Embarrassingly Simple Self-Distillation Improves Code Generation
Abstract: Can a LLM improve at code generation using only its own raw outputs, without a verifier, a teacher model, or reinforcement learning? We answer in the affirmative with simple self-distillation (SSD): sample solutions from the model with certain temperature and truncation configurations, then fine-tune on those samples with standard supervised fine-tuning. SSD improves Qwen3-30B-Instruct from 42.4% to 55.3% pass@1 on LiveCodeBench v6, with gains concentrating on harder problems, and it generalizes across Qwen and Llama models at 4B, 8B, and 30B scale, including both instruct and thinking variants. To understand why such a simple method can work, we trace these gains to a precision-exploration conflict in LLM decoding and show that SSD reshapes token distributions in a context-dependent way, suppressing distractor tails where precision matters while preserving useful diversity where exploration matters. Taken together, SSD offers a complementary post-training direction for improving LLM code generation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Embarrassingly Simple Self-Distillation Improves Code Generation”
What is this paper about?
This paper shows a surprisingly simple way to make a code-writing AI better using only its own outputs. No teacher model, no test-case checker, and no reinforcement learning are needed. The method is called “Simple Self-Distillation” (SSD), and it helps the AI write correct code more often, especially on harder problems.
What questions did the researchers ask?
- Can a coding AI improve just by learning from code it writes itself, even if we don’t check whether that code is correct?
- If yes, why does this work? What changes inside the AI make its code better?
- Can this work across different AI models and sizes, and does it beat the best possible settings for how we sample text from the model?
How did they do it? (Method, in everyday terms)
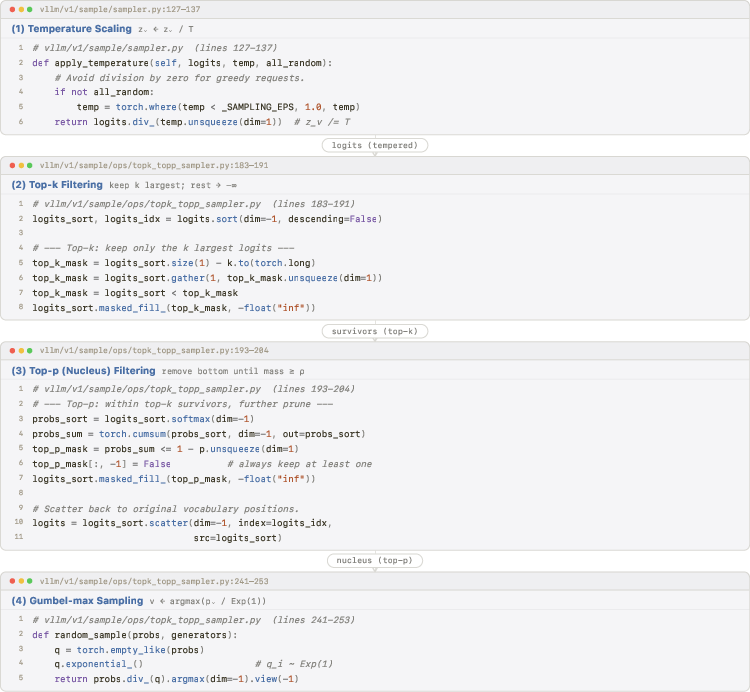
Think of code generation as the AI writing a program one token (tiny piece of text) at a time. The team used a three-step process:
- SSD in a nutshell: 1) Have the model solve lots of coding problems and save its answers. When sampling each answer, they add some randomness using a “temperature” setting (think: how adventurous the model is) and “truncation” (only consider the top few likely tokens, like choosing from the best options). 2) Fine-tune the model on those saved answers using standard supervised training (the same way models learn from human-written examples, but here the examples come from the model itself). 3) At test time, sample code with a chosen “evaluation” temperature and truncation.
Key terms, simply explained:
- Temperature (): Controls how random the AI is when picking the next token. Low = safe and predictable. High = more adventurous and varied.
- Truncation (top-k / top-p): The model only picks from the best-scoring tokens (like saying “only choose from the top 10” or “choose from the smallest set of tokens whose probabilities add up to 90%”).
- Supervised fine-tuning: Training the model to better match example outputs by adjusting its internal probabilities.
