Product-Quantised Image Representation for High-Quality Image Synthesis
Abstract: Product quantisation (PQ) is a classical method for scalable vector encoding, yet it has seen limited usage for latent representations in high-fidelity image generation. In this work, we introduce PQGAN, a quantised image autoencoder that integrates PQ into the well-known vector quantisation (VQ) framework of VQGAN. PQGAN achieves a noticeable improvement over state-of-the-art methods in terms of reconstruction performance, including both quantisation methods and their continuous counterparts. We achieve a PSNR score of 37dB, where prior work achieves 27dB, and are able to reduce the FID, LPIPS, and CMMD score by up to 96%. Our key to success is a thorough analysis of the interaction between codebook size, embedding dimensionality, and subspace factorisation, with vector and scalar quantisation as special cases. We obtain novel findings, such that the performance of VQ and PQ behaves in opposite ways when scaling the embedding dimension. Furthermore, our analysis shows performance trends for PQ that help guide optimal hyperparameter selection. Finally, we demonstrate that PQGAN can be seamlessly integrated into pre-trained diffusion models. This enables either a significantly faster and more compute-efficient generation, or a doubling of the output resolution at no additional cost, positioning PQ as a strong extension for discrete latent representation in image synthesis.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to store and rebuild images inside AI models so they can make high-quality pictures faster and more efficiently. The authors introduce PQGAN, which uses a method called product quantization (PQ) inside a popular image model framework (VQGAN). Their goal is to keep images looking sharp and detailed while using less computer power, and to plug this into big image generators like Stable Diffusion.
Key Questions and Goals
The paper asks:
- Can we store image information in a smarter, compact “shorthand” that still lets us reconstruct images with very high quality?
- Does product quantization (splitting information into smaller parts) work better than standard vector quantization (treating everything as one big chunk)?
- How do different settings—like how many parts we split into, how big the “dictionary” is, and how many channels we use—change image quality?
- Can this new representation be easily connected to diffusion models (like Stable Diffusion) to make images faster or at higher resolution without extra cost?
Methods and Approach
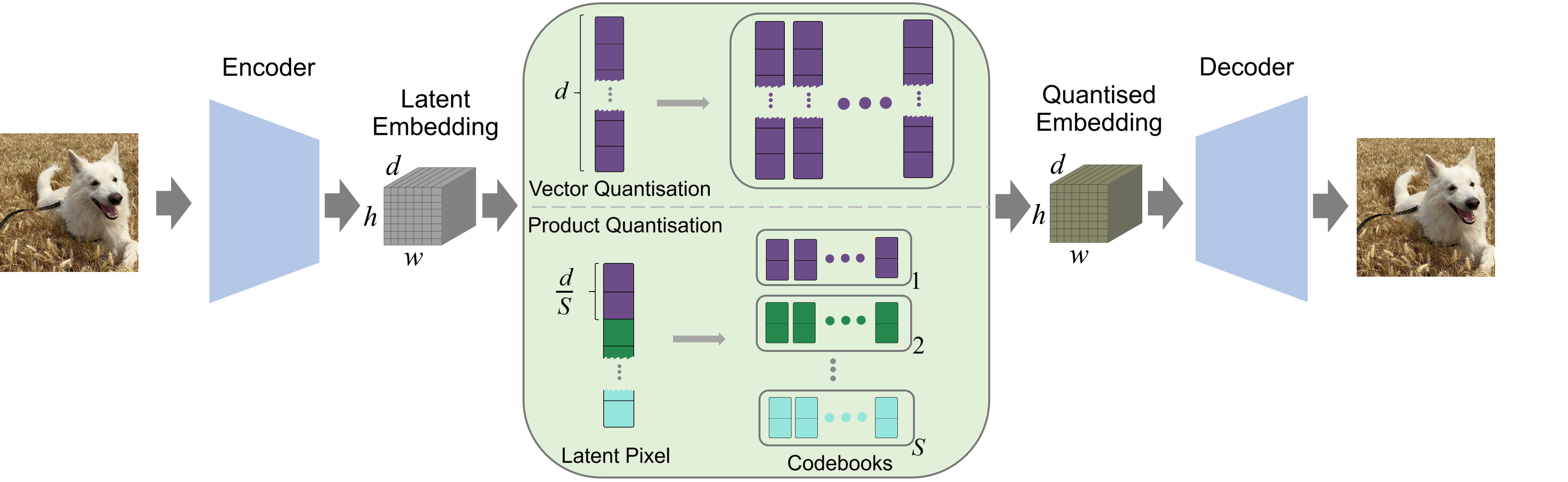
Think of images as being turned into a secret compact language inside the model, called a “latent space.” An autoencoder is the tool that does this: the encoder compresses the image into a code, and the decoder turns the code back into the image. The trick is how we store that code.
- Vector quantization (VQ): Imagine a single big dictionary of patterns. For each piece of the compressed image, you look up the closest matching pattern in the dictionary and store its index. This works, but with very large, complex patterns, the dictionary is hard to learn and can get messy.
- Product quantization (PQ): Instead of one big dictionary, split each pattern into smaller parts and give each part its own small dictionary. Like organizing LEGO pieces into separate bins (bricks, plates, wheels) instead of one giant mixed bin. You pick one piece from each bin and snap them together. This makes it easier to learn, faster to match, and creates many combinations without needing to store every full combination.
How the authors tested it:
- They kept the standard VQGAN design but swapped in PQ for the quantization step.
- They explored different settings:
- d: how many channels the compressed code has (like how many “features” the latent code can carry).
