- The paper introduces the CRIT dataset using a graph-based synthesis pipeline that guarantees multi-hop, cross-modal dependencies across images, videos, and documents.
- The methodology constructs multimodal content graphs by linking annotated scene graphs with complementary textual descriptions for rigorous compositional QA generation.
- Empirical results show that fine-tuning on CRIT boosts vision-language model performance and enhances robustness in multi-hop reasoning tasks over varied domains.
Graph-Based Data Synthesis for Cross-Modal Multi-Hop Reasoning: The CRIT Dataset
Motivation and Limitations of Existing Multimodal Reasoning Benchmarks
Real-world multimodal reasoning problems frequently demand the conjunction of evidence from text and images, chained over several intermediate hops. Existing benchmarks are generally inadequate for such evaluation; questions are usually answerable using a single image, span shallow inference, or have answers grounded solely in one modality. There is a lack of data that explicitly requires the compositional, cross-modal reasoning characteristic of human problem-solving in domains such as technical manuals, video understanding, or scientific literature.
Vision-LLMs (VLMs) demonstrate hallucination and insufficient cross-modal grounding traceability when assessed with current benchmarks. There is also evidence that commonly used interleaved image–text training corpora do not sufficiently enforce true multi-hop cross-modal integration. This motivates the need for a new class of dataset that tightly couples evidence chains across modalities and reasoning steps, while guaranteeing that the solution requires integrating distributed, complementary visual and textual cues.
CRIT: Dataset Design and Data Generation Pipeline
The CRIT dataset (Cross-modal multi-hop Reasoning over interleaved Image-Text) is constructed via a fully automatic, graph-based pipeline, designed to programmatically guarantee multi-hop, cross-modal dependencies and generate grounded annotations. Every CRIT example consists of a set of images, an interleaved and complementary textual context, a compositional question–answer pair, and a Chain-of-Thought (CoT) trace. The central innovation is the use of multimodal content graphs as a structured, intermediate representation that captures the entities, attributes, and relations drawn from both modalities, enabling the systematic synthesis of reasoning chains that enforce both intermodality and compositionality.
A prototypical CRIT example (Figure 1) demonstrates how the dataset integrates distributed clues—highlights in both text and images, with clear cross-references and alignment—demanding several inference steps that traverse both text and visual content.
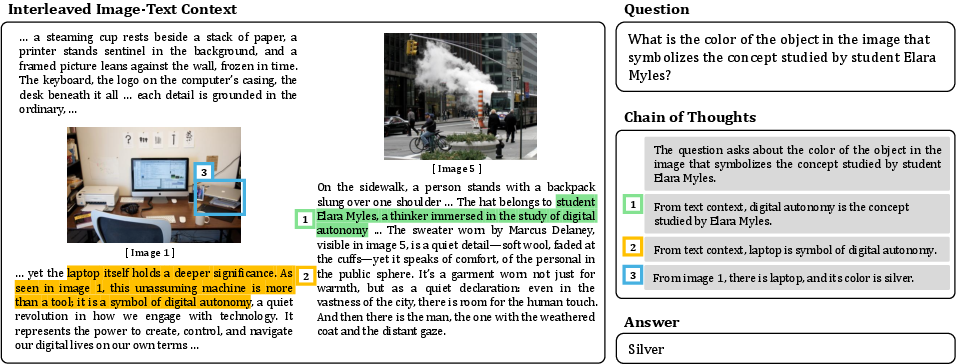
Figure 1: The CRIT dataset example requiring identification, alignment, and chaining of multimodal evidence segments for a compositional question.
The data generation pipeline comprises three key stages (Figure 2):
- Multimodal Content Graph Construction: Images with annotated scene graphs are sampled, filtered, and merged; text nodes are further generated and linked with edges via LLM prompting to capture cross-modal relations.
- Textual Context Generation: Subgraphs are extracted and used to produce multi-style descriptions that complement, but do not duplicate, the image information.
- Cross-Modal Multi-Hop QA Generation: QA pairs are sampled from subgraphs, and only those requiring genuine multi-hop, interleaved reasoning—with terminal evidence available only through a conjunction of visual and textual hops—are retained.
