- The paper introduces PI-VQ, a permutation-invariant autoencoder that decouples semantic features from pixel-level spatial cues.
- It employs a matching quantization strategy to maximize codebook utilization and enhance representation capacity by approximately 3.5×.
- The architecture supports smooth interpolation and compositional image synthesis, enabling efficient exploration of global latent features.
Permutation-Invariant Discrete Representation Learning for Aligned Images
Introduction and Motivation
This work introduces a permutation-invariant vector-quantized autoencoder (PI-VQ) for spatially aligned image representation learning, targeting the deficiencies of existing discrete methods (e.g., VQ-VAE, VQ-GAN) in interpretability, semantic consistency, and direct control. By enforcing that discrete latent codes encode no position information, the architecture encourages the extraction of global, semantic attributes, decoupling the representation from pixel-local spatial dependencies—a critical advantage for datasets such as CelebA, CelebA-HQ, and FFHQ, where alignment is assured and many features are inherently global.
The key contributions are:
- The formulation of a permutation-invariant discrete bottleneck (PI-VQ).
- Introduction of a matching quantization algorithm that greatly increases effective information capacity.
- Demonstration of efficient O(1) interpolation-based sampling without a dedicated prior.
- Analysis of the semantic and separable nature of the learned codes.
Architectural Framework
PI-VQ rethinks the VQ-family architecture by suppressing positional cues in the latent space. The forward pipeline comprises:
- Encoder: A stack of convolutions followed by transformer blocks that produce a set of L latent embedding vectors, stripped of spatial positional embeddings.
- Quantizer: Each latent vector is quantized by discrete assignment to a codebook entry. To address representation redundancy and increase capacity, matching quantization is introduced, ensuring each codebook element is used at most once per image.
- Decoder: Receives the unordered set of quantized codes and reconstructs the image, being invariant to code permutation due to architectural design (not using positional embeddings at decoding).
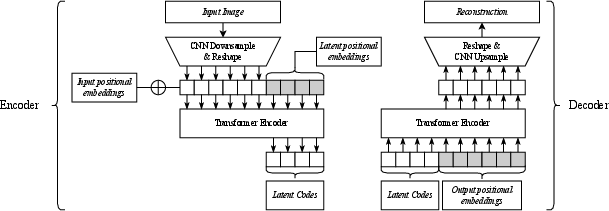
Figure 1: The PI-VQ encoder and decoder structure, explicitly omitting positional embeddings before decoding to ensure permutation-invariance.
This position-free latent organization compels the encoder to focus on capturing semantic features while mapping away spatial details.
Matching Quantization: Increasing Bottleneck Capacity
A core technical innovation is the optimal bipartite matching-based quantization. Unlike standard nearest-neighbor VQ—which often assigns multiple latents to the same codebook entry, collapsing the bottleneck and reducing codebook usage—matching quantization solves an assignment problem (Hungarian algorithm) ensuring code uniqueness per image, as long as codebook size K≥L. This directly addresses latent representation redundancy and boosts capacity by approximately 3.5×, as demonstrated empirically.
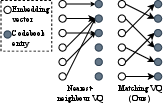
Figure 2: Matching quantization prevents redundant code assignments, maximizing per-image codebook utilization and enhancing information capacity.
Capacity analysis shows the upper bounds for PI-VQ (with matching quantization) approach those available to a standard VQ bottleneck of similar parameterization, justifying the information-theoretic adequacy of the approach.
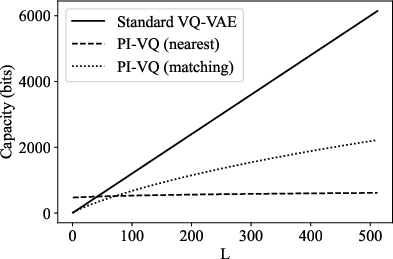
Figure 3: Theoretical information capacity as a function of latent length for different quantization configurations; matching quantization achieves near-maximal capacity within the PI-VQ constraint set.
Interpolation-Based Sampling and Compositionality
Permutation-invariant, discrete code structure enables systematic interpolation and recombination of semantic traits across images. By generating new latent sets via set operations (intersection, symmetric difference, controlled replacement), PI-VQ supports both stochastic and (approximately) smooth interpolation without any explicit prior, all via a single forward pass.

