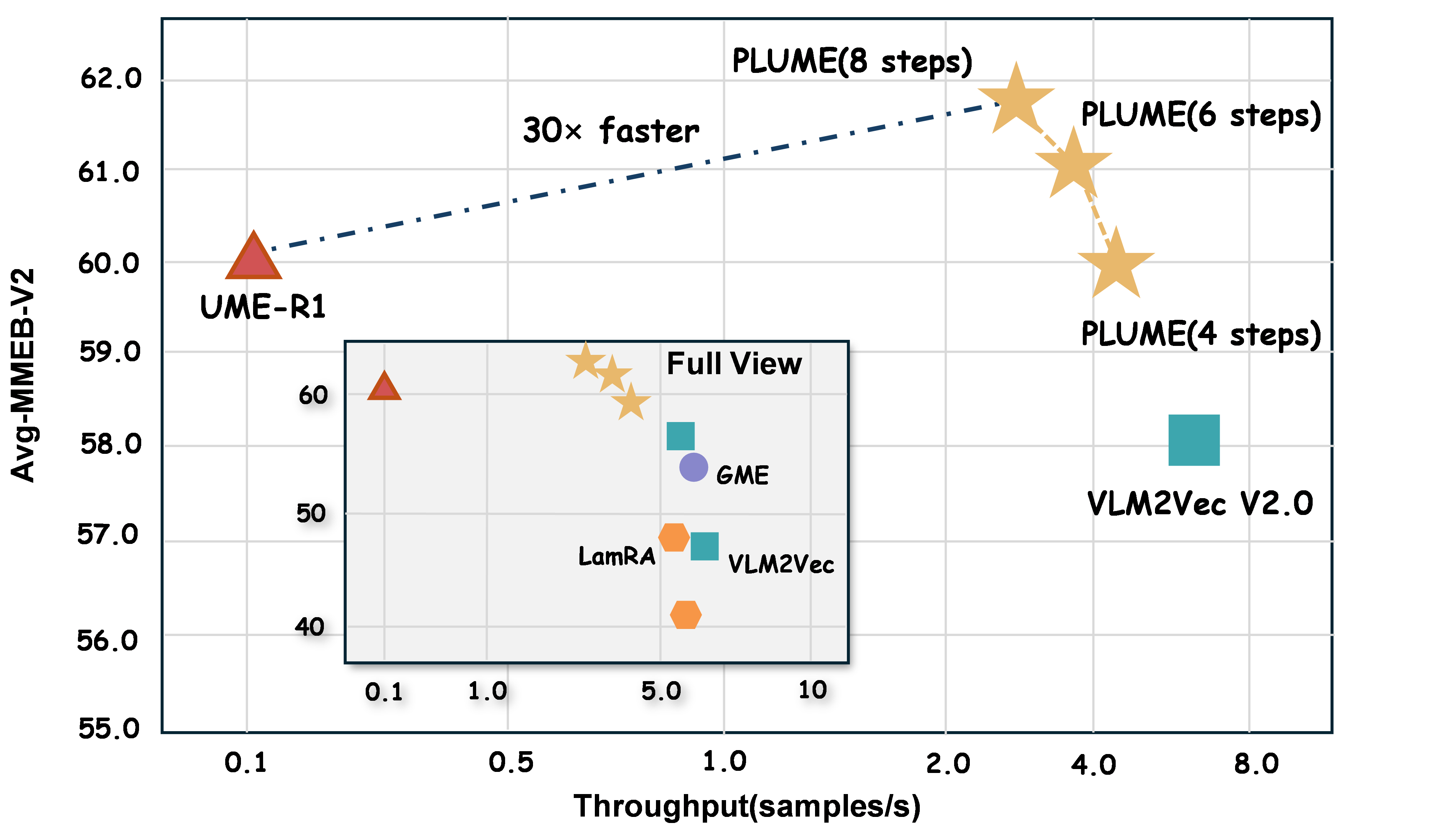
- The paper presents a latent reasoning framework that internalizes chain-of-thought, reducing computational overhead and achieving 30× throughput improvements.
- It introduces semantic-anchor-guided adaptive routing and a progressive explicit-to-latent curriculum to transfer reasoning capabilities efficiently.
- Experimental results on MMEB-v2 demonstrate state-of-the-art accuracy across images, videos, and visual documents, with significant gains in video and document retrieval.
