The Universal Weight Subspace Hypothesis
Abstract: We show that deep neural networks trained across diverse tasks exhibit remarkably similar low-dimensional parametric subspaces. We provide the first large-scale empirical evidence that demonstrates that neural networks systematically converge to shared spectral subspaces regardless of initialization, task, or domain. Through mode-wise spectral analysis of over 1100 models - including 500 Mistral-7B LoRAs, 500 Vision Transformers, and 50 LLaMA-8B models - we identify universal subspaces capturing majority variance in just a few principal directions. By applying spectral decomposition techniques to the weight matrices of various architectures trained on a wide range of tasks and datasets, we identify sparse, joint subspaces that are consistently exploited, within shared architectures across diverse tasks and datasets. Our findings offer new insights into the intrinsic organization of information within deep networks and raise important questions about the possibility of discovering these universal subspaces without the need for extensive data and computational resources. Furthermore, this inherent structure has significant implications for model reusability, multi-task learning, model merging, and the development of training and inference-efficient algorithms, potentially reducing the carbon footprint of large-scale neural models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a simple but powerful idea: many different deep neural networks, even when trained on different tasks and datasets, end up using very similar “paths” inside their weights. The authors call these shared paths “universal subspaces.” Think of it like lots of different musicians playing different songs, but most songs rely on the same small set of common chords. In the same way, the paper shows that most of the important action inside neural networks happens along a small set of directions, again and again.
Key Questions
The researchers set out to answer a few clear questions:
- Do neural networks trained on different tasks still rely on the same small set of weight directions?
- Is this true across different models (like vision models and LLMs), not just one type?
- Can we find these shared directions and reuse them to make training, merging, and running models faster and cheaper?
- Can we back this up with math, not just experiments?
How They Studied It
To make this understandable, here’s what they did, in everyday terms:
- What is a “subspace”? Imagine the weights of a neural network as a huge maze with many possible directions. A “subspace” is like a few favorite lanes in the maze that the network uses most of the time. A “low-rank” or “low-dimensional” subspace means only a small number of lanes are really important.
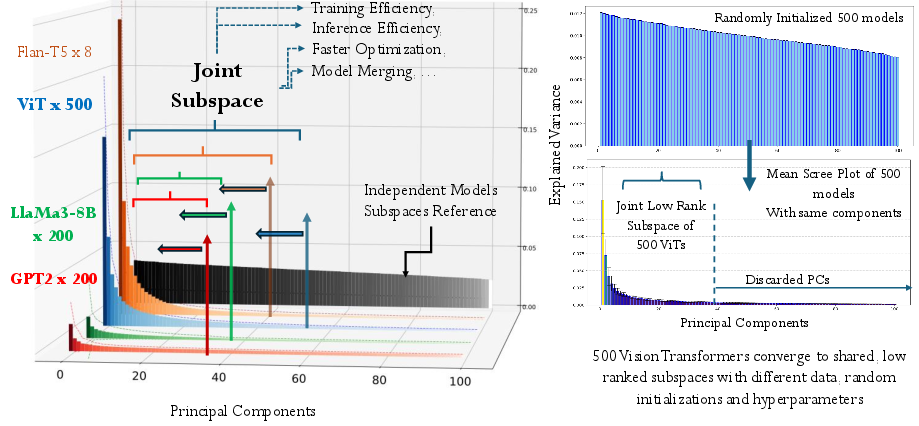
- Looking for main directions: They used a tool similar to Principal Component Analysis (PCA), which finds the most important directions in data. They applied it to the weight matrices of many models to see which directions carry most of the information. This kind of “spectral analysis” is like finding the main notes in a song or the biggest hills in a landscape.
- HOSVD (Higher-Order SVD): This is a generalization of SVD/PCA that works on big multi-dimensional arrays (called tensors). Picture stacking many weight matrices into a big block and then breaking it down to find its strongest shared directions.
