- The paper introduces a fidelity–steering decomposition method that enables robust, training-free continuous image editing.
- It separates semantic (steering) and structural (fidelity) components to maintain high-quality, smooth, and predictable slider-based edits.
- Experimental results demonstrate superior performance with enhanced CLIP-dir, DreamSim scores, and reliable slider behavior compared to learned alternatives.
FlowSlider: Training-Free Continuous Image Editing via Fidelity-Steering Decomposition
Motivation and Problem Setting
Continuous image editing aims to provide parametric, slider-based modulation of edit strength, maintaining source fidelity and semantic consistency throughout. While recent advances in text-guided image editing—primarily in diffusion models and rectified flow architectures—have yielded high-fidelity and semantically accurate outputs, most slider-style continuous control methods necessitate learned mappings, synthetic/proxy supervision, additional training, and explicit calibration on curated datasets. This enables fine-grained manipulation but introduces dependence on the supervision protocol, often degrading generalization and reliability under distribution or task shift.
The introduced FlowSlider framework addresses slider-style continuous control in a fully training-free regime, leveraging the theoretical and geometric properties of pre-trained rectified flow models. The approach is positioned as an extensible inference-time mechanism applicable to a broad class of flow-based editors, requiring only a source image and prompt pair for instant, robust slider-based editing.

Figure 1: FlowSlider for continuous image editing; each row demonstrates stronger prompt-induced edits with increasing slider magnitude, starting from the real image.
Methodology: Fidelity–Steering Decomposition
FlowEdit and Naive Scaling Limitations
FlowEdit defines the editing ODE in prompt-pair editing by constructing and integrating a velocity field difference between source- and target-conditioned flows, using a shared noise realization to couple states. Despite yielding faithful and semantically coherent edits, naive introduction of a scalar strength parameter s (i.e., sVΔ) fails to provide predictable or high-fidelity continuous modulation; amplifying the coupled noise and semantic components breaks the approximate noise cancellation, resulting in trajectory drift, over-sharpening, and artifact degradation, as shown in examples (see Section 3).
Exact Decomposition
The core innovation is the algebraic decomposition of the update into orthogonalized semantic and fidelity-preserving components:
- Steering term (Vsteer): Encodes same-state, cross-prompt velocity difference, isolating the semantic direction induced by prompt transition.
- Fidelity term (Vfid): Encodes same-prompt, cross-state difference, providing source-conditioned stabilization.
The update at each integration step for edit path ztedit becomes:
VΔ(t)=Vsteer(t)+Vfid(t)
Continuous strength modulation is realized as:
VsΔ(t)=Vfid(t)+sVsteer(t)
This scheme maintains the stabilizing effect of source coupling regardless of the editing strength, while the semantic axis is scaled in a controlled linear fashion.
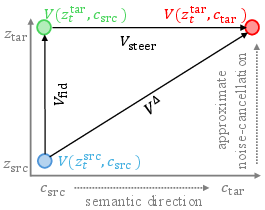
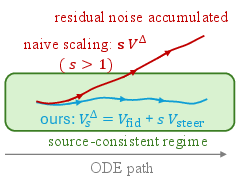
Figure 2: Schematic of exact velocity decomposition into orthogonal steering (semantic) and fidelity (structural) terms and the implication for strength modulation.
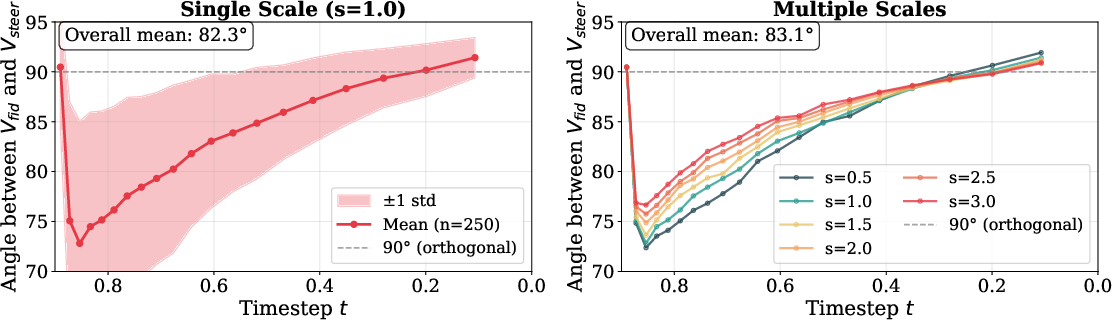
Figure 3: Empirical evidence of near-orthogonality between fidelity and steering terms in benchmark data; angles are concentrated near 90∘, confirming the weak coupling essential to stable decomposed scaling.
Geometric Analysis
FlowSlider's stability is underpinned by weak statistical coupling (near-orthogonality) between the steering and fidelity terms throughout the integration trajectory. The geometric argument shows that scaling only the semantic term increases edit strength without amplifying noise residuals or disturbing the source-state regime, as cross-terms in the norm expansions become negligible. This property is consistently demonstrated empirically (Figure 3).
Experimental Results
Datasets and Benchmarks
Evaluation is conducted on an extensive 250-sample benchmark, drawn from PIE-Bench and richly annotated Pixabay collections, spanning a diverse set of edit classes (season, style, weather, facial attributes, and degradative transformations). For generalization validation, performance is also measured on the broader PIE-Bench suite.