PLUME: Latent Reasoning Based Universal Multimodal Embedding
Introduction and Context
Universal Multimodal Embedding (UME) seeks to project multimodal data—spanning text, images, videos, and visual documents—into a shared, unitary retrieval space using a single model. While the scaling of Multimodal LLMs (MLLMs) has enabled significant advances in UME, existing embeddings predominantly rely on either single-pass encoding or explicit chain-of-thought (CoT) based rationales to enhance reasoning. However, these methods suffer from critical inefficiencies. Discriminative single-pass UME approaches are incapable of explicit reasoning, while CoT-based methods are computationally expensive: they generate hundreds of explicit reasoning tokens per inference and create a bottleneck by forcing rich multimodal information through a narrow text interface.
"PLUME: Latent Reasoning Based Universal Multimodal Embedding" (2604.02073) proposes a novel method that internalizes reasoning as compact latent computation, retaining the compositional reasoning benefits of explicit CoT traces without incurring their inference overhead. To achieve this, the method introduces semantic-anchor-guided adaptive routing, a progressive explicit-to-latent curriculum for knowledge transfer during training, and leverages a mixture-of-experts architecture at the latent reasoning stage. The resulting system establishes new state-of-the-art results on the MMEB-v2 benchmark and provides significant efficiency gains.
Latent Reasoning Framework
PLUME replaces explicit chain-of-thought generation with a recurrent, autoregressive rollout in the model's continuous hidden state space.
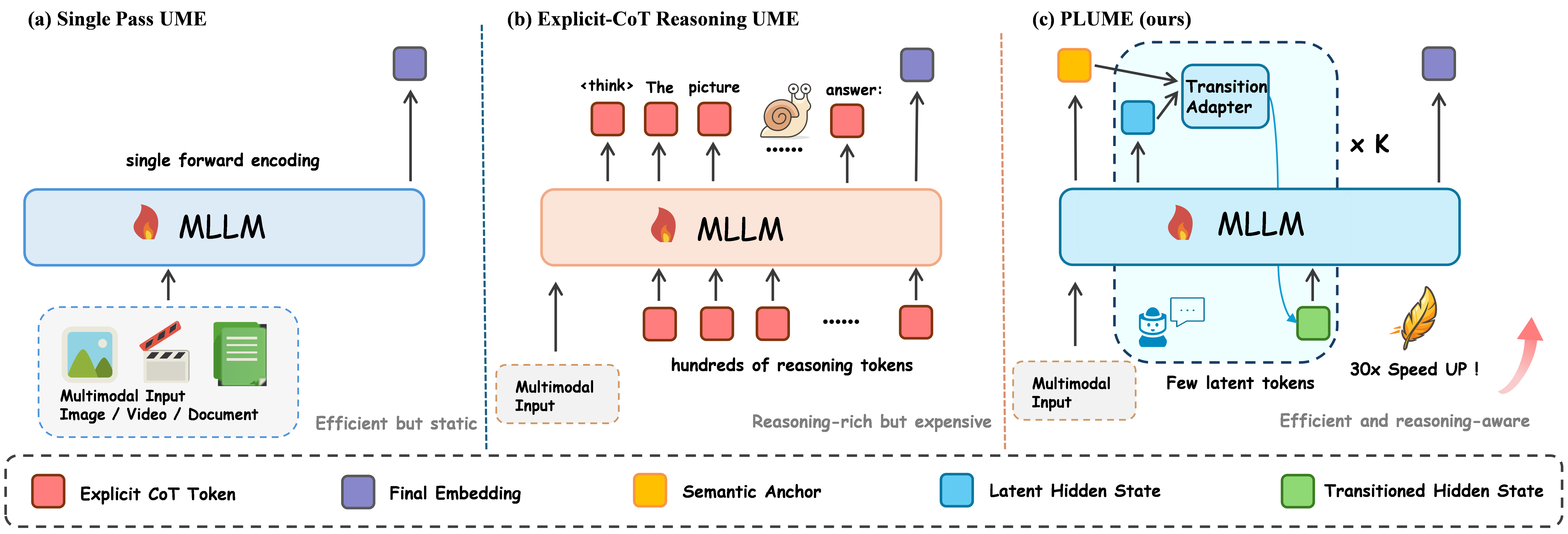
Figure 1: Schematic comparison among (left) traditional one-pass UME, (middle) explicit CoT-enhanced UME, and (right) PLUME's latent rollout with adaptive expert routing.