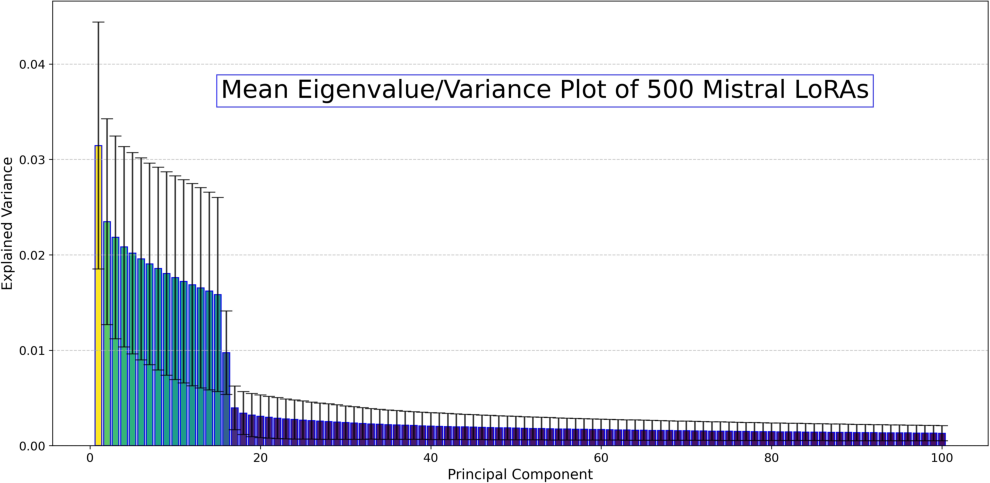
- LoRA adapters: These are small add-ons used to fine-tune big models cheaply. Because there are many public LoRA adapters, they make a great testbed. The team analyzed about 500 LoRA adapters on the Mistral-7B LLM and on Stable Diffusion (for images).
- Big, diverse test sets: They didn’t just check one or two models. They analyzed over 1100 models, including:
- ~500 Vision Transformers (ViT) for images,
- ~500 Mistral-7B LoRA adapters (language),
- 50 LLaMA-8B models (language),
- 177 GPT-2 models,
- and some Flan-T5 models (language).
- A bit of theory: They modeled tasks in a math space (a “Hilbert space”) and proved that if you learn many tasks well enough, the shared subspace you estimate will converge to the true common subspace. In simpler terms: the more tasks you include and the better each model is trained, the closer your discovered “favorite lanes” will be to the real ones. A bigger “eigengap” (the gap between important and less important directions) makes this even more reliable.
Main Findings
Here’s what they discovered, described simply:
- Strong “spectral decay”: When they look at the weight directions, the top few directions explain most of the variance (the “interesting” part). The rest quickly become less important. This happens across many layers and many different models and tasks.
- Universal subspaces really show up:
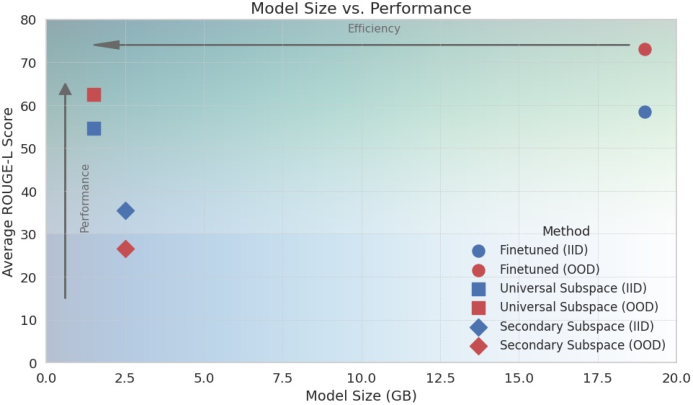
- In Mistral-7B LoRA adapters: Across ~500 different tasks, a small set of directions captures most of what those adapters do. Even when you reconstruct adapters by projecting them onto this shared subspace, performance stays strong, including on unseen tasks. That also makes storage about 19× smaller.
- In Stable Diffusion (text-to-image): Rebuilding styles using the universal subspace keeps image quality similar, sometimes even slightly better in CLIP scores.
- In Vision Transformers: Analyzing ~500 ViT models shows the same low-rank pattern. They can project new models onto a 16-dimensional subspace and retain accuracy, cutting memory by up to 100× (excluding task-specific input/output layers).