- S: how many subspaces or bins they split into (how many parts they break each code into).
- K: how many entries each small dictionary has (the number of pieces in each bin).
- They measured results using common image quality scores:
- PSNR (higher is better; means the reconstruction is closer pixel-by-pixel),
- FID, LPIPS, and CMMD (all lower is better; these measure perceptual quality and similarity).
- They also connected PQGAN to Stable Diffusion and adjusted only the first and last layers to handle the higher number of channels, then fine-tuned briefly so it could generate images from PQ latents.
Main Findings and Why They Matter
The authors found several important things:
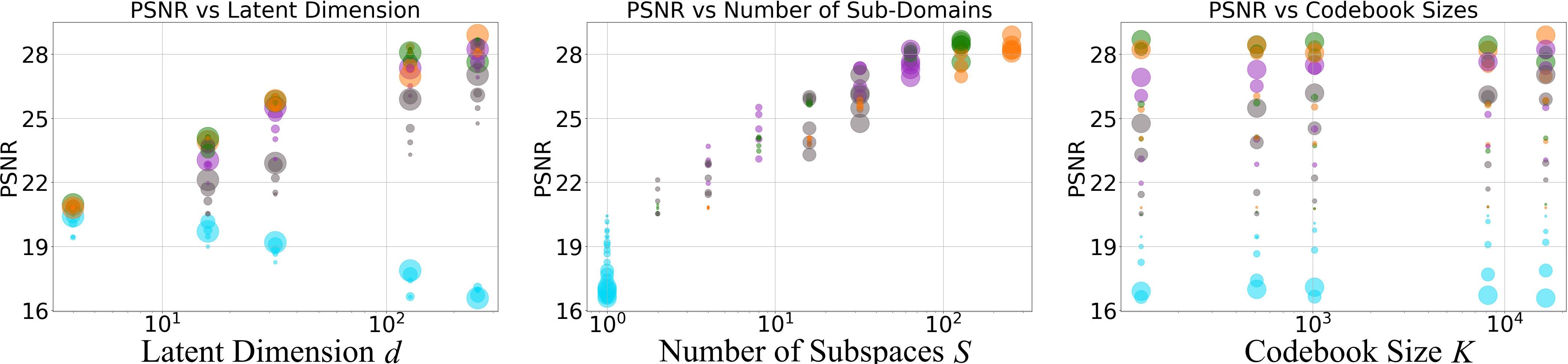
- PQ beats VQ and even continuous methods on image reconstruction.
- With PQGAN, they achieved PSNR up to about 37.4 dB on ImageNet, compared to prior results around 27 dB.
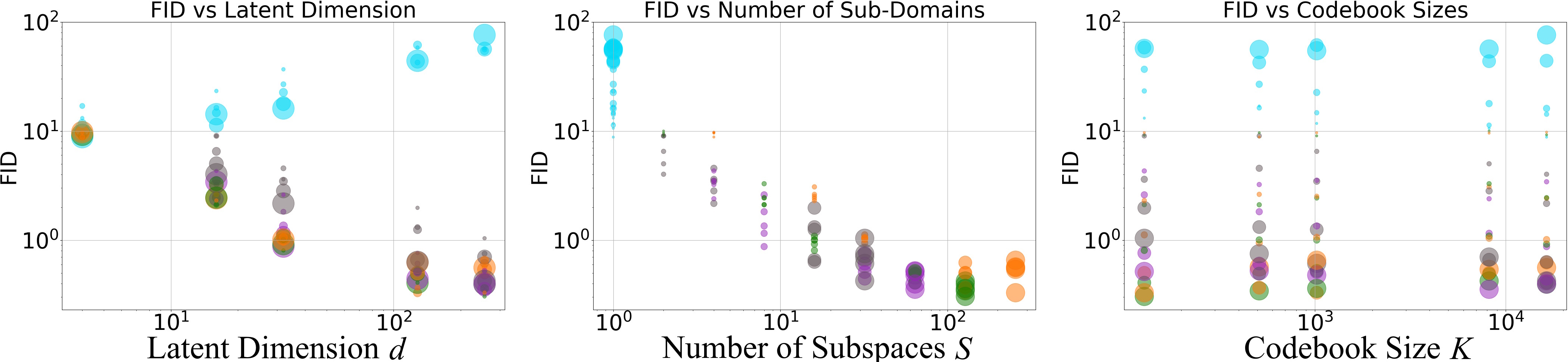
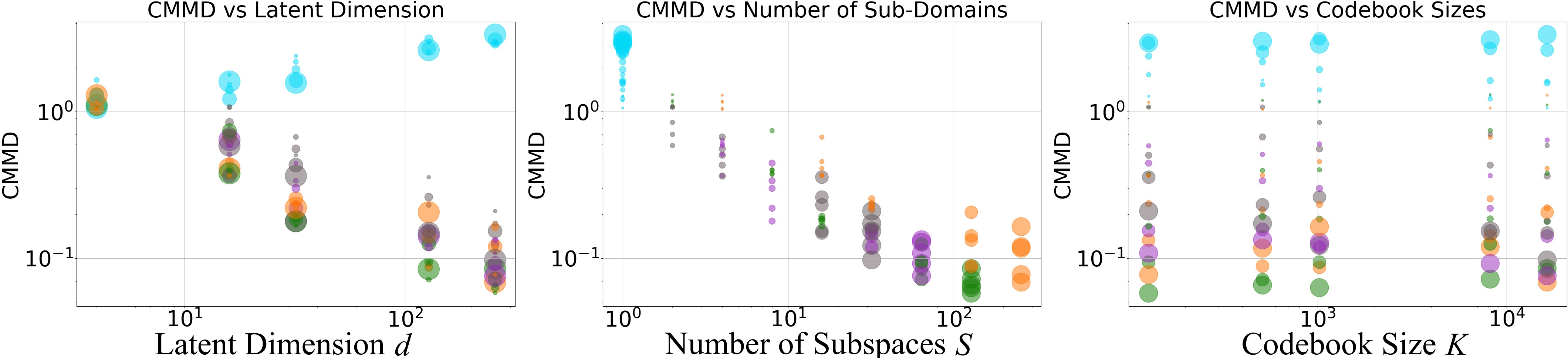
- They reduced FID, LPIPS, and CMMD by up to 96%, meaning images looked extremely close to the originals.
