- The paper introduces a discrete diffusion VLA model that decodes discretized action tokens within a unified transformer to overcome autoregressive bottlenecks.
- The method employs adaptive, parallel decoding with iterative re-masking for robust error correction and efficient inference.
- Experimental results on LIBERO and SimplerEnv benchmarks demonstrate improved success rates and reduced inference cost compared to traditional approaches.
Discrete Diffusion VLA: Discrete Diffusion for Action Decoding in Vision-Language-Action Policies
Introduction and Motivation
Discrete Diffusion VLA introduces a unified transformer-based approach for vision-language-action (VLA) policies, leveraging discrete diffusion for action decoding. Traditional VLA models either employ autoregressive (AR) token generation, which is inherently sequential and suffers from left-to-right bottlenecks, or continuous diffusion/flow-matching heads that are decoupled from the vision-language backbone and require specialized training and iterative sampling. Discrete Diffusion VLA addresses these limitations by modeling discretized action chunks as tokens and decoding them via a discrete diffusion process within a single transformer, trained with a standard cross-entropy objective. This design preserves pretrained vision-language priors, supports parallel and adaptive decoding, and enables robust error correction through iterative re-masking.
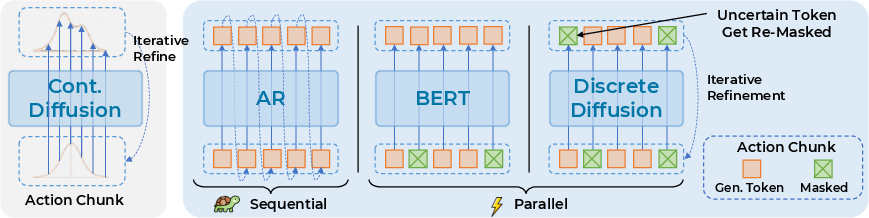
Figure 1: Paradigm comparison between continuous diffusion over action chunks and discrete token decoders: AR (sequential), BERT-style (parallel), and discrete diffusion with re-masking.
Methodology
Discrete Diffusion over Action Tokens
Actions are discretized into tokens using a binning scheme (e.g., 256 bins per dimension, binary gripper), forming fixed-length action chunks. The discrete diffusion process is formalized as a Markov chain, where each token is independently masked with probability βt at each step. The forward process progressively corrupts the action chunk, while the reverse process iteratively denoises masked tokens conditioned on multimodal context (vision and language).
During training, a random mask ratio is sampled, and the transformer is optimized to recover masked tokens using cross-entropy loss. At inference, all action positions are initialized as [MASK] and decoded in parallel over a small number of refinement rounds. High-confidence predictions are committed, while uncertain tokens are re-masked for further refinement. This adaptive decoding order follows a "first-easy, then-hard" philosophy, and secondary re-masking enforces cross-step consistency and error correction.
The architecture builds on OpenVLA's Prismatic-7B backbone, integrating SigLIP and DINOv2 visual encoders and a Llama 2 LLM. All modalities—vision, language, and action tokens—are processed by a single transformer. Action tokens use bidirectional attention, allowing full cross-modal fusion. The unified design enables parallel decoding and preserves the backbone's pretrained capabilities.