- In LLaMA-8B, GPT-2, Flan-T5: Similar low-rank shared patterns appear, suggesting this is a broad phenomenon.
- Model merging works better: Using the universal subspace to combine multiple models (without extra tuning) beats several popular merging methods on average accuracy, while using fewer parameters.
- Faster adaptation to new tasks: If you freeze the shared directions and learn only small “coefficients” (like volume knobs for each direction), you can adapt to new tasks much faster and with far fewer trainable parameters. For example:
- On GLUE (language tasks), their universal subspace approach matched or slightly improved performance over LoRA while running faster.
- For ViT image classification, they trained only about 10,000 parameters (vs. 86 million) and still got close to full-training accuracy.
Why This Matters
This is important because it suggests that the architecture (the design of the network) leads models to learn in similar ways, even across different tasks. That explains:
- Why huge models generalize well even when they have more parameters than data.
- Why different initializations (random starts) often end up with similar solutions.
- Why small, efficient fine-tuning methods (like LoRA) are so effective.
- Why model merging and transfer learning works across different datasets and goals.
In short, most models aren’t using their entire giant parameter space. They mostly operate within the same small set of “favorite lanes.” Knowing this lets us compress, reuse, and adapt models more easily.
Implications and Impact
This shared subspace idea could have big practical benefits:
- Model compression: Store only the shared directions and per-task coefficients, not full weights. This can reduce storage by 10×–100× or more.
- Efficient training and inference: For new tasks, learn tiny coefficients rather than millions of weights. That saves time, money, and energy.
- Better merging and multi-task systems: Combine many models into one unified representation without complex tuning, making deployment simpler.
- Environmental impact: Less computation means a lower carbon footprint for AI.
- New research directions: If many models collapse into the same subspace, they might share the same strengths and weaknesses. Future work could design architectures to control, diversify, or even break this convergence when needed, and to interpret what these shared directions actually mean.
In essence, the paper argues that deep learning has a hidden geometric simplicity: across many tasks and models, most of the learning happens in a small, shared set of directions. Recognizing and using this can make AI systems faster, cheaper, greener, and easier to build and combine.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of specific gaps, uncertainties, and unresolved questions that future work could address to strengthen and extend the claims in the paper.
- Formal bridge between function-space theory and weight-space empirics is missing: the theoretical analysis is framed in a Hilbert space of predictors () while experiments analyze weight matrices via HOSVD; derive and validate a principled mapping (e.g., via linearization/NTK, Fisher information, or Jacobian-based operators) that connects predictor-level second-moment operators to weight-space spectral structure.
- Eigengap and effective-rank assumptions are unverified in practice: quantify -dependent eigengaps () layer-wise across architectures and models, and empirically validate bounded effective rank; clarify and correct the “effective rank” definition (e.g., tr) and ensure it matches the operator used in experiments.
- Centering mismatch between theory and method: the theory uses the second-moment operator (not centered), while the HOSVD pipeline explicitly zero-centers weights; measure the impact of centering choice on the recovered subspaces and reconcile the theory–practice discrepancy.
- Rank selection and thresholding are under-specified: systematically ablate the number of retained components () and the variance threshold per layer and architecture; provide compression–performance curves and criteria for selecting that generalize across tasks.
- Possible confounding from LoRA rank and design: many LoRAs use rank 16, which may induce an apparent 16-dimensional “universality”; test universality with higher-rank LoRAs (e.g., 32, 64, 128) and different adapter designs to decouple subspace size from adapter constraints.
- Initialization confounds (especially for “randomly initialized” ViTs): verify whether the reported convergence to a “common subspace” without training is driven by shared initialization schemes; replicate with deliberately varied initializations (Xavier, Kaiming, orthogonal, scaled variants) and optimizers to isolate training-induced universality from initialization artifacts.
- Layer-wise granularity is limited: provide per-layer subspace overlap metrics (e.g., principal angles, Grassmannian distances), identify which layers exhibit strongest universality, and test whether attention heads, MLPs, and embedding layers differ in subspace structure.
- Neuron/attention-head permutation invariance is unaddressed: test robustness of universality under synthetic permutations of heads/neurons within layers; if subspace alignment is sensitive, introduce permutation/alignment procedures (e.g., Procrustes, optimal transport alignments) and re-evaluate universality claims.
