- The paper demonstrates that LLMimic, a role-based AI literacy intervention, significantly boosts AI literacy and reduces persuasion odds by 42%.
- The paper employs a rigorous 2x3 experimental design across ethical, commercial, and deceptive scenarios to validate the intervention's impact with strong engagement metrics.
- The paper reveals that improved AI literacy does not directly mediate resistance to persuasion, indicating the need for immersive, behaviorally validated digital literacy programs.
Training Users as LLMs: Evaluating the Impact of AI Literacy on Susceptibility to AI-driven Persuasion
Introduction
This paper investigates the impact of AI literacy on resistance to AI-driven persuasion, a topic of growing importance as LLMs permeate sensitive domains such as politics, commerce, and social interactions. Existing evidence demonstrates that LLMs are highly effective in modifying user attitudes and behaviors in both ethical and high-risk contexts, but technical mitigation strategies (e.g., content labeling, detection classifiers) have proven insufficient for robust defense against manipulative AI-generated content. The authors introduce LLMimic, an interactive and gamified AI literacy tutorial simulating the training dynamics of LLMs. Through a human-subjects study, the work aims to establish whether active, experiential engagement with the generative logic of LLMs can inoculate users against subsequent AI persuasion attempts. The study takes a systematic approach, integrating realistic scenarios of AI persuasion (ethical altruistic appeal, malicious financial solicitation, and commercial recommendation) and a validated battery of self-report and behavioral metrics.

Figure 1: Human study flowchart mapping the experimental design including demographic collection, intervention/control, AI literacy assessment, persuasion tasks, and post-task evaluation.
LLMimic and Experimental Design
LLMimic operationalizes a role-based AI literacy intervention by engaging users in the three canonical training phases of LLMs: Pre-training, Supervised Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF). Participants in the treatment condition actively participate in simulated data-driven prediction, Q&A mimicry, and reward model optimization, exposing them to both the mechanical and sociotechnical limitations of LLMs (e.g., exposure bias, hallucination, bias propagation, strategic persuasion). The system is augmented by synthetic demonstration data and real LLM outputs (ChatGPT-4o) to preserve authenticity and ecological validity.
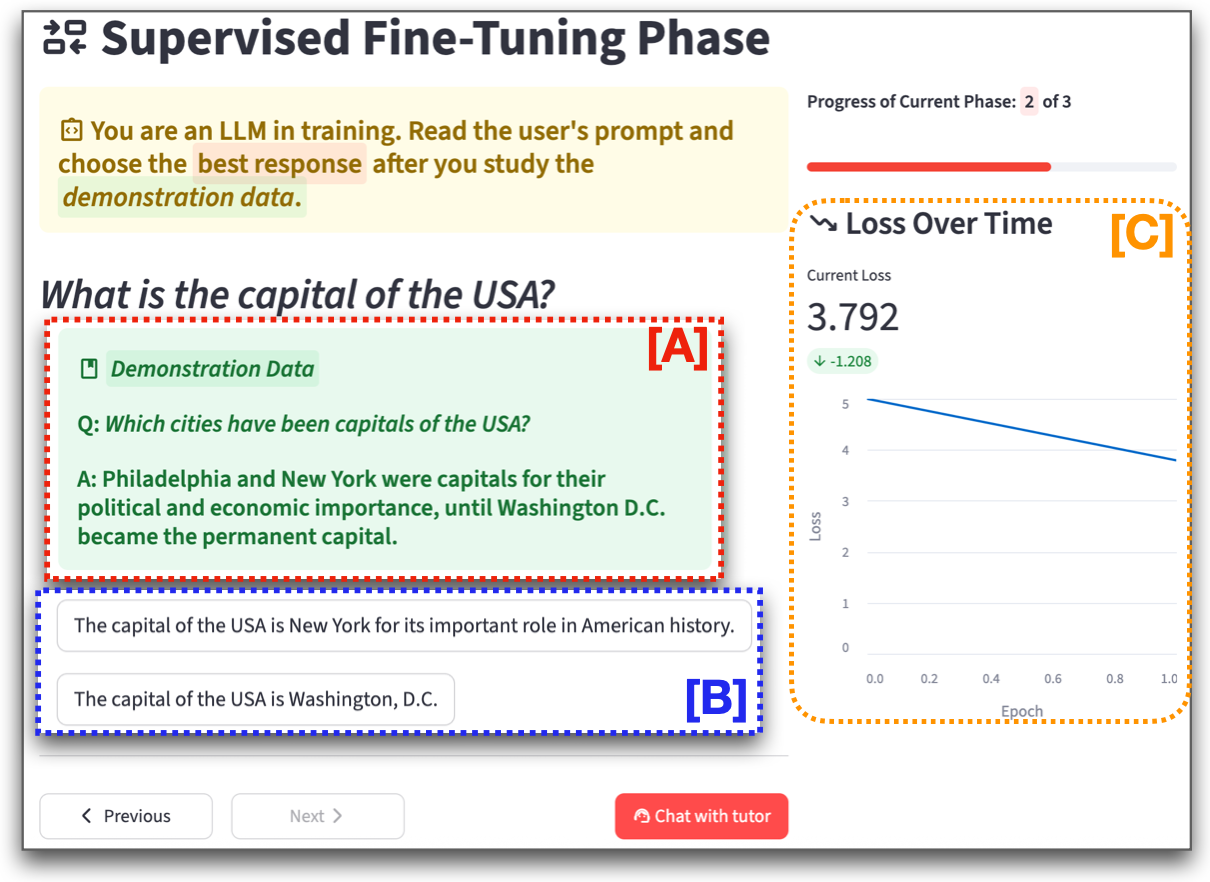
Figure 2: LLMimic interface demonstrating participant engagement in Pre-Training (token prediction), SFT (imitation of demonstration data), and RLHF (reward/feedback-driven selection).
