- The paper introduces dynamic lookahead keys that update key representations with emerging context, enhancing global modeling while preserving autoregressiveness.
- It develops a parallel formulation that reduces computational complexity from O(L^3 d) to O(L^2 d) for efficient training and inference using a modified KV cache.
- Empirical evaluations show that CASTLE achieves lower validation losses and improved downstream performance across various model scales and benchmarks.
Causal Attention with Lookahead Keys: A Technical Analysis
Introduction
The paper "Causal Attention with Lookahead Keys" (CASTLE) (2509.07301) introduces a novel attention mechanism for autoregressive sequence modeling, specifically targeting the limitations of standard causal attention in capturing global context. The core innovation is the introduction of lookahead keys, which allow each token's key representation to be continually updated as new context becomes available, while strictly preserving the autoregressive property. This mechanism is shown to improve both language modeling perplexity and downstream task performance across multiple model scales.
Motivation and Limitations of Standard Causal Attention
Standard causal attention restricts each token's query, key, and value (QKV) to encode only preceding context, enforced by a causal mask. This design impedes the model's ability to resolve ambiguities that require future context (e.g., garden-path sentences) and limits the quality of sentence embeddings and global context modeling. Prior works such as BeLLM, Echo Embeddings, and Re-Reading have attempted to address these issues, but their applicability to pretraining remains unclear.
CASTLE modifies the attention mechanism by introducing lookahead keys, which are dynamically updated to incorporate information from subsequent tokens as the context unfolds. The design maintains a hybrid structure: half of the keys are standard causal keys (static), and the other half are lookahead keys (dynamic).