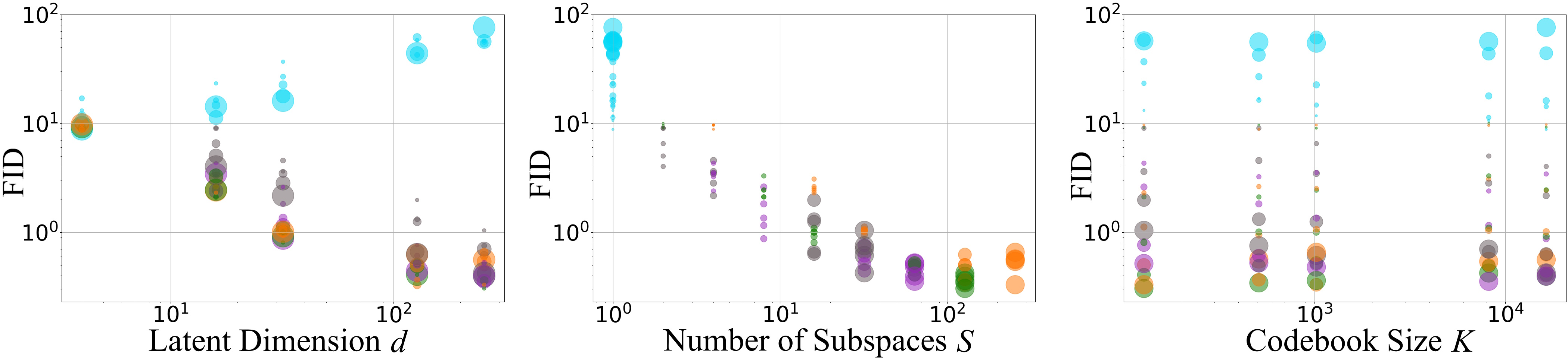
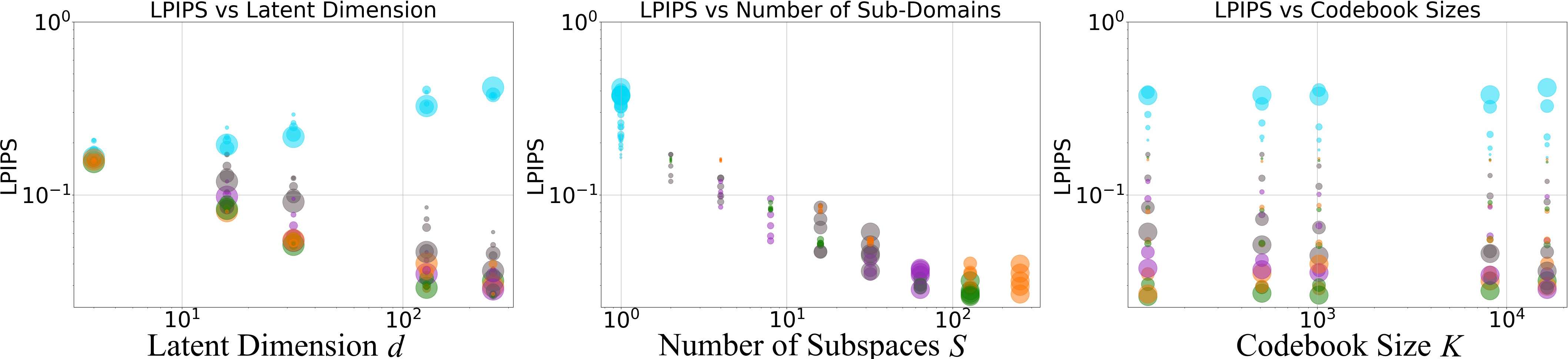
- Scaling behavior is different—and better with PQ.
- Increasing the number of channels (d) hurts VQ but helps PQ. PQ learns better when the compressed code has more features, as long as it’s split into subspaces.
- Splitting into more subspaces (S) consistently improves quality and stabilizes learning, up to a point just before treating each number separately (near scalar quantization).
- Small dictionaries can still give great results.
- Even with modest K (like 128 or 512 entries per subspace), PQ achieved state-of-the-art quality. You don’t need huge codebooks with hundreds of thousands of entries.