The core latent reasoning mechanism operates in four distinct phases:
- Multimodal Prefix Encoding: The backbone processes interleaved multimodal input up to a dedicated <slt> (start-latent-thinking) marker. The resulting last-layer vectors serve as the initial condition and semantic anchor for subsequent latent reasoning.
- Latent State Initialization: The latent reasoning state z(0) is set as the final hidden state at <slt>.
- Iterative Latent Rollout: Over K autoregressive steps, the latent state is updated via a routed mixture-of-experts adapter, conditioned on both the evolving state and a fixed semantic anchor. Each new latent state is fed back into the backbone, updating only one position in the causal sequence per step, maintaining full compatibility with transformer cache mechanics.
- Suffix Decoding & Embedding Extraction: Upon rollout completion, the final normalized hidden state at the <gen> marker is used as the retrieval embedding.
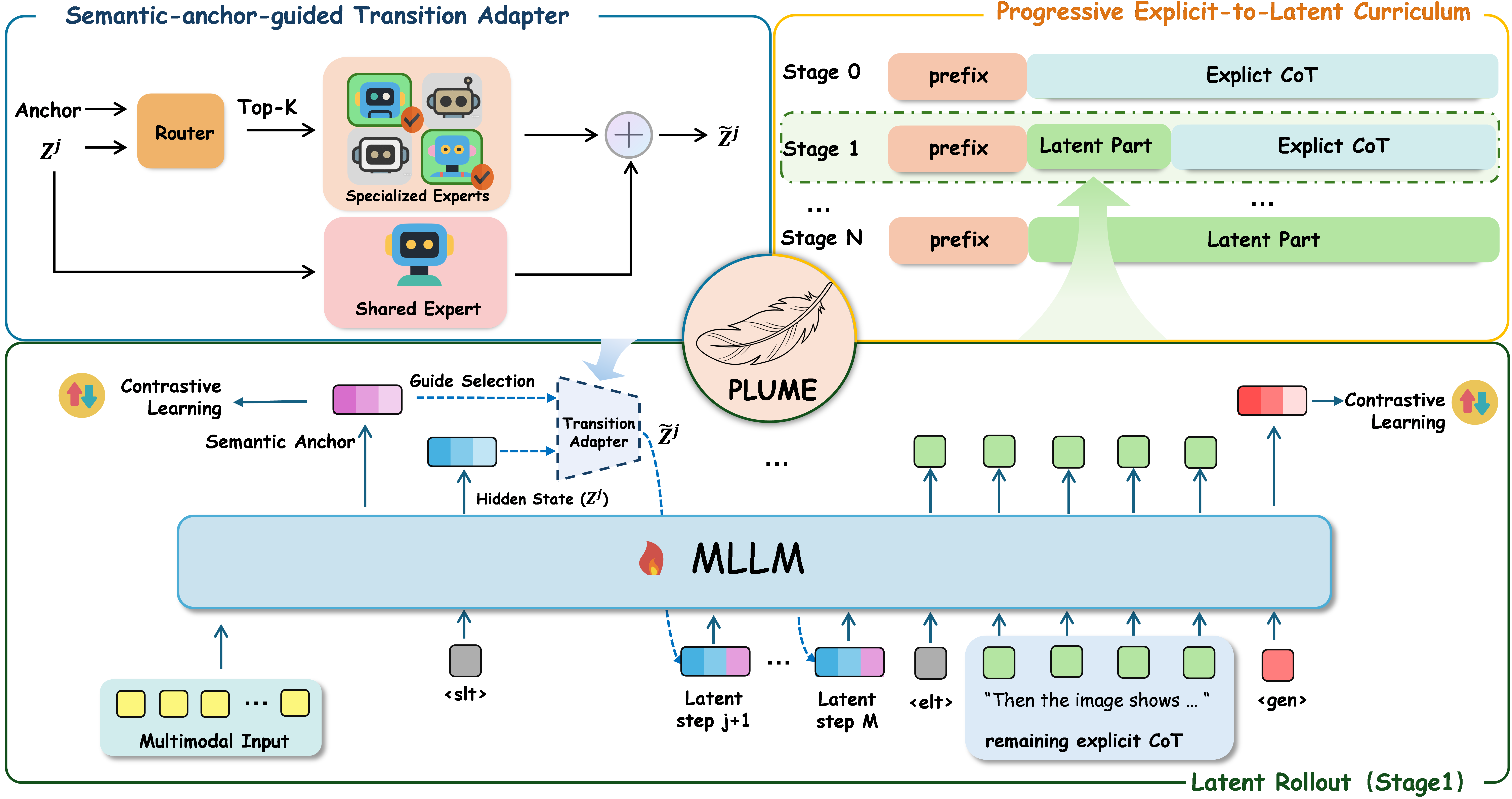
Figure 2: The PLUME method: explicit CoT is replaced by a sequence of K latent transitions, each routed through input- and step-dependent experts, guided by a semantic anchor.
