did they find? Why is it important?
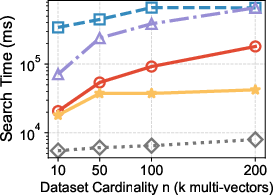
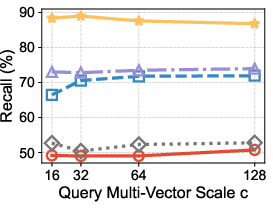
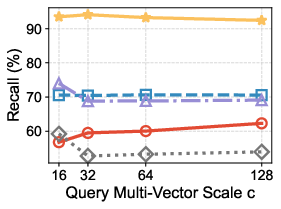
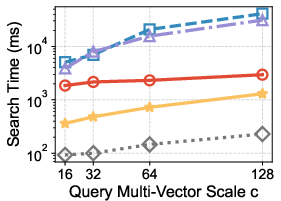
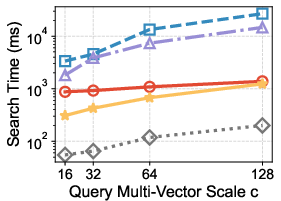
- Across 7 real-world datasets, their method kept high accuracy (over 90% recall, meaning it finds most of the true top answers) while being much faster—up to 14 times faster than popular existing methods.
- It outperformed strong baselines that adapted single-vector indexes to multi-vector data.
- This matters because many modern AI systems (like Retrieval-Augmented Generation that helps LLMs look up facts) need fast and accurate search over detailed representations. Better speed and recall means better answers, sooner.
What’s the bigger impact?
- MV-HNSW shows how to build a search index that natively supports multi-part representations, which are increasingly common in text, images, and other media.
- The three-part design—fair edge weights, faster similarity computation, and augmented search jumps—can make future search systems both smarter and faster.
- This can improve document retrieval, question answering, recommendation systems, and any application where fine-grained matching matters.
Knowledge Gaps
Unresolved gaps and open questions
Below is a concise, actionable list of the knowledge gaps, limitations, and open questions that remain unresolved in the paper.
- Formal proof completeness and assumptions:
- The proof of query consistency is only sketched and deferred to an online version; explicit conditions (e.g., vector norm constraints, metric normalization, γ>1) under which the bound holds are not stated.
- The cardinality robustness argument assumes similarity values lie in [-1, 1]; the required normalization of embeddings and compatibility with non-normalized inner products or L2 distances are not specified.
- Ambiguity in distance/similarity definitions:
- The paper defines inner product as a “distance” with larger values indicating greater similarity, which contradicts standard distance semantics; this creates ambiguity in maximization vs minimization throughout algorithms and proofs.
- It is unclear how the framework adapts when the base metric is a true distance (e.g., Euclidean) versus a similarity (e.g., cosine/inner product), especially for stopping criteria and thresholds.
- Generality of the edge-weight function:
- It is not shown whether the proposed edge-weight function f still satisfies symmetry, cardinality robustness, and query consistency for γ>1, weighted tokens (non-uniform wq), or alternative base metrics (e.g., cosine, L2) without additional assumptions.
- The effect of approximate USim (used during index construction/search) on the theoretical properties of f and the resulting graph connectivity is not analyzed.
- Parameterization and sensitivity:
- No systematic study of hyperparameters (M, efC, efS, γ, number of clusters √|Q|, β, ANT size M′) and their impact on recall/latency, stability, and memory.
- Lack of guidance for setting token weights wq (learned vs heuristic vs all-ones) and the sensitivity of performance and correctness (e.g., query consistency) to those weights.
- Scalability and memory overhead:
- The space and build-time cost of the Auxiliary Navigation Table (ANT) is not quantified; storing M multi-vector pointers per token for all tokens can be prohibitive at token-level granularity (potentially billions of token vectors).
- Memory footprint of MV-HNSW nodes storing all token vectors per object (especially token-level embeddings) and the feasibility on large-scale corpora are not evaluated.
- No analysis of the incremental update cost and memory churn for dynamic datasets (insertions/deletions), including how to maintain ANT and graph consistency.
