- The paper demonstrates that leveraging experience replay with Reptile meta-updates robustly reduces catastrophic forgetting in large language models during continual pre-training.
- It introduces an efficient meta-experience replay (MER) method that balances stability and plasticity with minimal computational overhead.
- Empirical results show MER outperforms replay-only and joint training baselines across multiple scales and downstream tasks.
Revisiting Replay and Gradient Alignment for Continual Pre-Training of LLMs
Introduction and Motivation
The paper addresses the challenge of continual pre-training (CPT) for LLMs, focusing on the stability-plasticity dilemma that arises when models are incrementally updated with new data distributions. Rather than retraining from scratch, CPT aims to efficiently update LLMs while mitigating catastrophic forgetting of previously acquired knowledge. The study systematically evaluates two principal strategies from the continual learning literature—experience replay and gradient alignment—at scale, using the Llama architecture across multilingual corpora. The work introduces an efficient implementation of meta-experience replay (MER), combining replay with Reptile-based meta-optimization for gradient alignment, and provides a comprehensive scaling analysis of replay rates versus model size.
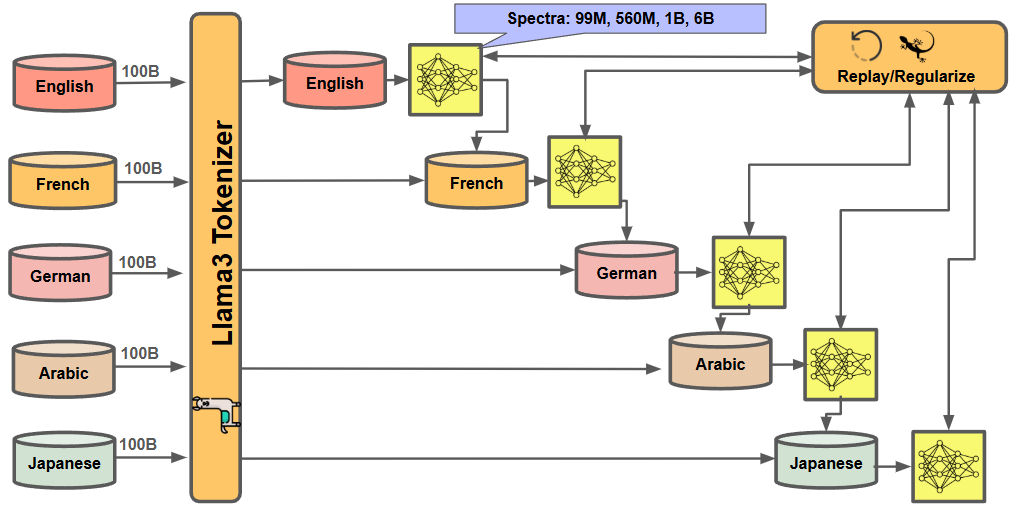
Figure 1: Continual pre-training of Llama models on English, French, German, Arabic, and Japanese sequentially using meta-experience replay, which combines replay with gradient alignment through Reptile meta-optimization.
Methodology
Experience Replay
Experience replay maintains a buffer of past samples, interleaving them with new data during training to stabilize learning and reduce forgetting. The buffer is implemented on disk with asynchronous prefetching and caching, enabling scalable replay for large-scale LLMs without exhausting RAM or VRAM. The replay ratio α controls the fraction of each batch drawn from the buffer, with experiments conducted at α∈{0,0.25,0.5}.
MER augments experience replay with Reptile-style meta-updates, promoting gradient alignment across batches. Every k steps, model parameters are interpolated with those from k steps prior, regularizing updates to maximize the dot product between gradients of new and replayed data. This approach is computationally efficient, adding negligible overhead relative to standard training.
Experimental Setup
Models from the Spectra LLM suite (99M, 560M, 1B, 6B parameters) are continually pretrained on five language-specific corpora (English, French, German, Arabic, Japanese), each with 100B tokens. The training follows a cosine learning rate schedule with linear warmup and a batch size of 4096. Evaluation metrics include forgetting score, retained loss, learned loss, and downstream task accuracy (HellaSwag, PiQA, PubMedQA).