- Cross-architecture universality left open: develop methods to compare/align subspaces across architectures (e.g., CNN↔Transformer, encoder↔decoder blocks) using canonical correlation analysis, representational similarity analysis, or learned inter-architecture maps; quantify similarities and differences.
- First/last layer handling is ad hoc: propose shape-agnostic alignment strategies for input/output layers (e.g., padding, learned linear maps, weight tying, or feature-space projections) and test whether universal subspaces extend to task-variable layers.
- Dataset and pipeline diversity insufficiently controlled: curate evaluation suites with truly disjoint domains and training pipelines (code, optimizer, data processing, hyperparameters) including math, code, multilingual, speech, graphs, RL, and time-series; test universality beyond natural images and general-purpose NLP.
- OOD generalization evidence is limited: define OOD rigorously, expand OOD evaluations to larger and more diverse model sets, and quantify accuracy, calibration, and robustness when projecting weights into universal subspaces.
- Statistical significance and baselines are underdeveloped: specify the “independent subspaces reference” baseline and add random-rotation/random-subspace controls; perform statistical tests (e.g., bootstrapped principal angles, permutation tests) to quantify how unlikely the observed alignment is under null models.
- Training dynamics are unexplored: track subspace emergence over training (checkpoints) to determine when universality appears, whether it stabilizes, and how it depends on learning rate schedules, regularization, and data curricula.
- Mechanistic interpretation is minimal: analyze and visualize principal directions (e.g., feature attribution, circuit-level probing, Fourier modes for CNNs, attention pattern archetypes for Transformers); link subspace axes to known interpretability artifacts (e.g., Gabor-like filters, common relational circuits).
- Energy, carbon, and latency claims need direct measurement: report standardized energy/latency metrics (hardware, batch sizes, precision modes) for training, inference, and merging, beyond memory savings, to substantiate environmental impact claims.
- Robustness, fairness, and safety implications are untested: evaluate whether universal subspaces encode shared biases/failure modes; test adversarial robustness, fairness metrics, and safety behaviors before/after projection to the universal subspace.
- Model merging comparisons may be unfair or incomplete: ensure baselines receive comparable hyperparameter tuning and validation budget; expand datasets, architectures, and merging settings; report compute/time and sensitivity analyses to strengthen the claim that subspace-based merging is superior.
- Scalability to very large models is unclear: demonstrate feasibility on larger LLMs (e.g., 70B+), explore randomized or streaming SVD/HOSVD, and quantify compute/memory costs of subspace extraction at scale.
- Secondary subspace definition is opaque: formalize the notion of “primary” versus “secondary” subspaces, establish objective criteria for separating them, and analyze performance when using different partitions.
- Reusability without pretrained task-specific models remains unresolved: develop and evaluate model-independent procedures to learn universal subspaces directly from data (e.g., using Fisher information, Jacobian ensembles, NTK kernels, or meta-learning over synthetic tasks), with sample-complexity guarantees.
- Conditions for breaking convergence are unstudied: empirically test strategies to increase diversity (e.g., orthogonality regularizers, anti-collapse penalties, alternative objectives, different architectures) and quantify trade-offs between diversity and performance.
- Reproducibility details are incomplete: release exact model lists, preprocessing, normalization/scaling of weights before HOSVD, code, and seeds; document how per-layer tensors are constructed and how variance is aggregated across layers.
- Measurement artifacts due to weight scaling/normalization may bias results: standardize layer-wise weight normalization before spectral analysis and report how different normalization schemes affect explained variance and subspace overlap.
- Theoretical scope is narrow: extend convergence guarantees beyond RKHS settings to more realistic deep-network regimes (nonlinear, finite width), incorporate weight symmetries, and analyze the effect of centering and mean components in the operator.
- Generalization to modalities beyond vision/NLP is not shown: test universality in speech (ASR), reinforcement learning (policy/value networks), graphs (GNNs), and multimodal models (e.g., LLM–vision joint encoders) to assess breadth of the hypothesis.