Figure 4: Representative samples from the benchmark indicating the diversity of source–target prompt pairs and editing tasks across 13 categories.
Baselines
Comparisons are made to:
- Learning-based sliders: e.g., Kontinuous Kontext and SliderEdit, which learn explicit strength mappings via supervised or synthetic protocols.
- Training-free/heuristic methods: e.g., classifier-free guidance (CFG) scaling, edit-window tuning, and naive update scaling.
Metrics
Performance is quantified with both semantic and perceptual measures: CLIP-dir (prompt alignment), DreamSim (identity/structure preservation), and slider-behavior metrics (monotonicity, smoothness). The methodological ablation includes naive scaling and linear interpolation alternatives.
Qualitative and Quantitative Analysis
FlowSlider produces consistent, monotonic, and smooth edit paths with significantly reduced structure loss or semantic drift, even at larger strength settings. In comparative qualities, learning-based methods (e.g., Kontinuous Kontext) often saturate rapidly, under-edit, or generate less photorealistic outputs, especially under distribution shift.
Notably, quantitative results on both edit quality (CLIP-dir up to 0.400, DreamSim down to 0.090) and slider behavior (monotonicity >0.83, smoothness <0.01) are superior to both learned and heuristic baselines.
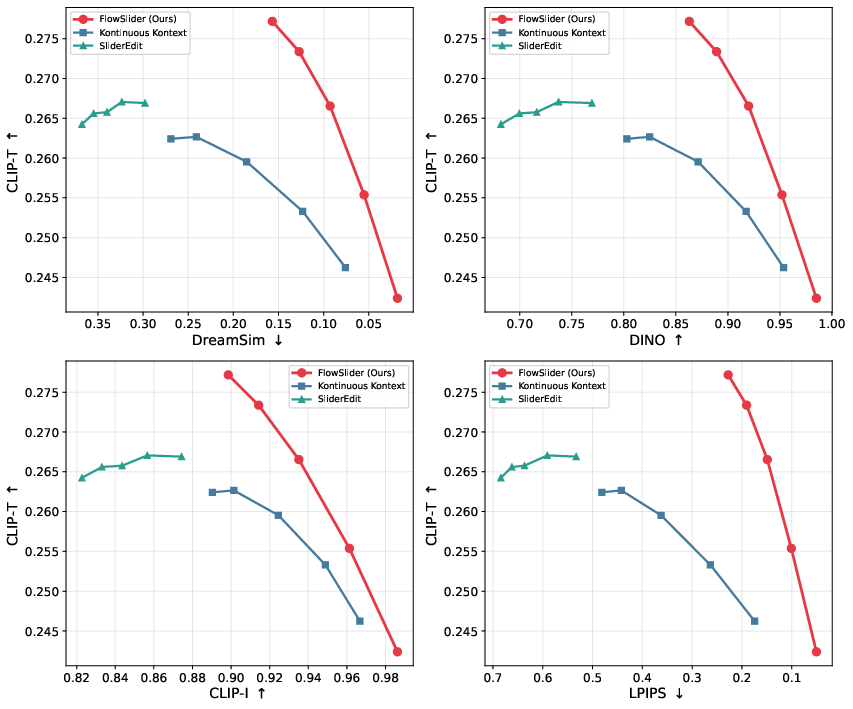
Figure 5: Fidelity–edit strength trade-off; FlowSlider achieves better prompt effect (CLIP-T) for each unit of source-consistency loss than Kontinuous Kontext and SliderEdit, consistently dominating the Pareto front across all evaluated metrics.
Ablation Studies
Naive scaling of the FlowEdit update amplifies all residual components, rapidly producing artifacts and degraded fidelity for sVΔ0. Simple linear interpolation between source and target velocities yields smoother but underpowered, non-monotonic transitions. Only the proposed decomposed formulation simultaneously maintains high alignment, maximal source preservation, and reliable slider behavior.
Practical Implications, Limitations, and Future Directions
FlowSlider enables generic, training-free, continuous-strength control for image editing with rectified flow backbone models, directly supporting flexible human–AI interaction in editing software, creative applications, and exploratory visual workflows. Since it is agnostic to training data or semantic distributions, it can be immediately deployed on all prompt pairs and domains serviced by the backbone model.
The method’s effectiveness, however, is contingent on the prompt embedding geometry: for highly discrete or non-continuous prompt pairs, the edit direction may saturate early, and for extreme scaling, minor nonorthogonality may induce artifacts or structural collapse. This indicates future work may focus on backbone-level regularization to further enforce axis separation or on adaptive, learned term weighting.
Negative strength parameterization naturally produces reverse edits, enabling bidirectional control within the same architecture.
Conclusion
FlowSlider establishes a theoretically driven, empirically validated paradigm for training-free, slider-style continuous image editing in rectified flow models. The fidelity–steering decomposition yields robust monotonic and smooth edit trajectories, consistent semantic control, and superior trade-offs between edit strength and perceptual quality compared to both heuristic and learned alternatives. Its architectural modularity suggests direct extensibility to emerging flow-based backbone models in both research and industry settings (2604.02088).