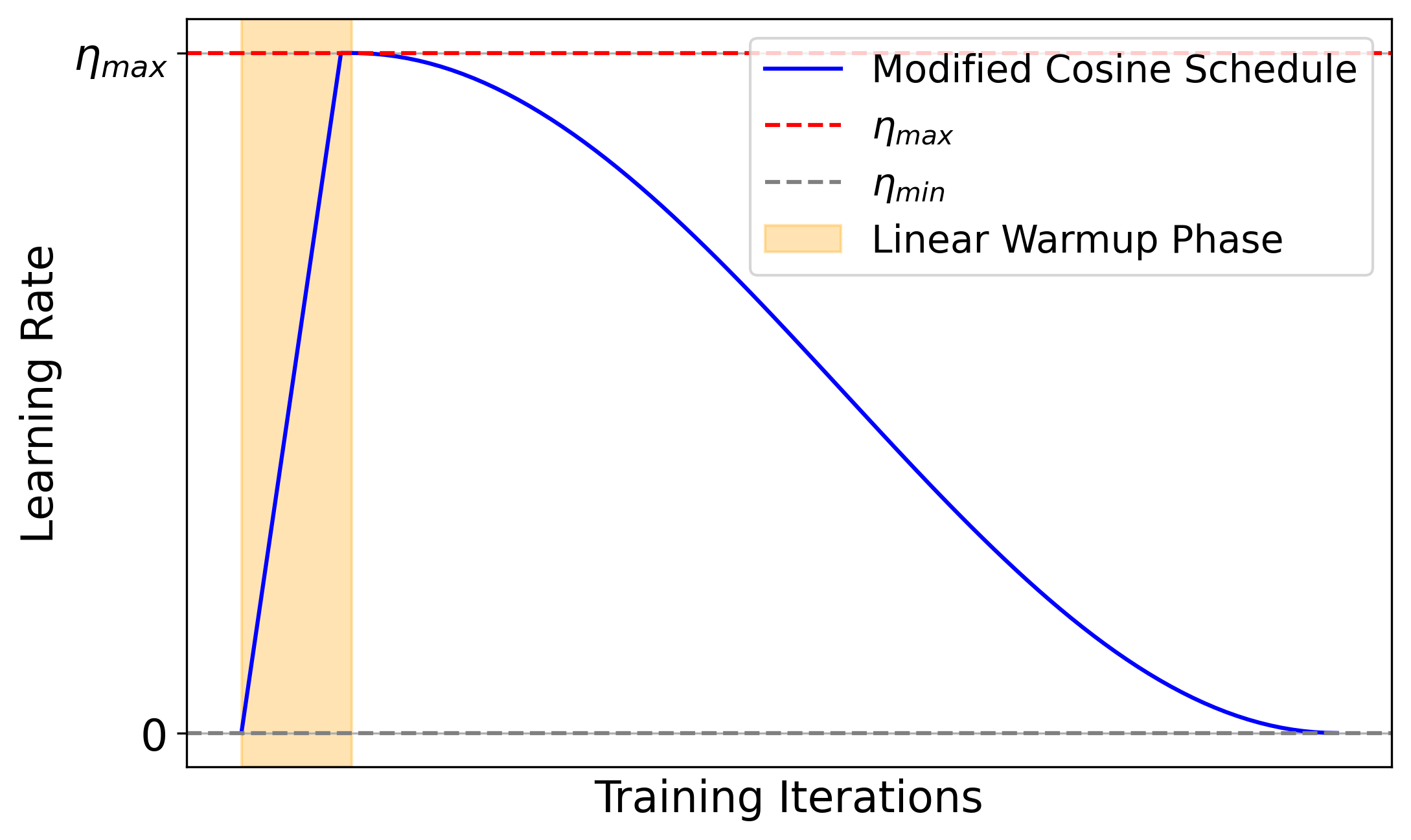
Figure 2: Dataset composition for continual pre-training and the cosine learning rate schedule used for all experiments.
Empirical Results
Replay Efficiency and Model Scaling
Replay substantially reduces forgetting compared to sequential training, with higher replay ratios yielding better retention. Notably, a 560M model with 50% replay matches the validation loss of a 1B model trained without replay, demonstrating that replay is a more compute-efficient strategy for knowledge retention than increasing model size.
