- The paper introduces a novel continuous image editing framework that uses learnable sliders for precise control over instruction strengths.
- It integrates low-rank adaptation matrices and Partial Prompt Suppression loss to modulate token embeddings for smooth, continuous edits.
- Experiments demonstrate enhanced visual consistency and controllability compared to traditional fixed-strength image editing models.
SliderEdit: Continuous Image Editing with Fine-Grained Instruction Control
Introduction
The paper "SliderEdit: Continuous Image Editing with Fine-Grained Instruction Control" (2511.09715) presents a novel framework aimed at enhancing the user control over image editing models using natural language instructions. Existing instruction-based image editing models apply edits with a fixed strength, which limits the flexibility and interpretability of complex multi-instruction edits. SliderEdit addresses this limitation by implementing fine-grained control over individual instruction strengths, facilitating continuous adjustment via learnable sliders.
The innovation lies in the integration of low-rank adaptation matrices that modulate token embeddings. These matrices generalize across various edits, attributes, and compositional instructions, allowing seamless interpolation along different editing dimensions. The main contributions include the introduction of the Partial Prompt Suppression loss to train these adapters, demonstrating significant improvements in controllability and visual consistency with models like FLUX-Kontext and Qwen-Image-Edit.
Methodology
SliderEdit's methodology centers on enabling fine-grained control over instruction strengths within a multi-instruction prompt. Each instruction can be associated with a slider, allowing users to adjust its influence smoothly. A key insight exploited by SliderEdit is the ability of modern multimodal diffusion transformers (MMDiTs) to encode instruction semantics within localized token embeddings. By modulating these embeddings, SliderEdit achieves precise control over individual instruction effects.
The framework trains learnable low-rank adaptation matrices on token embeddings relevant to the target instruction using the Partial Prompt Suppression (PPS) loss. This loss ensures the model suppresses the visual effect of certain instructions, enabling continuous control by scaling these learned weights dynamically. Additionally, SliderEdit introduces Selective Token LoRA (STLoRA) and Globally Selective Token LoRA (GSTLoRA) for different editing contexts, with GSTLoRA providing global control in single-instruction settings and STLoRA enabling selective modulation of token embeddings.

Figure 1: Instruction-token embedding interpolation for strength control. Interpolating between instruction and null-token embeddings produces intermediate edit strengths, demonstrating the potential for achieving fine-grained control through direct manipulation of intermediate instruction embeddings.
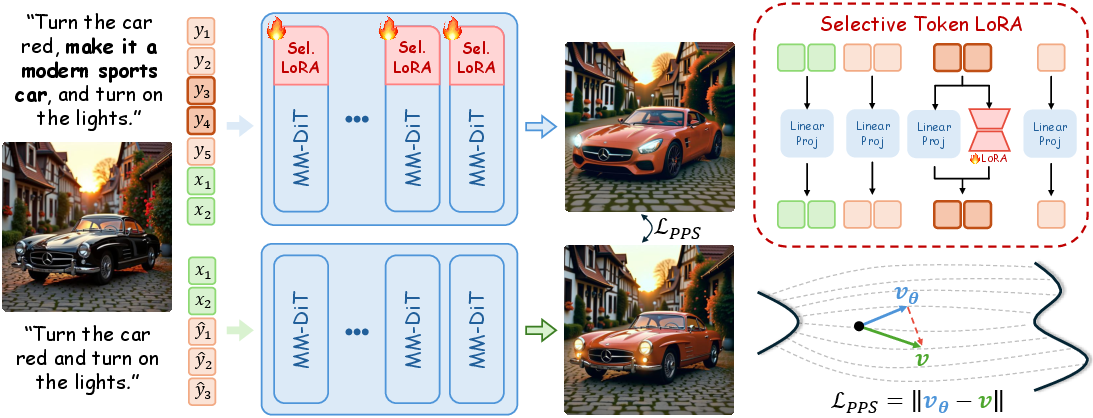
Figure 2: Overview of the SliderEdit training pipeline. Learnable low-rank matrices are applied to the intermediate token embeddings corresponding to the target edit instruction. These adapters are trained using the Partial Prompt Suppression (PPS) loss, which encourages the model to suppress or neutralize the visual effect of the selected instruction tokens.
Experiments
Comprehensive evaluations of SliderEdit across both quantitative and qualitative metrics highlight its robust performance compared to established baselines. The framework is tested using FLUX-Kontext and Qwen-Image-Edit models with results indicating superior edit controllability and semantic disentanglement.
Qualitative Results
Qualitative results underscore the model's ability to provide continuous and precise control over edits. SliderEdit effectively handles various local and global edits, producing smooth transitions without abrupt changes. Notable examples demonstrate the model's capability to modulate both visual and attribute-specific edits seamlessly.

Figure 3: Qualitative Samples of GSTLoRA. Demonstrates smooth, continuous control over the strength of both local and global edits.