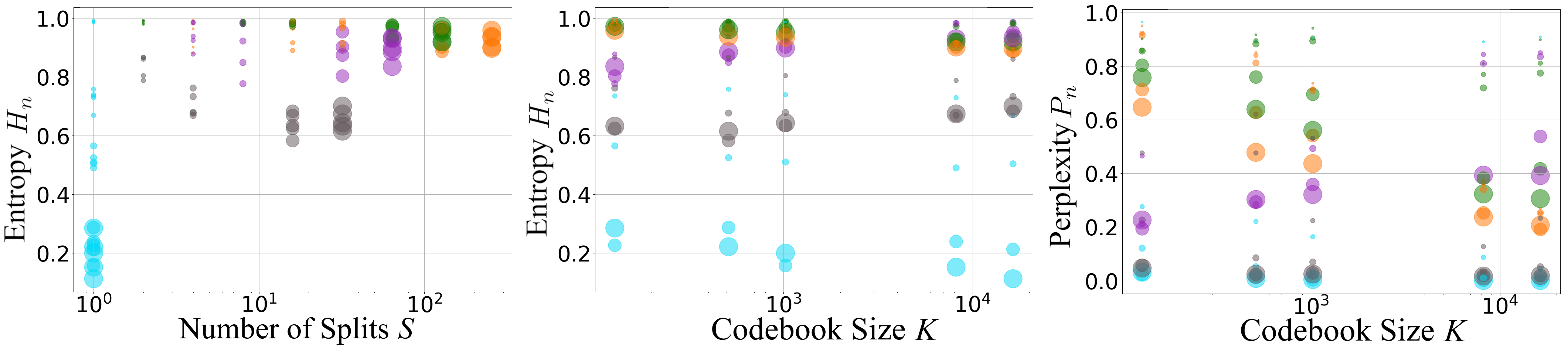
- Codebook usage is healthier with PQ.
- PQ uses its dictionaries more evenly and effectively (good entropy and perplexity), avoiding common problems like “dead” entries that never get used.
- Plugging PQ into Stable Diffusion is easy and powerful.
- You can either generate higher-resolution images at the same cost (double the output resolution without extra compute) or generate the same size images much faster (up to about 4× speedup), while maintaining or improving image fidelity.
In simple terms: breaking the compressed image code into parts makes it much easier to store, look up, and rebuild images with amazing detail, and it slots nicely into modern image generators.
Implications and Impact
This research suggests that future image models can:
- Reconstruct images far more accurately using the same or less compute.
- Run faster or make larger images without extra cost, making high-quality image tools more accessible.
- Use smaller, smarter dictionaries without sacrificing quality, which is helpful for memory and training stability.
One limitation: PQ creates many possible combinations of indices when split into many parts, so methods that need a single, simple index (common in some autoregressive models) may struggle. However, diffusion and flow models—which don’t rely on indexing one token at a time—benefit greatly from PQ.
Overall, PQGAN shows a practical, scalable, and high-fidelity way to represent images inside AI systems, likely influencing how future image generators are built and optimized.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Autoregressive/compression incompatibility: PQ requires storing S indices per spatial location; no practical scheme is proposed to make PQ indexable for AR models or bitrate-constrained compression without exponential blow-up. Explore compositional/factorized tokenization, joint entropy models across subspaces, or compact bijective encodings.
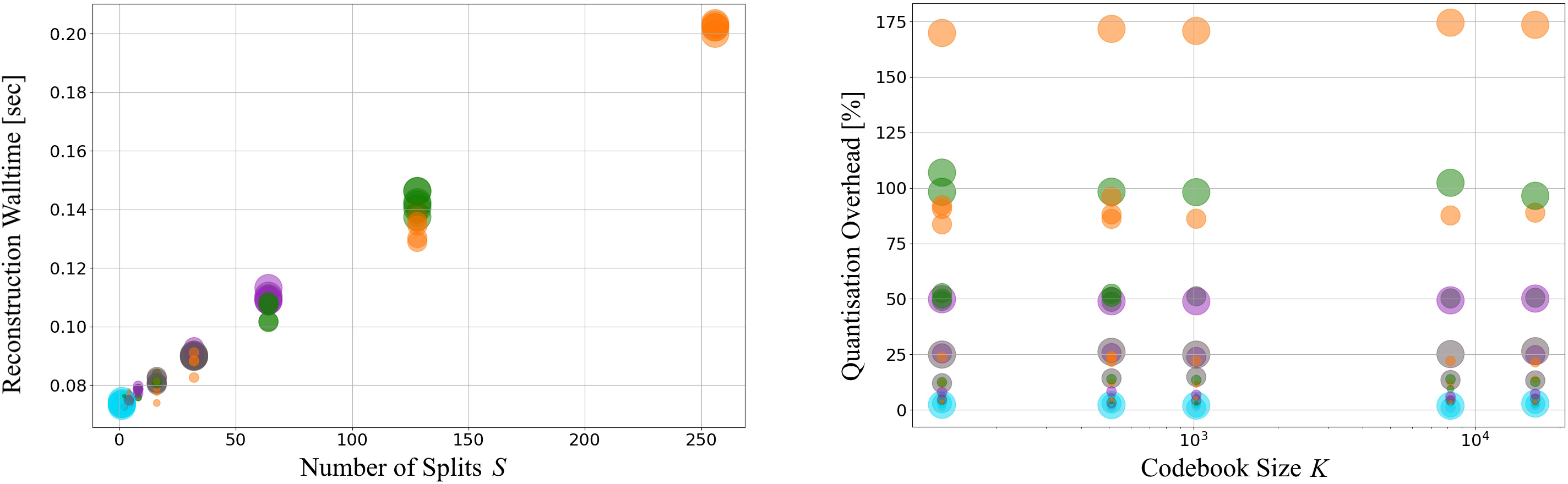
- Codebook matching overhead: Nearest-neighbor lookup scales linearly with the number of subspaces S and adds up to ~50% walltime overhead in their best setup. Need optimized GPU/TPU kernels, batched vectorized search, ANN per-subspace, or learned hashing, and an end-to-end latency breakdown including encode/decode.