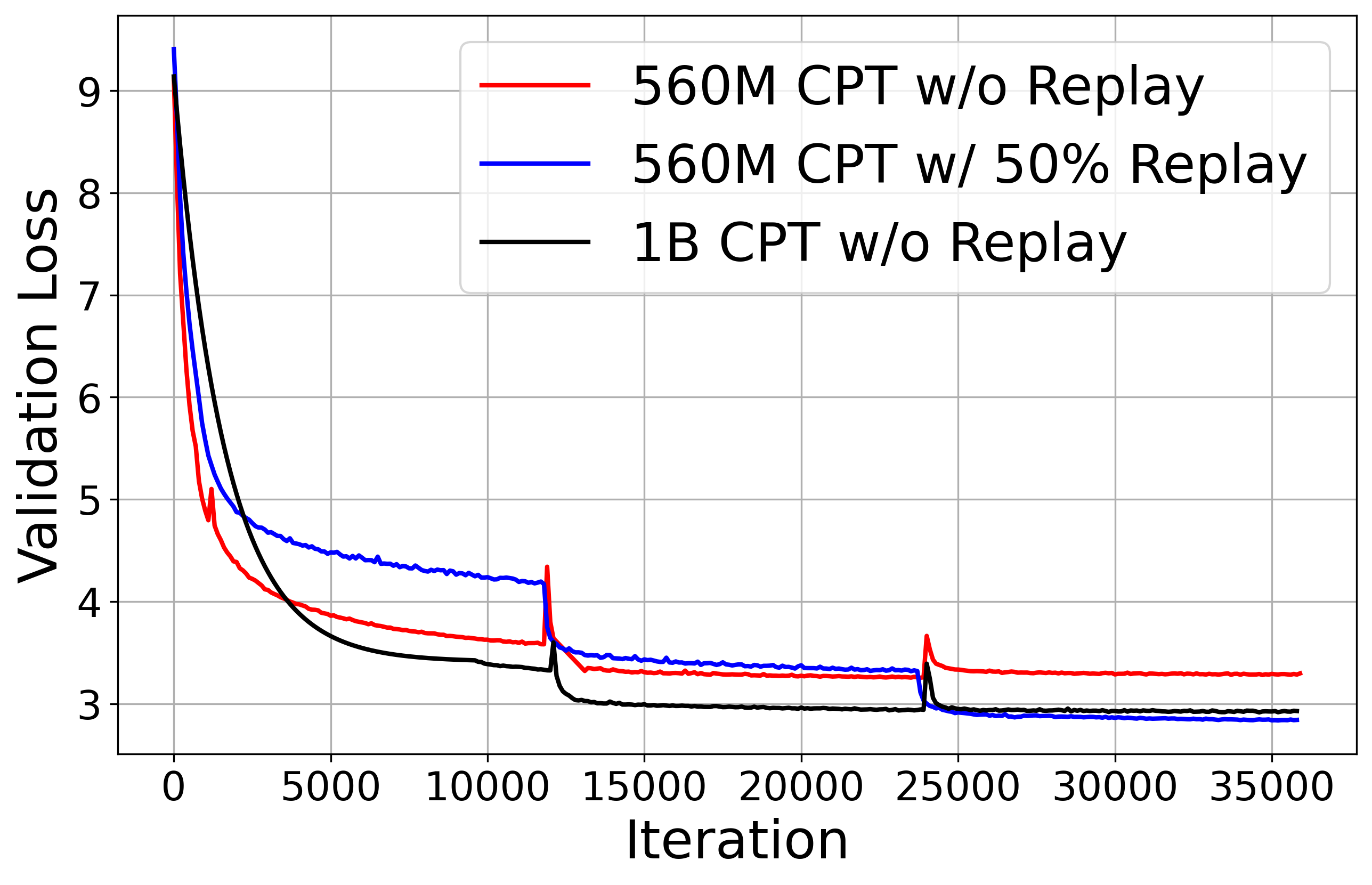
Figure 3: Comparison of cross-entropy validation loss curves for the Spectra 560M model with replay to the Spectra 1B model without replay.