This design ensures that the iterative reasoning capacity of MLLMs is preserved but realized in a highly efficient, non-verbal, latent format.
Semantic-Anchor-Guided Expert Routing
Expressive and adaptive latent reasoning across modalities is achieved by the introduction of a semantic-anchor-guided routed adapter. At each latent step k, the adapter uses a softmax router over step-embeddings and a summary "anchor" of the multimodal prefix to select the top-Kr experts from a set of Me experts. These experts, implemented as lightweight two-layer MLPs, facilitate specialization across tasks and input modalities without making the backbone itself a mixture-of-experts system. Routing balance is enforced via a regularizer on the expert-selection probabilities, ensuring specialization without collapse.
Empirical analysis demonstrates substantial allocation diversity between video and image sub-tasks, with experts specializing (unsupervised) for object grounding, temporal classification, or QA.
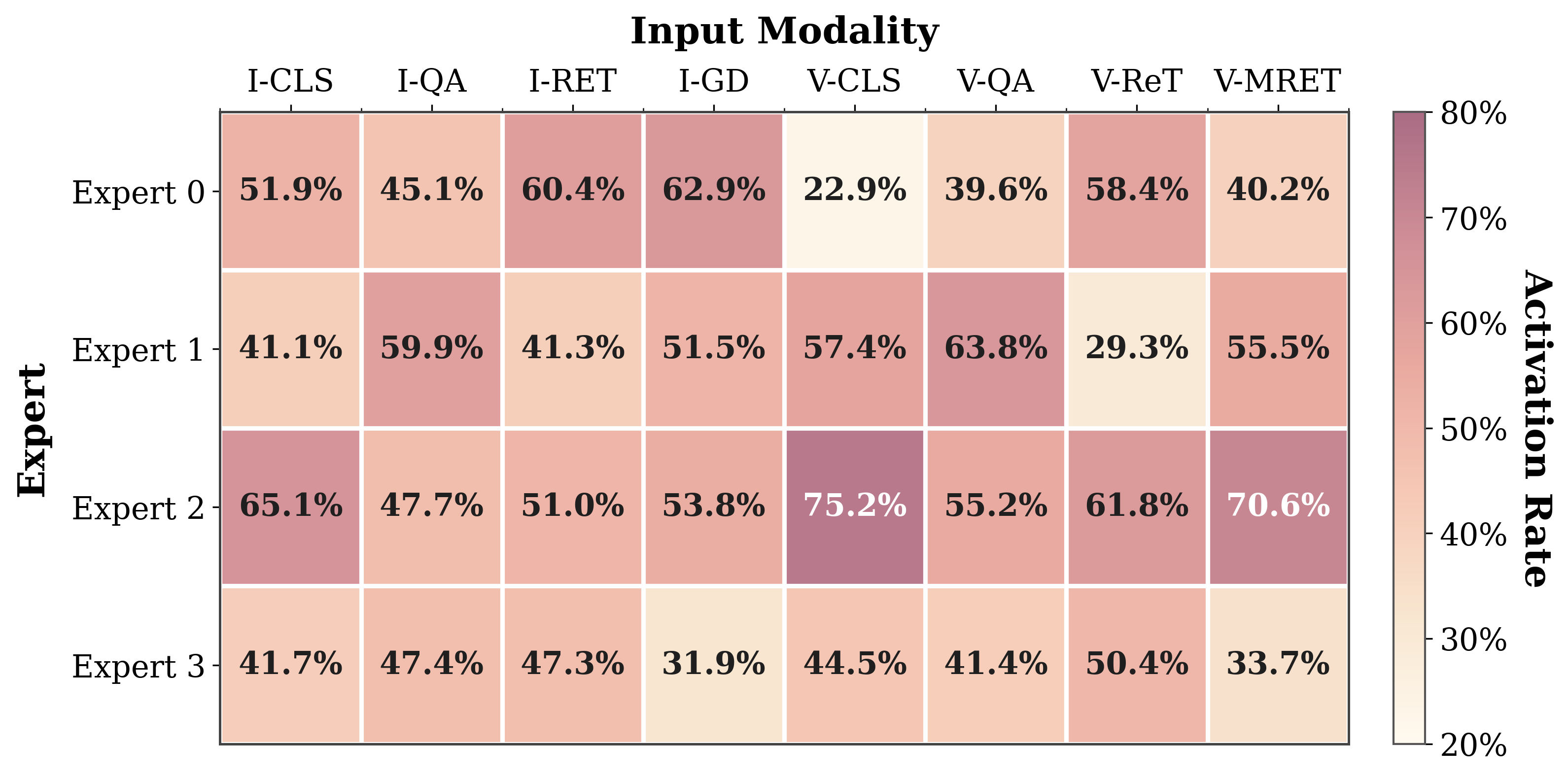
Figure 3: Activation rates of each specialized expert across video and image retrieval sub-tasks, revealing strong input-adaptive specialization.
