- The paper introduces a descriptor-based hypernetwork that decouples the parameter generator from target models, allowing arbitrary architecture and task instantiation.
- It leverages Gaussian Fourier feature encodings and a Transformer-based task encoder to predict weights for diverse tasks, achieving near-parity with direct training benchmarks.
- The approach supports recursive, multi-model, and multi-task regimes while maintaining a fixed generator parameter footprint, paving the way for scalable, architecture-agnostic deployment.
Universal Hypernetworks for Arbitrary Models: Technical Analysis
Introduction and Motivation
The paper "Universal Hypernetworks for Arbitrary Models" (2604.02215) presents a descriptor-based hypernetwork architecture—Universal Hypernetwork (UHN)—which decouples the hypernetwork parameter generator from the target model's architecture and task, enabling a single parameter generator to instantiate arbitrary architectures across vision, NLP, graph, and regression domains. Classic hypernetworks are architecturally entangled with their base models, requiring redesign and retraining for changes in the base architecture. UHN instead parameterizes each scalar weight by a deterministic function of parameter index, architecture metadata, and task identity, using expressive Gaussian Fourier feature encodings and a Transformer-based task-structure encoder. This decoupling yields architectural and task universality, supporting single-model, multi-model, multi-task, and recursive hypernetwork instantiation regimes under a fixed generator.
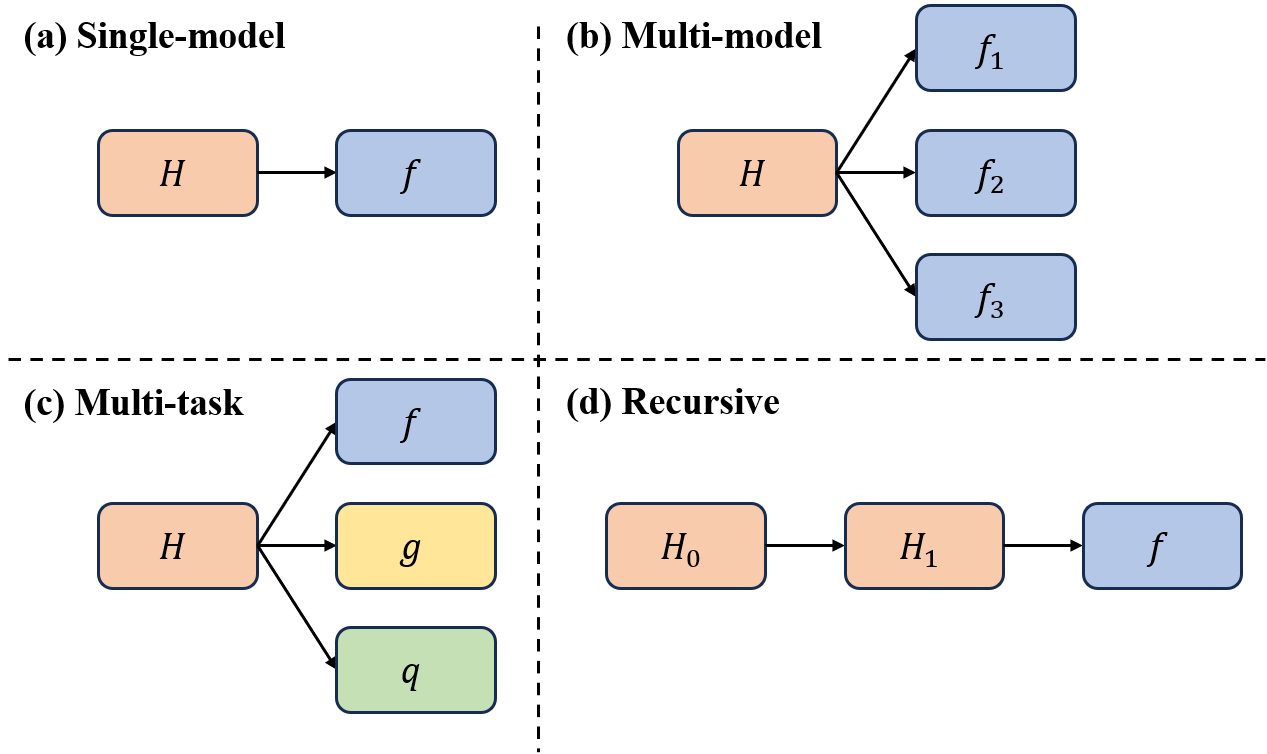
Figure 1: UHN operates in (a) single-model, (b) multi-model, (c) multi-task, and (d) recursive regimes, with a shared generator decoupled from target architectures and tasks.