Practical Applications
Practical Applications of the Universal Weight Subspace Hypothesis
Below, we distill actionable, real-world applications that follow from the paper’s findings: deep networks trained on diverse tasks converge to shared, architecture- and layer-specific low-rank subspaces; these can be recovered via spectral methods (e.g., HOSVD) and reused for efficient adaptation, merging, and serving. We group use cases by deployment horizon and note relevant sectors, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
The following applications can be piloted now with existing models and the paper’s methodology (HOSVD-based subspace extraction, subspace projection, and coefficient-only adaptation).
- 1) Parameter-efficient adaptation in universal subspaces Description: Freeze layer-wise principal directions and learn only task-specific coefficients to adapt large models (LLMs, ViTs, T5/Roberta) to new tasks with drastically fewer trainable parameters, faster convergence, and reduced memory. Sectors: software/ML platforms, enterprise MLOps, healthcare imaging, satellite/remote sensing, finance NLP. Tools/Workflows: “Subspace-Finetune” SDK; coefficient-only training loops; per-layer basis registries. Assumptions/Dependencies: Same base architecture; sufficient eigengap and effective rank; first/last task-specific layers may still need training; performance depends on quality and quantity of models used to estimate the subspace.
- 2) Large-scale model compression and storage reduction Description: Replace hundreds of models with a single “universal basis” plus sparse per-task coefficients—e.g., 500 ViTs or LoRAs consolidated into one subspace artifact with >100× storage savings. Sectors: cloud providers, model hubs, edge devices, mobile apps. Tools/Workflows: “Universal Subspace Hub” artifact format; basis + coefficient packaging; versioned basis registries. Assumptions/Dependencies: License to use model weights; subspace quality must be high enough; task-specific input/output layers remain separate.
- 3) Multi-tenant inference serving with coefficient hot-swapping Description: Serve many customer models on shared hardware by loading small coefficient sets on demand while keeping the universal basis resident in memory. Sectors: SaaS AI platforms, enterprise model hosting. Tools/Workflows: coefficient cache; runtime that executes low-rank transforms directly; per-tenant coefficient isolation. Assumptions/Dependencies: Shared architecture across tenants; runtime support for low-rank ops; careful scheduling to avoid contention.
- 4) Data-free or low-data model merging via subspace geometry Description: Merge multiple fine-tuned models analytically by projecting updates into the universal subspace and combining coefficients—achieving robust accuracy without heuristic pruning or validation sets. Sectors: enterprise AI, content moderation, legal/contract analytics, vision model consolidation. Tools/Workflows: “Subspace-Merge” CLI/library; per-layer alignment via HOSVD; optional small validation set for tuning. Assumptions/Dependencies: Good subspace alignment; same architecture and layers; performance may improve with optional post-merge fine-tuning.
- 5) Style LoRA consolidation for text-to-image generation Description: Compress and serve SDXL style LoRAs using a universal subspace; ship “style packs” as compact coefficients with preserved visual quality (CLIP-evaluated). Sectors: creative tools, game engines, media production. Tools/Workflows: LoRA recycler; style registry; on-device style switching via coefficients. Assumptions/Dependencies: Style LoRAs trained for the same base model; slight style drift possible; periodic refresh of the basis improves results.
- 6) On-device personalization with tiny updates Description: Learn per-user coefficients for personalization (e.g., clinician-specific imaging preferences, user-specific writing styles) with minimal compute and storage, enabling offline or privacy-preserving adaptation. Sectors: mobile, healthcare, assistive tech, robotics. Tools/Workflows: on-device coefficient training; differential privacy wrappers; federated coefficient aggregation. Assumptions/Dependencies: Shared architecture across devices; privacy policies; small local datasets suffice if the basis is strong.
- 7) Continual and multi-task learning without catastrophic forgetting Description: Maintain a bank of task-specific coefficients over a shared basis to switch tasks without overwriting weights, reducing interference and memory footprint. Sectors: education ML, industrial inspection, autonomous systems. Tools/Workflows: coefficient bank; task router; evaluation harnesses. Assumptions/Dependencies: Tasks share the architecture-specific subspace; first/last layers may remain task-specific.