Why this might help:
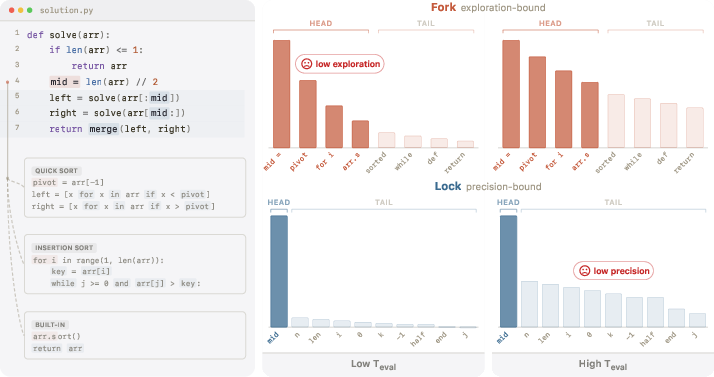
- Writing code mixes two kinds of steps:
- “Forks”: Moments where several different next steps are reasonable (e.g., choosing one of many valid algorithms).
- “Locks”: Moments where there is only one or very few correct next tokens (e.g., a specific keyword, bracket, or variable name).
- One global temperature can’t be perfect for both at once. Low temperature is great for locks (precision), but it limits exploration at forks. High temperature helps exploration at forks but risks mistakes at locks. The paper calls this the “precision–exploration conflict.”
SSD’s trick is that training on the model’s own temperature-shifted and truncated outputs reshapes the model’s internal probabilities:
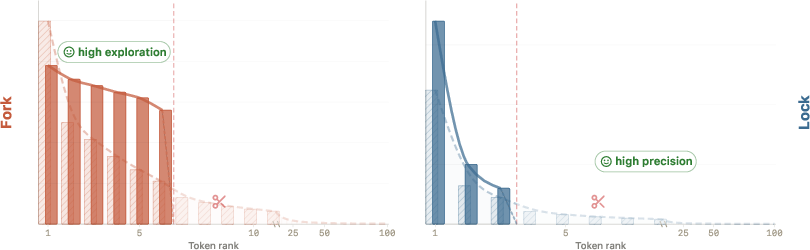
- It cuts down “distractor tails” (unlikely but tempting wrong tokens) where precision matters (locks).
- It keeps multiple good options alive where exploration matters (forks).
What did they find?
The results are strong and consistent:
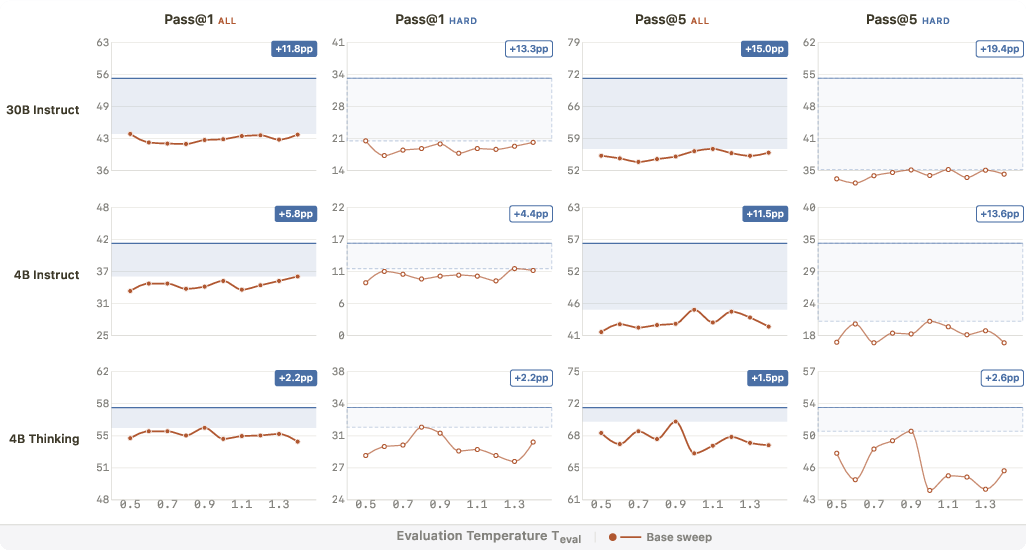
- Big improvement on a live coding benchmark:
- For the Qwen3-30B-Instruct model, the score “pass@1” (solving a problem on the first try) went from 42.4% to 55.3%. That’s a large jump, especially for a method that uses no correctness checks.
- “Pass@5” (solving a problem within five tries) improved even more, showing the model kept or improved its diversity of good attempts.