When generating the (t+1)-th token, the lookahead key for each preceding token s (1≤s≤t) is updated to encode information from tokens s+1 to t. This is achieved via a masked attention-like update, ensuring that no future information (tokens k>t) is incorporated, thus preserving autoregressiveness.
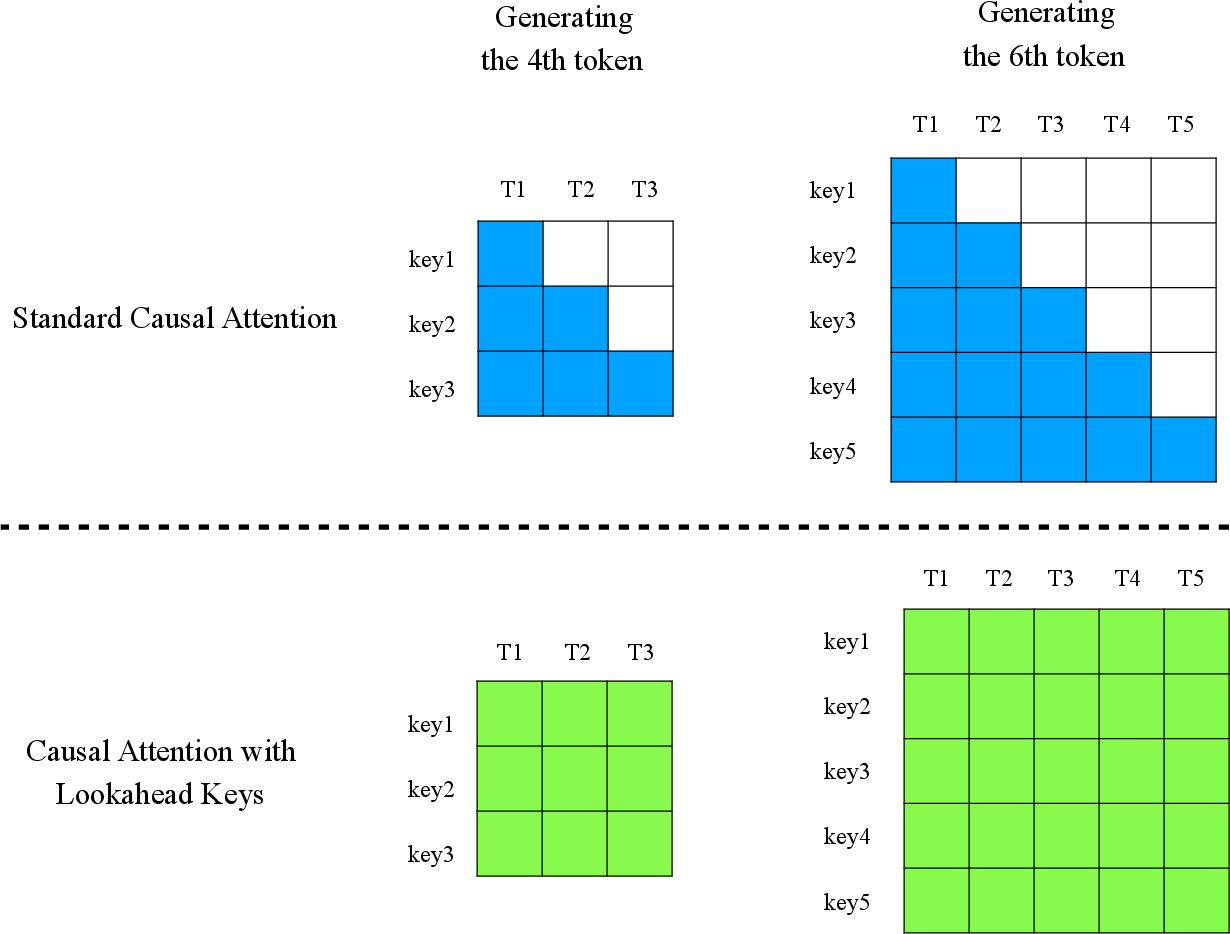
Figure 1: Comparison of receptive fields for keys in standard causal attention (static) and CASTLE (dynamic lookahead keys).
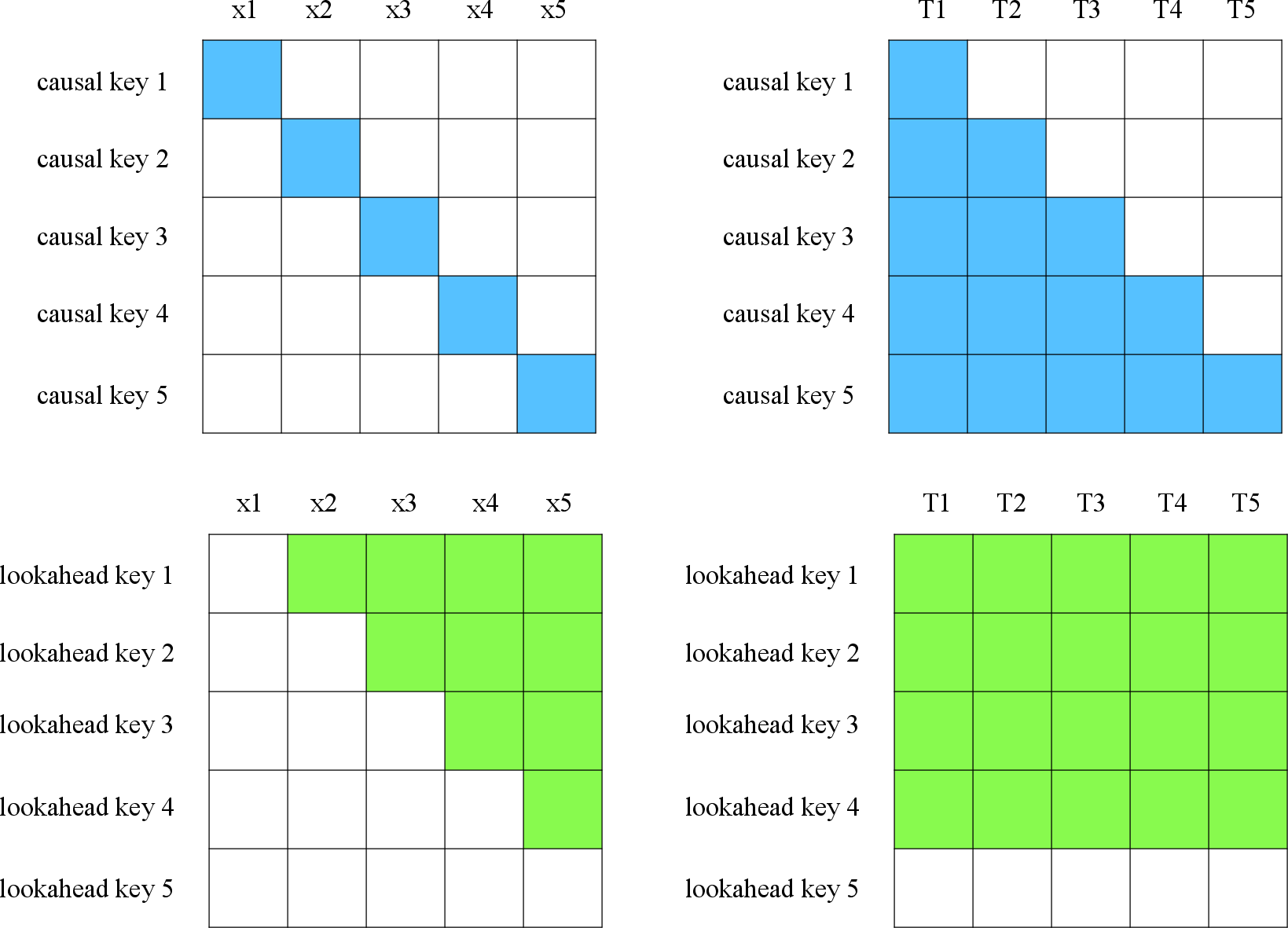
Figure 2: Receptive fields of causal and lookahead keys with respect to contextualized representations and tokens when generating the 6th token.
The mathematical definition in recurrent form involves projecting contextualized representations into causal and lookahead key matrices, and then combining their attention scores. The