- Complexity and performance guarantees:
- The time complexity hides constants by assuming d, c, γ are small constants; in practice c (number of token vectors per object) can be large and variable—no worst-case or practical bounds for high-cardinality objects are provided.
- No theoretical or empirical bounds on the overhead of dynamic candidate expansion (via ANT) in the worst case; potential explosion in expansions and its effect on latency is not analyzed.
- Absence of recall guarantees or convergence properties of the augmented search with respect to HNSW-like parameters.
- Practicality of ANT construction and usage:
- The construction of ANT relies on HNSW over all token vectors plus per-token top-γ aggregation over candidate multi-vectors; build-time and I/O costs at scale are not reported.
- The online priority computation appears to require per-candidate γNN between a token v and V′; it is unclear whether these are precomputed and stored with ANT or computed on the fly, and what the resulting compute/memory trade-offs are.
- Handling duplicates, updates, and deletions in ANT (and their propagation to search behavior) is not addressed.
- Algorithmic details and correctness:
- The neighbor selection heuristic used by HNSW to ensure graph navigability (diversity/routing-aware pruning) is not described; using simple top-M pruning may harm small-world properties and search recall.
- The stopping criterion in the augmented SEARCH-LAYER mixes approximate USim scores with candidate queues; implications for premature termination and missed neighbors are not analyzed.
- The definition of Contrib(v, Q) and its efficient computation assumes access to γNN(q, V) for all q; the paper does not explain how these are obtained without redundant recomputation at query time.
- Robustness across modalities and tasks:
- Evaluation is limited (as presented) to recall and latency; the impact on downstream task quality (e.g., RAG answer accuracy) is not reported.
- Generalization to non-text modalities (images, audio) or cross-modal multi-vector representations, where token semantics and cardinalities differ substantially, is unexplored.
- Behavior under out-of-distribution queries or domain shifts in embedding distributions is not studied.
- Metric and model support:
- Although the unified USim claims to encompass several metrics, empirical results use inner product; support and performance for cosine and L2, and any necessary normalization or rescaling, are not provided.
- Integration with learned token weights (e.g., Weighted Chamfer) at query time is unclear if the index edges were built with w=1; mismatch between build-time and query-time weighting and its effects are not evaluated.
- Compression and systems integration:
- No exploration of vector compression (e.g., PQ, OPQ) for node token vectors or ANT entries to reduce memory and bandwidth, and the effect on accuracy.
- Distributed/sharded deployment is not discussed (query routing, cross-shard traversal, ANT partitioning), which is critical for large-scale systems.
- GPU acceleration opportunities and bottlenecks for clustering, γNN, and candidate expansion are not addressed.
- Edge cases and failure modes:
- Performance and accuracy for extreme cardinalities (very short queries, ultra-long documents) are not analyzed.
- Potential hubness re-emergence due to high-cardinality objects despite normalization (e.g., via token redundancy or distribution skew) is not examined.
- Stability and numerical behavior of the softmax-based Weight(v, Q) in the priority heuristic (e.g., overflow/underflow, sensitivity to scale) are not discussed.
- Evaluation completeness:
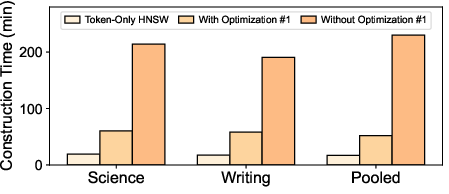
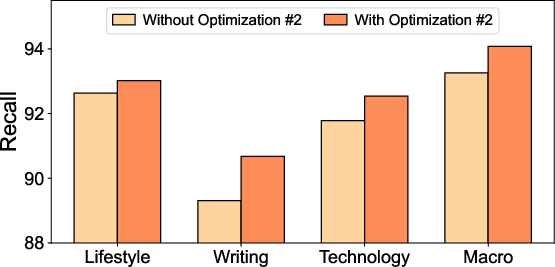
- The paper claims experiments on seven datasets, but details on datasets, baselines (including recent late-interaction variants and production systems that support multi-vector retrieval), ablations (edge-weight only vs acceleration only vs augmentation only), construction time, and memory usage are missing in the provided text.
