- The paper introduces ADR which uses trainable encoder adaptation, Hierarchical Analytic Merging (HAM), and Analytic Classifier Reconstruction (ACR) to resist feature drift.
- It achieves near joint-training performance on several benchmarks while maintaining privacy and increased model plasticity compared to frozen-encoder approaches.
- Empirical evaluations and ablation studies validate ADR’s theoretical guarantees and highlight its potential in sensitive applications like recommendation and medical informatics.
Analytic Drift Resister (ADR) for Non-Exemplar Continual Graph Learning: A Technical Analysis
Introduction and Motivation
Continual graph learning in non-exemplar settings aims to overcome catastrophic forgetting without relying on storage of raw examples, thereby ensuring privacy. Traditional methods using rehearsal (e.g., experience replay) are infeasible under privacy constraints, prompting the adoption of class-level prototypes or analytic continual learning (ACL) with frozen pre-trained encoders. However, prototype-based NECGL methods suffer from feature drift due to the mismatch between stored prototypes and the updated feature space after model adaptation. ACL variants, designed to eliminate drift via parameter freezing, experience a substantial loss of plasticity and are prone to underfitting when faced with large domain and distribution shifts across graph tasks.
The proposed Analytic Drift Resister (ADR) advances NECGL by simultaneously addressing plasticity loss and feature drift—without sacrificing privacy. ADR introduces trainable encoder adaptation, an analytic model merging method (Hierarchical Analytic Merging, HAM), and closed-form classifier reconstruction (Analytic Classifier Reconstruction, ACR). This framework yields theoretically guaranteed resistance to feature drift and achieves high empirical performance, closely approximating joint training in a privacy-preserving paradigm.
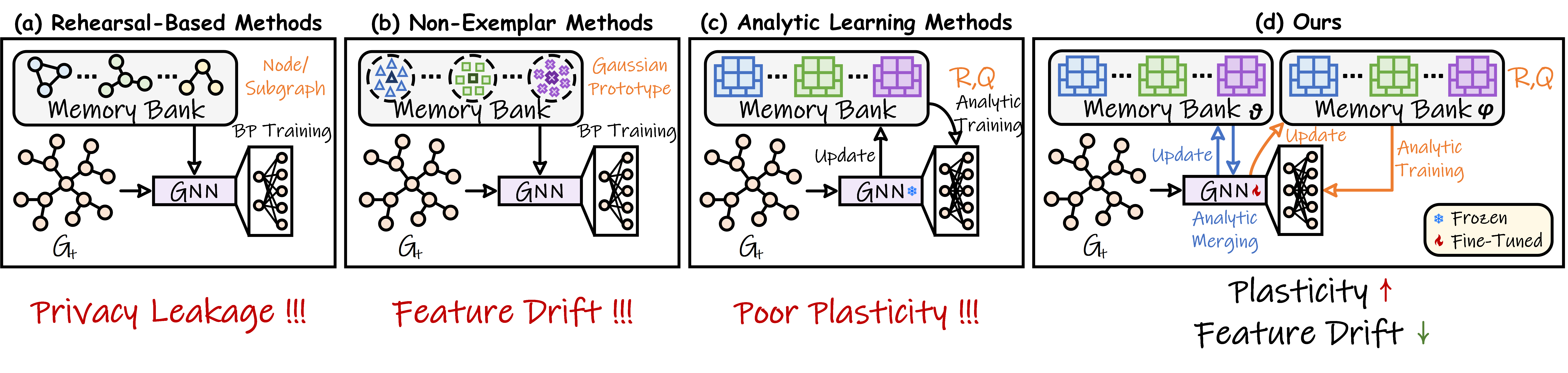
Figure 1: A schematic overview of different Continual Graph Learning paradigms.
Methodological Framework
ADR operates in three primary stages: incremental task adaptation, hierarchical analytic merging, and analytic classifier reconstruction.
Incremental Task Adaptation
Unlike traditional ACL strategies, ADR unfreezes the encoder, permitting parameter updates through backpropagation on new tasks. This increases model plasticity and enables effective adaptation to evolving graph distributions encountered in the task stream. The adaptation stage applies standard cross-entropy loss, without distillation-based regularization, allowing maximal flexibility. The challenge, however, is that such updates induce feature drift by misaligning previously cached feature statistics with the new representation space.
Hierarchical Analytic Merging (HAM)
To neutralize feature drift, ADR deploys HAM, which performs parameter consolidation by analytically merging all historical task encoders. For each GNN layer, linear weights across the sequence of task-adapted encoders are merged through a closed-form ridge regression solution, ensuring the merged encoder's representations are consistent with those of previous task-specific encoders.
Specifically, for any layer, HAM solves
WM∗=argWmini=0∑t∥Hi,k−H^i,kW∥F2+γ∥W∥F2,
enabling parameter merging with only occupation statistics (autocorrelation and cross-correlation matrices; no raw features). This construction is mathematically equivalent to a joint training objective, ensuring absolute resistance to feature drift.
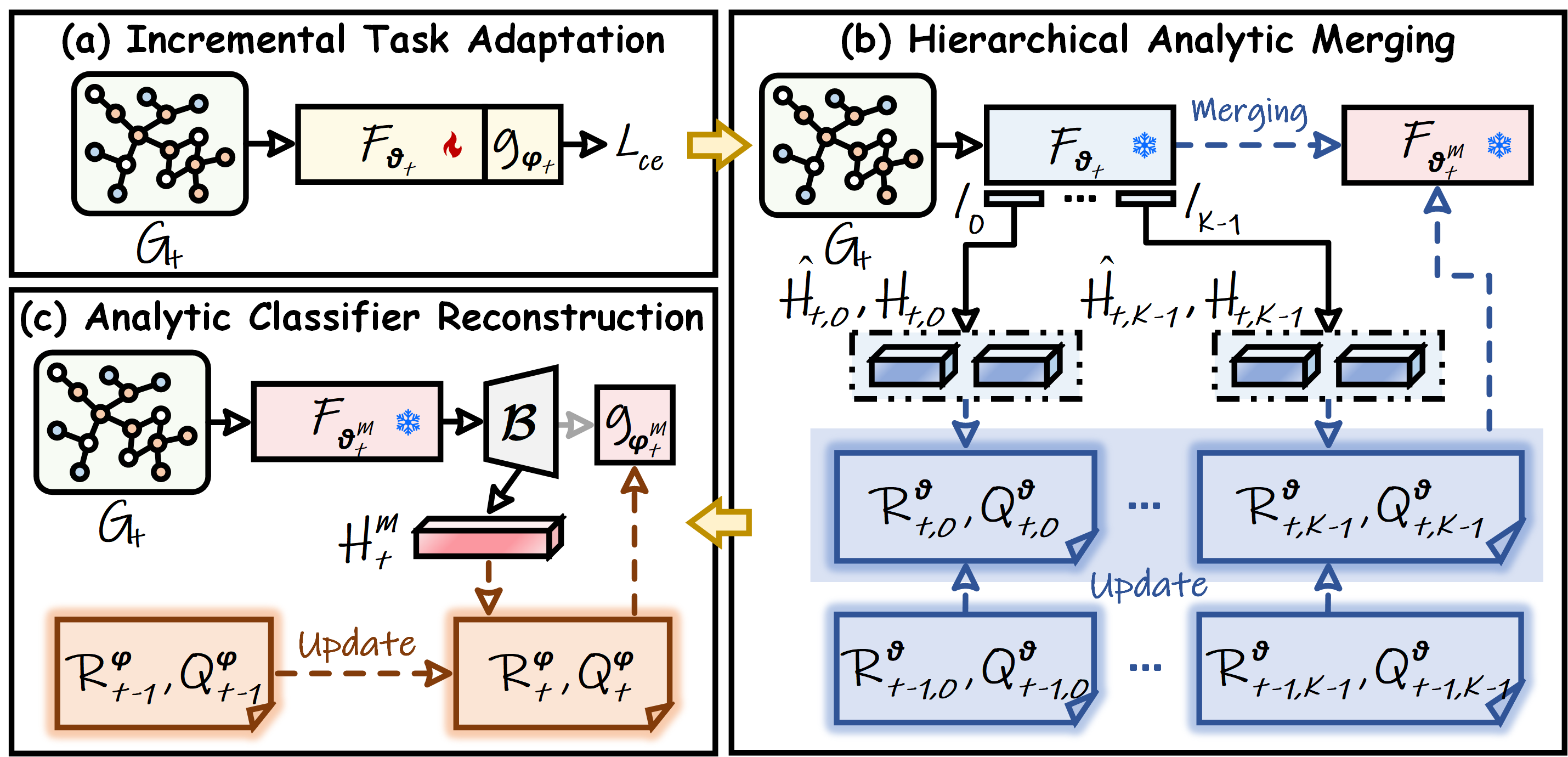
Figure 2: The overall pipeline of the proposed ADR. (a) The model adapts freely via BP. (b) HAM merges encoders analytically. (c) ACR reconstructs the classifier.