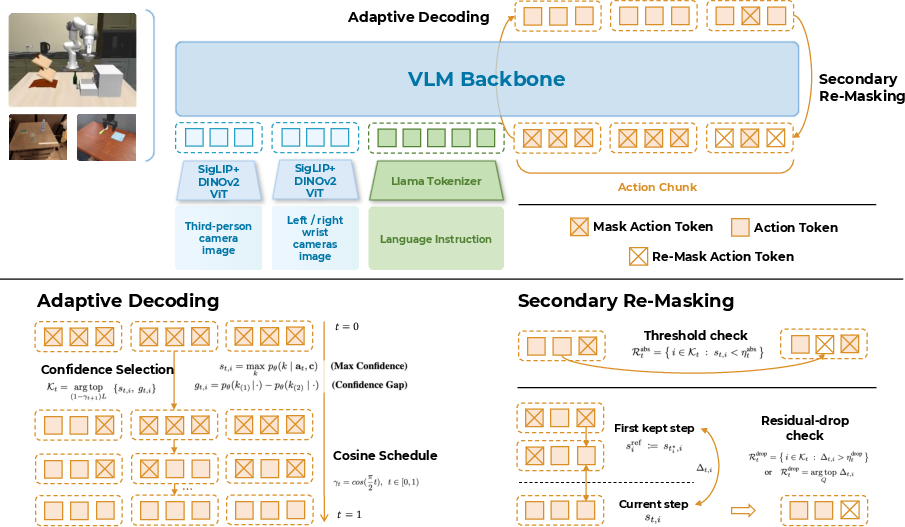
Figure 2: Discrete Diffusion VLA architecture: unified transformer encodes multi-view RGB and tokenized instruction, decodes discrete action chunks via iterative diffusion-style refinement. Adaptive decoding and secondary re-masking mechanisms are illustrated.
Algorithmic Pipeline
Training: For each minibatch, a mask ratio is sampled, action positions are masked, and the model is trained to recover the original tokens. The objective aligns with discrete diffusion via mask schedules and is compatible with standard LM training.
Inference: All action positions are masked initially. At each refinement round, the model predicts posteriors for masked positions, commits high-confidence tokens, and re-masks uncertain ones. The mask ratio is annealed using a cosine schedule. Secondary re-masking applies threshold and residual-drop checks to previously demasked tokens, preventing error propagation.
Experimental Results
Benchmarks
Discrete Diffusion VLA is evaluated on three robot settings:
LIBERO: Discrete Diffusion VLA achieves 96.3% average success rate, outperforming OpenVLA-OFT (Discrete) by +0.9 points and AR baselines by a wide margin. It also surpasses continuous diffusion baselines (e.g., π0) and models trained from scratch.
SimplerEnv–Fractal: Achieves 71.2% visual matching and 64.1% overall, exceeding π0 (58.8%) and OpenVLA-OFT (Discrete) (63.0%).
SimplerEnv–Bridge: Attains 49.3% overall, outperforming both AR and continuous diffusion baselines.
Ablation and Efficiency Analysis
Ablation studies show that a decayed temperature schedule during refinement yields the highest success rates (97.4% on LIBERO-Goal), supporting mild exploration early and sharper commitment later. The adaptive decoding strategy consistently outperforms parallel and random order baselines.
Inference efficiency is a key advantage: for an action chunk of length L, AR decoders require L sequential function evaluations, while Discrete Diffusion VLA requires only T parallel refinement steps (e.g., T=12 vs L=56 for LIBERO), decoupling inference cost from sequence length and enabling real-time deployment.
Implications and Future Directions
Discrete Diffusion VLA demonstrates that discrete diffusion can be natively integrated into VLA policies, enabling parallel, adaptive, and revisitable action decoding within a unified transformer. This approach preserves pretrained vision-language priors, supports efficient inference, and consistently outperforms both AR and continuous diffusion baselines under identical tokenization. The method lays the groundwork for scaling VLA models to larger architectures and datasets, with potential for broader multi-modal foundation models.
A limitation is the coarse granularity of fixed-bin action tokenization, which may lead to sub-bin precision loss. Future work could explore more expressive action encoding schemes or hybrid approaches that combine discrete diffusion with continuous-space objectives.
Conclusion
Discrete Diffusion VLA unifies vision, language, and action in a single transformer, leveraging discrete diffusion for adaptive, parallel, and robust action decoding. The architecture achieves state-of-the-art results across multiple robotic manipulation benchmarks, reduces inference cost, and preserves the scaling behavior of large vision-LLMs. This work provides a scalable foundation for future VLA research, with promising directions in action encoding and multi-modal integration.