- Lack of ablation to quantify the individual contributions and trade-offs of the three components: edge-weight function, accelerated USim via clustering, and ANT-based augmentation.
- Applicability beyond MaxSim/Aggregate NN:
- Open question whether MV-HNSW and f can support more complex multi-vector matching (e.g., optimal bipartite matching, Earth Mover’s Distance, coverage/diversity-aware objectives) while preserving the three properties and efficiency.
- Parameterized quality–efficiency controls:
- No principled way is provided to tune efC/efS/M and ANT expansion depth to meet target recall or latency SLAs; adaptive mechanisms or auto-tuning remain open.
These gaps point to concrete next steps: tighten theoretical assumptions and proofs, provide comprehensive sensitivity and ablation studies, quantify memory/build-time costs (especially for ANT), explore compression and distributed deployment, and broaden empirical validation across metrics, modalities, and downstream tasks.
Practical Applications
Immediate Applications
The following use cases can be deployed now by leveraging MV-HNSW’s native multi-vector index, accelerated similarity computation, and augmented search strategy to achieve high-recall, low-latency retrieval.
- Semantic RAG at token/passage level (software/AI, enterprise search, education, legal, healthcare)
- What: Replace single-vector retrieval in Retrieval-Augmented Generation pipelines with MV-HNSW for finer-grained matching (e.g., token-level MaxSim).
- Why: Up to 14× lower latency with >90% recall enables more contextually accurate grounding for LLMs across long documents and mixed-quality corpora.
- Tools/workflows: “MV-aware” retriever component; query encoder producing token vectors; MV-HNSW index for docs; augmented search for hard-to-reach candidates.
- Assumptions/dependencies: Availability of multi-vector encoders (e.g., ColBERT-style); additional memory to store token vectors; offline ANT construction time; vector DB or service that supports custom graph indexes.
- Passage-level literature & evidence retrieval (healthcare/biomed, legal, scientific search)
- What: Retrieve documents based on coverage across query facets (e.g., diagnosis + treatment + outcome), using weighted token vectors.
- Why: Reduces semantic dilution; improves coverage-based ranking for systematic reviews and case law discovery.
- Tools/workflows: Weighted USim (e.g., weighted Chamfer or MaxSim); token importance weights learned per domain; MV-HNSW for indexing.
- Assumptions/dependencies: Reliable domain embeddings; governance for weight learning to avoid bias; compute for index build.
- E-commerce product and attribute search (retail)
- What: Index product pages as multi-vectors (title, specs, bullets, reviews) and match query tokens to the most relevant fields.
- Why: Better facet alignment (e.g., “waterproof hiking boots, arch support”) boosts precision and CTR.
- Tools/workflows: Field-wise tokenization; MV-HNSW index per catalog; inference-time augmented search to find attribute-rich but topologically distant items.
- Assumptions/dependencies: Product data normalization; periodic re-indexing for changing catalogs.
- Code and API snippet retrieval (software engineering/devtools)
- What: Index functions/methods as sets of token/statement embeddings for intent-level code search and RAG for IDE copilots.
- Why: Token-level matching captures API usage patterns and edge cases better than file-level embeddings.
- Tools/workflows: Code encoders; MV-HNSW retrieval for docstrings + bodies; IDE plugin integrating multi-vector kNN.
- Assumptions/dependencies: Stable code embeddings; storage overhead manageable for large monorepos.
- Multimodal content search at patch/segment level (media/search)
- What: Index images/videos as multi-vectors (patch or frame embeddings) to support fine-grained visual grounding.
- Why: Improves retrieval for queries referencing small objects or specific frames (“red logo in top-right frame”).
- Tools/workflows: Vision encoders (ViT/CLIP) producing patch/frame vectors; MV-HNSW index; ANT to surface visually similar but disconnected items.
- Assumptions/dependencies: Larger storage for patch/frame vectors; precomputation budget for ANT.