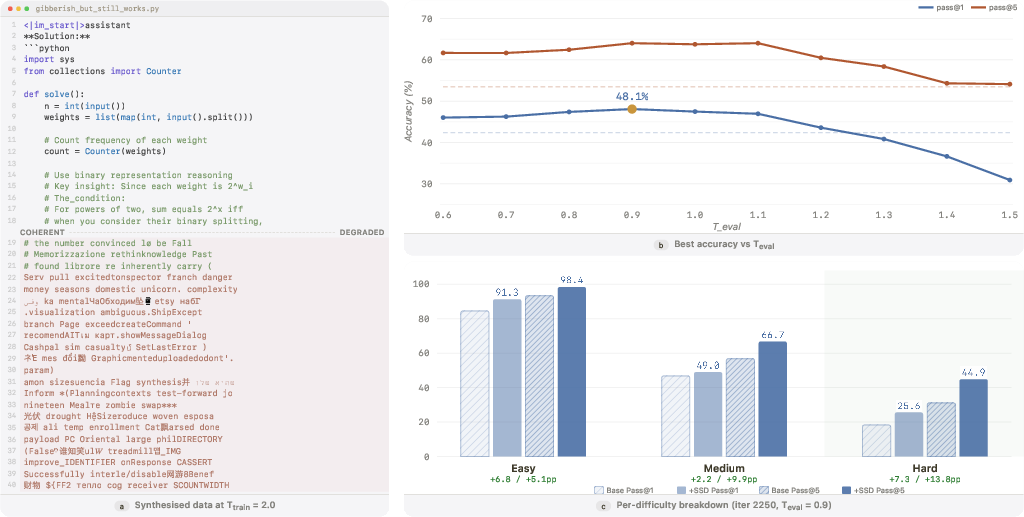
- Gains concentrate on harder problems:
- The biggest improvements happened on medium and hard coding tasks, not just easy ones.
- Works across models and sizes:
- The method helped several different models (Qwen and Llama families, 4B–30B sizes, “instruct” and “thinking” variants).
- You can’t get these gains just by tweaking sampling settings:
- The authors tried sweeping many temperature settings on the original model (without training). It helped a little, but never matched SSD. That means SSD changes the model itself in a helpful way that decoding settings alone can’t copy.
Why it works (intuition the authors tested):
- Fork vs. lock behavior:
- After SSD, the model’s probabilities at locks become “spikier” (the correct token more clearly stands out) so random sampling is less likely to fall for distracting wrong tokens.
- At forks, several top choices remain and become more evenly balanced, so modest randomness can help the model explore good solution paths.
- Training and decoding work together:
- Training reshapes the distribution (safer locks).
- Decoding then uses that safety to explore forks a bit more effectively.
Surprising stress test:
- Even when the training samples were very messy (very high temperature, no truncation, many outputs looked like gibberish), SSD still gave noticeable improvements. This suggests the gains come from reshaping the model’s probabilities—not just from learning correct code—especially when combined with careful decoding at test time.
Why is this important?
- Cheaper and simpler post-training: SSD doesn’t need a smarter teacher model, correctness checks, or reinforcement learning. It’s easy to run and scales with the model you have.
- Helps where it matters most: Harder problems benefit the most, and code variety improves too (better pass@5), which is useful when trying multiple solutions.
- A new angle on improving code AIs: It shows that code models may already “know” more than they show with standard decoding. SSD unlocks that by reshaping their probabilities in a smart, context-dependent way.
Takeaway
Simple Self-Distillation is a surprisingly effective, low-effort way to upgrade code-generating AIs using only their own outputs. It works because it makes the model more precise when precision is needed and more open-minded when different solution paths are possible. This could make future code assistants better, faster to train, and easier to maintain—without requiring expensive labels, verifiers, or complex training pipelines.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper, to guide future research.
- Domain generalization beyond competitive programming is untested: SSD is trained on rSTARcoder seed problems and primarily evaluated on LiveCodeBench (LCB). Its effectiveness on real-world software engineering tasks (multi-file projects, API usage, codebase context, refactoring, bug fixing) and across diverse languages is unknown.
- Breadth of out-of-domain impact is unclear: The paper states performance remains “broadly stable” on non-coding benchmarks for 30B models (appendix), but provides no systematic, multi-benchmark evidence (e.g., natural language tasks, instruction following, safety alignment, math, code understanding) and no results for 4B/8B models.
- Risk of training on incorrect or low-quality code is unquantified: SSD trains on unverified samples with minimal filtering; the proportion of correct code, syntactic validity, runtime correctness, and potential propagation of anti-patterns or insecure code are not measured.
- Data leakage safeguards are unspecified: It is not reported whether training prompts overlap with LCB problems or related distributions; no explicit decontamination checks or hash-based overlap audits between SSD data and eval sets are described.