The study employs a 2x3 between-subjects design (intervention vs. control crossed with three persuasion scenarios): "ethical donation," "malicious money elicitation," and "hotel booking." Each scenario is implemented as a multi-turn dialogue with an LLM-powered persuasive agent. The rigorous inclusion of control variables (AI experience, trust, persuasion skills, educational background) and manipulation checks ensures internal validity.
Empirical Results
AI Literacy Gains and Mechanistic Understanding
Post-intervention assessment demonstrates that LLMimic robustly improves self-reported AI literacy (mean increase of 3.78 points on a standardized 7-point scale, p<.001). Notably, salient sub-dimensions reflecting actionable literacy—data literacy, applied AI, programmatic understanding—show the strongest improvements. Engagement metrics (number of attempts/exposure time) support the claim of substantive cognitive participation, not mere passive tutorial completion.
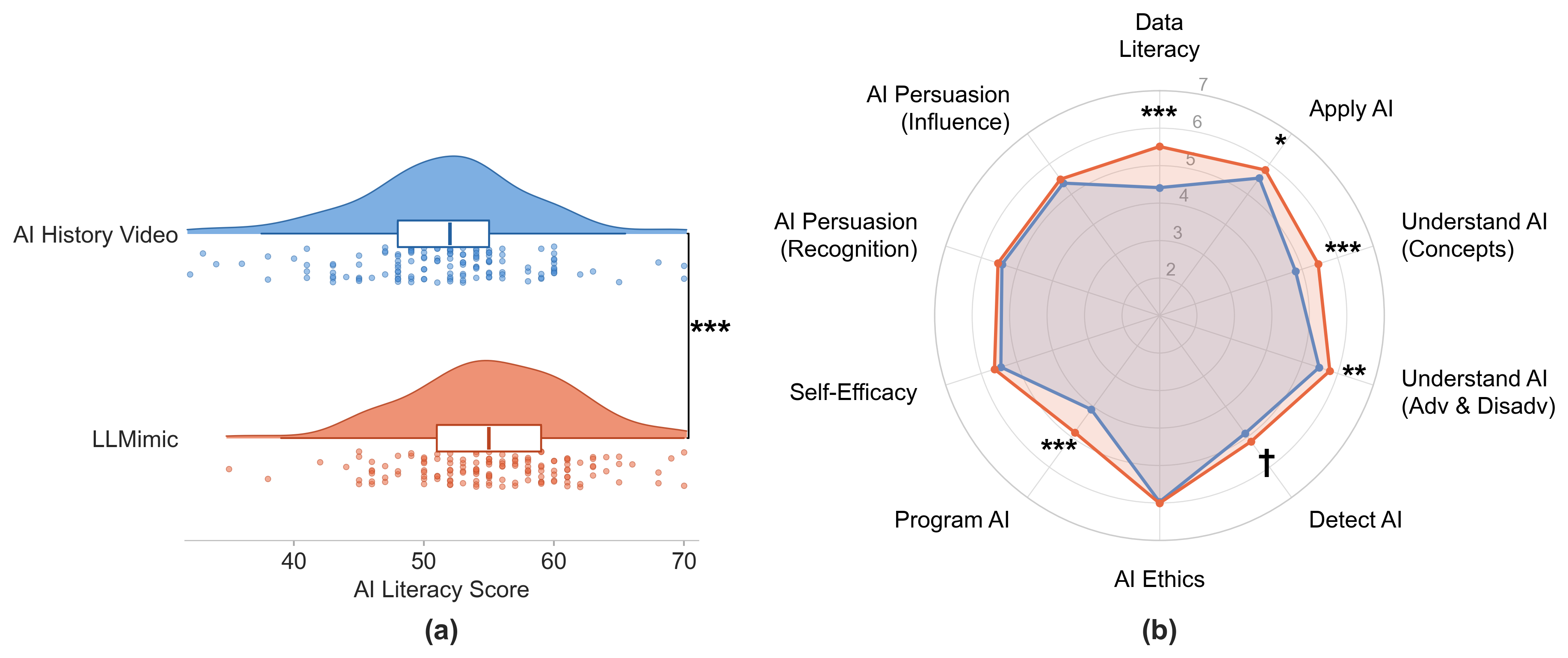
Figure 3: LLMimic induces significant increases in overall and dimension-specific AI literacy relative to the control group, particularly for technically grounded concepts.
Resistance to Persuasive AI
Behavioral outcome data indicate that exposure to LLMimic reduces the odds of successful persuasion by 42% across scenarios (OR = 0.58, p=0.045). This effect is consistent across ethical, commercial, and potentially malicious AI persuasion contexts. The manipulation check confirms enhanced mechanistic understanding—LLMimic participants outperform controls by 17 percentage points in correctly identifying AI content features and potential for bias/manipulation.