- Enterprise knowledge discovery and deduplication (enterprise search/knowledge management)
- What: Detect fine-grained duplication or overlap across documents/chunks for cleanup and governance.
- Why: Improves RAG quality and reduces hallucinations from redundant/conflicting sources.
- Tools/workflows: Token-level overlap scoring with MV-HNSW; workflows for content pruning and version tracking.
- Assumptions/dependencies: Versioned corpora; change management to update indices incrementally.
- Entity linking and disambiguation (NLP/knowledge graphs)
- What: Use multi-vector representations for entities (aliases, context snippets) to disambiguate references in text.
- Why: Higher precision linking in noisy or multilingual settings.
- Tools/workflows: Entity encoders; MV-HNSW as core index for candidate generation and re-ranking.
- Assumptions/dependencies: Coverage of alias/context inventory; continued maintenance as knowledge evolves.
- Real-time FAQ and helpdesk retrieval (customer support)
- What: Map user queries to multi-vector FAQs (title, steps, troubleshooting tokens).
- Why: Faster, more accurate answers; improved self-serve resolution.
- Tools/workflows: MV-HNSW retriever behind chatbot; dynamic candidate expansion for related but disconnected articles.
- Assumptions/dependencies: Periodic index refresh; logging to monitor recall/latency trade-offs.
- Personal information retrieval (daily life/productivity)
- What: Power fine-grained search over notes, emails, and documents at sentence/token level.
- Why: Users can retrieve specific details (e.g., “expense policy threshold” within a long email thread).
- Tools/workflows: Local or cloud-based MV index; privacy-preserving deployment (on-device if feasible).
- Assumptions/dependencies: Storage limits on client devices; privacy constraints.
- Vector database integrations and SDKs (software/infrastructure)
- What: Provide MV-HNSW as a native index option in vector DBs/services, or as an SDK with Python/Java bindings.
- Why: Lowers barrier for adoption; standardized edge-weight and search augmentation logic.
- Tools/workflows: Plugins for FAISS/Milvus/Weaviate; REST/gRPC services exposing MV APIs.
- Assumptions/dependencies: Vendor extensibility; maintenance of ANT and cluster-based USim components.
Long-Term Applications
The following opportunities benefit from further research, scaling, system engineering, or standardization before broad deployment.
- Distributed, sharded MV-HNSW for web-scale corpora (software/infrastructure)
- What: Horizontal scaling of MV-HNSW across clusters with consistent routing and cross-shard augmented search.
- Why: Serves web-scale search/RAG with multi-vector semantics.
- Assumptions/dependencies: Shard-aware graph navigation; distributed ANT synchronization; fault tolerance.
- Real-time, high-throughput updates and streaming indices (news/finance/social)
- What: Support continuous updates as documents and market events stream in, without costly rebuilds.
- Why: Keep retrieval fresh for time-sensitive applications.
- Assumptions/dependencies: Incremental ANT maintenance; lock-free graph updates; eventual consistency guarantees.
- GPU/ASIC-accelerated multi-vector similarity and graph traversal (software/hardware)
- What: Hardware acceleration for USim computation and graph search to support low-latency, high-QPS workloads.
- Why: Pushes the efficiency frontier for large token-cardinality objects.
- Assumptions/dependencies: GPU-friendly batching; memory layouts for token vectors; specialized kernels.
- Privacy-preserving and compliant MVSS (healthcare/finance/public sector)
- What: Apply secure enclaves, federated retrieval, or homomorphic encryption to multi-vector search.
- Why: Enable fine-grained retrieval without exposing sensitive token-level data.
- Assumptions/dependencies: Cryptographic protocols compatible with graph traversal; acceptable latency overheads.
- Personalized and context-adaptive MV retrieval (recommendation/assistants)
- What: Learn token weights (w_q) and dynamic segmentation per user/task to tailor retrieval.
- Why: Boosts relevance and user satisfaction.
- Assumptions/dependencies: On-device or server-side personalization pipelines; fairness/robustness safeguards.