- Long-horizon stability and convergence are untested: SSD is trained for a fixed (short) number of steps; whether repeated or prolonged SSD cycles lead to degradation, over-sharpening, loss of exploration, or collapse (as seen in some unsupervised RL variants) is unknown.
- Sensitivity to training duration and schedules is not explored: The impact of different learning rates, schedulers, batch sizes, and number of iterations (especially for thinking models where iterations were much fewer) remains open.
- Hyperparameter robustness is only partially mapped: While , , and a few truncation settings are explored, broader grids (e.g., diverse top-k/top-p, min-p, repetition/frequency penalties, alternative truncation orders) and cross-model robustness are not systematically studied.
- One-shot sampling per prompt (N=1) is assumed sufficient: The benefits of multiple samples per prompt during SSD data synthesis—and how they interact with truncation and temperature—are not evaluated.
- Iterative or multi-round SSD is unexamined: Whether repeating SSD (using the improved model to resample and retrain) yields compounding gains, plateaus, or degeneration is unknown.
- Comparative baselines are limited: There is no head-to-head comparison with (i) self-imitation on greedy or low-temperature outputs, (ii) correctness-filtered self-training (e.g., STaR-like), (iii) purely decode-time dynamic/heterogeneous temperature policies, or (iv) simple entropy-minimization or confidence-weighted SFT without verification.
- Interaction with light-weight verification is unexplored: Whether a minimal fraction of execution-based filtering (e.g., quick unit tests) synergizes with SSD to boost gains without full verification remains an open design point.
- Mechanistic claims lack direct token-level validation: The lock/fork distinction is supported by toy and aggregate evidence, but there is no automated procedure to label lock/fork positions in real code (e.g., via AST, syntax, or dataflow) and directly measure tail suppression and head reshaping at those positions.
- Calibration and uncertainty effects are unknown: SSD reshapes token distributions, but its impact on calibration, confidence alignment, and risk-aware decoding has not been assessed.
- Diversity quality vs. correctness is not dissected: Pass@5 gains suggest diversity, but there is no analysis of whether additional samples represent distinct correct algorithmic families versus diverse failure modes.
- Safety and security implications are unassessed: The impact on insecure coding patterns, vulnerability introduction (e.g., cryptographic misuse, injection-prone code), or unsafe API usage is not measured.
- Transfer to interactive/multi-turn coding and debugging remains open: SSD is evaluated on single-shot competitive problems, not on iterative development settings (tool use, tests, fixes, IDE loops).
- Effect on code style, maintainability, and readability is unmeasured: SSD may alter stylistic distributions; impacts on style guides, documentation quality, or maintainability are unknown.
- Impact on general-language capabilities is underreported: Beyond a brief claim of stability on some benchmarks (for 30B), the broader trade-offs with natural language tasks and instruction following are not quantified (especially for smaller models).
- Theoretical decomposition relies on assumptions not fully enumerated: The support-compression and within-support reshaping objective (Rényi-entropy term, KL alignment) is presented without a full accounting of conditions under which it holds or fails, nor proofs of convergence or fixed points under repeated SSD.
- Limits of the composition are unclear: The effective-temperature heuristic is validated in narrow settings; its generality under truncation, different models, and larger datasets remains to be tested.
- Failure cases and regressions are not analyzed: Some cells show smaller or negative changes (per table shading), but the paper does not characterize when and why SSD hurts performance, nor provide guidance to avoid such regimes.
- Model- and scale-transferability is only partially shown: Tests cover Qwen and Llama at 4B/8B/30B; generality to larger dense models (e.g., 70B+) or different MoE topologies, and to other families, remains open.
- Parameter-efficient fine-tuning (PEFT) vs. full fine-tuning is not evaluated: Whether LoRA/adapter SSD matches full SFT gains at lower cost is unknown.
- Compute and cost-benefit analysis is missing: The paper does not quantify wallclock time, GPU hours, or generation costs versus performance gains, hindering practical adoption decisions.
- Robustness to implementation details is untested: Results rely on a specific decoding pipeline (temperature→top-k→top-p in vLLM); sensitivity to different ordering or sampling implementations is not studied.
- Long-context and repository-scale code tasks are not evaluated: Despite using long sequence lengths, SSD’s impact on very long contexts (e.g., 100K-token repos) or cross-file dependencies remains untested.
- Language and ecosystem coverage is unspecified: No analysis by programming language, library ecosystem, or problem category (e.g., dynamic vs. static typing, algorithmic vs. API-heavy tasks) is provided.
- Synergy with RL or verifier-based methods is unproven: The paper claims complementarity but does not test pipelines where SSD initializes or is combined with RL/verification to assess additive gains.