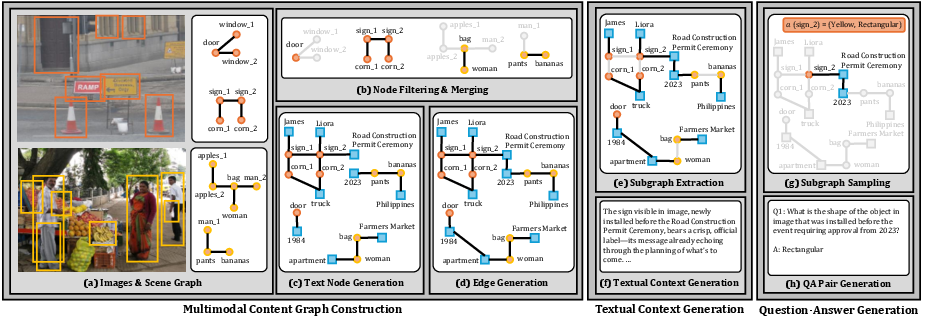
Figure 2: Overview of the CRIT pipeline: content graph construction, context generation, and question–answer creation guaranteeing compositional, interleaved dependencies.
The pipeline avoids the cyclical bias of relying on VLMs for question generation. Only LLMs handle text; the image–text linkage always flows through structural graph constraints. Human annotators manually verify the test split for non-degeneracy and correct grounding.
Domain Extension: Video Frames and Text-Rich Scientific Documents
To extend CRIT from static natural images, the pipeline was adapted for temporally coherent video frames and scientific papers. For videos, event-level dense captions are converted to partial scene graphs, with frames sampled based on CLIP similarity for alignment. Coreference is maintained across frames. For scientific documents, paragraphs, figures, and tables are mapped into a single content graph, with visual elements treated as nodes and proper cross-text references extracted via LLMs. This enables compositional QA annotation in domains not amenable to manual scene-graph annotation (see Figure 3, Figure 4).
Dataset Scale and Properties
CRIT encompasses 269k QA pairs over 84k train and 1.4k test samples, spanning natural images (from GQA), video frames (from ActivityNet Captions), and scientific papers (from SPIQA). Test set curation enforces strict filtering: inclusion only when questions truly mandate cross-modal multi-hop inference and have a unique answer. Each example contains explicit CoT traces—enabling stepwise supervision and fine-grained error analysis.
Model Evaluation on CRIT and Cross-Modal Benchmarks
State-of-the-art proprietary models (GPT-4o, Gemini 2.0 Flash) and large open-source VLMs (Qwen2.5-VL-72B, LLaVA-Onevision) all produce low Exact Match (EM) and F1 on CRIT, with performance rarely exceeding 40% EM even in the most favorable domains. This demonstrates that, unlike prior benchmarks, solutions cannot be achieved using shallow or single-modal reasoning.
Gains from CRIT-Based Supervision
Fine-tuning open-source models on CRIT substantially boosts performance. For instance, Qwen2.5-VL-7B moves from 28.3%/29.1% (EM/F1) pre-tuning up to 58.6%/59.5% (EM/F1) post-tuning for natural images, with nontrivial gains in video and scientific domains (see Table 1 in the main paper). Model scaling, or even pretraining on general instruction-tuning data, does not close the gap; compositional supervision is required.
Performance on external cross-modal benchmarks (SPIQA, VEGA, MMQA, FCMR) shows that fine-tuning with a mixture of standard data (Mantis-Instruct) plus CRIT yields substantial jumps (e.g., more than doubling METEOR, ROUGE-L, and CIDEr on SPIQA relative to standard instruction tuning).
Robustness to Domain Expansion
Scaling the dataset with noisy, model-generated annotations (from Open Images, Charades, DiDeMo, VidOR) continues to improve scores, especially in lower-resource domains such as video frames, and even benefits out-of-domain scientific paper tasks, supporting strong transfer.
