- The paper introduces the Multiscreen architecture, a screening mechanism that replaces standard softmax attention by explicitly discarding irrelevant keys.
- It demonstrates that Multiscreen achieves approximately 40% fewer parameters and stable training at larger learning rates, enhancing overall model efficiency.
- Robust long-context generalization and near-perfect key-value retrieval, along with reduced inference latency, highlight the practical benefits of this approach.
Absolute Relevance in Sequence Modeling: Analysis of the Multiscreen Architecture
Introduction and Motivation
The paper "Screening Is Enough" (2604.01178) introduces the Multiscreen architecture, asserting that a fundamental limitation exists in standard softmax attention: it inherently defines only relative query–key relevance and cannot explicitly reject irrelevant keys. This property leads to issues with long-context modeling, parameter inefficiency, and unnatural "competition" among keys, particularly as context window size grows. The authors propose that screening, an explicit threshold-based selection mechanism, offers superior inductive biases for context utilization and model efficiency.
Theoretical Framework and Architectural Innovations
From Softmax Attention to Screening
Traditional Transformers use a softmax-based attention module, which:
- Produces unbounded query–key dot products as attention scores.
- Normalizes these into a probability distribution across all keys (attention weights), ensuring their sum is one per query.
This design means that all unmasked keys participate in attention and some weight is always distributed, even if no keys are relevant to the query.
Multiscreen replaces this mechanism with a screening-based approach in which:
- Both queries and keys are normalized.
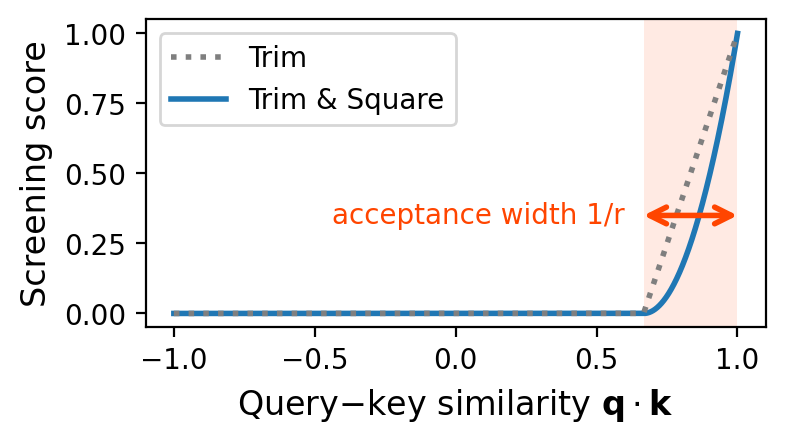
- Similarity is computed and thresholded independently for each key, with only strongly similar keys contributing to the result.
- Relevance is defined on an absolute scale—irrelevant keys are simply discarded.
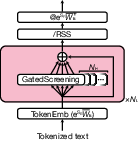
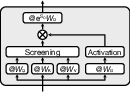
Figure 1: The Multiscreen architecture replaces softmax attention modules with stacks of parallel, threshold-based gated screening tiles, each operating independently on input representations.
The gating and aggregation mechanism diverges fundamentally from relative competition, providing a model with the ability to represent the absence of relevant context and to avoid unnecessary computation over distant or irrelevant tokens.
Screening Unit Mechanics
A screening unit in Multiscreen executes the following steps:
This confers unique properties:
- Each key’s contribution is independent of others—no competition or required redistribution.
- The screening window (context range) is learned and can default to full context when necessary, reducing computation adaptively.
- The minimal positional encoding is only active for short-range dependencies, preventing positional extrapolation artifacts beyond the training range.


Figure 3: Distance-aware relevance maps show that each screening tile independently learns its effective context and acceptance width for query–key interactions, many becoming highly sparse.
Empirical Results
Scaling and Parameter Efficiency
The empirical scaling study shows that, for a matched validation loss, Multiscreen models require ~40% fewer parameters than Transformer baselines across a range of model sizes.