Progressive Explicit-to-Latent Curriculum
Directly training the model to perform all reasoning purely in the latent space is ineffective due to instability and shortcut solutions. PLUME adopts a progressive explicit-to-latent curriculum:
- Training begins with explicit CoT rationales as teacher-forced tokens.
- Reasoning segments are gradually replaced by latent blocks, from left to right.
- Supervision remains on any unconverted explicit tokens and the answer, providing a bridge for semantic transfer into the latent space.
- In the final curriculum stage, all explicit reasoning is elided and the model generates only latent reasoning steps before producing the generative embedding.
This curriculum design is critical for model stability, effective reasoning transfer, and the resulting empirical performance.
Experimental Results
PLUME is evaluated on MMEB-v2, a 78-task benchmark covering images (classification, QA, grounding, retrieval), videos (classification, QA, retrieval), and visual documents (retrieval, OOD). All models use the Qwen2-VL-2B backbone and identical fine-tuning data for parity with baselines.
Main empirical findings:
Per-task and per-modality analysis demonstrates that the largest gains occur on tasks with structurally complex, dense, or temporally dependent evidence (e.g., video multi-modal retrieval, visual document OOD). Ablations confirm the essentiality of both the curriculum and adaptive expertise in all settings.
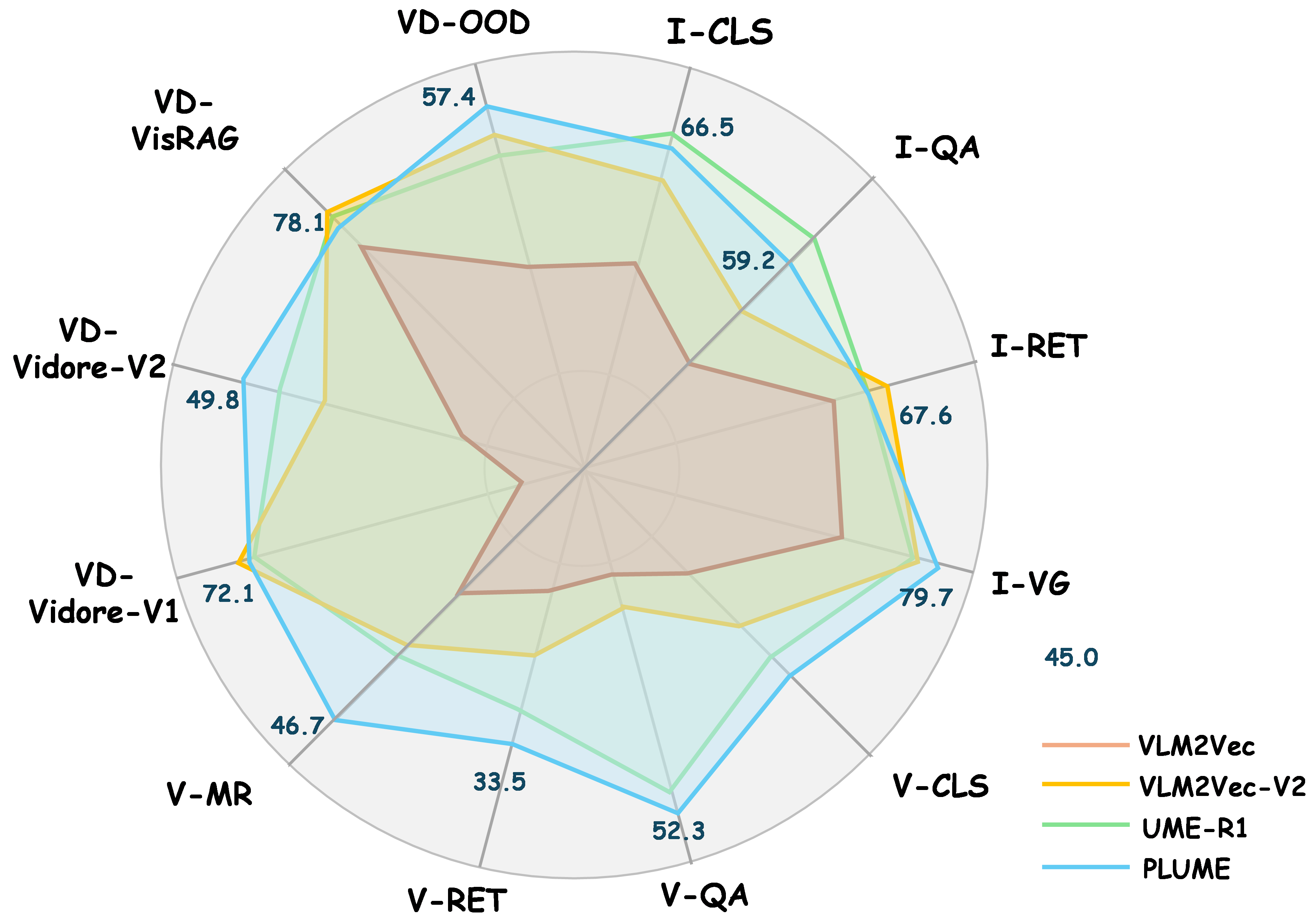
Figure 5: Sub-task accuracy breakdown, confirming PLUME’s consistent advantages, especially on video and visual document modalities.
Trajectory analysis reveals smoother and more stable latent reasoning dynamics in PLUME compared to explicit CoT methods. However, for text-rich or fine-grained knowledge-dependent image QA, explicit reasoning occasionally confers small advantages—highlighting a limitation and direction for future research in latent reasoning transfer.
Theoretical and Practical Implications
PLUME's architectural choices have significant implications:
- Efficiency: Demonstrates that highly capable, reasoning-aware universal embeddings for multimodal data do not require explicit rationale generation, invalidating the assumption that multi-step computation requires high-latency token-level CoT.