- Automated hyperparameter selection: While qualitative trends are reported, there is no principled method to select (d, S, K) under compute/memory constraints. Develop predictive scaling laws, validation-time model selection, or Bayesian optimization policies linking quality, compute, and memory.
- Fixed, equal subspace partitioning: Only uniform channel splits are evaluated. Assess learned rotations (e.g., OPQ), channel permutations, variable subspace sizes, learned subspace assignment, or mixtures/hierarchies of product quantizers.
- Missing theory for diffusion–quantization interaction: No analysis of how discrete PQ latent distributions interact with diffusion noise schedules or preconditioning. Study whether the noise schedule should be retuned for quantized latents and if quantization-aware diffusion objectives/dithering improve training.
- Cross-subspace dependency loss: In the scalar limit (S = d), independence may suppress cross-channel correlations. Investigate regularizers or pre/post transforms (invertible mixing, learned linear transforms) to reintroduce dependencies without harming training.
- Stability and codebook dynamics: Long-horizon behavior of codebook utilization (churn, dead codes, reinitialization strategies, EMA vs. straight-through updates) is not characterized; analyze lifecycle of codes as K and S grow.
- Approximate lookup trade-offs: The effect of approximate per-subspace search on reconstruction and generation quality is not studied. Quantify quality/speed trade-offs for ANN, coarse-to-fine search, and quantization-aware caching.
- Compute profiling beyond one setup: Claims that compute is dominated by spatial resolution are demonstrated for one U-Net and hardware. Provide systematic FLOP/latency/memory profiling across channel widths, U-Net variants, attention-heavy blocks, and different accelerators (A100, consumer GPUs, TPUs).
- Encoder/decoder overhead in generation: Reported sampling speeds exclude or do not isolate encoder/decoder and quantization overhead. Provide end-to-end throughput/latency including encode, quantize, generate, and decode phases.
- Fairness of comparisons: PQGAN uses adversarial loss (VQGAN-style) whereas several KL baselines typically do not. Control for architecture and losses by retraining baselines under matched backbones/objectives to isolate the PQ effect.
- Generation quality metrics absent: For PQ-adapted SD, generation metrics (e.g., FID/KID@50k, CLIP-FID/CLIP score, text-image alignment) are not reported. Quantify prompt fidelity, diversity, and aesthetics compared to SDv2.1/SDXL under identical sampling conditions.
- Minimal adaptation cost: Integration into SD requires 20k projection training plus ~1M fine-tuning steps. Explore parameter-efficient fine-tuning (LoRA/adapters), freezing strategies, and the minimal adaptation needed for strong performance.
- Generality across model families: Only SD2.1 is adapted. Extend to SDXL, DiT, PixArt, consistency/flow models, and non-UNet backbones to test generality and any architecture-specific constraints.
- Robustness/transfer breadth: Domain shift tests are limited (FFHQ, LSUN at 256²). Evaluate robustness across varied distributions (web-scale LAION subsets, artistic domains), OOD stress tests, and adversarial/perturbation robustness.
- High-resolution scaling: Reconstruction/generation beyond 1536² is not assessed. Study tiling strategies, long-range consistency, and artifacts at 2–4K resolutions.
- Rate–distortion and storage: The storage cost per latent location is S·log2(K) bits, but no rate–distortion analysis or comparison to continuous latents (memory/caching/serving) is provided. Quantify latency/quality at fixed storage budgets and design entropy models across subspaces.
- Downstream task impact: Effects on editing, inversion, inpainting, ControlNet conditioning, and segmentation are untested. Determine whether PQ helps/hurts fine-grained controllability and inversion stability.
- Failure cases and sensitivity: Conditions where VQ/KL may outperform PQ (e.g., very small d/K, small datasets, tight compute) are not cataloged. Provide sensitivity analyses to initialization, optimizer, β/λ weights, and training duration.
- Code interpretability: Whether subspaces capture disentangled or semantically meaningful factors is unknown. Study interpretability and targeted editing via subspace-specific index manipulations.
- PQ for video/audio/multimodal: Spatiotemporal PQ, temporal subspace sharing, motion consistency, and cross-modal latents are unexplored. Extend PQGAN to video/audio and evaluate temporal coherence.
- Hardware-aware design: Co-design PQ and kernels for different accelerators; measure speed and memory on consumer GPUs and TPUs; evaluate mixed precision and memory-saving techniques for large S.
- Product-quantized AR models: Despite index explosion, hybrid designs (parallel token streams per subspace, multi-head decoders, factorial AR) could make PQ usable in AR pipelines. Feasibility and training stability remain open.
- Hyperparameter–compute Pareto fronts: Quantify Pareto curves of quality vs. latency/memory for varying (F, d, S, K), including encoder/decoder and search overheads, to guide deployment at different budgets.
- User studies and perceptual measures: Beyond rFID/LPIPS/CMMD, conduct user studies and metrics like DISTS/NIQE/PIQE to validate perceived improvements, especially at high resolutions.
- Data scale and training resolution: Most reconstructions use ImageNet 256². Evaluate training at 512–1024² and on web-scale data to test whether PQ gains persist and whether codebook capacity saturates.
- Open-source and reproducibility: The main text lacks explicit release details for code, pretrained models, and full hyperparameters. Public artifacts and scripts would enable broader validation and extension.
- Security/privacy aspects: PQ’s discrete latents may affect memorization or leakage differently from continuous latents. Analyze privacy risks and membership inference under PQ.