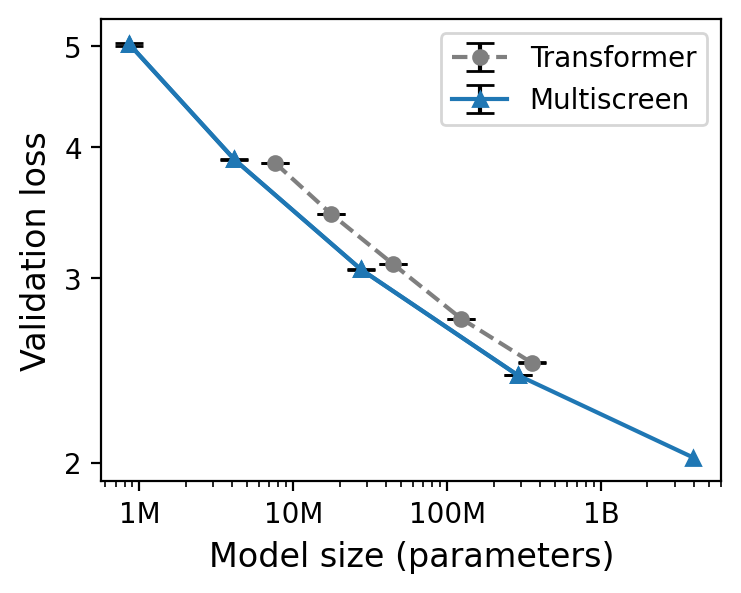
Figure 4: Multiscreen achieves equivalent perplexity with 40% fewer parameters compared to Transformers, as seen in scaling curves across model sizes.
This suggests that screening provides a more effective inductive bias for context aggregation, enabling reduction in model scale for a fixed compute budget.
Training Stability at Large Learning Rates
Multiscreen enables stable optimization at substantially larger learning rates versus Transformers. While Transformer training diverges for learning rates above 10−3 (for 45M-parameter models), Multiscreen remains stable up to 20.
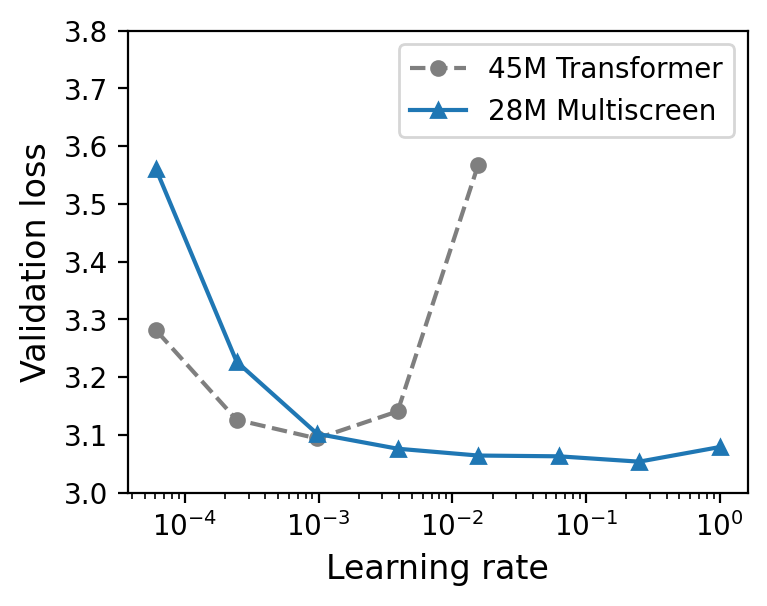
Figure 5: Multiscreen is invulnerable to training divergence at large learning rates, permitting more aggressive optimization hyperparameters.
Related analyses display that gradient norms in Multiscreen decay rapidly and remain low, without the variance spikes or non-zero gradient floor observed in Transformers.
Long-Context Generalization and Retrieval
Multiscreen demonstrates robust generalization to contexts far exceeding those seen during training. Evaluations on PG-19 with positions far beyond training lengths illustrate that perplexity remains stable and does not degrade abruptly, unlike Transformers, which suffer sharp breakdowns when exceeding trained context lengths, regardless of RoPE scaling trickery.