Analytic Classifier Reconstruction (ACR)
Given the merged encoder, the final classification layer is reconstructed analytically, solving a series of ridge regression problems on the node embeddings produced by the unified encoder. ACR can also leverage random feature expansion and nonlinearity to increase separability, following Cover's theorem. Closed-form updates guarantee that no information from previous raw data is required, and the solution remains consistent with the latent space, eliminating catastrophic forgetting.
Empirical Analysis
ADR is evaluated against a comprehensive suite of state-of-the-art regularization-based, rehearsal-based, Non-Exemplar, and analytic continual learning baselines across four node-classification benchmarks: CS-CL, CoraFull-CL, Arxiv-CL, and Reddit-CL.
ADR consistently delivers near-joint performance while strictly adhering to privacy constraints. On CS-CL and Reddit-CL, ADR establishes new SOTA average and final accuracy metrics (Aavg and Af), outperforming both rehearsal-based and traditional NECGL alternatives. On CoraFull-CL, ADR achieves substantial improvements over all baselines except for slightly lagging behind ACIL/DS-AL on Arxiv-CL due to extreme class imbalance, which disproportionately influences its model merging step due to both encoder and classifier adaptation.
Model Plasticity and Theoretical Forgetting
ADR achieves markedly higher plasticity compared to frozen-encoder ACL methods, as illustrated by the learning accuracy analysis.
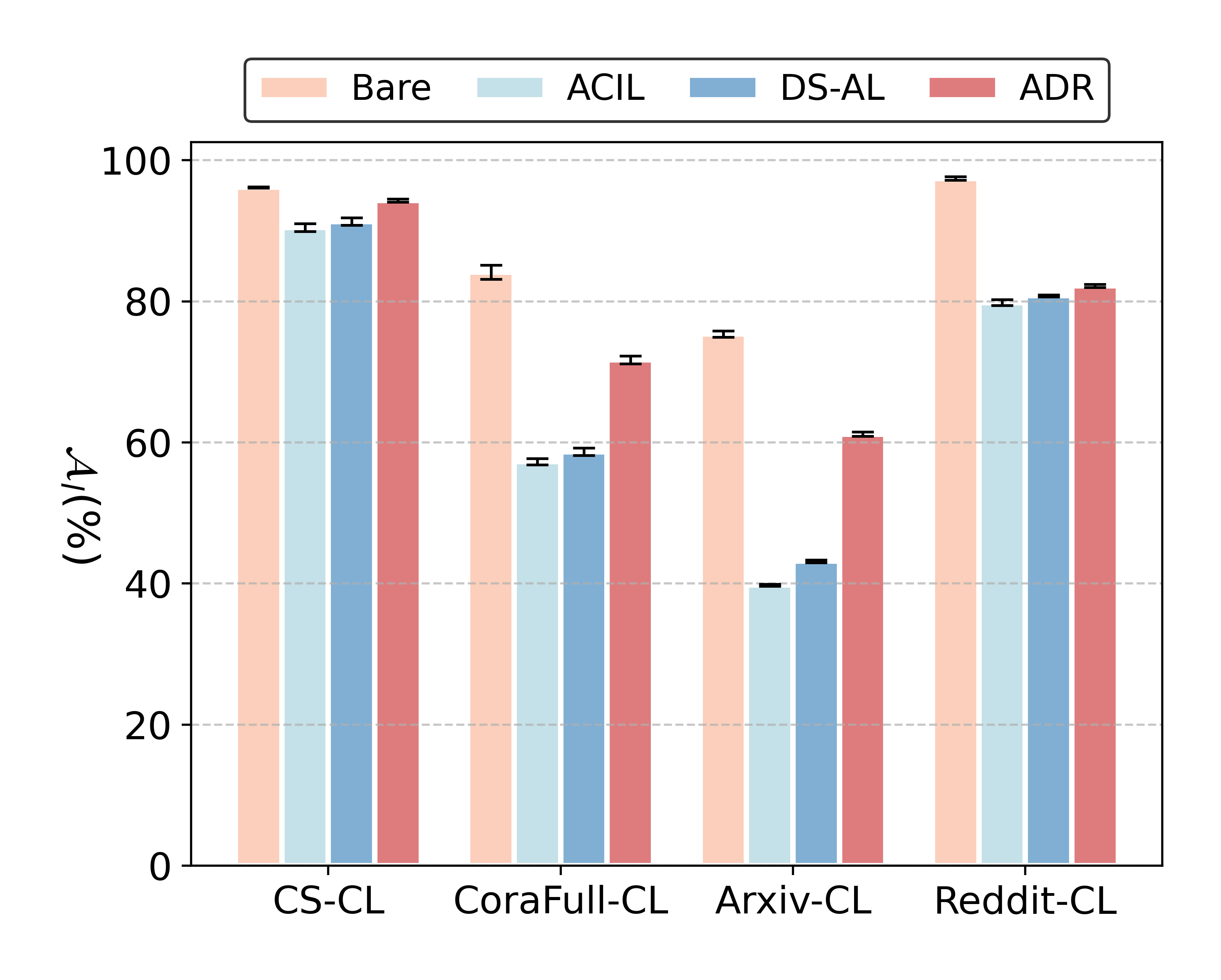