Methodology
Descriptor-Based Weight Generation
Given a base model fw (with parameter vector w), the UHN generator Hθ predicts each wi as:
wi=Hθ(vi,sg,{sℓ,j}j=1L,t)
where vi encodes parameter index and type (layer, component, position), sg encodes global architectural metadata, {sℓ,j} encodes per-layer details, and t encodes the task/dataset.
Deterministic descriptors are mapped via Gaussian Fourier features—critical for alleviating MLPs’ spectral bias and enabling modeling of high-frequency structure in the parameter space—to fixed-length vectors, which are then aggregated (alongside structural descriptors via a Transformer encoder) to feed a compact MLP for scalar weight prediction.
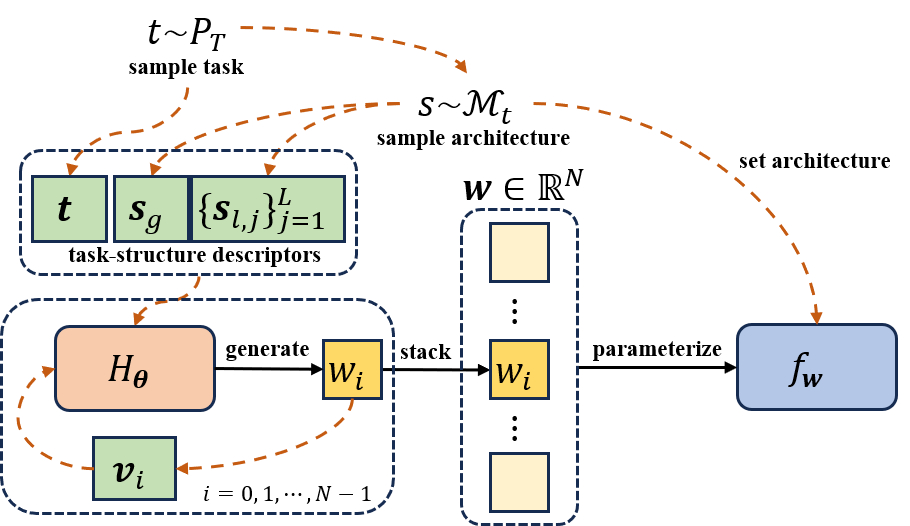
Figure 2: Overview of UHN weight generation: for each parameter, index and task-structure descriptors are encoded and then mapped to a predicted value by the universal generator.
Universal Generation Regimes
The method supports:
- Single-model instantiation: UHN predicts all weights for a fixed base model.
- Multi-model instantiation: UHN generates parameters for a set of architectures from a model family by varying architecture descriptors.
- Multi-task instantiation: Task descriptors select among tasks/datasets using static or heterogeneous base architectures.
- Recursive generation: UHN can generate parameters for another UHN, which recursively generates further models.
Unlike previous chunk- or block-based hypernetworks, whose parameter footprint grows with target model size or block count, the UHN’s parameterization is independent of target architecture size—generator parameters remain fixed, eliminating the architectural bottleneck.
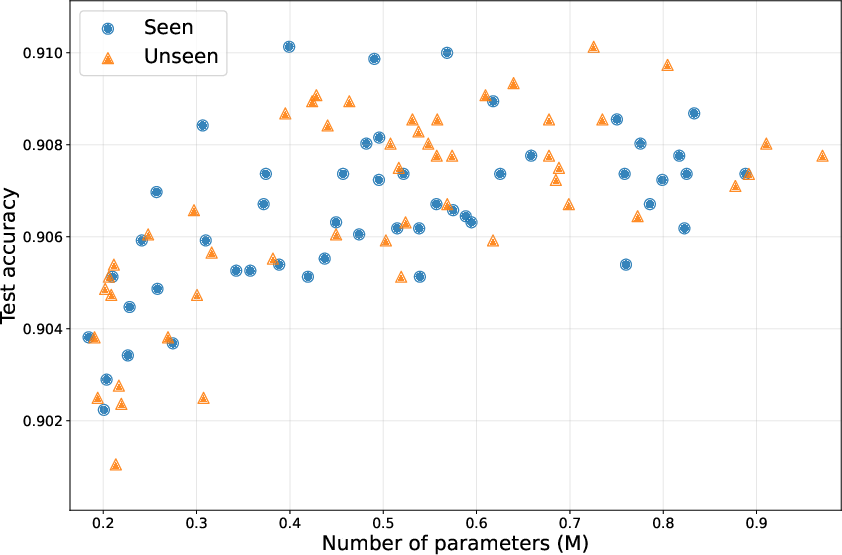
Figure 3: Performance scaling on the CNN Mixed Depth benchmark highlights UHN’s ability to maintain efficacy as target depth grows.