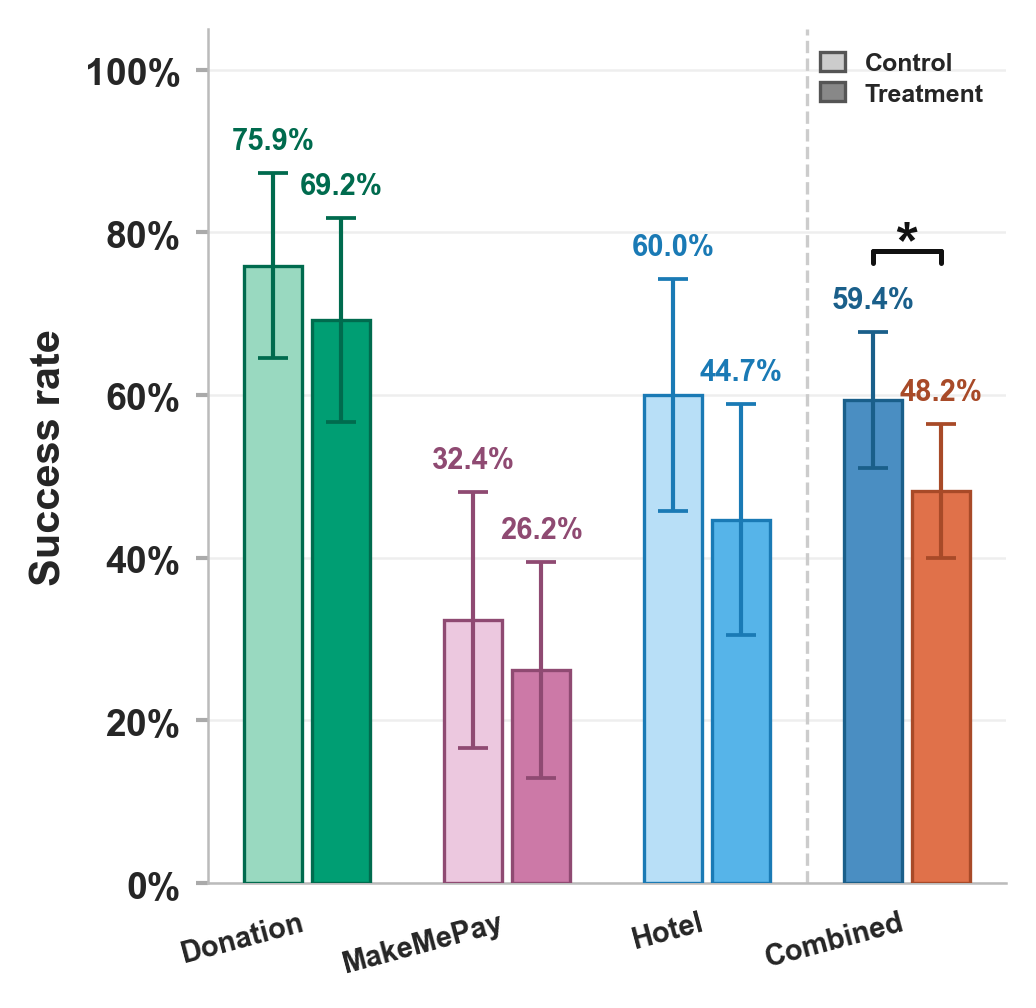
Figure 4: LLMimic exposure reduces persuasion rates across all AI-driven scenarios; statistical modeling confirms significant treatment effects.
Crucially, while LLMimic increases AI literacy and both conditions show decreased post-intervention trust in AI, neither AI literacy nor trust emerges as a significant mediator of the effect on persuasion resistance. Structural equation modeling finds no indirect effects (p>0.90), and neither AI literacy nor trust significantly predicts behavioral susceptibility when controlling for confounds.
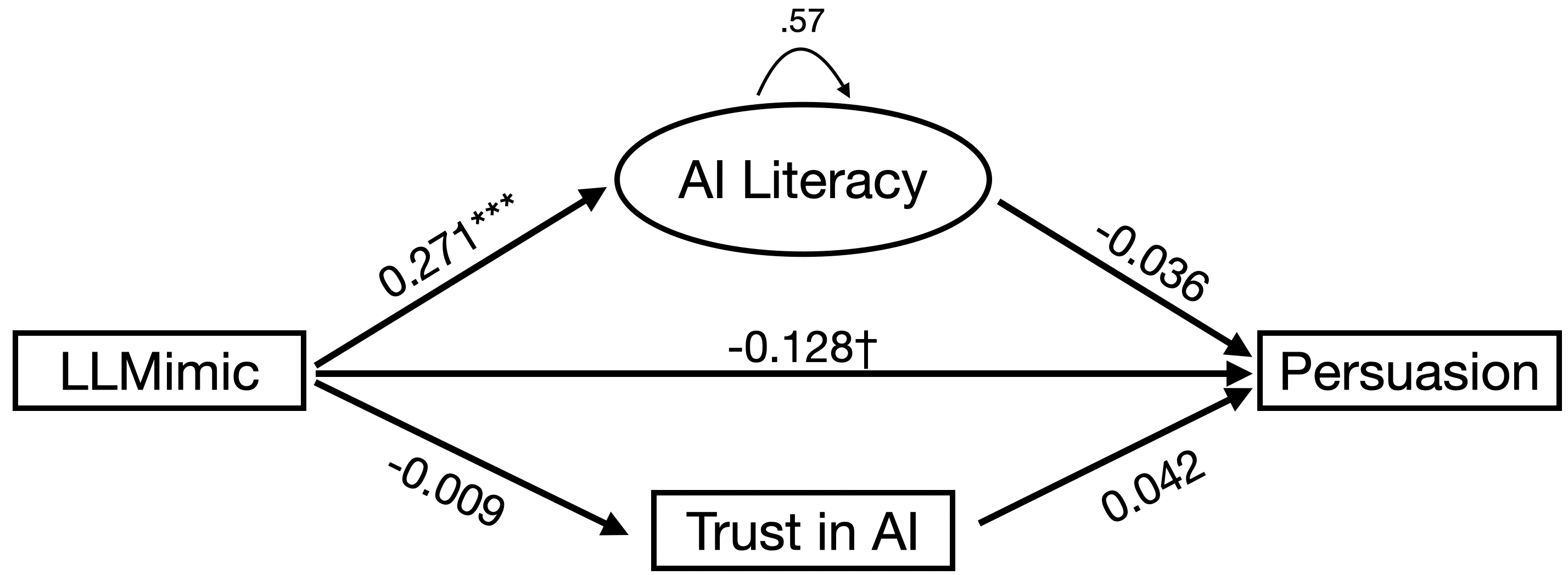
Figure 5: Mediation pathways indicate LLMimic improves AI literacy, but this does not translate to reduced persuasion success via literacy or trust—total effects remain.
Perceived Ethics: TARES Scale Application
Application of the TARES framework to agent evaluation validates the tool's sensitivity: agents in ethical donation scenarios are perceived as significantly more ethical than those in deception-adjacent money elicitation. This demonstrates user capacity for fine-grained, scenario-specific ethical judgment regarding AI-driven persuasion.
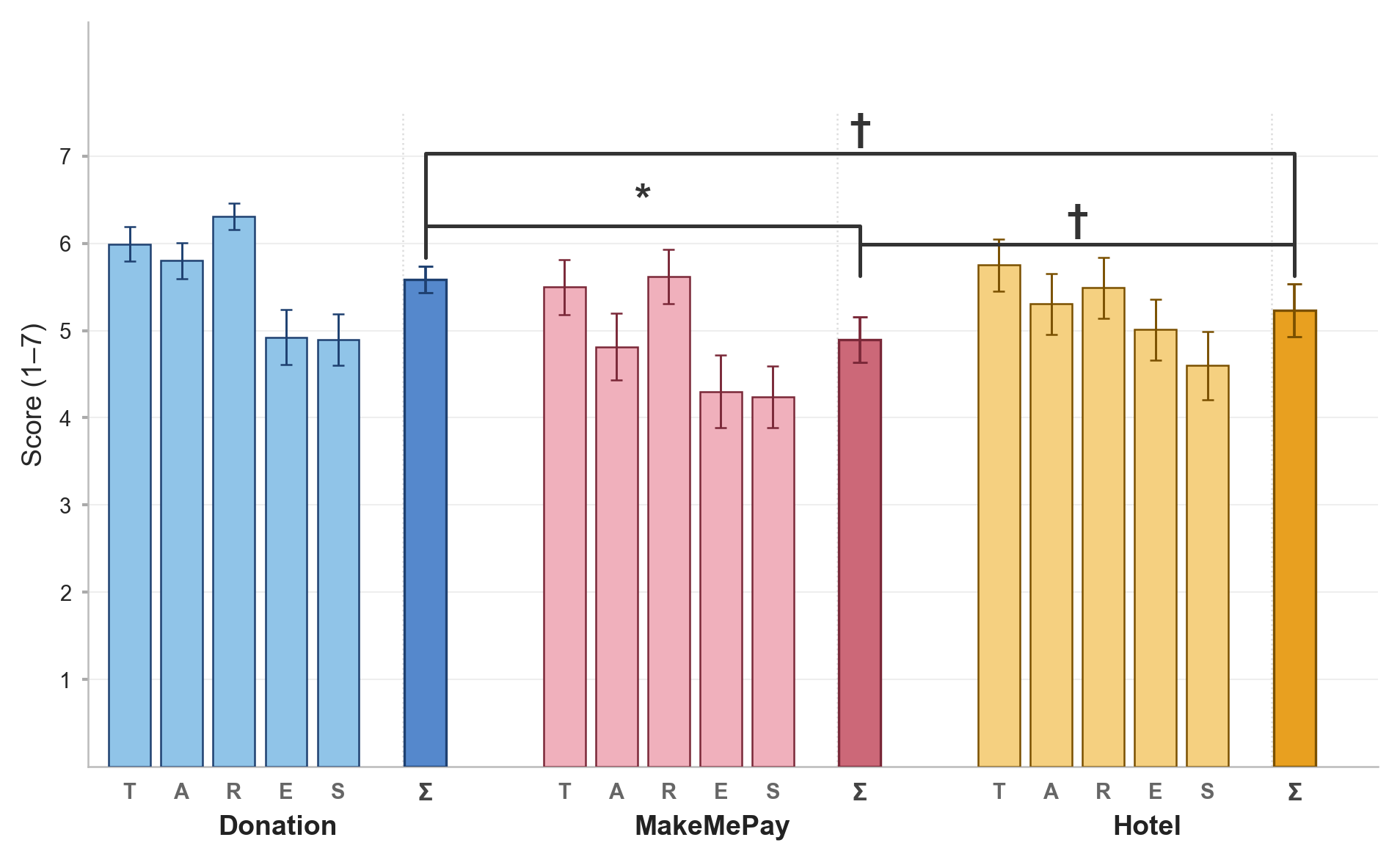
Figure 6: TARES-derived ethicality scores are scenario-dependent; donation agents are rated as significantly more ethical compared to manipulative agents.