- Cross-lingual and cross-modal MVSS (global search/education)
- What: Align token vectors across languages and modalities for unified multi-vector retrieval.
- Why: Richer educational and global search experiences.
- Assumptions/dependencies: High-quality multilingual/multimodal encoders; domain adaptation.
- Robotics and autonomous systems scene retrieval (robotics)
- What: Retrieve scenes or maps via multi-vector patch descriptors for localization and planning.
- Why: Robust place recognition in dynamic environments.
- Assumptions/dependencies: Robust visual encoders; low-power indexing on edge devices; update handling.
- Energy and industrial monitoring via multi-sensor retrieval (energy/IIoT)
- What: Represent time-series windows as multi-vectors (frequency bands, sensors) for fault search by example.
- Why: Faster diagnosis leveraging similar historical patterns.
- Assumptions/dependencies: Sensor embedding quality; storage/computation at the edge; streaming updates.
- Compliance, audit, and e-discovery with fine-grained coverage guarantees (policy/legal)
- What: Retrieve documents that collectively cover a policy query’s facets with explainable token-level matches.
- Why: Traceability and defensibility in audits and investigations.
- Assumptions/dependencies: Explainability tooling; standardized token-weight policies; governance frameworks.
- Benchmarking, fairness, and robustness standards for MVSS (academia/policy)
- What: Establish datasets and metrics for MVSS covering recall/latency, cardinality effects, and bias.
- Why: Promote reproducibility and responsible deployment.
- Assumptions/dependencies: Community adoption; shared evaluation suites and open-source baselines.
- Content safety and watermark detection at fine granularity (platform safety)
- What: Detect harmful or watermarked content using token/patch-level retrieval patterns.
- Why: Improved moderation and IP protection.
- Assumptions/dependencies: Labeled token/patch-level signals; regulatory compliance.
- Low-resource and on-device MVSS (edge/mobile)
- What: Compress and quantize multi-vectors and ANT for on-device private retrieval.
- Why: Personal assistants and offline search with privacy.
- Assumptions/dependencies: Product quantization for token vectors; memory-optimized graph representations; accuracy trade-offs.
- Workflow-aware MV pipelines with adaptive segmentation (MLOps)
- What: Learn segmentation granularity (token vs passage vs mixed) dynamically to optimize recall/latency per query class.
- Why: Tailors cost-performance to workload patterns.
- Assumptions/dependencies: Meta-learners or controllers; robust monitoring; safe fallback strategies.
- Tooling for explainable, facet-covered RAG (education/enterprise)
- What: Provide token-level evidence trails and coverage diagnostics for RAG outputs.
- Why: Trust and pedagogy in educational and enterprise settings.
- Assumptions/dependencies: UI/UX for visualizing token matches; logging and attribution pipelines.
Notes on feasibility and dependencies (cross-cutting):
- Memory/compute trade-offs: Multi-vector indexing increases storage and precomputation (ANT) costs; benefits hinge on budget and corpus size.
- Encoder quality: Gains depend on high-quality token/passage/multimodal encoders; domain adaptation may be needed.
- Integration: Adoption improves when vector databases and serving stacks expose native MV-HNSW and ANT features.
- Hyperparameters: Performance depends on M, efC/efS, γ, cluster counts, and token weights; autotuning pipelines are recommended.
- Update dynamics: Highly dynamic corpora require incremental maintenance strategies for both the graph and ANT.
Glossary
- Aggregate NN: A multi-vector similarity metric that aggregates distances to several nearest neighbors per query token (generalizing MaxSim by using γ>1). "Aggregate was originally introduced in Google's framework (called XTR~\cite{lee2023rethinking}) for multi-vector similarity search."
- Auxiliary Navigation Table (ANT): A precomputed mapping from token vectors to relevant multi-vectors used to guide search toward globally relevant but topologically distant candidates. "stored in an Auxiliary Navigation Table (ANT)."
- Cardinality robustness: A property of an edge-weight function ensuring its value does not systematically depend on the number of token vectors in either multi-vector. "An edge weight function is cardinality-robust if it does not exhibit systematic bias towards larger cardinalities of multi-vectors."