Synergy of Replay and Gradient Alignment
Combining replay with Reptile meta-updates (MER) consistently achieves the lowest average forgetting scores across all model sizes and task sequences. The effect is robust to scaling the number of tasks, with MER maintaining strong retention even as the diversity and number of tasks increase.
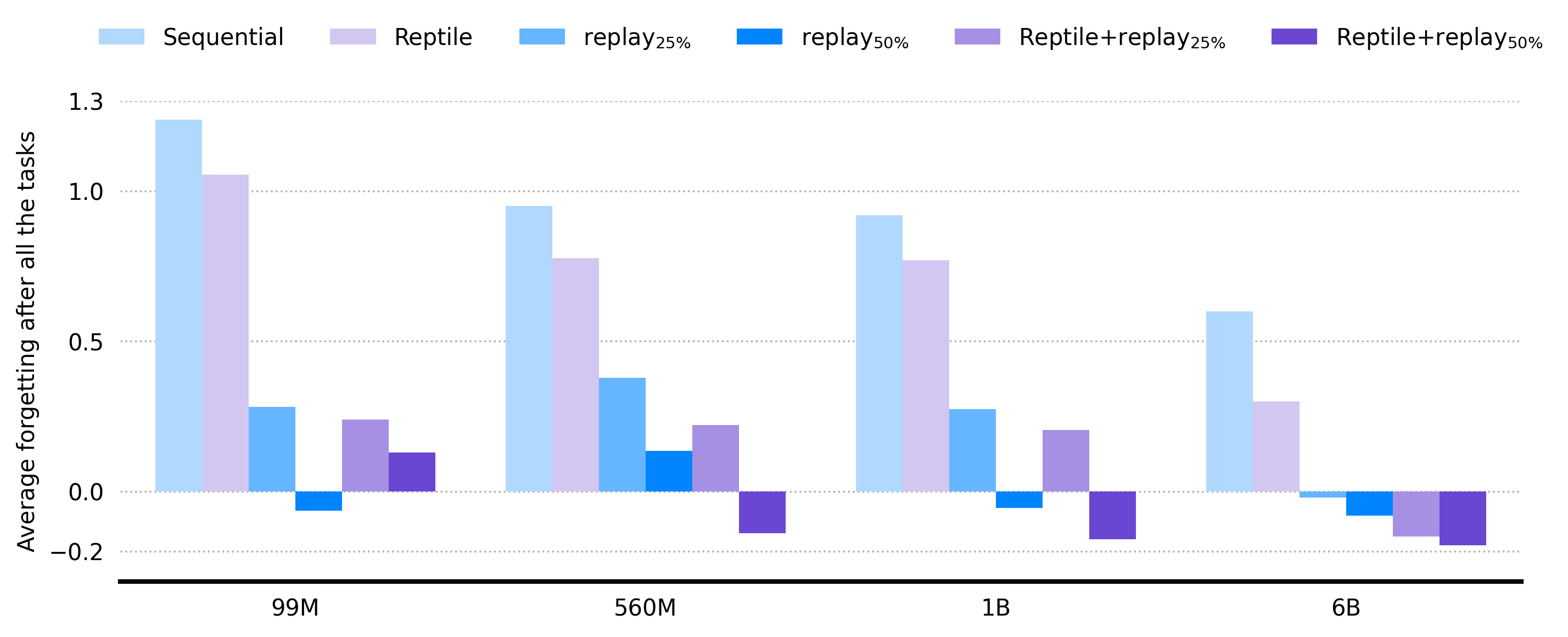
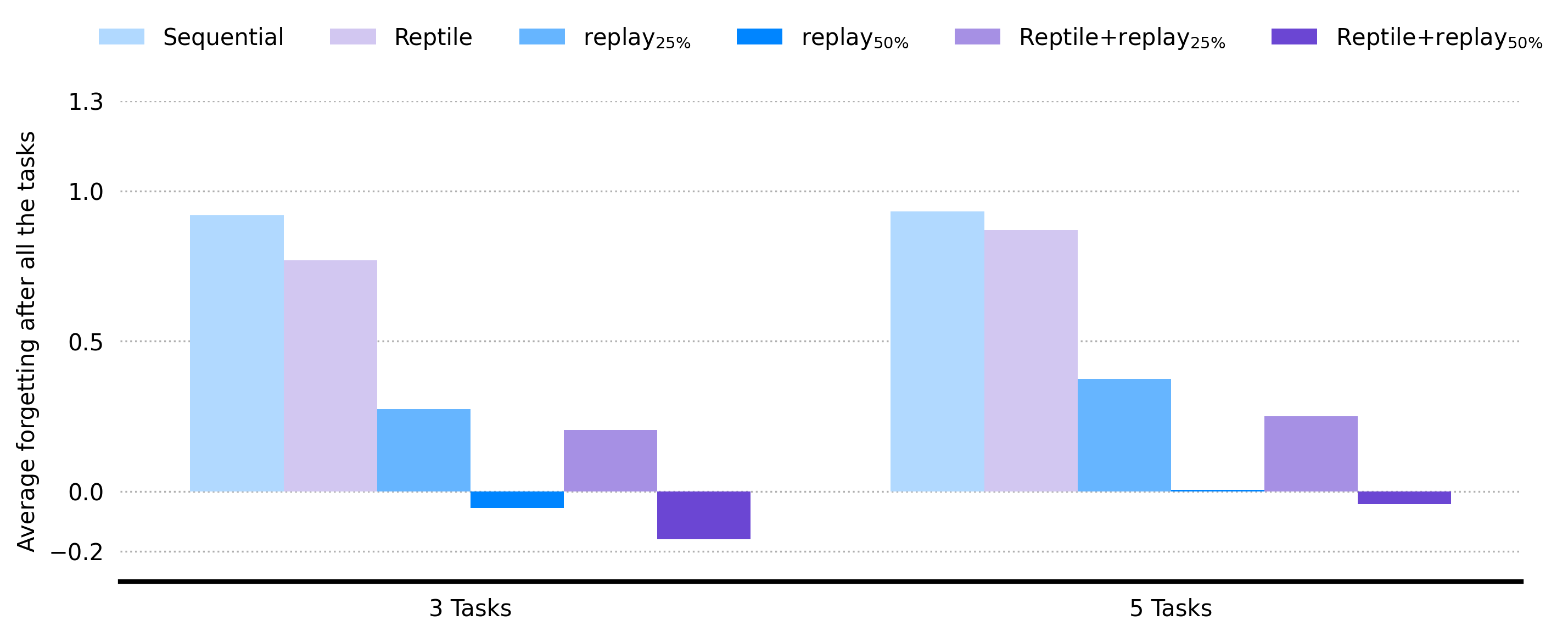
Figure 4: Final average forgetting scores across model scales and task counts, highlighting the superior retention of MER.
MER not only improves stability but also enhances generalization to downstream tasks. For the 560M model, 25% replay with Reptile outperforms both joint training and replay-only baselines on HellaSwag, PiQA, and PubMedQA. The effect is most pronounced in larger models (6B), where MER yields the highest average downstream accuracy.