- 8) Model audit and spectral interpretability scaffolding Description: Use layer-wise principal directions as an interpretable scaffold to audit recurring circuits, detect spurious directions, and study universal biases. Sectors: academia, AI safety, compliance. Tools/Workflows: “Subspace Explorer” visualization; spectral diagnostics; direction-level probing. Assumptions/Dependencies: Mapping from spectral directions to semantics remains limited; requires careful interpretation.
- 9) Carbon footprint reductions and sustainability reporting Description: Quantify and cut energy usage by training fewer parameters, serving shared bases, and consolidating model variants; include subspace metrics in sustainability dashboards. Sectors: energy policy, ESG reporting, cloud FinOps. Tools/Workflows: carbon accounting tied to parameter counts; “basis reuse” KPIs; green deployment playbooks. Assumptions/Dependencies: Organizational buy-in; infrastructure to measure energy; realized speedups depend on runtime integration.
- 10) Compressed model distribution for consumer apps Description: Ship a single basis and per-feature coefficients to reduce download size and enable offline features (e.g., personalized keyboards, camera filters, small LLMs). Sectors: consumer software, AR/VR, IoT. Tools/Workflows: app packaging of basis + coefficients; incremental updates push coefficients only. Assumptions/Dependencies: Common device architecture support; robust low-rank inference kernels.
Long-Term Applications
These applications require further research, scaling, standardization, or hardware/software development before broad deployment.
- 1) Cross-architecture universal subspaces and standards Description: Extend universality beyond single architectures; define shared artifacts and APIs for CNNs, Transformers, diffusion models, and hybrid systems. Sectors: standards bodies, ML hubs, research consortia. Tools/Workflows: “Basis Artifact” open standard; cross-arch comparison suites. Assumptions/Dependencies: New methods to compare subspaces across architectures; consensus on packaging and governance.
- 2) Subspace-first training algorithms Description: Train models from scratch constrained to learned universal subspaces to accelerate convergence, reduce overfitting, and lower compute budgets. Sectors: cloud training, foundation model providers. Tools/Workflows: optimizers with subspace constraints or priors; curriculum that expands rank over time. Assumptions/Dependencies: Risk of performance loss if constraints are too tight; requires robust estimates of “ideal” subspace.
- 3) Hardware acceleration for low-rank inference and coefficient routing Description: Design chips and kernels optimized for low-rank tensor ops, fast coefficient swapping, and subspace-aware memory layouts. Sectors: semiconductors, edge computing, cloud accelerators. Tools/Workflows: compiler passes for low-rank fusion; on-chip basis caches. Assumptions/Dependencies: Sufficient market demand; co-design with runtime and model formats.
- 4) Bias and diversity management (“breaking convergence” when needed) Description: Detect and mitigate shared biases and failure modes embedded in universal subspaces; deliberately diversify or decorrelate bases to improve fairness and robustness. Sectors: policy, AI ethics, regulated industries. Tools/Workflows: subspace diversity metrics; fairness-aware basis construction. Assumptions/Dependencies: New diagnostics; trade-offs between universality and diversity.
- 5) Secure federated learning with coefficient sharing Description: Exchange only coefficients (not full weights) across clients; reduce bandwidth and improve privacy while leveraging a shared basis. Sectors: healthcare, finance, public sector. Tools/Workflows: secure aggregation for coefficients; audit trails; DP guarantees. Assumptions/Dependencies: Shared architecture and basis across clients; strong privacy guarantees for coefficient leakage.
- 6) Automated universal subspace discovery directly from data Description: Learn a reusable basis without a large zoo of pretrained models, e.g., via unsupervised or self-supervised spectral objectives. Sectors: research, foundation model pretraining. Tools/Workflows: data-driven HOSVD variants; self-supervised subspace learners. Assumptions/Dependencies: New algorithms; scalable estimation; validation across tasks.
- 7) Regulatory certification of subspaces for high-stakes domains Description: Certify universal bases for safety, reliability, and domain compliance (e.g., medical imaging or autonomous driving) and restrict task coefficients to controlled ranges. Sectors: healthcare, automotive, aviation. Tools/Workflows: basis-level audits; certification pipelines; documentation standards. Assumptions/Dependencies: Domain-specific validation, liability frameworks, and regulatory acceptance.
