- The paper provides a comprehensive evaluation of analytic and bootstrap methods, highlighting the limitations of CV1 and the improved reliability of CV3 in cluster-robust inference.
- It employs a linear regression model with one-way clustering and uses Monte Carlo simulations and placebo tests to assess reliability under varying cluster sizes and heterogeneity.
- The study emphasizes the importance of rigorous diagnostic routines and alternative CRVE methods to mitigate risks from small cluster counts, heterogeneity, and misclassification.
Trustworthy Cluster-Robust Inference: Scope and Limits
Context and Motivation
Cluster-robust inference is pervasive in empirical microeconometrics, typically adopted to accommodate arbitrary within-cluster correlation while maintaining independence across clusters. Despite its ubiquity, rigorous guarantees for the reliability of cluster-robust procedures are scarce, especially in finite samples or under severe cluster heterogeneity. The question central to this work is: Under what conditions and using which procedures can researchers genuinely trust cluster-robust inference? The paper comprehensively surveys analytic and bootstrap-based approaches, provides technical diagnostics, and evaluates inferential reliability through empirical applications and simulation experiments.
Models, Estimators, and Asymptotics
The analysis is anchored in the linear regression model with one-way clustering. The OLS estimator, β^, depends on stacked cluster-level score vectors, whose cross-cluster independence is crucial for asymptotic validity. The true variance matrix is the classical sandwich form but must be estimated via cluster-robust variance estimators (CRVEs).
The paper identifies three primary CRVEs:
- CV1 (the default): Widely used, but vulnerable to unreliable inference, especially as G (number of clusters) diminishes or cluster heterogeneity rises.
- CV2: Analogous to HC2, features unbiased diagonal elements under i.i.d. disturbances; however, unbiased variance alone does not guarantee t-distribution of the test statistic.
- CV3 (jackknife): Demonstrated to yield more reliable inferences and always more conservative than CV1; forms the basis for modern diagnostics and adjustment procedures.
Inference conventionally proceeds via t-statistics compared to an assumed t(G−1) distribution (following [BCH_2011]). Some methods additionally calculate custom degrees-of-freedom and bias scaling factors for each coefficient, notably via Hansen's procedure.
Bootstrap Inferential Procedures
Bootstrap methods often improve reliability, especially in settings with few or varied clusters:
- Pairs Cluster Bootstrap (PCB): Resamples clusters; may fail with heterogeneous cluster sizes or leverage—bootstrap samples can differ markedly from the original.
- Wild Cluster Bootstrap (WCB): Generates bootstrap samples by multiplying empirical score vectors by Rademacher random variables; the WCR-S variant further corrects for least-squares distortions using jackknife estimates. WCB variants offer superior finite-sample properties and are computationally tractable.
Sources of Unreliability
The paper systematically details conditions leading to unreliable inference:
- Small 10: Asymptotics are driven by cluster count, not sample size; fewer clusters amplify estimator variance.
- Cluster heterogeneity: Variability in 11, leverage, treatment status, or disturbance distributions exacerbates size distortions.
- Few treated clusters: Even with moderate 12, small 13 (treated) or 14 (control) sharply impairs inference reliability.
- Incorrect clustering assignments: Nested or misspecified clusters undermine all analytic and bootstrap approaches.
Diagnostics and Assessment Methods
A suite of diagnostics is advocated:
- Partial leverage and scaled variance: Quantify heterogeneity across clusters and highlight influential clusters.
- Effective number of clusters (15): Provides an interpretable bound on reliability.
- Cluster-level residual variance and heteroskedasticity: Tests for treatment-related heteroskedasticity.
- Jackknife estimates (16): Identify influential clusters whose omission leads to large parameter changes.
Reliability can be empirically evaluated through:
- Targeted Monte Carlo experiments: Simulate data using the exact regressor matrix and cluster configuration, varying disturbance specifications.
- Placebo regressions: Substitute or add placebo regressors that mimic the regressor structure of interest but have no genuine effect.
Empirical Applications
Two applications—female role models in economics and diversity in Delhi schools—highlight the complexity of inference with clustered data:
- For small numbers of clusters or treated clusters, analytic and bootstrap methods can yield contradictory inferences.
- Simulation and placebo experiments confirm that standard procedures based on CV17 and 18 often over-reject, and reliance on bootstrap or jackknife methods is warranted—provided diagnostics indicate sufficient cluster homogeneity.
Monte Carlo rejection frequencies as functions of intra-cluster correlation (19) further illustrate these reliability issues.
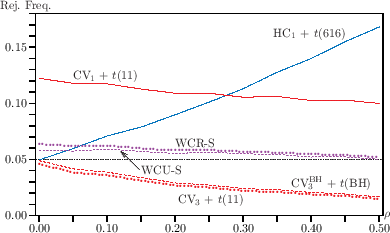
Figure 1: Monte Carlo rejection frequencies as functions of G0 highlight the divergence in rejection behavior among inferential procedures as intra-cluster correlation changes.
Practical and Theoretical Implications
Practically, the paper suggests rigorous diagnostic routines and simulation-based checks before adopting cluster-robust methods. Reliance on CVG1 and G2 must be carefully justified; otherwise, CVG3, Hansen's adjustments, or WCB (especially WCR-S) bootstrap are preferable.
Theoretically, the results reinforce that cluster-count asymptotics are the key driver of inferential validity, urge caution with heterogeneous clusters, and reinforce the value of simulation-based evaluation and placebo analysis for empirical applications.
Future Directions
Potential directions include formalizing testing for clustering dimension, generalizing diagnostics for two-way or higher clustering, and developing fast computational methods for large-regressor or cluster datasets. Further, exploration of genuinely robust inference under severe heterogeneity and treatments with few clusters remains critical.
Conclusion
The paper delivers a rigorous framework for evaluating cluster-robust inference, articulates specific limits, and provides actionable diagnostics. Researchers are advised to critically scrutinize cluster configuration, leverage heterogeneity, and adopt simulation-based validation. While no method is universally reliable in all settings, combining diagnostics with advanced CRVE or bootstrap approaches yields results in which reasonable confidence may be placed (2604.02000).