Figure 4: Controllable zero-shot multi-subject personalization with STLoRA. STLoRA enables smooth adjustment of each instruction's strength to generate coherent, evolving image sequences, supporting story-like visual editing. (Best viewed from top-left to top-right, then bottom-right to bottom-left)
Quantitative Results
The evaluation set for quantitative analysis involves diverse edit configurations, allowing the assessment of continuity, extrapolation, and disentanglement across various prompt structures. Metrics include vision-LLM embedding similarities and identity preservation measures, with SliderEdit demonstrating robust performance across all metrics compared to other frameworks.
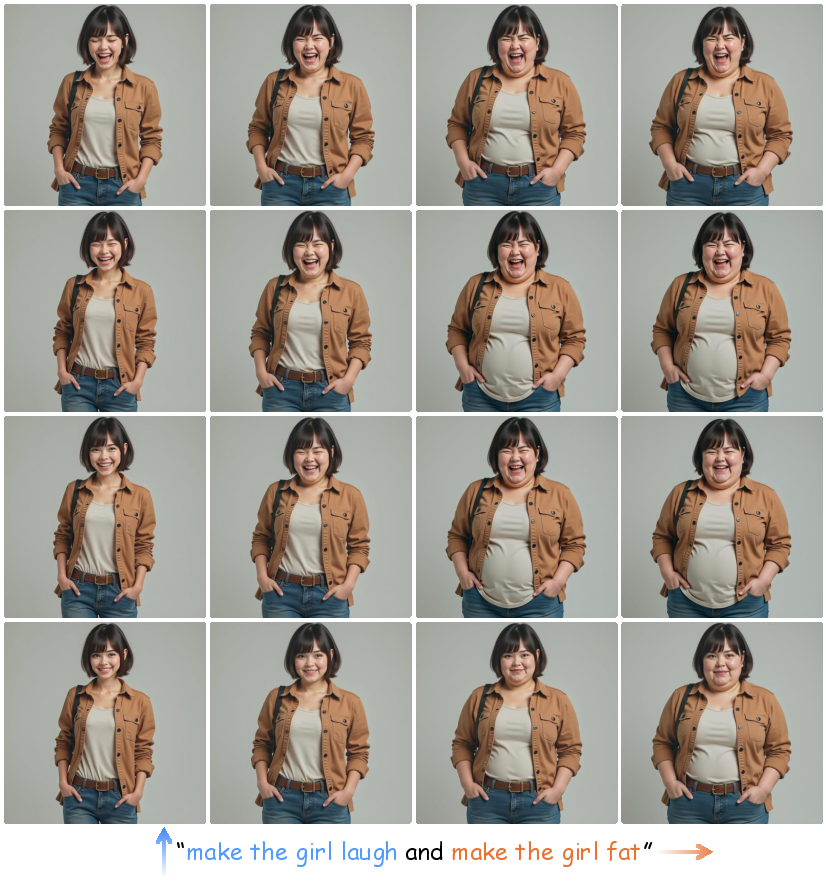
Figure 5: Qualitative results of STLoRA on 2-instruction edit. The 2D grid shows smooth, continuous transitions, allowing precise and disentangled control over each instruction's strength.
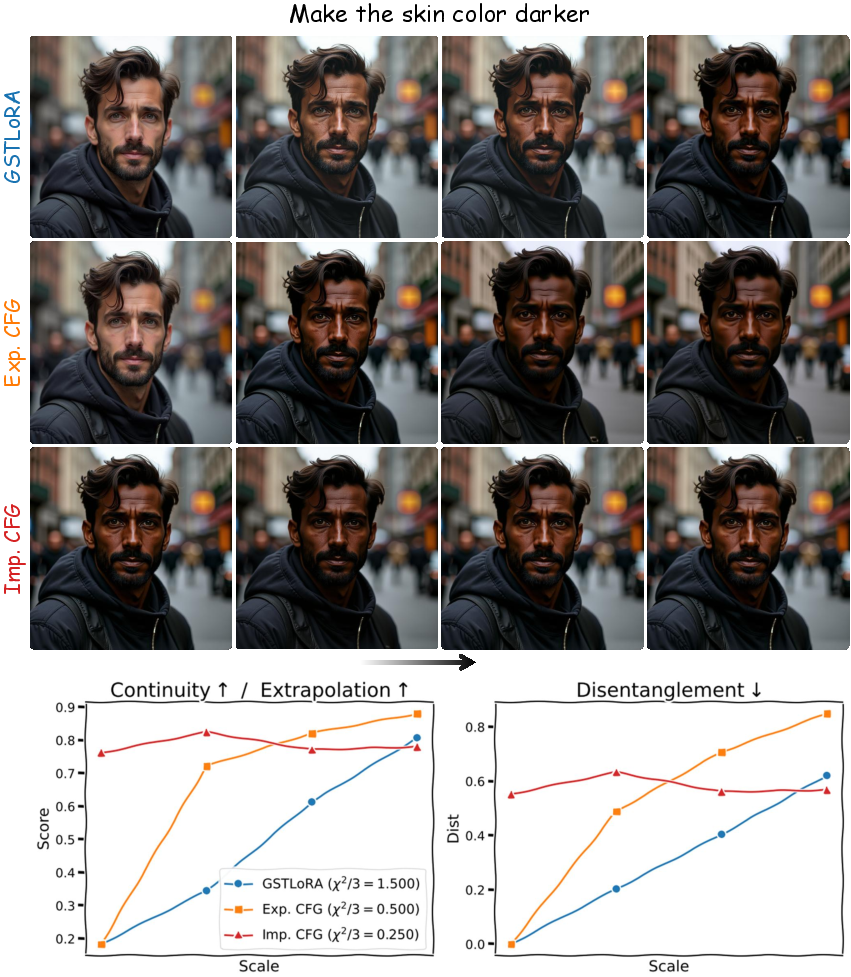
Figure 6: Qualitative and quantitative comparison of GSTLoRA with CFG baselines. GSTLoRA shows smooth edit trajectories with gradual similarity changes, unlike Implicit and Explicit CFG, which exhibit abrupt transitions and greater identity drift.
Conclusion
SliderEdit establishes a unified framework for fine-grained, instruction-based image editing, bridging the gap between discrete application models and user-desired continuous, interactive control. By leveraging low-rank adaptations and PPS loss, it integrates seamlessly with existing models to enhance controllability and coherence in image edits. The demonstrated improvements signal promising directions for future research, particularly in interactive visual storytelling and creative content generation. This foundational contribution paves the way for further exploration into compositional and continuous control mechanisms in machine learning and AI-driven image editing.