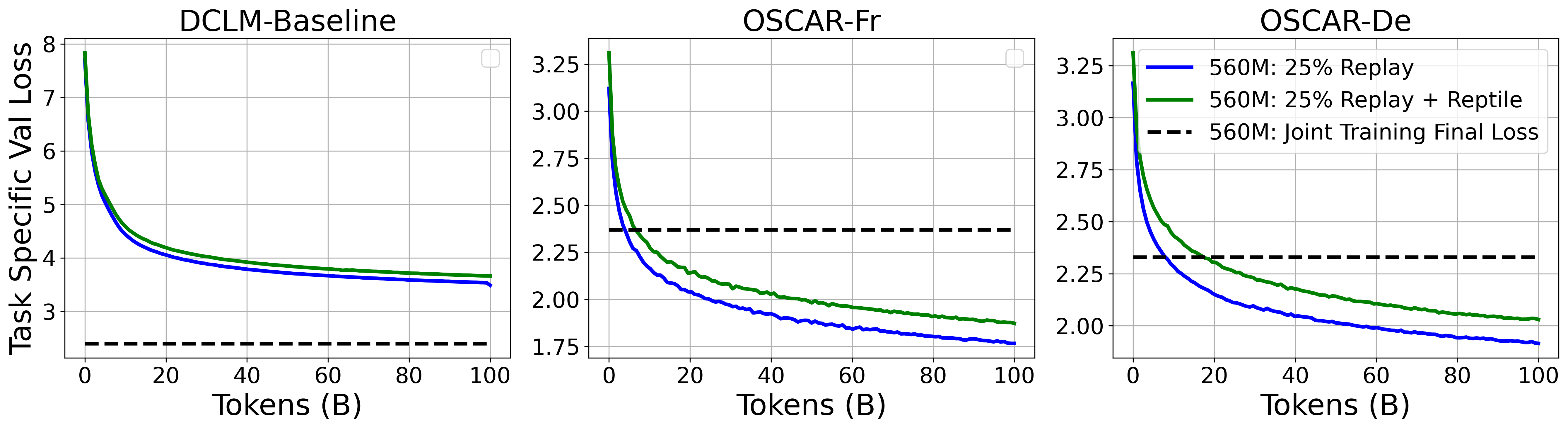
Figure 5: Task-specific cross-entropy validation loss curves for a 560M model during CPT, showing MER approaches the joint training baseline.
Scaling Laws: Compute vs. Replay vs. Model Size
Scaling analysis reveals that, for large models, investing compute in moderate replay rates (25%) is more efficient than increasing replay to 50%. Further, increasing model size with moderate replay yields better stability and plasticity than increasing replay alone. The integration of Reptile meta-updates provides nearly free gains in both metrics, with performance improvements scaling favorably with model size.
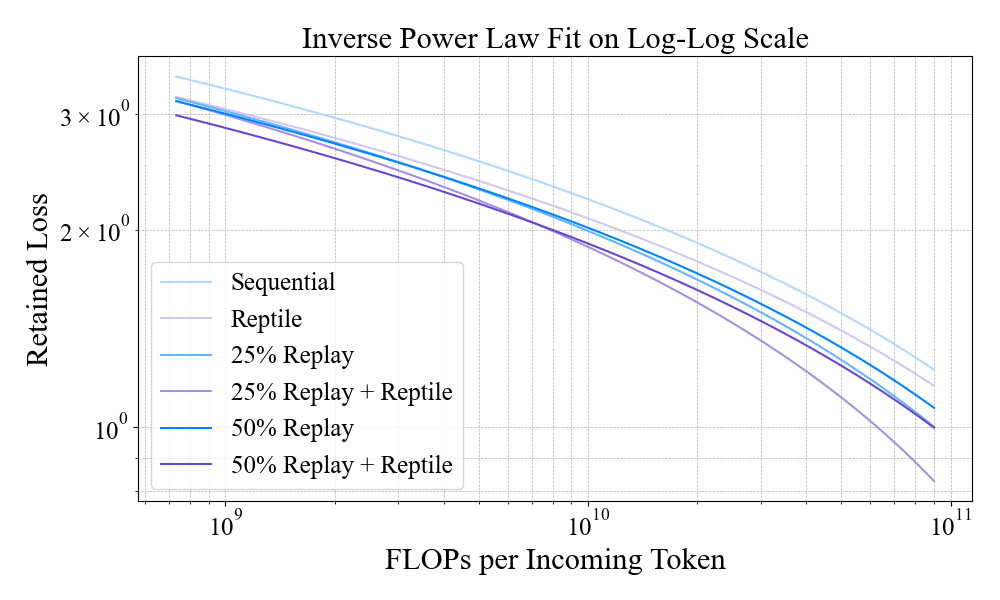
Figure 6: Stability scaling analysis—retained loss vs. compute per token, showing inverse power law trends for each model family.