- 8) Education and scientific reproducibility Description: Use stable layer-wise subspaces to teach deep learning concepts and to enable reproducible model comparisons across tasks and datasets. Sectors: academia, open science. Tools/Workflows: interactive subspace explorer; reproducibility kits. Assumptions/Dependencies: Community adoption; curated benchmarks.
- 9) Safety via subspace ensembles and resilience testing Description: Build ensembles over diversified subspaces to detect anomalies and improve robustness to distributional shifts. Sectors: AI safety, defense, mission-critical systems. Tools/Workflows: subspace ensemble builders; stress-testing frameworks. Assumptions/Dependencies: Methods to generate complementary bases; evaluation suites for OOD conditions.
- 10) Energy policy and carbon accounting standards for AI Description: Embed subspace reuse metrics into procurement and reporting; incentivize low-rank adaptation and shared-basis serving to cut emissions. Sectors: public policy, ESG, cloud procurement. Tools/Workflows: standardized reporting (basis reuse rate, parameter savings); incentives in funding and contracts. Assumptions/Dependencies: Policy alignment; measurement infrastructure; industry collaboration.
Notes on Feasibility and Assumptions
- Universality is architecture- and layer-specific; cross-architecture universality is an open question.
- Subspace fidelity improves with the number and quality of models used to estimate the basis; an eigengap and bounded effective rank accelerate reliable recovery.
- First and last layers often remain task-dependent due to input/output variability; these may require separate handling.
- Legal licensing and data governance apply when aggregating weights from public repositories.
- Coefficient-only adaptation is empirically strong but not theoretically guaranteed for arbitrary unseen tasks; optional fine-tuning can help.
- Shared subspaces may encode common biases and failure modes; diversity-aware construction and audits are advisable.
- Realized speedups depend on runtime and hardware support for low-rank ops; gains are largest when inference stacks are subspace-aware.
Glossary
- Bernoulli pruning: Randomly removing parameters or updates according to a Bernoulli distribution to sparsify model merging. "random Bernoulli pruning"
- Catastrophic forgetting: The tendency of a model to lose performance on previously learned tasks when trained on new ones. "catastrophic forgetting"
- CLIP: A vision-LLM used to evaluate text–image alignment; here used for quantitative assessments of generated images. "CLIP-based evaluations"
- Convolutional Neural Network (CNN): A neural architecture with convolutional layers, commonly used for image tasks. "CNN (Convolutional Neural Network) architectures."
- Core tensor: The central tensor in Tucker/HOSVD decompositions that captures interactions among factor matrices. "truncated core tensor"
- Effective rank: A measure of the intrinsic dimensionality of an operator or matrix based on its spectrum. "bounded effective rank"
- Eigengap: The difference between consecutive eigenvalues, governing stability of subspace recovery. "Define the eigengap ."
- Eigenspace: The subspace spanned by eigenvectors associated with selected eigenvalues. "Its top- eigenspace "
- Explained variance: The fraction of total variance captured by selected principal components or singular vectors. "Explained Variance"
- Gabor-like filters: Orientation- and frequency-selective filters often learned in early convolutional layers. "Gabor-like filters"
- Grokking: A phenomenon where a model suddenly generalizes after extended training beyond fitting. "grokking"
- Higher-Order Singular Value Decomposition (HOSVD): A generalization of SVD to tensors, factoring them into mode-specific subspaces. "HOSVD (Higher-Order Singular Value Decomposition)"
- Hilbert space: A complete inner-product space used to model predictors and operators. "separable Hilbert space"
- Implicit regularization: The tendency of optimization dynamics (e.g., gradient descent) to favor simpler solutions without explicit penalties. "implicit regularization"
- Inductive bias: Assumptions built into an architecture or learning procedure that shape the learned solutions. "inductive bias of modern deep architectures"
- Kernel ridge regression: A regularized regression method in RKHS combining kernels with L2 penalties. "kernel ridge regression"
