- The paper proposes an anchored diffusion policy leveraging demonstration-derived trajectory priors and truncated denoising to address multimodal mobile manipulation.
- It integrates a lightweight residual correction module that performs real-time per-step adjustments, reducing drift and computational overhead.
- Experimental results on simulated and real-world tasks show that AnchorVLA outperforms state-of-the-art baselines in success rate and efficiency.
AnchorVLA: Anchored Diffusion for Efficient End-to-End Mobile Manipulation
Introduction
Mobile manipulation poses a set of distinct challenges compared to standard tabletop manipulation, due to the inherent multimodality of the action distribution, tight temporal coupling between navigation and manipulation, dynamics mismatches, and the high frequency of drift-induced failures under open-loop execution. Vision-Language-Action (VLA) models pretrained on large-scale data streams have enabled direct mapping from visual observations and language instructions to robotic actions, but dominant paradigms suffer from either mode-averaging pathology in deterministic heads or computational inefficiency in generative diffusion policies. AnchorVLA addresses these limitations with an anchored diffusion policy that leverages trajectory-level priors and a test-time residual correction mechanism for robust, low-latency mobile manipulation.

Figure 1: Comparison of action generation policies for manipulation; unlike L1-based regression, AnchorVLA captures the required multimodality and remains executable in mobile manipulation settings.
Methodology
Problem Context and Multimodality
Tabletop manipulation tasks have a limited solution space, where L1 regression suffices and policies do not require expressive multi-modal generative capacity. In contrast, mobile manipulation tasks are under-constrained and exhibit multiple valid approach and execution trajectories, necessitating stochastic policies capable of modeling multimodal action distributions. L1 regression collapses diverse behaviors into physically infeasible averaged actions.
Anchor-Guided Diffusion Action Head
AnchorVLA introduces a trajectory vocabulary derived from clustering expert demonstration action chunks. At test time, instead of sampling from pure Gaussian noise, the policy initializes trajectory candidates from these well-localized anchors and applies truncated diffusion denoising around them. This architectural bias restricts sampling to the demonstration manifold, ensuring plausibility and drastically reducing sampling steps, thereby mitigating drift and the high latency associated with conventional diffusion processes.
The generative process comprises three core modules: (1) a VLA-Adapter backbone extracting visual, proprioceptive, and language features, (2) a conditional DiT-based denoiser performing anchor-localized truncated reverse diffusion, and (3) a compact scoring head selecting the most context-compatible denoised trajectory among the candidate set.
Figure 2: Overview of AnchorVLA; training with anchored diffusion plus scoring, and closed-loop inference with residual correction for trajectory refinement.
Residual Correction Module
To address open-loop cumulative drift introduced by chunk-based control (extended action sequences), AnchorVLA employs a lightweight residual correction module. This MLP receives current observations, the instruction, and intra-chunk action-phase, and outputs per-step corrections to the macro trajectory—enabling real-time micro-adjustments that substantially improve robustness under state-estimation errors, disturbances, and complex dynamics. Importantly, this module is computationally marginal relative to the full policy backbone.
Experimental Evaluation
Simulation on ManiSkill-HAB
Experiments on the ManiSkill-HAB benchmark encompass six diverse mobile manipulation tasks. AnchorVLA is evaluated against RGB- and pointcloud-based baselines, including π0, ACT, RDT, DP, DP3, and AC-DiT. All baselines are evaluated at a short action chunk horizon (H=2) to enable highly reactive policies. AnchorVLA not only delivers a higher overall success rate (64.0% at H=2) than the strongest baselines—exceeding AC-DiT (55.6%) and RDT (42.9%)—but maintains robust performance even when the action chunk is extended to H=5, remaining competitive and demonstrating tolerance to open-loop prediction and reduced compute.