- Seed variability and statistical confidence are not reported: There is no multi-seed analysis or statistical testing to quantify variance of gains across runs and decoding seeds.
- Reproducibility scope is unclear: While code is linked, availability of the exact SSD datasets (prompts and generated outputs), trained checkpoints, and all configs for end-to-end replication is not fully specified.
Practical Applications
Immediate Applications
The paper’s “Simple Self-Distillation (SSD)” method is deployable today for code-focused LLMs because it requires only prompts, the model itself, and standard supervised fine-tuning. Below are concrete, sector-linked use cases and how to put them into practice.
- Low-cost post-training upgrades for existing code models (Software/AI)
- What: Improve a model’s pass@1 and pass@5 on coding tasks without verifiers, reward models, teachers, or execution environments.
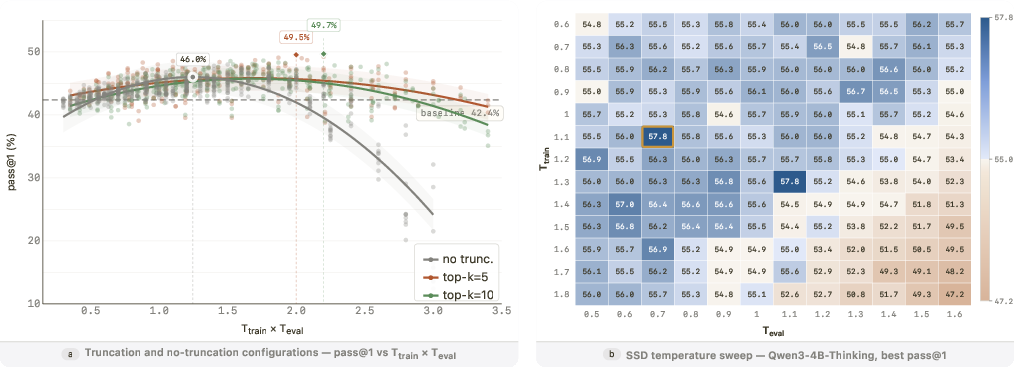
- How: Sample 1 solution per prompt using higher training temperature with modest truncation (e.g., T_train≈2.0 with top-k≈10), fine-tune via SFT, and at inference use a moderately higher temperature (e.g., T_eval≈1.0–1.2) and multi-sample when possible.
- Tools/workflows: vLLM for sampling; Megatron-LM, Hugging Face TRL/PEFT or LoRA for SFT; CICD to schedule SSD runs; evaluation with LiveCodeBench or internal harnesses.
- Assumptions/dependencies: Access to a code-capable base model (e.g., Qwen/Llama), modest compute for SFT, and a problem-prompt set. Gains are strongest on harder problems; decode-only tuning cannot match SSD’s improvements.
- Domain adaptation to proprietary codebases without labels or verifiers (Software, Enterprise IT, Finance)
- What: Tailor a code assistant to internal APIs, patterns, and compliance constraints using only internal prompts and self-sampled outputs.
- How: Build a prompt set reflecting internal tasks/APIs, run SSD, then deploy the adapted model within the enterprise.
- Tools/workflows: Internal prompt mining from tickets/repos; nightly self-sampling; SFT; regression tests on internal code tasks.
- Assumptions/dependencies: Strong internal prompts; guardrails to prevent reinforcing bad patterns; privacy-preserving infrastructure.
- Privacy-preserving adaptation for regulated settings (Healthcare, Legal/Compliance)
- What: Improve models for data-cleaning scripts, ETL, or report-generation code using only in-house prompts, without shipping data to third-party verifiers/teachers.
- How: SSD on de-identified/problem-only prompts; evaluate internally.
- Tools/workflows: On-prem GPU clusters; privacy-approved logging of prompts; internal test suites.
- Assumptions/dependencies: Careful prompt curation to avoid PHI/PII leakage; legal review of model licensing and internal use.
- “Self-improving mode” in IDEs and code assistants (Software Tooling/DevEx)
- What: Productize an offline maintenance routine that periodically self-samples from seen tasks and self-distills for better future suggestions.
- How: Add a maintenance job that collects recent task prompts (not code), samples once per prompt, SFTs, and pushes a new model checkpoint; exploit higher pass@5 with multi-sample inference and ranking.
- Tools/workflows: IDE plugin/agent; feature flags; A/B evaluation; autoscaling training jobs.
- Assumptions/dependencies: Telemetry consent and governance; monitoring to detect regressions and avoid drift.
- Boosting multi-sample workflows (e.g., pass@5-aware systems) (Software/Platform)
- What: Leverage SSD’s larger relative gains at pass@5 to improve reranking, majority voting, or execution-based selection.