Implications and Future Directions
The primary empirical claim—that experiential, role-based AI literacy interventions confer quantifiable resistance to sophisticated AI persuasion—holds across diverse scenarios. This provides converging evidence for the applicability of inoculation theory in the LLM era, with direct design implications for user-facing AI safety strategies. Importantly, the absence of mediation by self-reported literacy or trust calls attention to the limitation of knowledge-based metrics for predicting behavioral resilience. Instead, results suggest a need for longitudinal, context-adaptive literacy programs and behavioral assessment frameworks that account for the complex interplay between critical awareness and real-world decision making.
Pragmatically, the findings point toward the deployment of interactive transparency mechanisms (e.g., user-simulated model audits, scenario-based curricula) as a viable complement to purely technical detection/classification pipelines. The nuance in user autonomy, scenario-specific ethicality, and practical trade-offs further underscores the necessity for multi-dimensional evaluation benchmarks (e.g., TARES, scenario contextualization) in future AI literacy and AI safety research. The lack of a significant effect for increased trust calibration also suggests the need for precision measures that differentiate between global distrust and contextually justified, epistemically sound caution.
Open research directions include the refinement of cognitive and behavioral measures for AI literacy (beyond self-report), scalable deployment of experiential literacy tools, and integration into real-world digital literacy ecosystems. Additionally, further investigation into the boundary conditions for literacy-based resistance (e.g., prolonged intervention effects, transfer across domains, demographic interaction effects) and the interplay between transparency, ethical framing, and persuasion outcomes are warranted.
Conclusion
LLMimic provides empirically supported evidence that active, role-based AI literacy interventions can measurably reduce user susceptibility to AI-driven persuasion in realistic, multisectoral contexts. However, the mechanism is not fully captured by declarative literacy or trust scores, indicating more complex cognitive-behavioral pathways underlie resistance. The validated use of the TARES scale for scenario-anchored ethical evaluation further broadens the methodological toolkit for future AI persuasion studies. The implications extend to human-centered AI defense, transparent system design, and policy-oriented educational innovation, with the caveat that literacy interventions must be immersive, contextually situated, and designed for behavioral outcomes to achieve robust mitigation in the face of increasingly persuasive AI systems.