- ColBERT: A late-interaction retrieval model that encodes token-level embeddings and uses MaxSim for matching. "It was first introduced in ColBERT~\cite{khattab2020colbert}"
- Curse of dimensionality: The phenomenon whereby high-dimensional spaces make exact nearest neighbor search and distance-based methods inefficient. "Due to the curse of dimensionality"
- Dynamic candidate expansion strategy: A search-time method that augments graph traversal by adding promising candidates inferred from token-level correlations via ANT. "Dynamic Candidate Expansion Strategy."
- Edge weight function: The function assigning a similarity weight to an edge between two multi-vectors in the graph index. "The edge weight function is defined as the average of bidirectional normalized similarity between two multi-vectors and :"
- Filter-and-refine paradigm: A two-stage approach that first prunes candidates with coarse indices and then computes exact multi-vector similarity on the remaining set. "Most existing approaches follow a filter-and-refine paradigm."
- Gamma-nearest neighbors (γNN): The set of γ closest vectors to a given vector according to a chosen distance metric. "We use to denote these -nearest neighbors of in ."
- HNSW (Hierarchical Navigable Small World): A hierarchical graph-based index enabling efficient approximate nearest neighbor search. "The Hierarchical Navigable Small World (HNSW) graph \cite{malkov2018efficient} has become a dominant index for single-vector similarity search."
- IVF (Inverted File index): A coarse partitioning/quantization index that routes queries to a subset of posting lists for efficient ANN search. "single-vector indexes (e.g. HNSW \cite{malkov2018efficient} and IVF \cite{sivic2003video})"
- Markov's inequality: A probabilistic bound relating expectations to tail probabilities, used here to analyze query consistency. "Applying Markov's inequality \cite{DBLP:books/daglib/0012859} then yields a constraint on the distance discrepancy for any query ."
- MaxSim: A multi-vector similarity metric that sums, over query tokens, the maximum similarity to any token in a candidate. "MaxSim is the most prevalent multi-vector similarity metric."
- Multi-Vector Similarity Search (MVSS): A retrieval paradigm where both queries and documents are represented by sets of token or passage vectors. "This paradigm, known as Multi-Vector Similarity Search (MVSS) \cite{lee2023rethinking, khattab2020colbert}, preserves fine-grained semantics and enables more precise relevance matching"
- MV-HNSW: A hierarchical graph index proposed in this paper that natively indexes multi-vector objects with a new edge-weight function and augmented search. "we propose MV-HNSW, the first native hierarchical graph index designed for multi-vector data."
- Product quantization: A vector compression and indexing technique that partitions dimensions into subspaces and quantizes each to accelerate ANN search. "or product quantization \cite{jegou2010product} to prune dissimilar objects."
- Query consistency: A property requiring that nodes connected by high-weight edges have similar similarity scores to any query. "An edge weight function is said to be query-consistent if, whenever two nodes are similar under , their scores remain similar for any query."
- Retrieval-Augmented Generation (RAG): A technique that augments LLM outputs by retrieving external knowledge via vector search. "With the rapid advancement of Retrieval-Augmented Generation (RAG) \cite{DBLP:journals/corr/abs-2312-10997}, vector similarity search has become essential for enabling LLMs to access external knowledge."
- Softmax normalization: An exponentiation-and-normalization operation used to weight contributions, emphasizing larger values. "is derived using softmax normalization to amplify high-contribution token vectors and suppress low-impact ones."
- Topological disconnect: A search issue where true nearest neighbors are distant or unconnected in the index graph due to structure and degree limits. "Topological Disconnect: Due to multi-vector structural complexity, true nearest neighbors may be topologically distant or disconnected from traversed nodes within the graph index."
- Weighted Chamfer: A variant of Chamfer similarity for multi-vector matching that assigns learnable weights to token vectors. "Weighted Chamfer was proposed to explicitly account for importance of different token vectors in multi-vector similarity search~\cite{garg2025incorporating}."
Collections
Sign up for free to add this paper to one or more collections.

