- The paper demonstrates that a short AI literacy intervention significantly improves students' regulation of LLM interactions during science problem-solving.
- The intervention enhances prompt discrimination and encourages strategic follow-up actions, leading to improved rubric-based performance scores.
- The study reveals that behavioral metrics, rather than self-report measures, effectively capture the impact of AI literacy on regulatory practices.
Study Design and Context
The paper investigates the efficacy of a brief, classroom-feasible AI literacy intervention targeting middle school students as they interact with LLMs during science inquiry tasks. Prior work highlights risks in uncritical acceptance of GenAI outputs, especially among adolescents, due to incomplete metacognitive monitoring and regulation. The intervention in this study combines foundational LLM concepts with procedural heuristics for querying and evaluating chatbot outputs, aiming to improve interaction strategies and, by extension, final task performance.
A controlled design (N = 116, grades 8–9) splits students into intervention and control groups. The intervention group receives a two-hour AI literacy workshop two days before engaging in six science exercises with LLM support. The study’s behavioral metrics include prompt acceptance/replacement, follow-up question behavior, and correctness judgments, capturing regulatory interaction dynamics. Performance is assessed via rubric-based scoring of final answers.
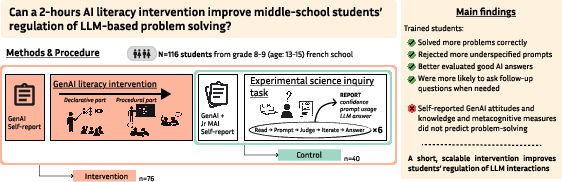
Figure 1: Study overview, depicting group assignments, the AI literacy intervention, and main outcome variables. Intervention students show improved performance and more sophisticated regulation in LLM interactions.
LLM Interaction Paradigm
The experimental workflow systematically assesses students’ interaction with LLMs. Each exercise presents a suggested prompt (either well-specified or intentionally underspecified) to seed chatbot interactions, simulating realistic scenarios where initial queries may be suboptimal. Students choose to accept or replace the prompt, submit their query, optionally ask follow-up questions, and ultimately compose a final answer. The design enables precise measurement of regulation strategies at both the prompt and response phases.

Figure 2: Task structure highlighting the student-LLM interaction loop, evaluation checkpoints, and manipulation of prompt specificity to probe regulatory behavior.
Trained students outperformed controls on the aggregate task performance metric (M=11.38 vs. 10.29 out of 20, U=1871, p=0.040, r=0.19), demonstrating that even minimal AI literacy instruction enhances solution quality in GenAI-assisted inquiry. Analyses reveal that the core advance arises not from generalized gains in LLM discrimination ability but from strategic, context-sensitive regulation: students in the intervention group were more discerning in prompt acceptance, less likely to adopt underspecified prompts, and more adept at reparative actions when prompt quality was suboptimal.
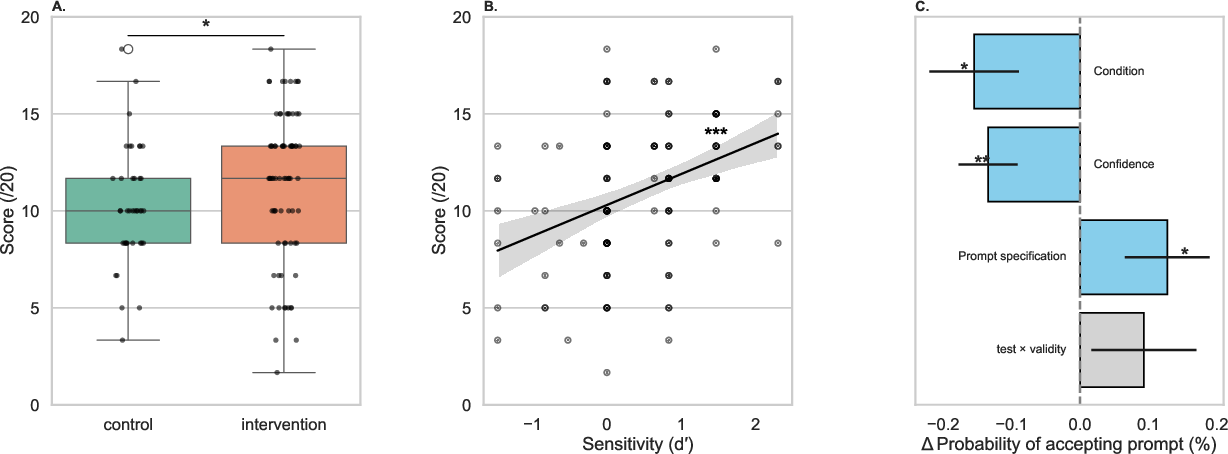
Figure 3: (A) Performance improvement in the intervention group; (B) Strong association between prompt discrimination (d') and task performance; (C) Predictors of prompt acceptance, with trained students rejecting more underspecified prompts.