Figure 3: Model plasticity comparison of ADR versus existing ACL methods across four benchmarks.
The feature drift resistance of ADR is visually confirmed through embedding distributions on representative tasks. In contrast to both prototype-based and unfrozen ACL approaches, ADR preserves latent manifold consistency across time, providing empirical evidence for the absolute resistance to feature drift as derived analytically.
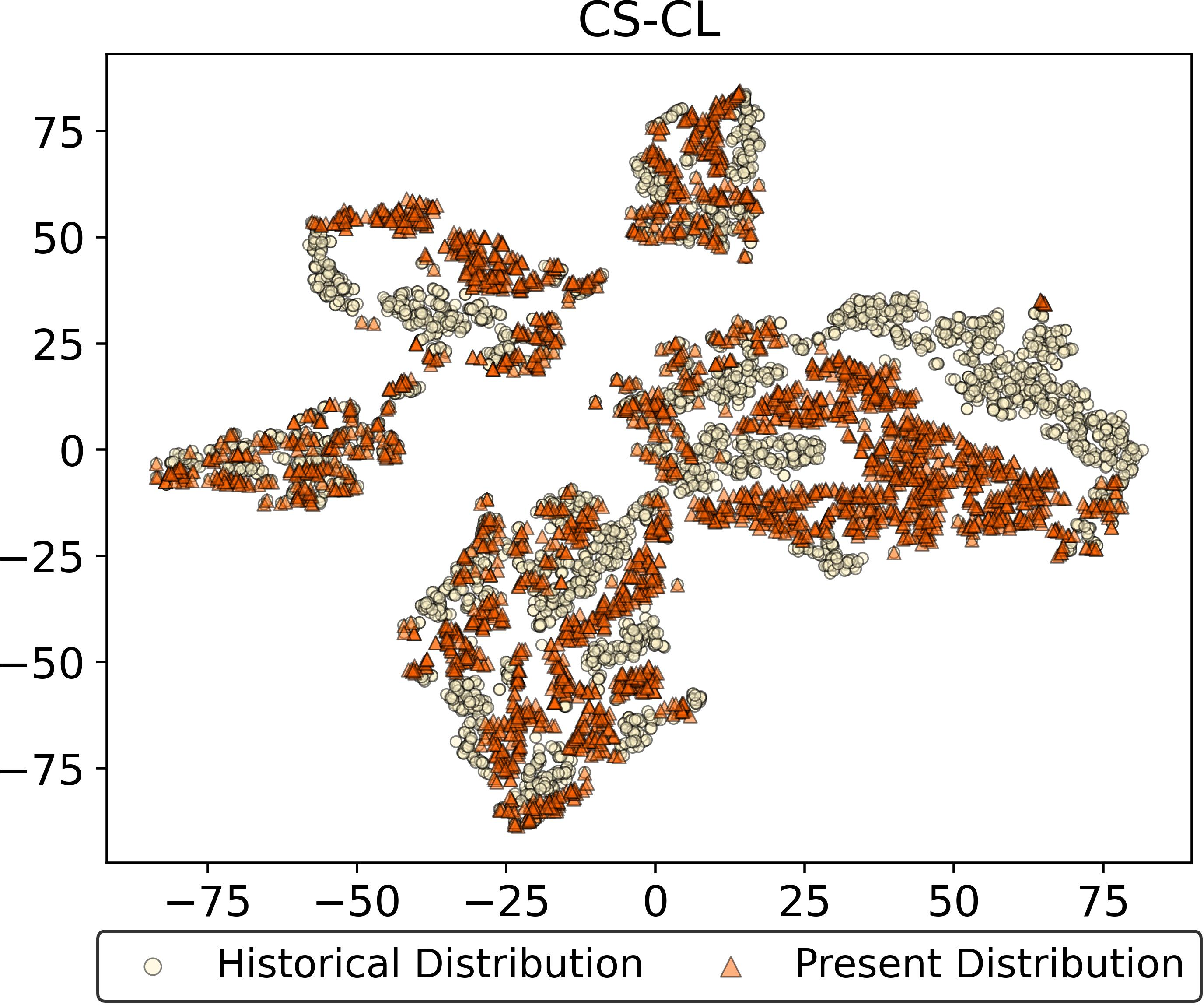
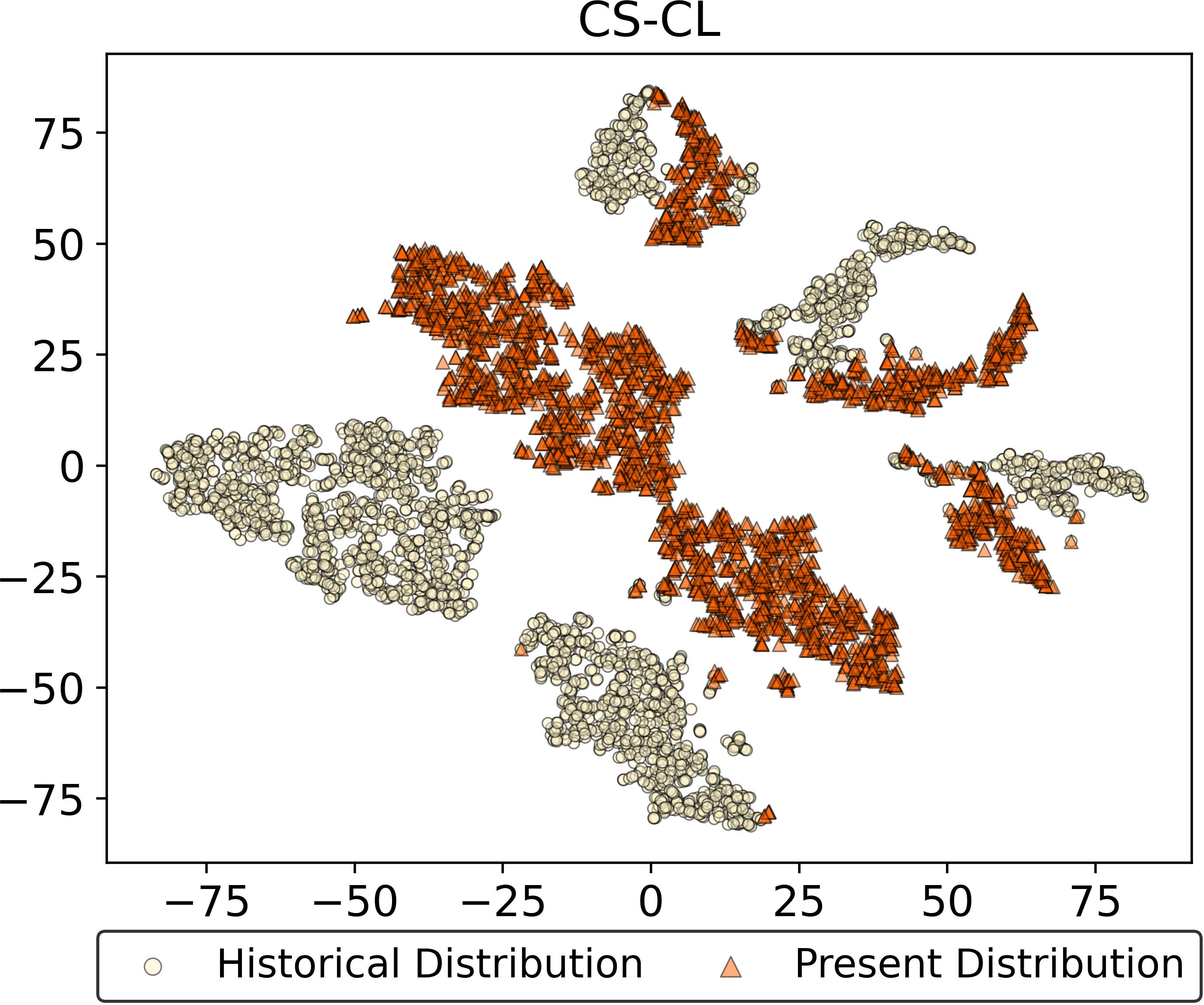
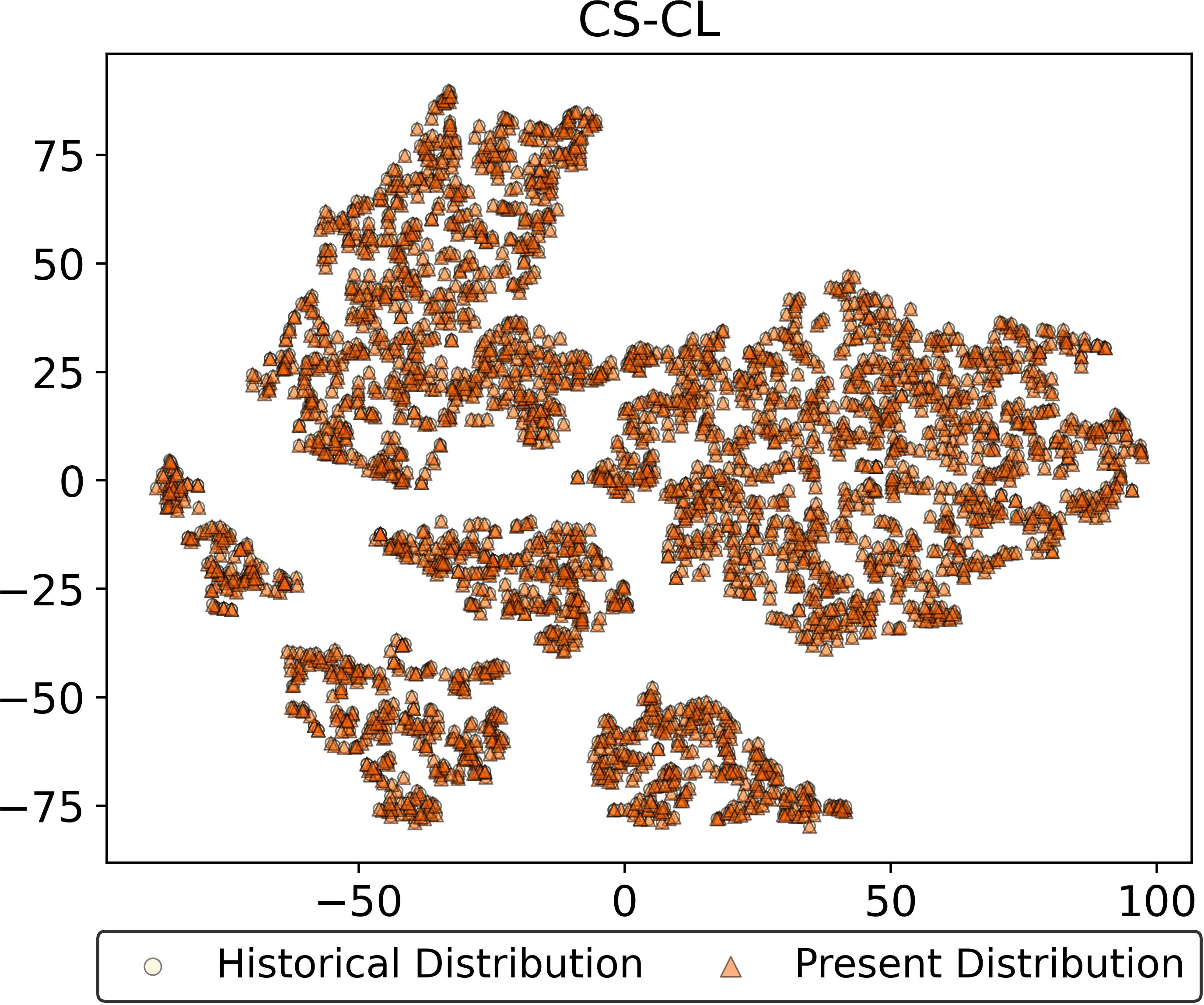
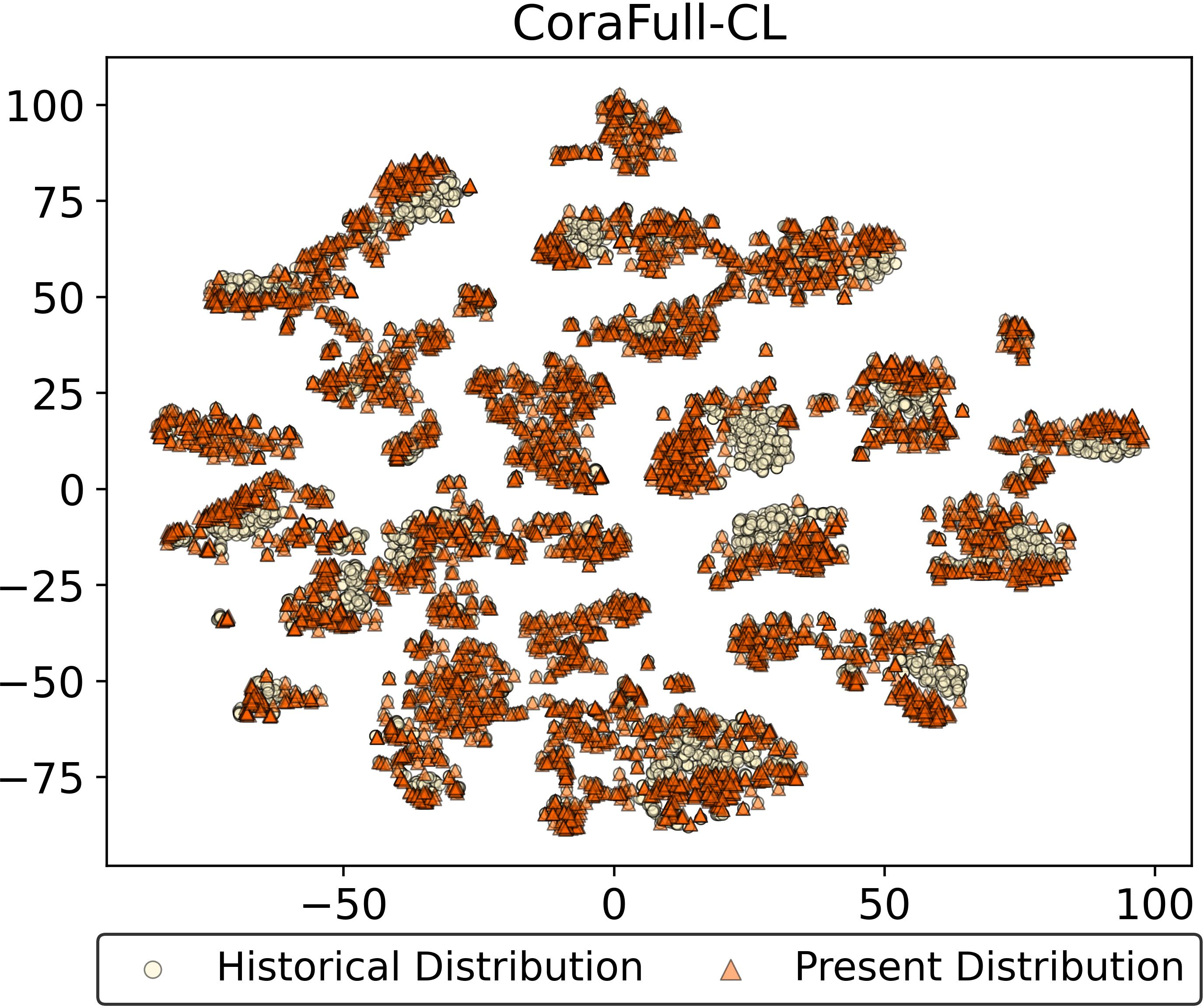
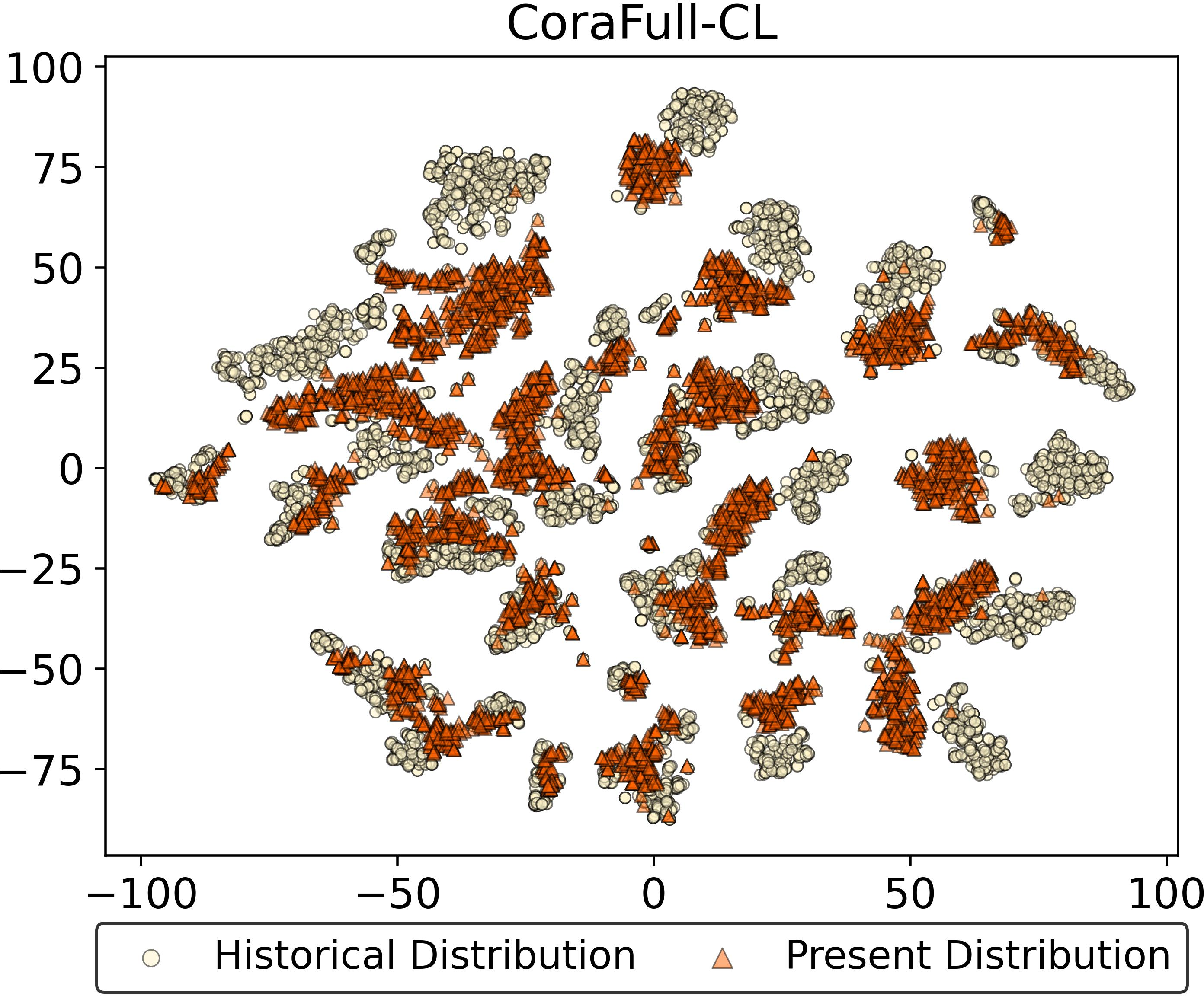
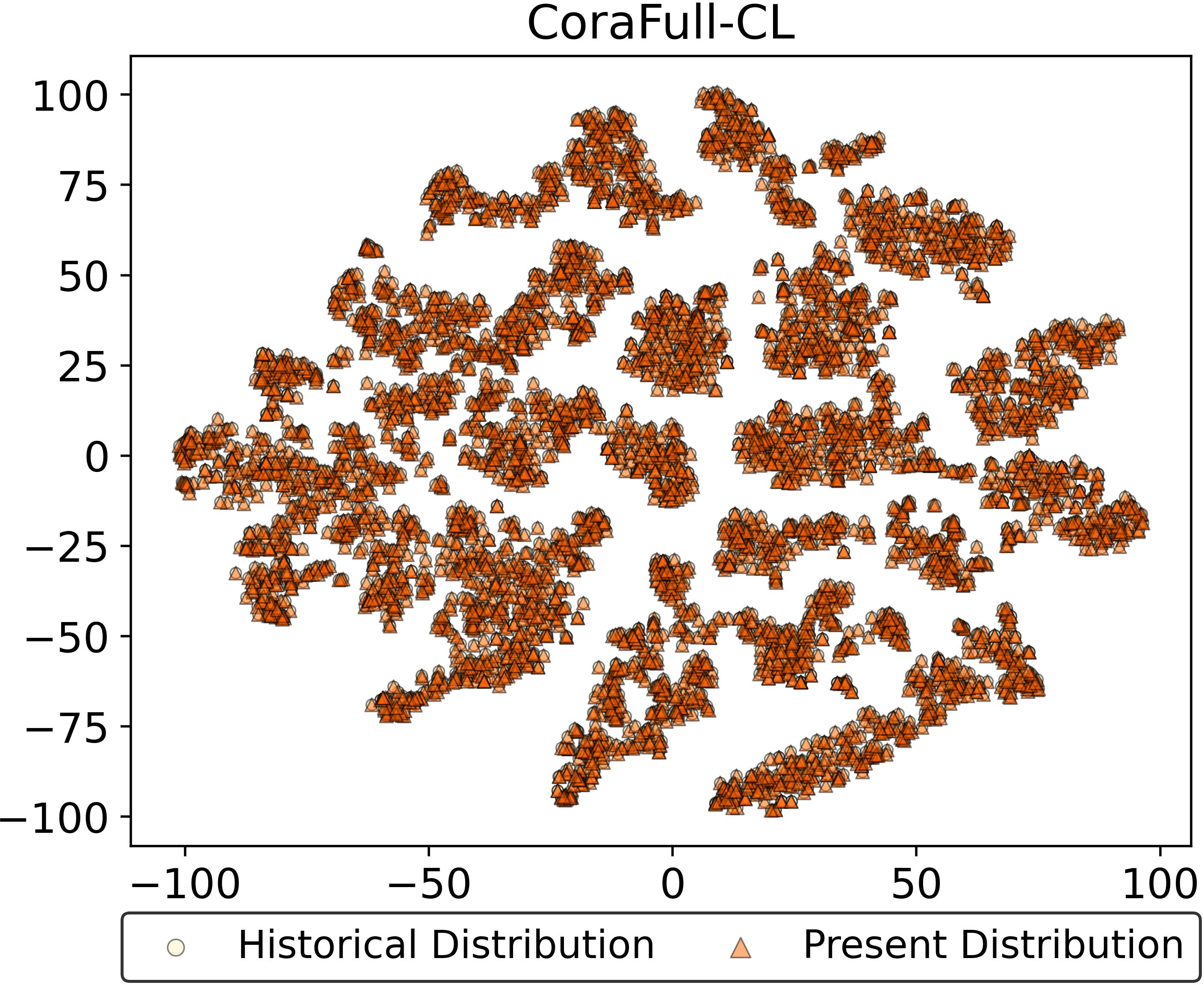
Figure 4: Feature drift visualization—ADR maintains embedding alignment after multiple tasks, unlike EFC and DPCR.