lookahead keys are computed using a masked sigmoid-weighted sum over future representations, rather than softmax, to avoid compulsory synthesis of future information.
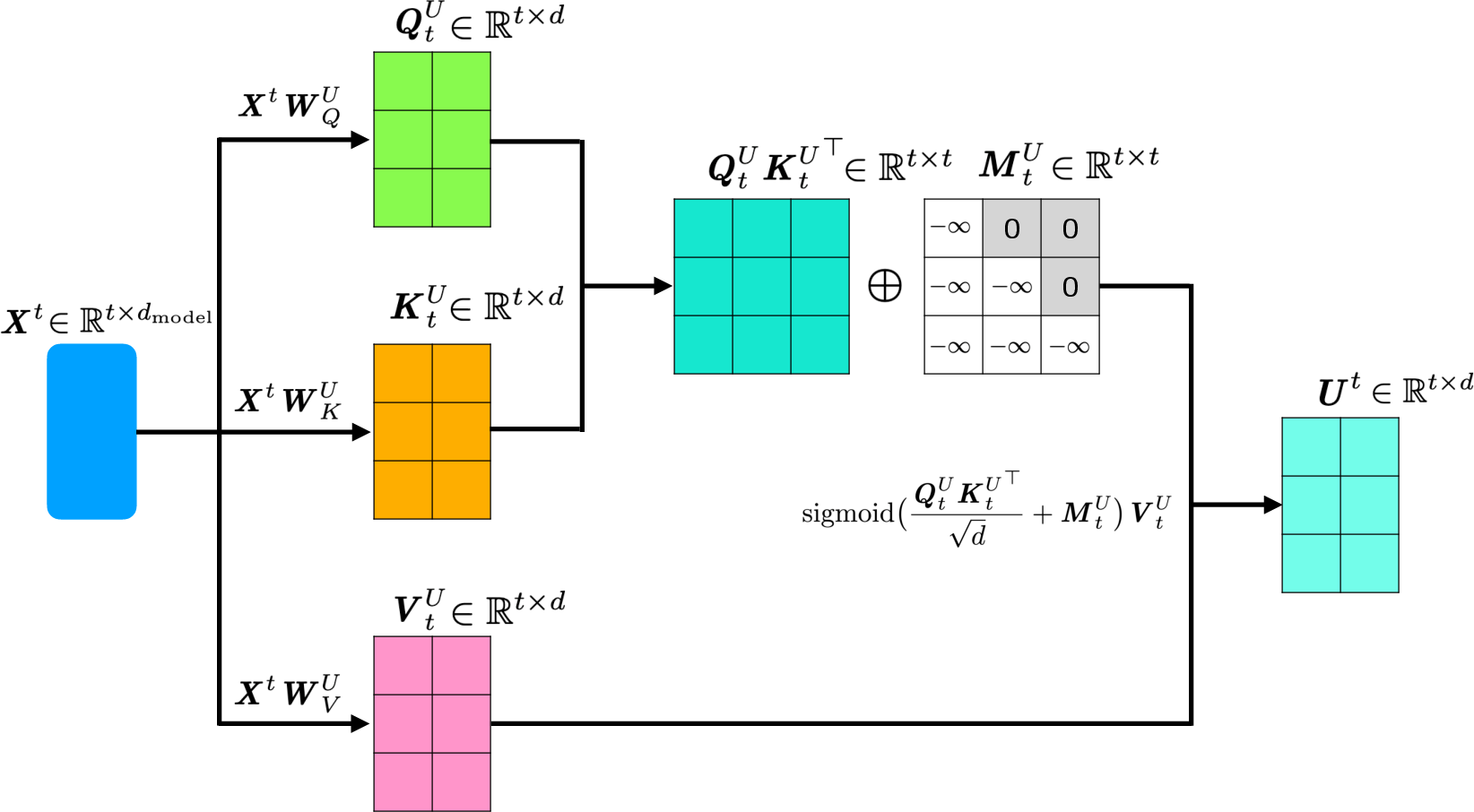
Figure 3: Illustration of lookahead key computation for a short sequence.
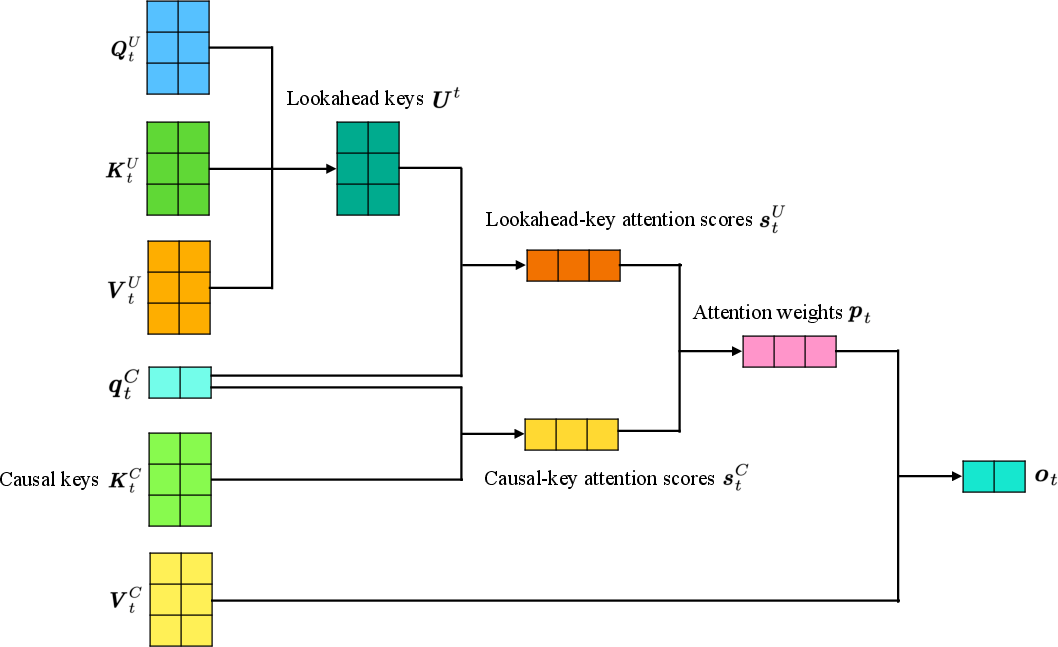
Figure 4: CASTLE recurrent form: causal and lookahead keys are queried, scores combined, and softmaxed to yield attention weights.
Efficient Parallel Training and Inference
A direct implementation of CASTLE's recurrent form is computationally prohibitive (O(L3d)). The authors derive a mathematically equivalent parallel formulation that eliminates the need to materialize lookahead keys at every position, reducing complexity to O(L2d) and enabling efficient parallel training. The parallel algorithm leverages the low-rank structure of the masked key matrices and is implemented in Triton for high-throughput GPU execution.