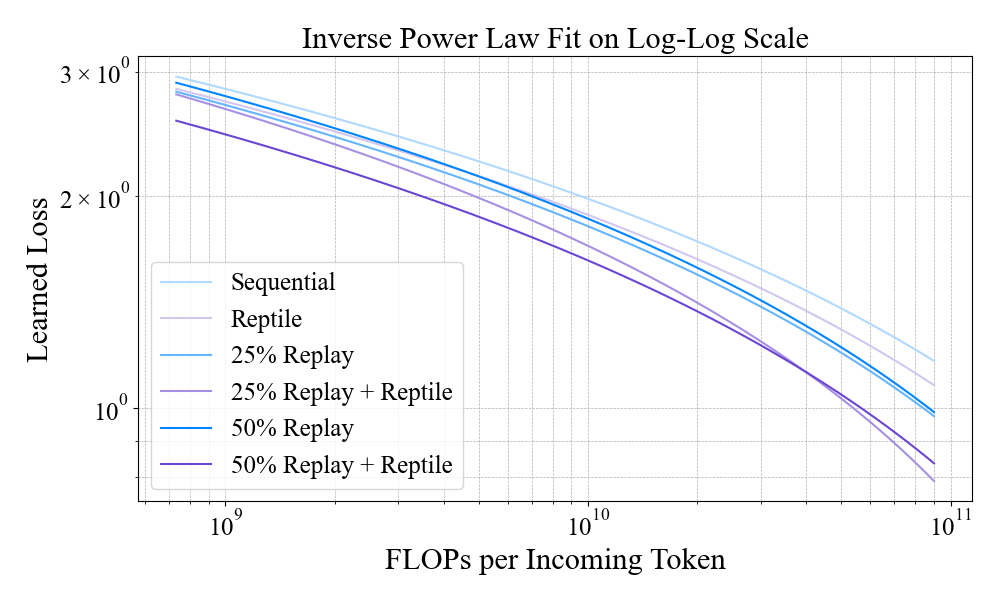
Figure 7: Plasticity scaling analysis—learned loss vs. compute per token, demonstrating efficient adaptation with MER.
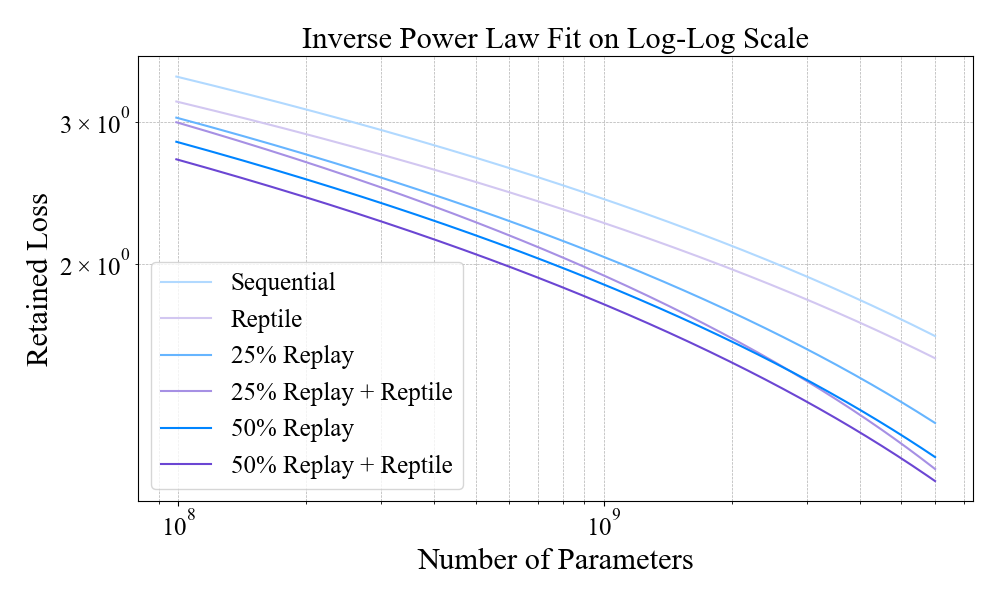
Figure 8: Stability scaling analysis—retained loss vs. model size, confirming replay and MER benefits across scales.