Ablation and Merging Strategy Evaluation
Ablation studies demonstrate that substituting HAM with alternative model merging techniques (e.g., simple averaging, Fisher-based, or MAGMAX) results in significant performance degradation, underlining the necessity of the analytic merging property for true drift resistance. Removing HAM altogether leads to catastrophic forgetting, highlighting the unique theoretical role of layerwise analytic merging.
Hyperparameter Sensitivity
ADR's effectiveness scales with the feature expansion factor (α) and regularization weight (γ), with trends varying by dataset characteristics. Denser and larger graphs benefit from increased feature expansion, while ill-conditioned settings (e.g., extreme class imbalance) may require careful regularization tuning.
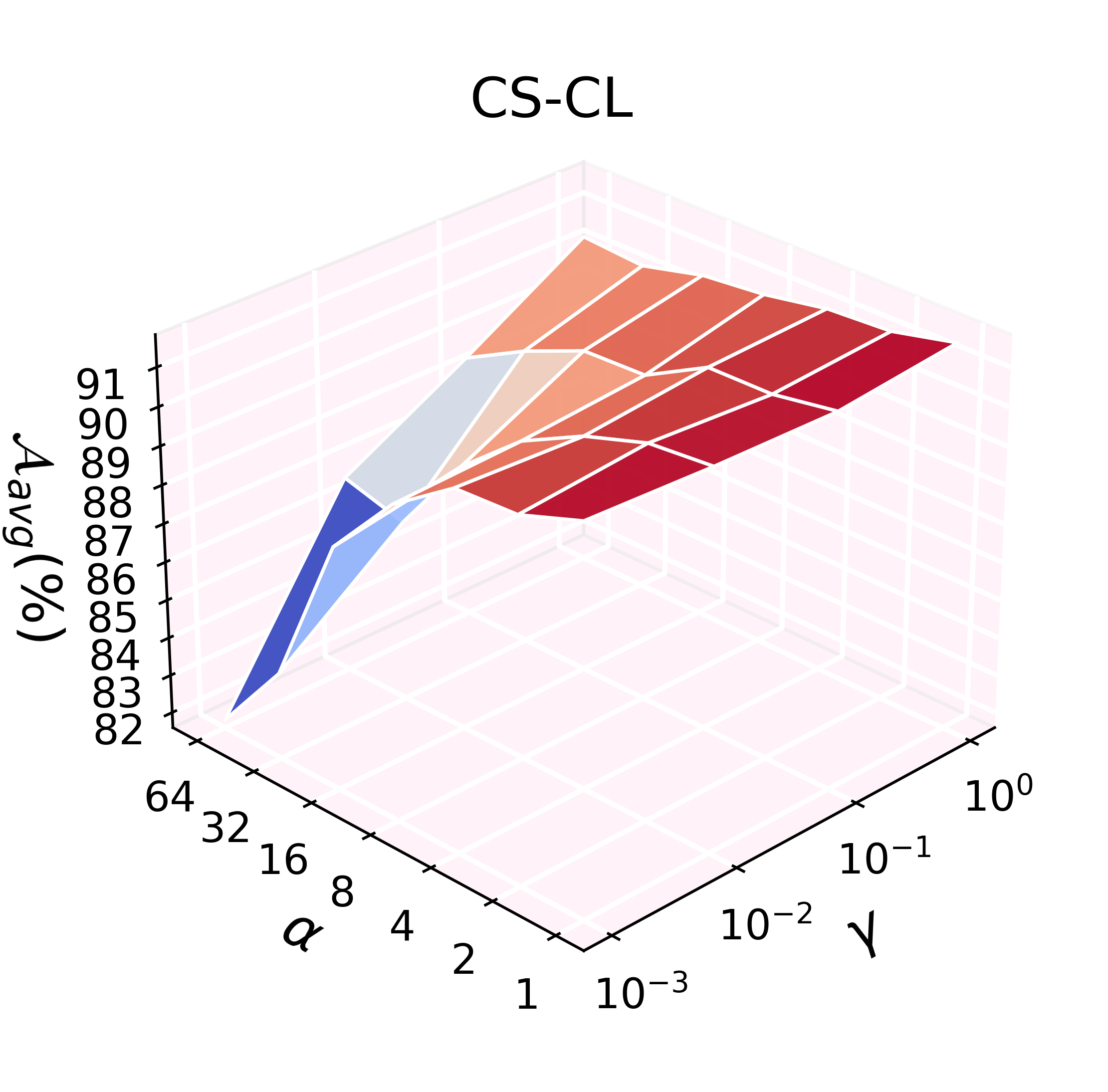
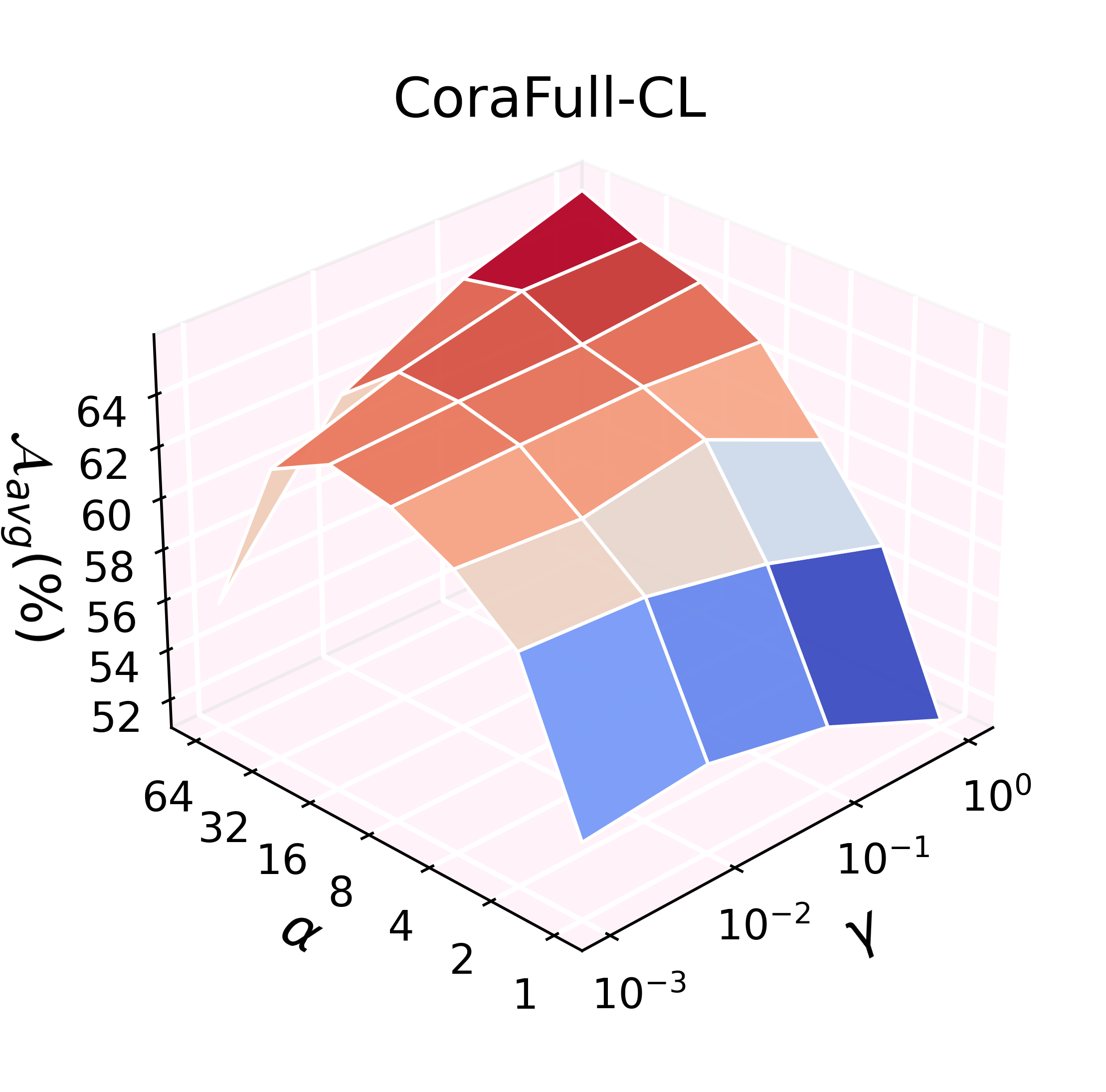
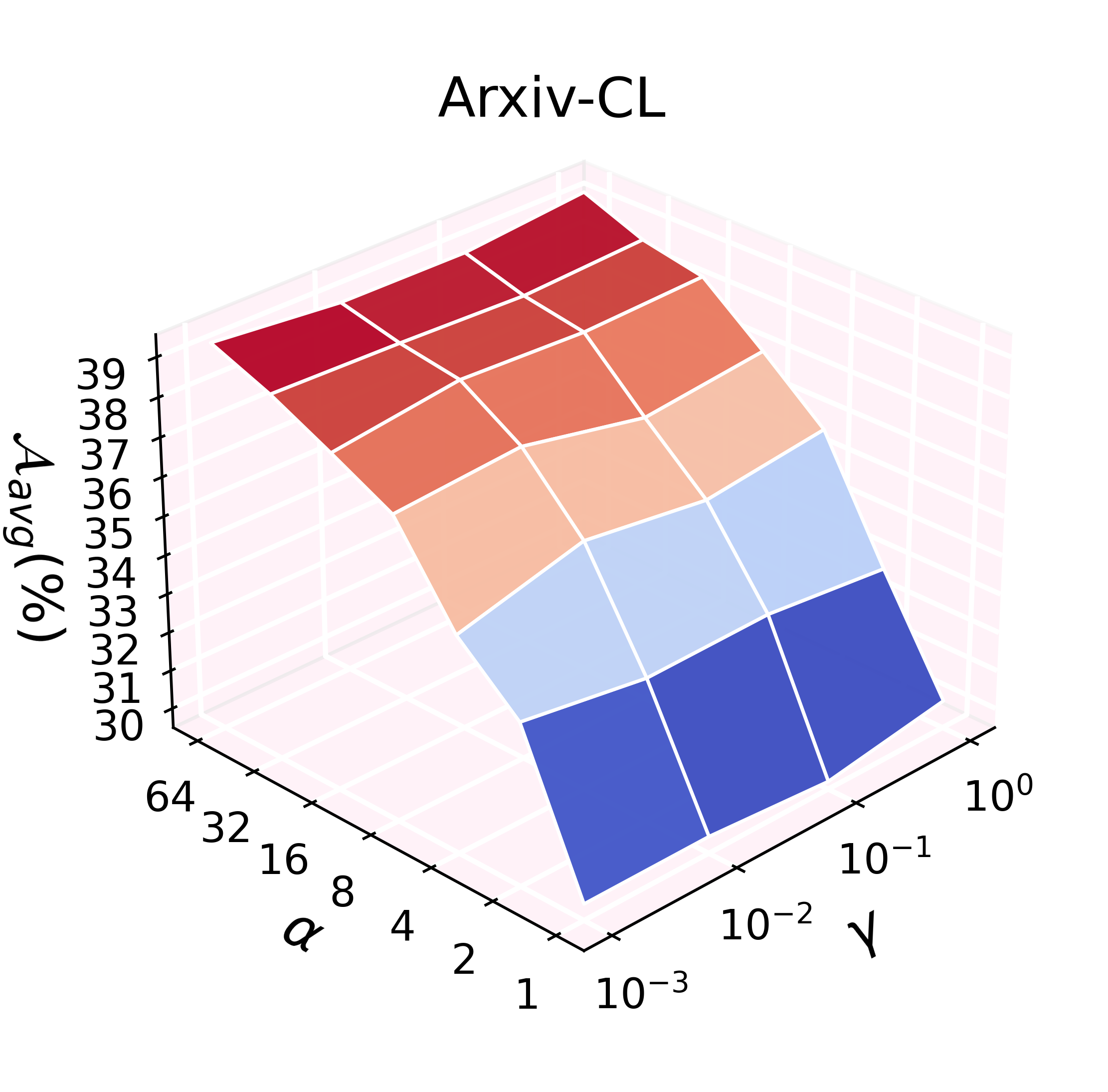
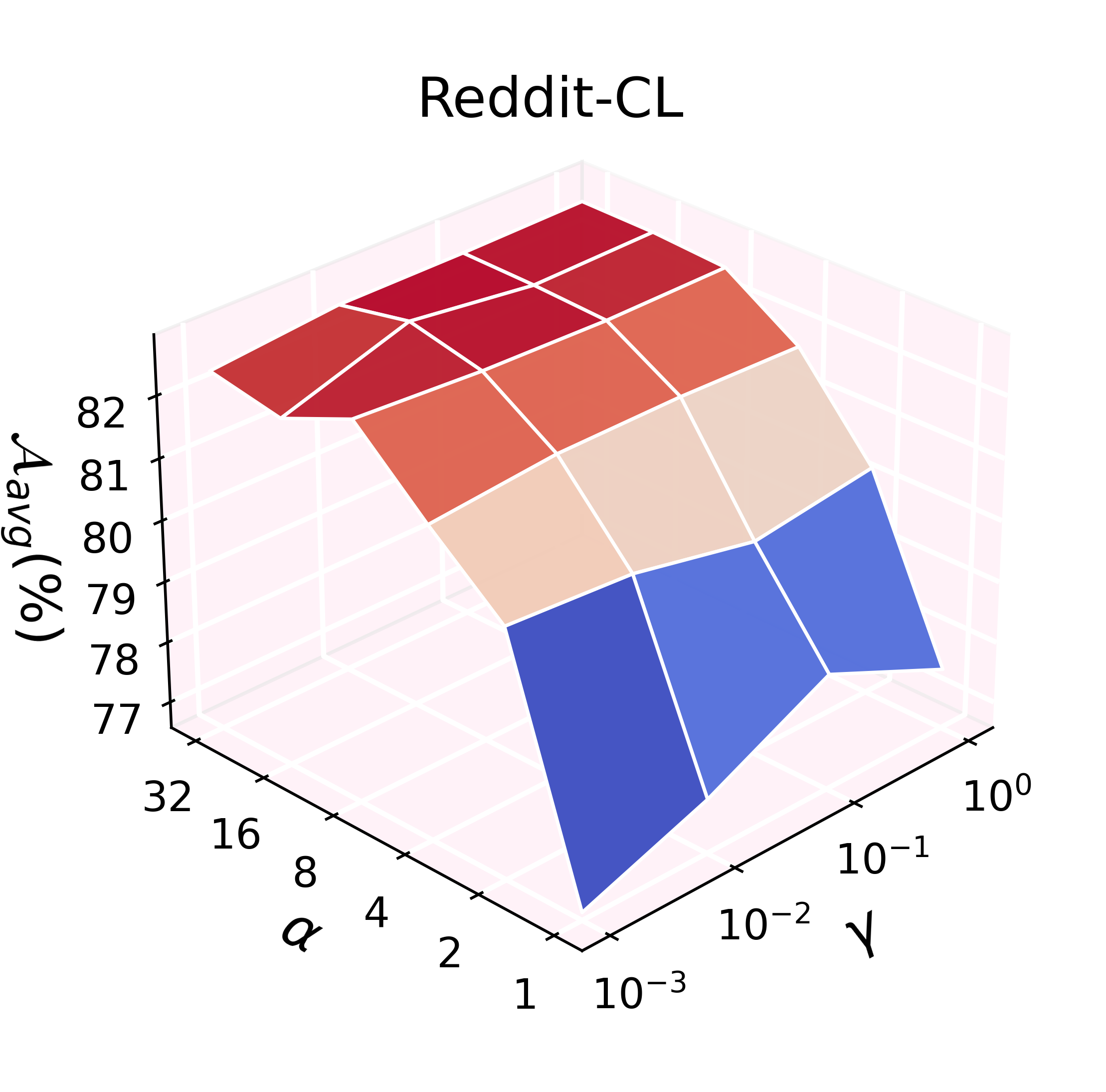
Figure 5: Hyperparameter grid search for α and γ demonstrates robust performance scaling.