- Quantization-aware augmentation: Investigate training augmentations (jitter, dither) and temperature schedules that may improve robustness/stability of PQ learning and downstream generation.
Practical Applications
Overview
Below is a focused synthesis of practical, real-world applications that follow directly from the paper’s findings and innovations around product-quantised latent representations (PQGAN) and their integration into diffusion models. Applications are grouped by deployment horizon and linked to sectors, with concrete tools/workflows and feasibility notes.
Immediate Applications
These can be deployed now with existing tooling and standard diffusion model infrastructures, requiring only modest adaptation (e.g., swapping VAEs, retraining input/output projections, or using the provided PQ configurations).
- Software/AI Platforms — Drop-in PQ VAE replacement for diffusion pipelines
- What: Replace standard VAEs in Stable Diffusion-like systems with PQGAN to either double output resolution at comparable cost (PQSD-HR) or achieve 3–4× faster sampling at the same resolution (PQSD-Quick).
- Why now: The paper shows practical adapters (modifying only first/last conv layers, brief freeze-unfreeze finetuning) and measured speed/VRAM parity for 1536×1536 vs. 768×768 generations.
- Tools/workflows:
- PQGAN encoder/decoder as a VAE module
- A “latent adaptation” training recipe (20k projection-only + ~1M fine-tune steps)
- Serving configurations: PQSD-HR, PQSD-Precise, PQSD-Quick
- Assumptions/dependencies: Access to pretrained diffusion weights, sufficient GPU memory, licensing of base models, and tolerance for a ~50% quantisation matching overhead (bounded and acceptable in reported setups).
- Media, Design, and Advertising — Higher-fidelity content and faster iteration
- What: Generate sharper composites, typography, and faces with fewer artifacts in high-res campaigns; run more iterations per creative cycle due to speedups.
- Why now: PQGAN achieves up to 37.4 dB PSNR and near-original reconstructions (LPIPS ≈ 0.0024), reducing artifact propagation from the VAE into the generative process.
- Tools/workflows:
- Integrate PQSD-Quick into creative pipelines for rapid drafts; switch to PQSD-HR for final high-res assets
- Batch rendering with improved reconstruction fidelity to minimize post-processing
- Assumptions/dependencies: Existing prompt-to-image workflows, creative approval cycles; potential need to validate color management and print profiles at higher resolutions.
- E-commerce and Product Visualization — Crisp catalog imagery with controlled compute
- What: Generate consistent, high-resolution product images (zoom-ins, variants) at near-constant cost versus standard pipelines.
- Why now: Lower spatial latent resolution with higher channel dimensionality enables cost-effective scaling while preserving detail.
- Tools/workflows:
- PQSD-Precise for 768×768 with fidelity gains
- PQSD-HR for 1536×1536 without added VRAM vs. SDv2.1 baseline
- Assumptions/dependencies: Quality checks for material textures and brand colors; governance for synthetic imagery and disclaimers.
- Game and VFX Asset Pipelines — Efficient high-res asset generation
- What: Use PQ latents to upscale concept art, textures, and matte paintings quickly while preserving detail.
- Why now: Demonstrated speed/fidelity trade-offs enable production-friendly workflows without heavy retraining.
- Tools/workflows:
- PQGAN-augmented concept-to-asset generation
- Texture upscaling and stylization passes leveraging PQSD-HR
- Assumptions/dependencies: Integration with DCC tools (Substance, Blender), asset management and versioning; pipeline-wide consistency tests.
- On-device and Mobile Photo Apps — Faster enhancement and stylization
- What: Deploy mobile inferencing with smaller latent spatial footprints for efficient high-res output (super-resolution, de-noising, stylistic edits).
- Why now: PQ reduces the attention bottleneck via lower latent spatial resolution; channel increases don’t dominate compute for attention-heavy blocks.
- Tools/workflows:
- Edge-optimized PQ encoders with lightweight decoders
- Mobile SDK wrapper for PQ quantisation matching and inference
- Assumptions/dependencies: Hardware acceleration (GPU/NPU), optimized kernels for PQ matching; power/thermal constraints on-device.
- Academic Research — Robust latent representation benchmarking and hyperparameter guidance
- What: Use the reported trends (opposite scaling behavior of VQ vs. PQ with embedding dimension; entropy/perplexity diagnostics) to design better latent studies and methods.
- Why now: The paper offers actionable scaling laws and diagnostics to avoid codebook collapse and select S/K/d effectively.
- Tools/workflows:
- Open-source PQ autoencoder baselines
- Codebook utilization dashboards (entropy, perplexity) for training monitoring
- Assumptions/dependencies: Availability of datasets (ImageNet, FFHQ, LSUN), reproducible training scripts.
- Sustainability and Cost Control (Policy/Operations) — Same compute, higher output quality
- What: Reduce cloud GPU-hours or generate higher-resolution outputs for the same budget; quantify carbon savings via fewer re-renders/iterations.
- Why now: Paper’s speed/memory parity for higher resolutions offers immediate operational gains.
- Tools/workflows:
- Internal cost/energy dashboards to measure improvements from PQ latents
- Procurement guidelines favoring PQ-based pipelines for generative workloads
- Assumptions/dependencies: Organizational buy-in; robust metering of energy and GPU-hour consumption.
Long-Term Applications
These require further research, scaling, or standardization (e.g., broader tooling, interoperability, domain-specific validation).
- Healthcare Imaging (Radiology, Pathology) — High-fidelity generative reconstructions and augmentation
- What: Use PQ latents for artifact-minimized reconstructions and synthetic augmentation of medical images to support training and analysis.