Empirical Error Analysis
Systematic annotation of errors on GPT-4o outputs (Figure 5) identifies that evidence localization (failure to identify the necessary image or text segment) is responsible for 55% of all errors, surpassing visual misperception, textual misunderstanding, and answer generation issues. Detailed qualitative cases (Figures 8–11) reveal that failures are often deeply rooted in the inability to traverse the requisite chain of multimodal dependencies, rather than superficial model deficits.
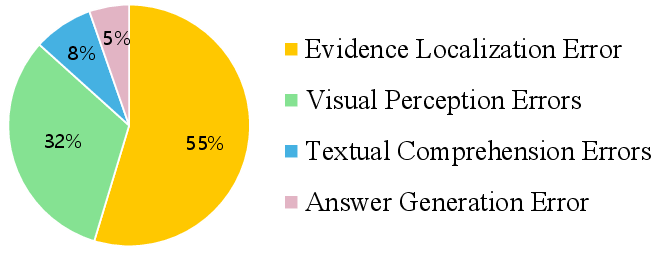
Figure 5: Distribution of error types across sampled GPT-4o responses on CRIT, dominated by evidence localization failures.
Qualitative Examples in Video and Scientific Domains
Examples in the video frame domain (Figure 3) and scientific literature (Figure 4) highlight the ability of CRIT to generate richly structured, temporally or textually anchored, multi-hop reasoning tasks unavailable in previous datasets.

Figure 3: Qualitative example showcasing CRIT’s capability to synthesize multi-frame reasoning challenges for video understanding.
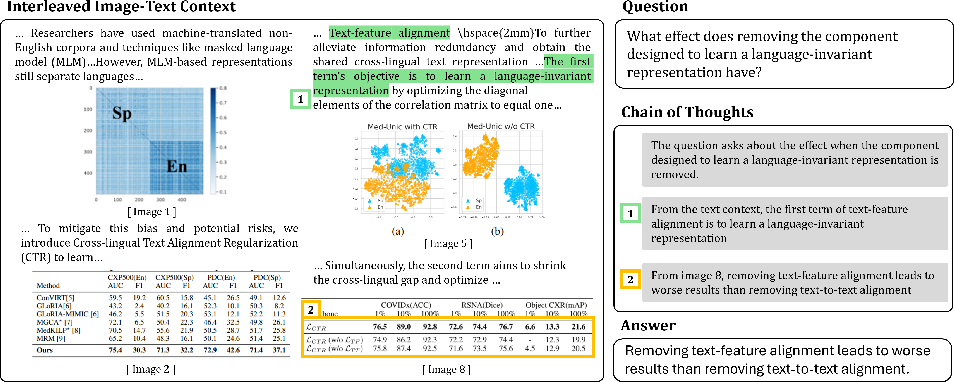
Figure 4: Qualitative example illustrating complex cross-modal dependencies in the context of scientific paper comprehension.
Implications, Practical Utility, and Theoretical Relevance
CRIT and its pipeline serve as a practical engine for scalable, compositional supervision of multimodal models, directly addressing the limitations of prior interleaved image–text data. The findings underscore that advances in scaling architectures are uncoupled from advances in compositional and grounded reasoning when the data curriculum lacks explicit, cross-modal compositionality. Supervision from CRIT not only fosters improvements in benchmarked tasks but also encourages robustness and transfer in scientific and document understanding domains.
Theoretically, the results clarify that multi-hop, multimodal grounding is a different capability axis than basic vision–language alignment or single-hop QA, and is currently a bottleneck for next-generation VLMs.
Conclusion
The CRIT dataset and its automatic, graph-based generation framework represent a significant advancement for cross-modal multi-hop reasoning research. By imposing structural compositionality, manual curation, and explicit supervisory signals, CRIT exposes the performance gap in current VLMs and provides a reliable substrate for progress. The methodology directly generalizes to video and document modeling, supporting extensibility and broader AI alignment. Models trained with CRIT exhibit large, consistent gains across dedicated and general-purpose multimodal evaluation suites. The strong empirical results and comprehensive ablations validate the graph-based synthesis paradigm as foundational for the next phase of robust, interpretable, and genuinely compositional multimodal reasoning.
Reference: "CRIT: Graph-Based Automatic Data Synthesis to Enhance Cross-Modal Multi-Hop Reasoning" (2604.01634)