- Input-Adaptive Computation: The semantic-anchor-guided MoE architecture is highly efficient, scalable, and enables automatic expertise discovery for diverse query structures—directly addressing the heterogeneity challenge in UME.
- Latent Reasoning: By decoupling reasoning from explicit tokens, PLUME opens the possibility of continuous, compressed, and even hardware-optimized reasoning loops for large-scale retrieval and complex agentic systems.
- Training Protocols: The progressive curriculum strategy for CoT-to-latent transfer is likely extensible to other generative-modeling and embedding tasks where latent intermediate computation is desired.
Future Research Directions
- Interpretability: While task-specialized expert activation is observed, formal techniques for interpreting continuous latent reasoning remain underdeveloped. Connecting latent step trajectories with semantic concepts and sub-task structure is a key open challenge.
- Generalization to Ultra-Long or Interactive Reasoning: Scaling up the length of the latent rollout, or using recurrent interactive feedback for multi-turn agentic retrieval, would further expand the capabilities of latent reasoning systems.
- Toolkit Integration: Bridging with retrieval-augmented generation (RAG) or tool-augmented agents could benefit from latent, rather than explicit, reasoning pipelines.
- Modality Expansion: While PLUME is validated on images, video, and documents, similar architectures could be extended to audio, 3D, and beyond—where single-pass or tokenized CoT are particularly limiting.
Conclusion
PLUME represents a substantive advancement in universal multimodal embedding by embedding intermediate reasoning steps as efficient, input-adaptive latent transitions. It achieves superior accuracy–efficiency tradeoffs relative to both discriminative and explicit-CoT UME approaches, particularly excelling in structurally complex retrieval domains like video and visual documents. The core methodologies—the latent rollout, semantic-anchor-guided routing, and progressive explicit-to-latent curriculum—not only operationalize efficient latent reasoning but offer promising directions for the next generation of large-scale, unified retrieval and agentic systems.