- KnOTS-DARE-TIES: A model-merging method combining KnOTS alignment with DARE-TIES heuristics. "KnOTS-DARE-TIES"
- KnOTS-TIES: A merging approach that applies SVD-based alignment (KnOTS) before TIES merging. "KnOTS-TIES"
- LoRA adapters: Low-rank trainable modules inserted into large models for parameter-efficient fine-tuning. "LoRA adapters"
- Lottery ticket hypothesis: The idea that sparse subnetworks within overparameterized models can train to high accuracy. "lottery ticket hypothesis"
- Magnitude-based pruning: Removing parameters by thresholding their magnitudes to promote sparsity. "magnitude-based pruning"
- Matricization (mode-n matricization): Reshaping a tensor into a matrix by unfolding along a specific mode. "mode- matricization"
- Mechanistic interpretability: Analyzing circuits and representations inside networks to understand their computations. "mechanistic interpretabilityâspecifically its own universality hypothesis"
- Mode connectivity: The existence of low-loss paths between different trained solutions in parameter space. "mode connectivity"
- Mode- tensor–matrix multiplication: Multiplying a tensor by a matrix along a specific mode, transforming one dimension. "mode- tensor--matrix multiplication"
- Mode-wise spectral analysis: Spectral examination performed per mode (e.g., per layer or tensor mode) to study shared directions. "mode-wise spectral analysis of over 1100 models"
- Neural Tangent Kernel (NTK): A kernel describing training dynamics in the infinite-width limit of neural networks. "Neural Tangent Kernel (NTK) theory"
- Out-of-distribution (OOD): Data or tasks that differ from the training distribution used to build models. "unseen (OOD) tasks"
- Positive semi-definite: An operator or matrix whose quadratic form is nonnegative for all inputs. "self-adjoint and positive semi-definite"
- Principal component analysis (PCA): A technique to find orthogonal directions capturing maximal variance in data or weights. "Principal component analysis of 200 GPT2, 500 Vision Transformers, 50 LLaMA-8B, and 8 Flan-T5 models"
- Projector (onto a subspace): A linear operator that maps vectors onto a specified subspace. "projector onto the population top- subspace"
- Rademacher complexity: A measure of hypothesis class richness based on random sign fluctuations. "Rademacher complexity"
- RegMean: A gradient-free model-merging method aligning task updates via layer-wise regression. "RegMean"
- Reproducing kernel Hilbert space (RKHS): A Hilbert space of functions with a reproducing kernel enabling evaluation via inner products. "reproducing kernel Hilbert space (RKHS)"
- Second-moment operator: An operator capturing the uncentered covariance structure across tasks/predictors. "Task second-moment operator"
- Self-adjoint: An operator equal to its adjoint (transpose/conjugate), ensuring real eigenvalues. "self-adjoint and positive semi-definite"
- Separable Hilbert space: A Hilbert space with a countable dense subset, facilitating analysis and representation. "separable Hilbert space"
- Spectral bias: The tendency of learning to favor low-frequency components or smooth functions. "spectral bias toward low-frequency functions"
- Spectral decay: Rapid decrease of eigenvalues/singular values, indicating low-rank structure. "sharp spectral decay"
- Spectral decomposition: Factorizing an operator or matrix into eigenvalues/eigenvectors or singular values/vectors. "spectral decomposition techniques"
- Sub-Gaussian response noise: Noise with tails bounded like a Gaussian, used in generalization analyses. "sub-Gaussian response noise"
- Subspace alignment: Aligning subspaces across models (e.g., via SVD) prior to merging. "SVD-based subspace alignment"
- Task Arithmetic (TA): Linear combination of model parameters to edit or merge tasks. "Task Arithmetic (TA)"
- Thin SVD: Computing a reduced SVD keeping only nonzero singular vectors for efficiency. "Compute thin SVD"
- Truncated Zero-Centered HOSVD: An HOSVD variant after zero-centering and truncating by explained variance. "Truncated Zero-Centered Higher-Order SVD (HOSVD)"
- Unfolding: Reshaping a tensor into a matrix along a dimension to enable SVD or PCA. "unfold"
- Universal subspace: A shared low-dimensional parameter subspace across models/tasks within an architecture. "Universal subspace"
- Vision Transformer (ViT): A transformer-based architecture for images using patch embeddings and self-attention. "Vision Transformers"
Collections
Sign up for free to add this paper to one or more collections.