- How: After SSD, use slightly higher inference temperatures and generate 3–5 candidates; rank by static analyzers, linters, or quick-run unit tests when available.
- Tools/workflows: Rerankers; simple execution harness; caching to control costs.
- Assumptions/dependencies: Some runtime or static checks increase the benefits; if none, rely on human-in-the-loop.
- Data-scarce organizations’ performance uplift (Academia/SMBs/Open Source)
- What: Achieve meaningful gains without labeled solutions or expensive RL/verifiers.
- How: Use public problem prompts (e.g., de-duplicated competitive programming sets) and 1-sample SSD; fine-tune modest models with LoRA or QLoRA.
- Tools/workflows: Cloud A10/L40/A100; LoRA; small-batch SFT.
- Assumptions/dependencies: Avoid test-set contamination; monitor out-of-domain performance.
- Faster, simpler post-training pipelines (MLOps/Platform)
- What: Replace RL/verification-heavy stacks with a simpler, more robust SSD loop for routine post-training.
- How: Integrate SSD into MLOps with temperature/truncation sweeps and automated evaluation; store checkpoints along a temperature band.
- Tools/workflows: Pipelines for sampling→SFT→evaluation; hyperparameter sweeps on T_train/T_eval; model registry.
- Assumptions/dependencies: Compute budget for sweeps; consistent evaluation; attention to truncation during training for best gains.
- Robustness via wider effective temperature band (Software/Infra)
- What: Post-SSD, models tolerate higher evaluation temperatures, improving exploration at forks while keeping locks precise, aiding deployment across variable environments.
- How: Calibrate T_eval around the paper’s “effective temperature” intuition (T_eff = T_train × T_eval) and choose operating points that maximize performance.
- Tools/workflows: Temperature sweeps; telemetry-driven auto-tuning.
- Assumptions/dependencies: Monitoring to prevent overheating (too-high T_eval degrades quality); truncation at inference for stability.
- Edge/local model enhancement without external connections (Consumer/On-device AI, Robotics/Embedded)
- What: Improve locally hosted small models (4B–8B) using only local prompts and outputs when connectivity is limited.
- How: SSD with on-device sampling and small SFT (e.g., LoRA); deploy improved checkpoint on-device.
- Tools/workflows: Mobile/edge inference toolchains; incremental updates.
- Assumptions/dependencies: Device supports small-scale fine-tuning; careful energy/runtime budgeting.
- Research enabler: studying precision–exploration conflict (Academia)
- What: Immediate framework to probe how token distributions behave at locks/forks using SSD-induced shifts.
- How: Analyze token-level mass before/after SSD; measure entropy changes under truncation; replicate temperature-composition findings.
- Tools/workflows: Instrumented decoders; token-level logging; synthetic toy environments.
- Assumptions/dependencies: Access to model internals and sampling hooks; careful experimental controls.
Long-Term Applications
These require more research, scaling, or safeguards but have clear paths suggested by the paper’s mechanism and evidence.
- Continuous self-improvement pipelines with safety gates (Software Platforms/DevOps)
- What: Always-on SSD loops that learn from new prompts, with automated evaluations and “promotion” gates before deployment.
- How: Nightly SSD runs → regression suites (e.g., unit tests, secure coding checks) → staged rollout; integrate pass@5 workflows for exploration.
- Tools/products: “Self-tuning” code assistant platforms; MLOps governance dashboards.
- Assumptions/dependencies: Strong test coverage; drift detection; audit trails; rollback plans.
- Hybridization with verifiers/RL for larger gains (AI/Software)
- What: Use SSD as a stabilizing preconditioning step before light-weight verifier-based filtering or RL for hard tasks.
- How: SSD to clean distractor tails and widen viable temperatures, then add minimal execution tests or value-model rewards.
- Tools/workflows: Two-phase training; sparse verifier calls; budget-aware RL fine-tuning.
- Assumptions/dependencies: Extra engineering for verifiers; compute to support second phase; careful reward design to avoid collapse.
- Context-aware decoding policies that adapt to locks/forks (Software/Inference Systems)
- What: Runtime detectors estimate whether a position is a “lock” or “fork,” choosing temperature/truncation adaptively.
- How: Token-level classifiers using entropy, gradient norms, or calibrated uncertainty drive per-token T_eval and truncation thresholds.
- Tools/products: Smart decoders in vLLM or custom inference; IDE-integrated settings that adjust on the fly.
- Assumptions/dependencies: Additional inference latency; calibration of detectors; avoidance of oscillatory behavior.