Impact of Class Imbalance
Unbalanced tasks, particularly in Arxiv-CL, expose a potential weakness: merging can propagate bias if one task's model is highly skewed. This phenomenon is attributable to the full adaptation of both encoder and classifier, as opposed to classifier-only adaptation in strict analytic CL. Matrix plots and intra-task imbalance ratios reveal that improvement under such conditions remains an open challenge and a promising future research direction.
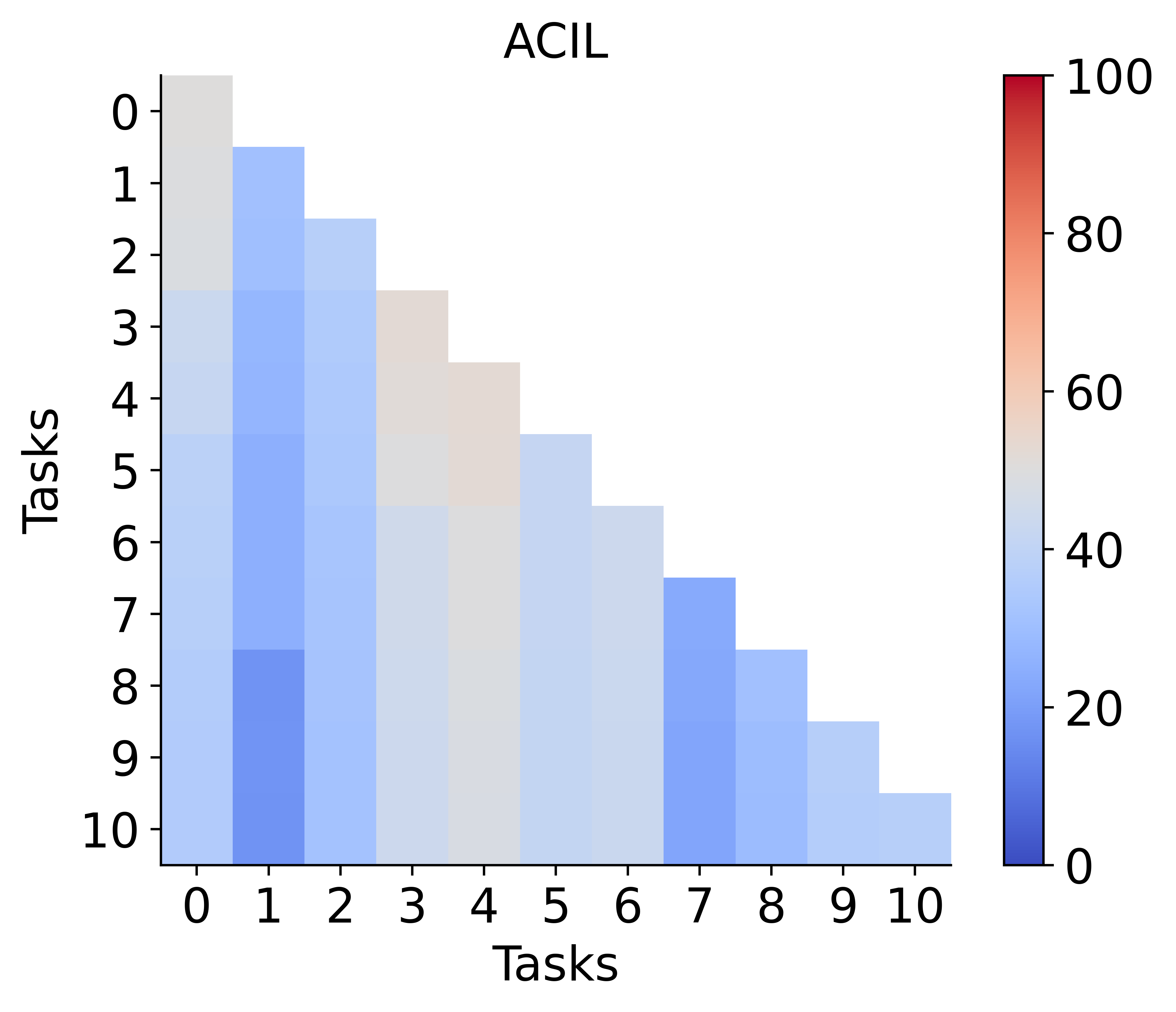
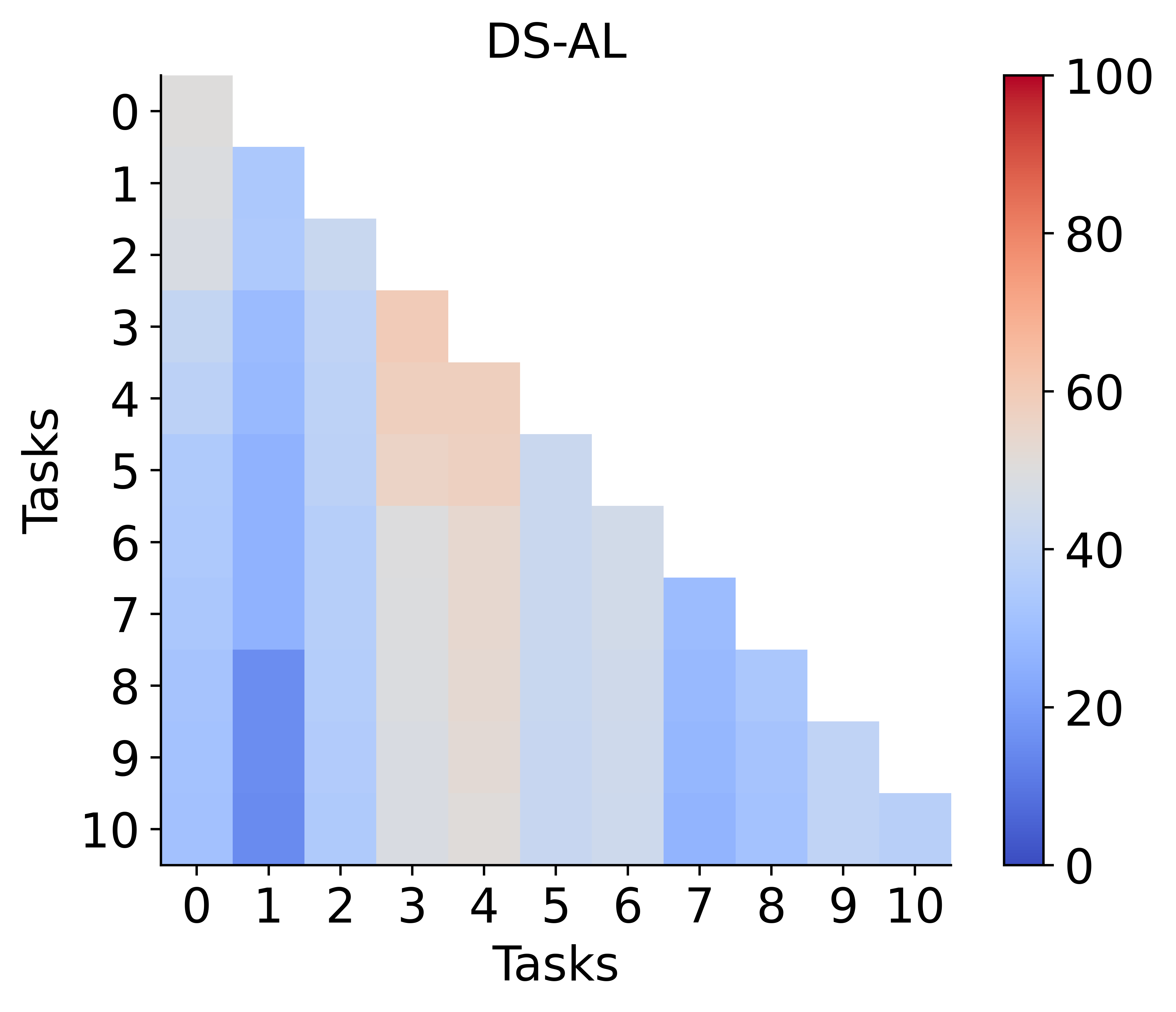
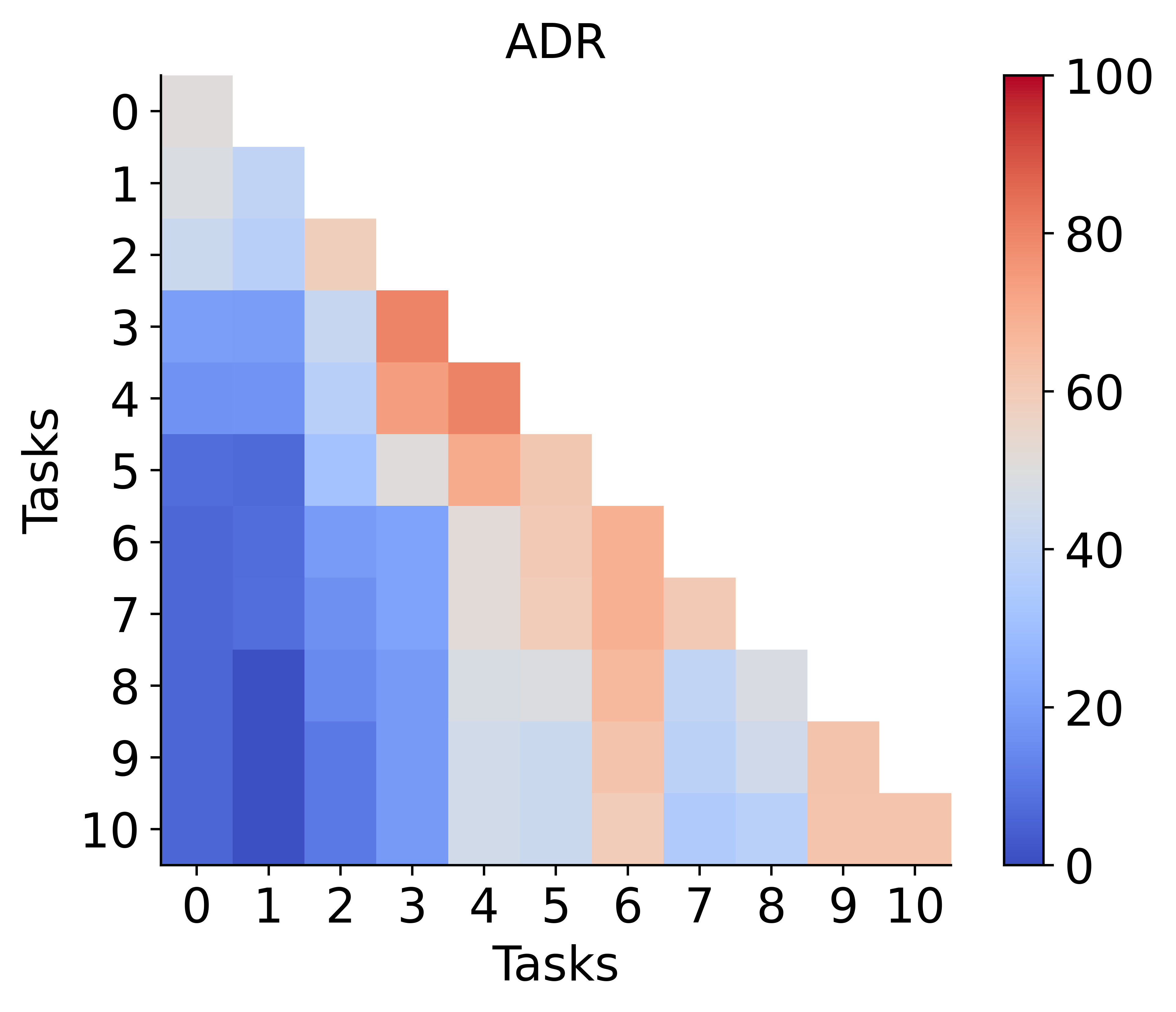
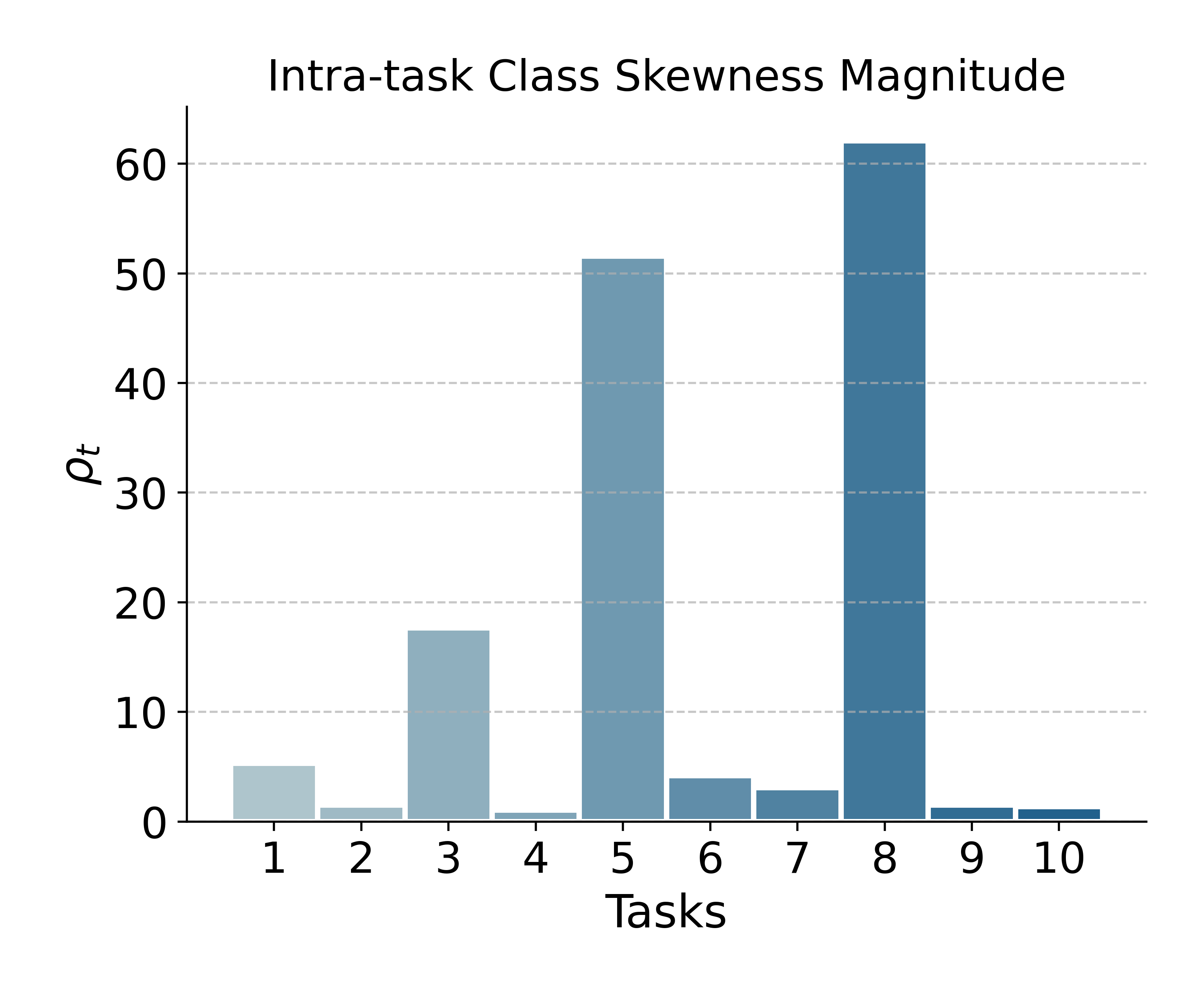
Figure 6: Left: ADR versus baselines on class-imbalanced Arxiv-CL. Right: Task-wise class imbalance, which correlates with ADR's performance dips.
Theoretical and Practical Implications
ADR marks an advancement in privacy-preserving graph continual learning: by reconciling model plasticity with guaranteed drift resistance, it brings joint training performance within reach in a non-exemplar, analytic setup. Its closed-form solutions for both encoder and classifier consolidation set a formal precedent for future non-exemplar paradigms. Practically, ADR holds promise for sensitive applications in recommendation, medical informatics, and dynamic graph analysis, where raw data storage is infeasible and distribution shift is pronounced.
The analytic merging principle outlined in HAM may find utility in general continuous adaptation scenarios beyond graphs, particularly for modular neural architectures requiring lifelong learning with strict privacy and drift minimization constraints.
Conclusion
ADR for NECGL achieves near joint-training performance with theoretically provable zero-forgetting and layerwise analytic feature drift resistance via a combination of encoder adaptation, analytic merging, and classifier reconstruction. Its effectiveness is empirically demonstrated on multiple challenging benchmarks. Moving forward, addressing class imbalance and extending analytic merging beyond GNN architectures represent compelling research frontiers.