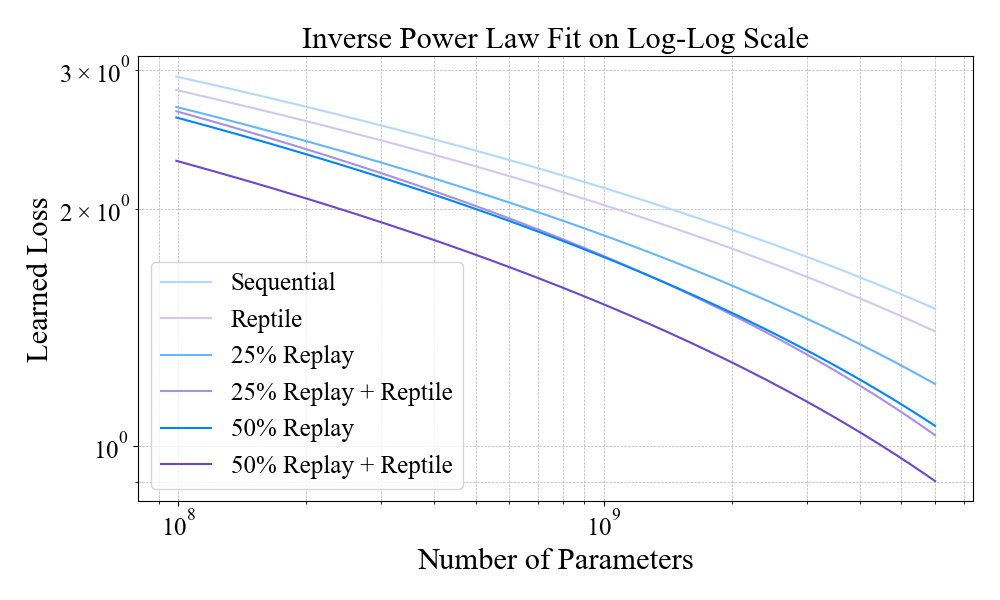
Figure 9: Plasticity scaling analysis—learned loss vs. model size, highlighting adaptation efficiency with replay and MER.
Implementation Details
The disk-backed replay buffer is compatible with Megatron/NeoX and supports infinite capacity, asynchronous prefetching, and offset-based indexing for low-latency sampling. MER is implemented by periodically interpolating model parameters every k batches, with negligible compute overhead. The approach is scalable to hundreds of billions of tokens and large model sizes, with resource requirements dominated by FLOPs and VRAM for model parameters.
1
2
3
4
5
6
7
8
|
for t in range(T):
x_t = sample_new_data()
B_M = sample_replay_buffer(alpha * batch_size)
B = concat_new_and_replay(x_t, B_M)
theta = adamw_update(B, theta)
update_replay_buffer(x_t)
if t % (k * batch_size) == 0:
theta = theta_prev + epsilon * (theta - theta_prev) |
Discussion and Implications
The study demonstrates that experience replay and gradient alignment are synergistic and compute-efficient strategies for CPT in LLMs. Replay enables efficient knowledge retention, outperforming model scaling in terms of compute utilization. Gradient alignment via Reptile meta-updates further enhances both stability and plasticity with minimal overhead. The combined MER approach generalizes well to downstream tasks and scales favorably with model size and task diversity.
Key empirical findings:
- Replay is a more valuable use of compute than increasing model size for knowledge retention.
- MER achieves the lowest forgetting and highest downstream accuracy across scales.
- Moderate replay rates (25%) with MER are optimal for large models.
- Reptile meta-updates provide nearly free gains in stability and plasticity.
Contradictory claim: For large models, increasing replay rate beyond 25% is less efficient than scaling model size, challenging the assumption that more replay always yields better retention.
Future Directions
Further research should explore dynamic adjustment of replay rates and meta-update intervals to optimize the stability-plasticity trade-off. Extending MER to longer and more complex task sequences, incorporating generative replay, and establishing scaling laws for replay and gradient alignment in even larger models are promising avenues. Deeper evaluation of knowledge evolution and multilingual QA during CPT would provide additional insights into factual retention and transfer.
Conclusion
This work establishes experience replay and gradient alignment as complementary, scalable, and compute-efficient techniques for continual pre-training of LLMs. The MER approach enables efficient retention and adaptation across diverse tasks and model scales, with strong empirical evidence supporting its superiority over model scaling and replay-only baselines. The findings have significant implications for resource-efficient LLM maintenance and update strategies, motivating further exploration of continual learning algorithms in foundation model development.