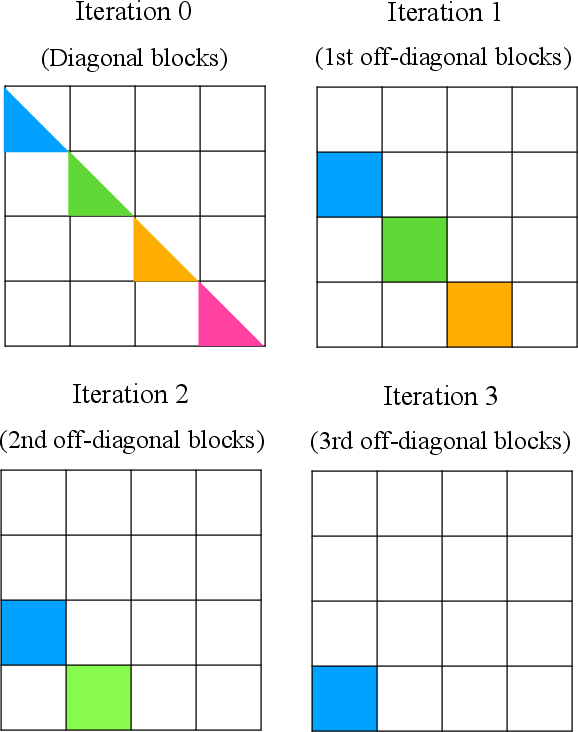
Figure 5: Parallel blockwise computation scheme for efficient CASTLE training.
For inference, the UQ-KV cache (containing updated lookahead keys, queries, and values) is introduced, analogous to the standard KV cache but adapted for the dynamic key updates. The cache management and update rules are designed to minimize memory and computational overhead during both prefilling and decoding stages.
Empirical Results
Language Modeling
CASTLE is evaluated on the FineWeb-Edu dataset across four model scales (small, medium, large, XL), using a Transformer backbone with SwiGLU, RoPE, and RMSNorm. All other architectural components are held constant to isolate the effect of the attention mechanism.
CASTLE consistently achieves lower training and validation loss compared to standard causal attention. The improvement in validation loss is most pronounced in medium, large, and XL models, with margins up to 0.0356 for large and 0.0348 for XL models after 50B training tokens.
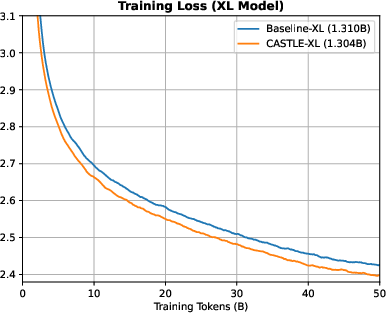
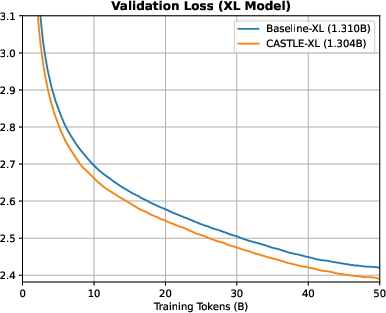
Figure 6: Training and validation loss curves for XL models; CASTLE-XL achieves a 0.0348 lower validation loss than Baseline-XL.
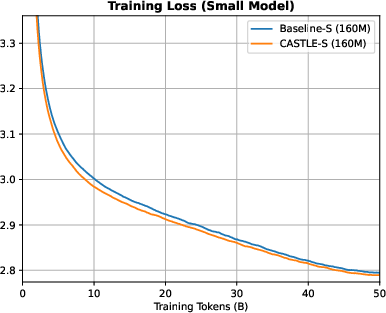
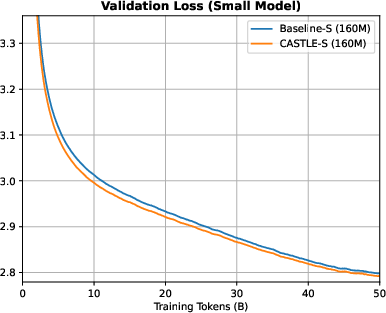
Figure 7: Training and validation loss curves for small models; CASTLE yields marginal improvements over baseline at this scale.