Sensitivity (d') and conservative response bias (β) both predict performance, but the intervention’s effect primarily manifests in enhanced regulatory actions when prompt inadequacy is detected. Trained students exhibited increased agency, evidenced by effective rejection and replacement of both underspecified and well-specified prompts without incurring performance penalties. This indicates procedural transfer of regulation heuristics beyond mere rote technique adoption.
Output Evaluation and Follow-Up Strategies
Robust regulation is not limited to the prompt phase but extends to the evaluation of AI outputs. Trained students exhibit improved accuracy in correctness judgments (especially following well-specified prompts) and display a higher propensity to issue follow-up queries after receiving insufficient answers, particularly when starting from an underspecified prompt. These behaviors are tightly linked to improved performance, suggesting that the intervention effectively operationalizes monitoring-to-control cycles in LLM-augmented inquiry.
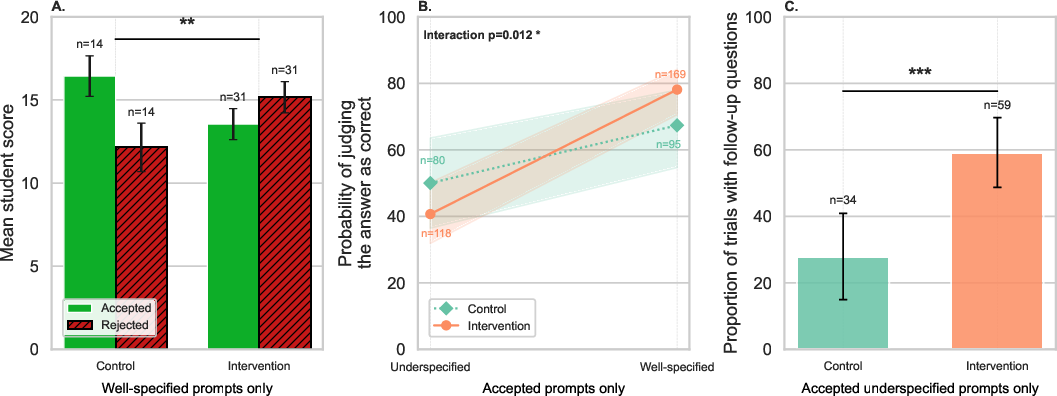
Figure 4: (A) Within-student performance by prompt replacement strategy; (B) Improved correctness judgment accuracy for trained students; (C) Increased follow-up querying after inadequate AI responses in the intervention group.
Notably, students in the intervention arm gain approximately 5/20 additional points from appropriating follow-up question strategies—an effect absent in controls. This highlights that the intervention fosters actionable regulatory routines, not only awareness.
Null Results from Self-Report Measures
Self-reported GenAI literacy and metacognitive awareness do not correlate with performance. The workshop produces no significant shift in self-report dimensions (MANOVA, p=.247), nor do such measures predict regulatory behaviors or exercise outcomes. This exposes a dissociation between perceived competence and effective regulatory action, particularly salient in adolescent populations, and underscores the necessity of behavioral/process measures over self-assessment for evaluating intervention efficacy.
Theoretical and Practical Implications
The findings validate that short, scalable AI literacy interventions can produce measurable, process-level improvements in LLM-assisted learning, targeting not only knowledge transfer but dynamic regulation strategies crucial for productive GenAI use. The demonstration that regulatory heuristics—rather than platform-specific prompt engineering—drive performance gains is significant for curriculum developers aiming for generalizability and transfer.
The result is consistent with accounts emphasizing monitoring-control loops in digital tool use, implicating explicit instruction in heuristics for when and how to intervene (as opposed to solely foundational AI knowledge) as the primary driver of robust human-AI co-regulation in educational contexts. That self-reported competence is non-predictive also has implications for how AI literacy is assessed: process-level measurement during engagement, rather than post-hoc survey, is necessary for valid evaluation.
Longitudinal scope, transfer across domains, and broader contextual validation remain open questions. The single-site, short-term context constitutes a limitation in generalizability and durability estimation. Future directions should explore repeated interventions, adaptation for other inquiry modalities (beyond STEM), fine-grained linguistic analyses of reformulation/repair strategies, and the influence of additional LLM system variability on student regulatory trajectories.
Conclusion
This study establishes that minimal, focused AI literacy instruction based on conceptual and procedural principles can significantly improve regulatory behavior and final performance in LLM-supported science tasks for middle school students. Performance benefits are rooted in increased interactive regulation—prompt discrimination, judicious rejection of low-quality prompts, accurate output evaluation, and strategic follow-up—which standard self-report measures fail to capture. The practical implication is clear: effective GenAI use requires explicit instructional support for interaction regulation, and intervention efficacy must be measured through behavioral engagement metrics. This paradigm can inform scalable AI literacy curricula and supports further exploration of regulatory scaffolding in broader and more diverse educational environments.