Figure 4: Smooth interpolations in the latent code space, visualizing plausible semantic transitions between source images.
This combinatorial flexibility supports dense sample space coverage and the creation of novel, semantically plausible images, echoing the compositional aspirations found in disentanglement literature. The number of unique interpolation paths is combinatorially large, contributing to output diversity.
Empirical Analysis of Bottleneck Efficiency
Experiments on CelebA, CelebA-HQ, and FFHQ validate the claims:
- Nearest-neighbor quantization on a PI-VQ bottleneck typically results in severe codebook under-utilization (max per-image code usage ≈ 49/512).
- Matching quantization attains the theoretical maximum (L codes per image), yielding a bottleneck of 2221 bits—comparable with state-of-the-art VQ-GANs.
Sample Quality and Semantic Structure
Quantitative evaluation, including FID, precision, recall, density, and coverage, positions PI-VQ as competitive in precision, density, and coverage on aligned faces, exceeding or approaching leading GAN/diffusion models in some respects. However, recall and FID lag, indicating mode dropping and limitations in fine-grained, rare feature capture, likely stemming from the constraints of permutation invariance and remaining information bottlenecks.
To analyze semantic content, logistic regression on binarized latent codes is used to predict ground-truth FFHQ annotations. Codes prove linearly predictive for several human-interpretable attributes (e.g., gender, happiness, eye makeup), but less so for some, revealing partial but not universal disentanglement.
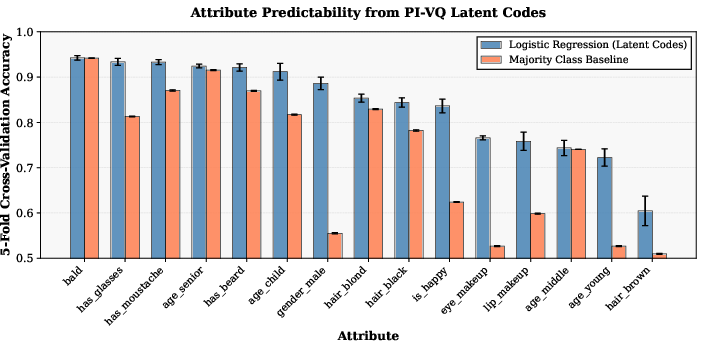
Figure 5: Attribute predictability of PI-VQ codes, showing substantial linear separability for several semantic features versus a majority-class baseline.
Practical and Theoretical Implications
Permutation-invariant discrete representation learning:
- Facilitates direct semantic manipulation, enabling rapid exploratory synthesis and controllable generative modeling for aligned datasets.
- Supports interpretability and global code semantics, useful for model analysis, feature attribution, and downstream tasks requiring global factors.
- Reduces reliance on complex generative priors, accelerating sampling and enabling more efficient exploration of the latent space.
The cost is diminished spatial fidelity and weaker capture of fine-grained details, imposing a trade-off between semantic compositionality and pixel-level diversity. For applications where spatial alignment and semantic abstractions are sufficient (e.g., face synthesis, style transfer, robust feature extraction), this is an acceptable and sometimes desirable trade-off.
Limitations and Future Directions
While matching quantization alleviates the worst bottleneck effects, the fundamentally reduced capacity of permutation-invariant codes cannot be entirely overcome. Certain attributes (fine spatial features, rare combinations) remain poorly captured.
Future work may benefit from:
- Enhanced codebook management (to further mitigate collapse and maximize codebook coverage).
- Strategies combining permutation-invariant with locally-aware representations, integrating the best aspects of both approaches.
- Application to other modalities (audio, structured tabular data) and other spatially-aligned domains.
- Systematic investigation of the trade-off between globality and locality in discrete bottlenecked models.
Conclusion
The PI-VQ architecture presents a compelling alternative to position-dependent discrete encodings for the case of spatially aligned images. The combination of permutation-invariant latent spaces and matching quantization yields interpretable, compositional, and semantically meaningful representations that facilitate direct and efficient interpolation-based image synthesis. While there are trade-offs in fidelity and recall, the practical and theoretical affordances for interpretable, memory-efficient generative modeling are substantial, especially in aligned data regimes.
Reference: "Investigating Permutation-Invariant Discrete Representation Learning for Spatially Aligned Images" (2604.01843)