Empirical Results
Universality Across Modalities and Scalability
UHN achieves near-parity with direct training in tasks spanning MLPs/CNNs for vision, GCN/GATs for graph tasks, Transformers for NLP, and specialized regression (KAN for function regression). For example, on CIFAR-10 with a CNN-20, UHN yields 0.8993±0.0016 test accuracy versus w0 for direct training, a statistically insignificant delta given model stochasticity.
Scaling studies demonstrate that, unlike chunked or embedding-based hypernetworks, the UHN maintains a fixed parameter footprint as network depth/width increases without loss of predictive accuracy.

Figure 4: Applying Gaussian Fourier features to parameter indices provides the high-frequency basis necessary for accurate generation of diverse parameter fields.
Multi-Model and Multi-Task Generalization
In multi-model generalization (e.g., CNN families with varying depth and width), UHN generalizes effectively to unseen architectures. On the Transformer Mixed family, it achieves indistinguishable accuracy on train- and held-out architectures (w1 vs w2). This is a strong empirical verification of architectural decoupling and transfer.
In multi-task settings (jointly spanning vision, graph, text, and formula regression), the same UHN, with shared capacity, gives only marginal degradation versus dedicated, per-task trained UHNs or direct training. For complex tasks (e.g., CIFAR-10, GCN/Cora), the delta is w3 1% (absolute), suggesting that cross-task interference is limited by the expressivity of the descriptorization.
Recursive Generation
UHN supports recursive hypernetwork chains to a depth of three: w4, with only gradual reduction in output task performance (MNIST accuracy drops from w5 to w6 at w7).
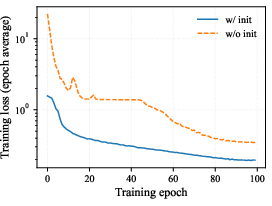
Figure 5: Initialization dramatically accelerates convergence and stabilizes recursive and multi-model training, as reflected in loss curves (shown for multi-model Transformer task).
Ablations and Architectural Insights
Comprehensive ablations confirm:
- Index encoding is critical: Gaussian Fourier features outperform raw/positional encodings by a margin (>0.03 absolute accuracy on CIFAR-10).
- Task-structure encoder’s role is mainly optimization: removes only minor performance for many settings, though it aids early-stage convergence and is essential for stability in deep recursion.
- Initialization is essential for training stability, especially in recursion; absence leads to divergence due to weight scale mismatch.
Theoretical and Practical Implications
UHN constitutes a class of architecture-agnostic hypernetwork with the following ramifications:
- Parameter decoupling: Generator size is independent of target model size/structure; system scales to arbitrarily large or structurally diverse model families.
- Cross-modal/heterogeneous-task sharing: Trained once, a UHN may serve vision, graph, NLP, and regression simultaneously, supporting unified multi-task architectures.
- Recursive and compositional model generation: Validation of up to three recursion levels suggests feasibility of hierarchical model generation (e.g., meta-meta-networks).
- Practical deployment: Eliminates the need for architecture-specific hypernetwork engineering, paving the way for autoML instantiation, large-scale ensemble generation, or architecture search where the generator remains fixed.
Limitations and Future Directions
While UHN approaches direct-training accuracy in most regimes, there remains a (typically small) performance gap, attributable to cross-task interference and parameter sharing. The model does not yet handle non-trainable state (e.g., BatchNorm moments), and larger/deeper recursive chains may require architectural or optimization advances. Further, hypernetwork regularization, more expressive encodings, and low-level training dynamics merit deeper examination.
Conclusion
Universal Hypernetwork (UHN) demonstrates that conditioning parameter generation on deterministic index, architecture, and task descriptors enables a fixed-capacity generator to instantiate arbitrary model architectures, match direct optimization baselines across modalities and tasks, and recursively generate other hypernetworks. This formulation represents an explicit decoupling of generator design from base architecture, supporting scalable, reusable, and practically transferable hypernetworks. Future work should address scaling, regularization, non-trainable state, and the underlying limits of descriptor-based universality.