- Why future: Medical domains need rigorous validation, privacy and regulatory compliance; domain shift tests beyond ImageNet/FFHQ/LSUN.
- Tools/products/workflows:
- PQ-based latent encoders for DICOM pipelines
- Audit trails and uncertainty quantification around generative edits
- Assumptions/dependencies: Clinical validation, explainability, FDA/CE approval pathways; secure data handling.
- Robotics and Autonomous Systems — Robust visual modeling under compute constraints
- What: PQ latents for on-robot generative perception modules (scene completion, texture synthesis) using low spatial resolution latents.
- Why future: Integration with control stacks and real-time SLAM requires specialized kernels and latency guarantees.
- Tools/products/workflows:
- PQ-optimized vision backbones for embedded GPUs
- Simulation-to-real asset generation with PQ latents
- Assumptions/dependencies: Deterministic inference, real-time benchmarks, vendor-specific acceleration.
- Remote Sensing and Geospatial (Energy, Agriculture, Finance) — High-res synthesis and enhancement at scale
- What: Use PQ to efficiently generate or enhance satellite and aerial imagery for monitoring crops, infrastructure, or risk.
- Why future: Requires domain-specific models, multi-spectral support, and validation against ground truth.
- Tools/products/workflows:
- PQ-augmented geospatial diffusion models
- Monitoring dashboards for anomaly detection and change maps
- Assumptions/dependencies: Access to calibrated datasets; integration with GIS tools; rigorous accuracy audits.
- Education and XR — Realistic, high-res content streaming for learning and AR/VR
- What: PQ latents reduce bandwidth/compute for high-fidelity assets in immersive experiences and interactive learning content.
- Why future: Needs standardized PQ codecs, device-level support, and content safety frameworks.
- Tools/products/workflows:
- PQ-based streaming protocols for discrete latents
- Classroom and headset SDKs for on-device decoding
- Assumptions/dependencies: Edge compute capabilities; content moderation; interoperability standards.
- Video Generation and Compression Standards — PQ for temporal latents
- What: Extend PQ to video latents to balance rate-distortion in generative video and next-gen compression.
- Why future: Temporal consistency and PQ matching speed across frames require algorithmic advances; possible standardization efforts.
- Tools/products/workflows:
- PQ-temporal autoencoders with motion-aware subspace factorization
- Benchmark suites for temporal entropy/perplexity and perceptual metrics beyond FID
- Assumptions/dependencies: Research into PQ matching acceleration; collaboration with standards bodies.
- Multimodal Systems and Model Interoperability — Common discrete latent layer
- What: Use PQ as a unified latent interface across image, audio, 3D, and text-conditioned models to improve composability.
- Why future: Requires community adoption, conversion toolchains, and abstractions that hide PQ indexing complexities.
- Tools/products/workflows:
- PQ latent interchange formats
- Cross-model adapters for product-quantised subspaces
- Assumptions/dependencies: Ecosystem-level standards; efficient multi-domain PQ codebooks.
- Enterprise MLOps — Automated hyperparameter tuning and PQ diagnostics
- What: Production tooling to select S/K/d automatically based on data distribution and downstream tasks, with codebook health monitoring.
- Why future: Needs general-purpose auto-tuners and robust alerting for codebook collapse, saturation, or drift.
- Tools/products/workflows:
- PQ AutoTune services plugged into training pipelines
- Monitoring dashboards for entropy/perplexity across subspaces
- Assumptions/dependencies: Integration into existing MLOps stacks; data governance for retraining triggers.
- Policy and Governance — Best-practices for efficient generative infrastructure
- What: Guidelines that encourage PQ-based generative systems for reduced energy use per high-res output; transparent reporting of fidelity and compute trade-offs.
- Why future: Requires consensus on metrics (beyond FID), public benchmarks (e.g., CMMD adoption), and disclosure norms.
- Tools/products/workflows:
- Policy templates and procurement checklists
- Shared benchmark suites and reporting protocols
- Assumptions/dependencies: Cross-industry collaboration; alignment on environmental KPIs and reproducibility.
Notes on Feasibility and Dependencies
- PQ is best suited to diffusion/flow models; autoregressive index-based tasks face exponential index growth with many subspaces.
- Quantisation matching introduces overhead that scales with the number of subspaces; practical deployments should profile and optimize kernels.
- The demonstrated adapters assume access to pretrained U-Net weights and minimal architecture changes (first/last layer projections).
- Metrics beyond FID (e.g., CMMD, LPIPS) should be adopted in production QA to capture perceptual improvements; domain-specific validation is essential where safety or compliance matters.
Glossary
- Adversarial loss: A GAN-based training term that encourages realistic reconstructions via a discriminator. "adversarial loss used in VQGAN training."
- Attention layers: Neural network components that compute pairwise interactions across spatial tokens, often with quadratic cost in resolution. "the use of attention layers throughout the architecture causes computational cost to scale quadratically with spatial resolution."
- Autoregressive factorisation: Decomposing generation into a sequential process over indices or tokens. "without requiring an explicit autoregressive factorisation."
- Autoregressive transformers: Transformer models that generate outputs token-by-token conditioned on previously generated tokens. "Autoregressive transformers, for example, require discrete and indexable representations~\cite{esser2021taming}"
- Bottleneck representation: The compressed latent produced by an autoencoder that retains essential information while discarding details. "under the assumption that this bottleneck representation discards perceptually negligible details while retaining the core visual structure~\cite{rombach2022high, lee2022AR_ResQuant}."