Figure 3: Experimental environments used: ManiSkill-HAB simulation (left), Unitree Go2 + SO101 hardware platform for real-world manipulation (right).
Chunk Length and Robustness
Empirical analysis reveals deterministic L1 regression policies exhibit steep degradation as chunk length increases (from 42.8% at H=1 to 8.8% at H=10), confirming their inability to model temporally extended multimodal action distributions. AnchorVLA decays much more gradually under increasing chunk length, remaining effective and further reducing per-episode computation by lowering the frequency of expensive VLA backbone queries.
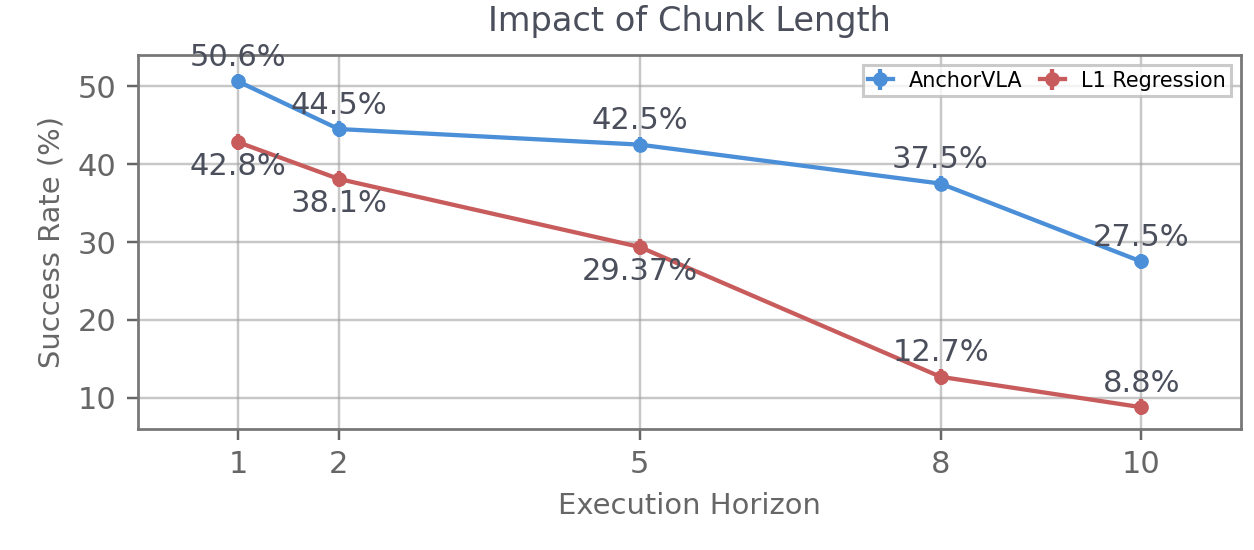
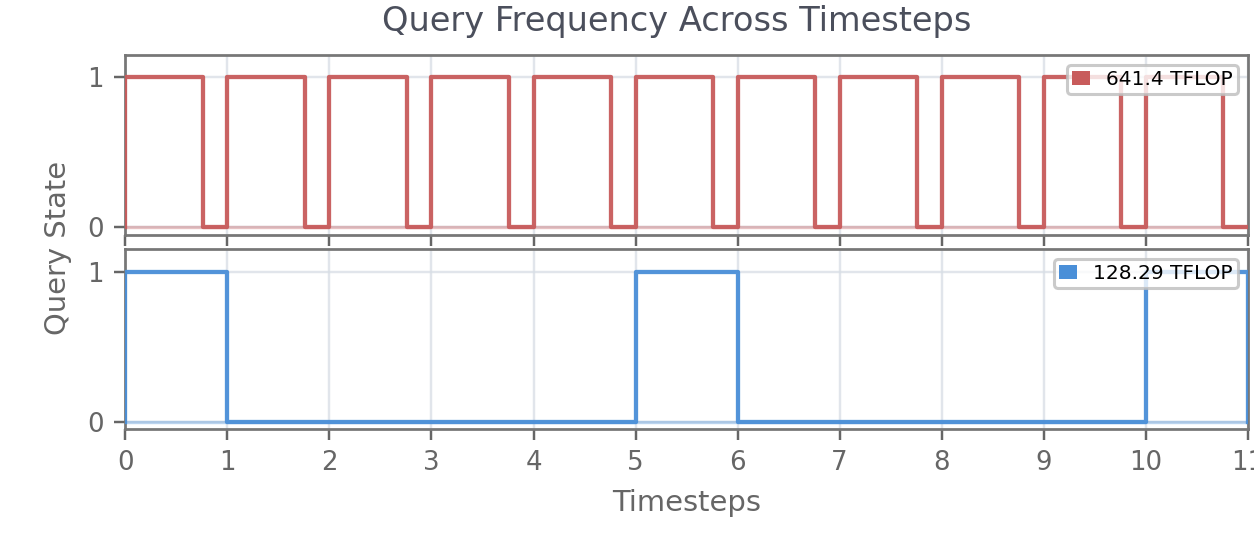
Figure 4: AnchorVLA outperforms deterministic L10 regression across all chunk lengths, with superior robustness and graceful performance degradation.
Trajectory Diversity and Optimal Proposal Selection
Qualitative visualization of policy rollouts demonstrates that AnchorVLA generates a rich set of multimodal candidate trajectories at each timestep. The anchor scoring head consistently selects optimal denoised samples compatible with dynamic context, sidestepping mode-averaging and avoiding physically infeasible transitions.

Figure 5: White point clouds visualize the breadth of candidate trajectories; colored points trace the selected denoised, executable trajectory tailored for the current scene and instruction.
Real-World Deployment
AnchorVLA is deployed on a Unitree Go2 quadruped with SO101 arm. In real-world tasks (Open Drawer, Lift Bag), it outperforms the parameter-matched SmolVLA-0.5B by a relative margin of 25% in average success rate (15% → 40%), demonstrating efficacy under real nonholonomic drift, visual variability, and base vibration.

Figure 6: Successful end states for Open Drawer and Lift Bag tasks in real-world deployment showcase AnchorVLA's capability across navigation and contact-rich object interaction.
Implications and Future Directions
AnchorVLA presents a compelling architectural template for addressing the unique requirements of end-to-end mobile manipulation. Anchored diffusion combines the representational power of generative policies with the sample efficiency and truncated inference of demonstration-derived priors, supporting robust multi-modal action generation under strict real-time constraints. The residual correction module demonstrates a practical and general pattern for low-latency, per-step refinement, particularly valuable as mobile manipulation systems transition from synthetic benchmarks to real-world deployment.
Future research will need to explore extension beyond offline imitation learning, integrating reinforcement learning for greater out-of-distribution robustness, and possibly combining online adaptation mechanisms to further close the loop under distribution shift and sensor drift. Moreover, the anchor-based framework suggests future opportunities for meta-learning demonstration segment priors or compositionally re-anchoring to novel skills via rapid re-clustering or self-supervised anchor augmentation.
Conclusion
AnchorVLA provides a technically rigorous solution to the limitations of both deterministic and classical diffusion-based policies in mobile manipulation. Through its combination of anchored generative priors, truncated denoising, integrated scoring for multi-modal plans, and closed-loop micro-correction, it achieves a new Pareto frontier of performance, robustness, and inference efficiency in both simulated and real-world whole-body control. This architecture is positioned to inspire further advancements in flexible, robust VLA systems for mobile and high-DoF manipulation (2604.01567).