- New training objectives for “support compression” and “head reshaping” (ML Research)
- What: Replace implicit SSD effects with explicit losses that compress diffuse tails while preserving exploration within head tokens.
- How: Loss terms approximating the paper’s decomposition (support mass, Rényi-entropy shaping, tempered KL alignment).
- Tools/products: Open-source training objectives; token-level regularizers in common frameworks.
- Assumptions/dependencies: Theoretical work to ensure stability; generalization beyond code.
- Extending SSD beyond code to math reasoning, planning, and dialog (Education, Operations, Customer Support)
- What: Leverage SSD to improve chain-of-thought breadth and correctness where verifiers are costly or unavailable.
- How: Curate domain prompts; use SSD; evaluate on math/logic benchmarks and task-specific metrics.
- Tools/products: Self-improving math tutors; planning assistants; customer service tools with better reasoning diversity.
- Assumptions/dependencies: Evidence in the paper is strongest for code; broader domains may need modified truncation/temperatures or small verifier hooks.
- Personalized learning and course-specific coding assistants (Education)
- What: Course or cohort-specific assistants that self-distill on recent assignments/exercises to improve help quality.
- How: Teachers release prompt banks; the assistant SSDs and deploys updates weekly; exploit pass@5 with rubric-based selection.
- Tools/products: LMS-integrated assistants; educator dashboards.
- Assumptions/dependencies: Cheating/misuse safeguards; careful curation to avoid leaking solutions.
- Verticalized small-model marketplaces (Industry/Startups)
- What: Offer SSD-tuned small models per vertical (e.g., data engineering, DevOps, embedded, scientific Python) that run cheaply.
- How: Assemble vertical prompt corpora; SSD on small open-weight models; deliver as on-prem containers or private endpoints.
- Tools/products: “Model packs” with SSD configs, decoding presets, and evaluation reports.
- Assumptions/dependencies: Legal clarity on base model licenses; vertical-specific evaluation suites; support SLAs.
- Edge/IoT robotics controllers generating platform-specific code (Robotics/Embedded)
- What: Improve code synthesis for microcontrollers and robot SDKs with self-distilled, platform-tailored distributions.
- How: SSD using prompts focused on target SDKs/APIs; deploy with multi-sample inference + static analysis.
- Tools/products: Onboard self-adapting code agents; auto-patching scripts.
- Assumptions/dependencies: Tight resource constraints; safety validation for physical systems.
- Governance and policy frameworks for self-improving models (Policy/Standards)
- What: Standards defining evaluation gates, auditing, and reporting for SSD-derived updates in production.
- How: Require disclosure of SSD parameters (T_train, truncation), evaluation sets, and regression results; mandate rollback mechanisms.
- Tools/products: Compliance checklists; certification programs for self-improving AI systems.
- Assumptions/dependencies: Cross-industry consensus; regulators’ capacity to assess technical pipelines.
- Risk management against drift and error reinforcement (Policy/Safety, Software Quality)
- What: Controls that prevent compounding errors when training on unverified outputs.
- How: Canary prompts; periodic external benchmark checks; conservative update frequency; dual-model comparisons.
- Tools/products: Drift monitors; anomaly detectors; human-in-the-loop sign-off.
- Assumptions/dependencies: Organizational processes for sign-off; culture that prioritizes safety over raw velocity.
Notes on feasibility and dependencies across applications
- Data/prior setup: A prompt set representative of the target domain is essential; single-sample SSD works surprisingly well, but truncation during training improves results.
- Compute: The paper used 8×B200 GPUs for 30B MoE; smaller models can be fine-tuned with LoRA/QLoRA on commodity GPUs.
- Inference strategy: Many benefits (especially pass@5) assume multi-sample inference and simple ranking heuristics; if only single-sample decoding is allowed, expect smaller gains.
- Generalization: The strongest evidence is for code; transfers to math/reasoning are plausible but require validation.
- Safety: Self-distillation can reinforce artifacts; regression tests, static analyzers, and drift monitors are recommended, especially outside the coding domain.
- Licensing/IP: Training on your own model’s outputs reduces dependencies on external labeled data, but base-model licenses still apply; ensure internal data governance.
Glossary
- AdamW: A variant of the Adam optimizer with decoupled weight decay, commonly used for training large models. "using AdamW with cosine decay (peak LR )"
- cross-entropy loss: A standard loss function for training probabilistic classifiers or LLMs by maximizing likelihood of target tokens. "fine-tune on those raw, unverified samples via standard cross-entropy loss."