- CMMD: A distributional metric for image similarity designed to address biases of FID. "we additionally employ CMMD, which has been shown to provide a more faithful and unbiased comparison of image similarity."
- Codebook: A learned set of embedding vectors (codewords) used to discretise continuous latents. "vector quantisation learns a codebook consisting of codewords ."
- Codebook collapse: A failure mode where few codebook entries are used, reducing diversity and capacity. "often leading to codebook collapse and slow convergence."
- Codebook matching: The process of finding nearest codewords for quantisation, which adds computational overhead. "requires higher codebook matching times that scale linearly with the number of subspaces"
- Codebook utilisation: How evenly and extensively codebook entries are used during encoding. "we further analyse codebook utilisation via entropy and perplexity metrics"
- Commitment term: A regulariser that encourages encoder outputs to stay close to selected codewords. "includes a commitment term to stabilise codebook usage."
- Diffusion models: Generative models that iteratively denoise latent variables to synthesize images. "In diffusion models such as Stable Diffusion~\cite{rombach2022high}, the use of attention layers throughout the architecture causes computational cost to scale quadratically with spatial resolution."
- Downsampling factor (F): The spatial reduction factor mapping images to lower-resolution latents. "with a spatial resolution reduced by a downsampling factor ."
- FID: Fréchet Inception Distance, a widely used perceptual distributional metric for image quality. "reduce the FID, LPIPS, and CMMD score by up to 96\%."
- Fictive codebook: The combinatorial set of all possible subspace codeword combinations implied by PQ. "PQ defines a fictive codebook of combinatorial size "
- Flow-based generation: Generative models that transform noise into data via invertible flows. "diffusion- and flow-based generation~\cite{rombach2022high, SDXL, DDPM, esser2024scaling}"
- Hierarchical quantisation: A multi-level quantisation scheme that captures structure progressively. "such as residual quantisation~\cite{vqres1, lee2022AR_ResQuant}, hierarchical quantisation~\cite{VQVAE2}, and other regularisation techniques~\cite{zhang2023regularized}"
- Index space: The discrete representation where each spatial location is encoded by an index. "This mapping transforms the latent space into a discrete index space"
- Index-based tasks: Methods that require a compact, enumerable set of indices for modeling or compression. "can not directly be used for index-based tasks"
- KL-regularised autoencoders: Autoencoders trained with a Kullback–Leibler divergence term to shape continuous latents. "continuous latent spaces based on KL-regularised autoencoders within the VQGAN framework."
- Latent embedding: The feature vector at each spatial location in the bottleneck of an autoencoder. "Its latent embedding is obtained from the bottleneck of an autoencoder"
- Latent space: The lower-dimensional representation where models operate to reduce compute. "operate in the latent space of an autoencoder trained for image reconstruction"
- LPIPS: Learned Perceptual Image Patch Similarity, a perceptual metric for image similarity. "we report four complementary metrics: FID~\cite{FID}, PSNR, CMMD~\cite{cmmd}, and LPIPS~\cite{LPIPS}."
- Normalised entropy (H_n): A measure of uniformity in codebook usage, scaled to [0,1]. "normalised entropy , which captures the uniformity of code usage"
- Normalised perplexity (P_n): A measure of the fraction of actively used codebook entries, scaled to [0,1]. "normalised perplexity , which reflects the fraction of entries actively used:"
- Perceptual reconstruction loss: A loss that encourages reconstructions to match perceptual features rather than raw pixels. "$\mathcal{L}_{\text{rec}$ is the perceptual reconstruction loss"
- Product quantisation (PQ): Quantisation that splits vectors into subspaces and quantises each independently. "Product quantisation (PQ) is a classical method for scalable vector encoding"
- PSNR: Peak Signal-to-Noise Ratio, a pixel-level fidelity metric. "We achieve a PSNR score of 37~dB"
- Rate–distortion constraints: The trade-off between bitrate and reconstruction error in compression. "Freed from rate-distortion constraints, we explore the full potential of PQ"
- Residual quantisation (RQ): A scheme that quantises residuals over multiple stages to improve fidelity. "such as residual quantisation~\cite{vqres1, lee2022AR_ResQuant}"
- Scalar quantisation: Quantisation of each channel dimension independently (S=d in PQ). "Vector and scalar quantisation emerge as special cases of PQ when and , respectively."
- Shannon entropy: Information-theoretic measure of uncertainty used to assess code usage. "where is the empirical codeword distribution and is its Shannon entropy."
- Stop-gradient operator: A training trick that prevents gradients from flowing through certain variables. "where denotes the stop-gradient operator"
- Subspace factorisation: Splitting embeddings into independent subspaces for separate quantisation. "factorising each codebook entry into independent subspaces."
- U-Net generator: An encoder–decoder architecture with skip connections used in diffusion models. "We observe that the U-Net generator contains a fixed projection from 4 to 512 channels at the input layer"
- Vector quantisation (VQ): Replacing each latent vector by its nearest codebook entry to obtain discrete indices. "Vector quantisation (VQ), popularised by VQVAE~\cite{vqvae} learns discrete latent representations by replacing each continuous vector with its nearest entry from a learned codebook."
- VQGAN: A GAN-augmented VQ autoencoder framework for image representation and synthesis. "we adopt the VQGAN~\cite{esser2021taming} architecture and training pipeline"
- VQ-VAE: A VAE variant with a discrete codebook for quantised latent representations. "VQ-VAE~\cite{vqvae} demonstrated that latent image representations can be quantised by learning a codebook of discrete vectors"
Collections
Sign up for free to add this paper to one or more collections.