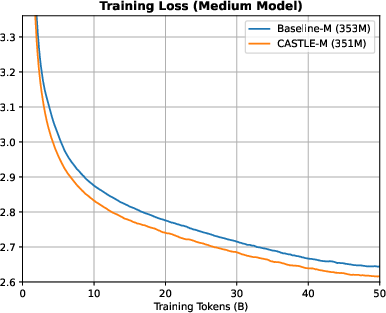
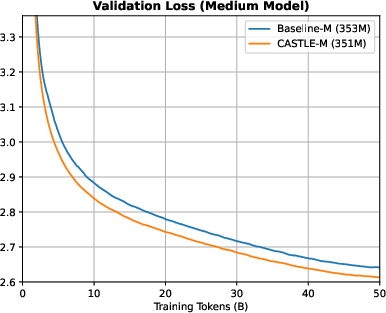
Figure 8: Training and validation loss curves for medium models; CASTLE-M achieves a 0.0245 lower validation loss than Baseline-M.
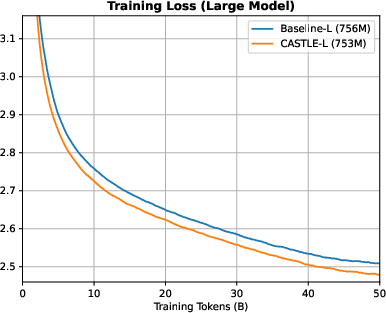
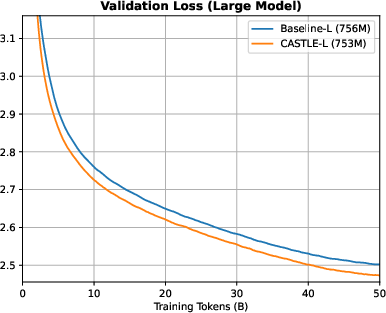
Figure 9: Training and validation loss curves for large models; CASTLE-L achieves a 0.0356 lower validation loss than Baseline-L.
CASTLE models outperform baselines on a suite of downstream tasks (ARC, BoolQ, HellaSwag, MMLU, OBQA, PIQA, Winograde) in both 0-shot and 5-shot settings. The improvements are robust across all scales, with particularly strong gains in reasoning and commonsense benchmarks. Notably, CASTLE achieves higher average accuracy even when parameter counts are matched or lower than the baseline.
Ablation Studies
Ablations confirm that both causal and lookahead keys are necessary; removing causal keys degrades performance. The improvements are not attributable to simply increasing the number of keys, as CASTLE variants with matched key counts still outperform baselines. The inclusion of the SiLU function in the attention score combination further enhances downstream generalization, though its effect on perplexity is minimal.
Implementation Considerations
- Computational Complexity: Efficient parallel training is critical; naive recurrent implementation is infeasible for large-scale pretraining.
- Memory Usage: UQ-KV cache management is essential for scalable inference.
- Parameter Efficiency: CASTLE achieves improvements without increasing parameter count, and in some configurations, with fewer parameters than baseline.
- Integration: CASTLE can be integrated into existing Transformer architectures with minimal changes to non-attention components.
Theoretical and Practical Implications
CASTLE demonstrates that dynamic key updates in causal attention can substantially improve global context modeling and downstream performance, without violating autoregressive constraints. This has implications for the design of future autoregressive models, suggesting that static key representations are a limiting factor for both pretraining and downstream generalization.
The mathematical equivalence enabling parallel training is a significant technical contribution, making CASTLE practical for large-scale deployment. The approach may be extensible to other modalities (e.g., vision, audio) and to architectures beyond standard Transformers.
Future Directions
- Ratio Optimization: Exploring optimal ratios of causal to lookahead keys.
- Lookahead Values: Investigating dynamic value updates for further gains.
- Scaling: Application to even larger models and longer context windows.
- Modalities: Extension to non-text domains and multi-modal architectures.
- Theoretical Analysis: Formal characterization of expressivity and generalization improvements.
Conclusion
CASTLE introduces a principled modification to causal attention, enabling dynamic key updates that enhance global context modeling while preserving autoregressiveness. The mechanism is shown to be both theoretically sound and practically efficient, yielding consistent improvements in language modeling and downstream tasks. The results suggest that evolving key representations are a promising direction for future autoregressive model design.