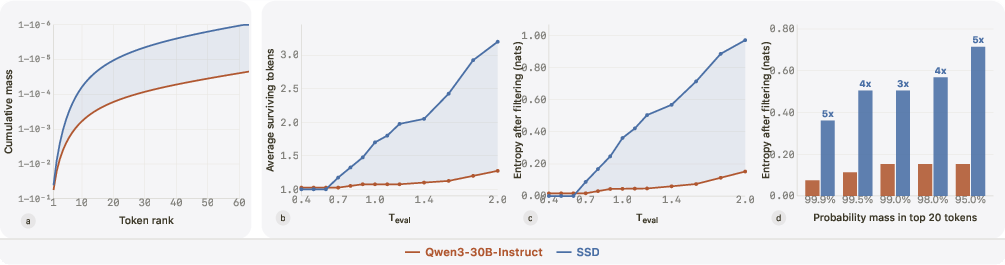
- effective temperature: The product of training-time and evaluation-time temperatures that jointly governs performance under SSD. "Define $T_{\textsf{eff} = T_{\textsf{train} \cdot T_{\textsf{eval}$; we show that $T_{\textsf{eff}$ governs performance."
- fork: A generation context where multiple plausible continuations exist and exploration is needed. "We call the second a fork~\citep{bigelow2025forking,wang2025beyond8020}: a position where the distribution is spread across multiple plausible tokens that can lead to meaningfully different downstream continuations."
- Gumbel-max trick: A sampling method that draws from a categorical distribution by adding Gumbel noise to logits and taking argmax. "Sampling via the Gumbel-max trick."
- KL divergence: A measure of how one probability distribution diverges from a reference distribution; used to align with tempered base-model probabilities. "T \cdot \mathrm{KL}!\bigl(q \,|\, p_{\theta,T}(\cdot \mid S)\bigr)"
- LiveCodeBench: A dynamic benchmark for code generation evaluation with versions and difficulty splits. "SSD improves Qwen3-30B-Instruct from 42.4\% to 55.3\% pass@1 on LiveCodeBench\,v6"
- lock: A generation context where one token is clearly correct and precision (tail suppression) matters. "We call the first a lock: a position where the distribution is sharply peaked, with very few tokens carrying most of the mass and a long distractor tail carrying the rest."
- Mixture-of-Experts (MoE): A model architecture that routes inputs to a subset of specialized expert networks, increasing capacity with sparse activation. "Qwen3-30B-A3B-Instruct-2507 (MoE, 30B total / 3B active; hereafter Qwen3-30B-Instruct)"
- nucleus sampling (top-p): A truncation method that keeps the smallest set of tokens whose cumulative probability exceeds p, then samples from it. "Step~3: Top- (nucleus) filtering."
- pass@1: The fraction of problems solved when only a single sample/output is considered. "The primary metric is pass@1; we also report pass@5 and per-difficulty breakdowns."
- pass@5: The fraction of problems solved when up to five samples/outputs are considered. "Coverage improvements are larger still: hard-problem pass@5 rises from 31.1\% to 54.1\%"
- precision-exploration conflict: The tension between needing low temperature for precision at locks and higher temperature for exploration at forks. "we call this tension the precision-exploration conflict."
- self-distillation (SSD): Training a model on its own sampled outputs (with temperature/truncation) using standard supervised objectives, without external supervision. "Our method, simple self-distillation (SSD), is embarrassingly simple: sample solutions from the base model with specified temperature and truncation, then fine-tune on those raw, unverified samples via standard cross-entropy loss."
- support compression: Reducing probability mass on low-probability tails by constraining the retained token set during training-time sampling. "SSD induces support compression and within-support reshaping."
- supervised fine-tuning (SFT): Post-training with labeled (or pseudo-labeled) sequences using teacher-forced likelihood maximization. "We fine-tune the model on $\mathcal{D}_{\textsf{SSD}$ with standard supervised fine-tuning~(SFT):"
- temperature scaling: Adjusting logits by a temperature to sharpen or flatten the distribution before sampling. "Step~1: Temperature scaling."
- top-k filtering: Truncating the distribution to the k highest-probability tokens prior to sampling. "Step~2: Top- filtering."
- truncation: Restricting the sampling support (via top-k/top-p) to suppress low-probability distractor tails. "training-time truncation provides an additional gain channel."
- vLLM: A high-throughput LLM inference framework used for decoding and evaluation. "All inference in this paper uses vLLM~v0.11.0~\citep{kwon2023vllm}"
- within-support reshaping: Reweighting probabilities among the retained tokens to preserve useful diversity at forks while keeping tails suppressed. "SSD induces support compression and within-support reshaping."
Collections
Sign up for free to add this paper to one or more collections.