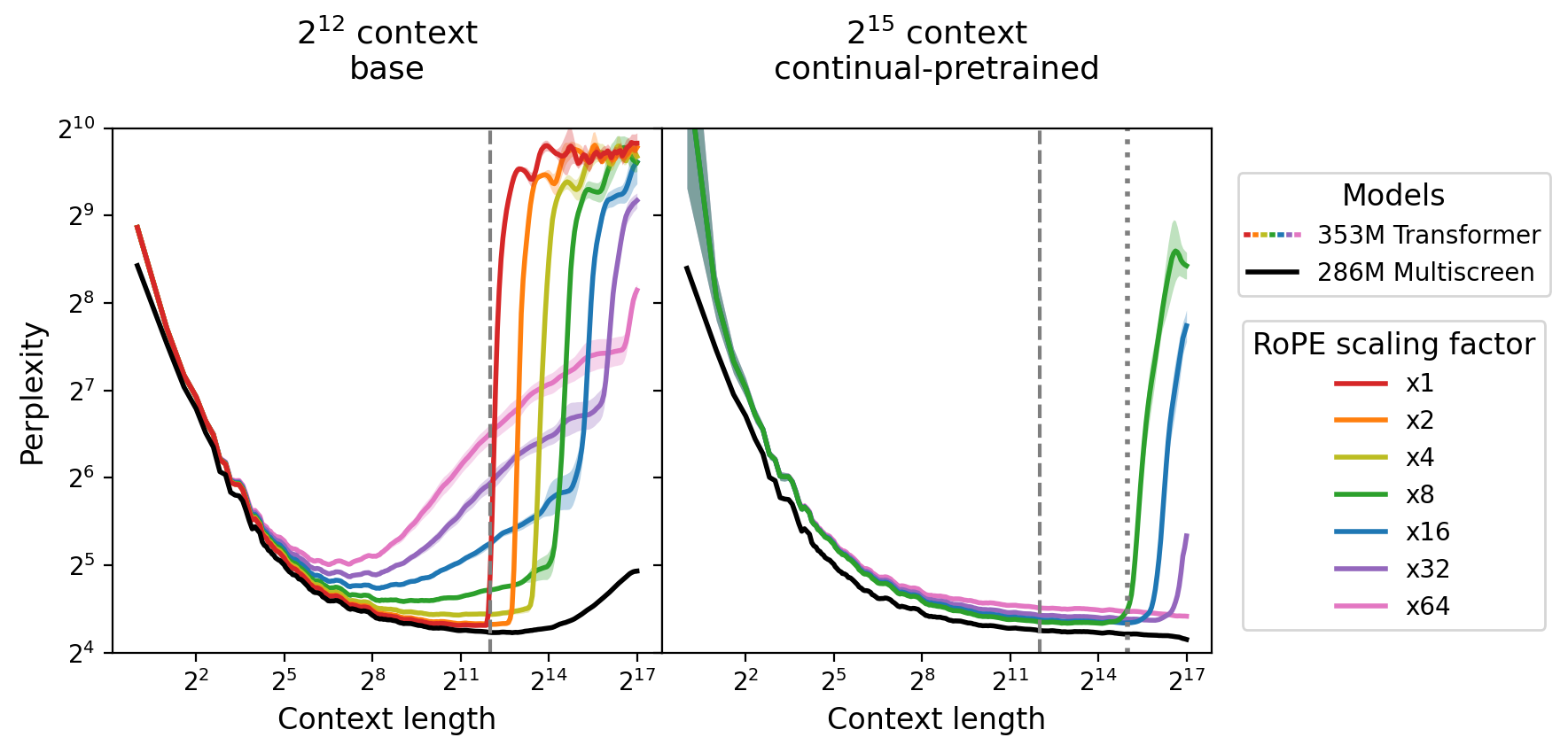
Figure 6: Multiscreen maintains flat perplexity across long-context positions, whereas Transformers undergo substantial perplexity inflation outside the training window.
Crucially, in key–value retrieval tasks, Multiscreen excels. In the ABCDigits benchmark—explicitly constructed to isolate retrieval and exclude semantic/heuristic signals—Multiscreen attains near-perfect accuracy even for context lengths of 217 tokens, and substantially outperforms equivalently scaled Transformers, which fail to retrieve with nontrivial frequency even at trained context lengths.
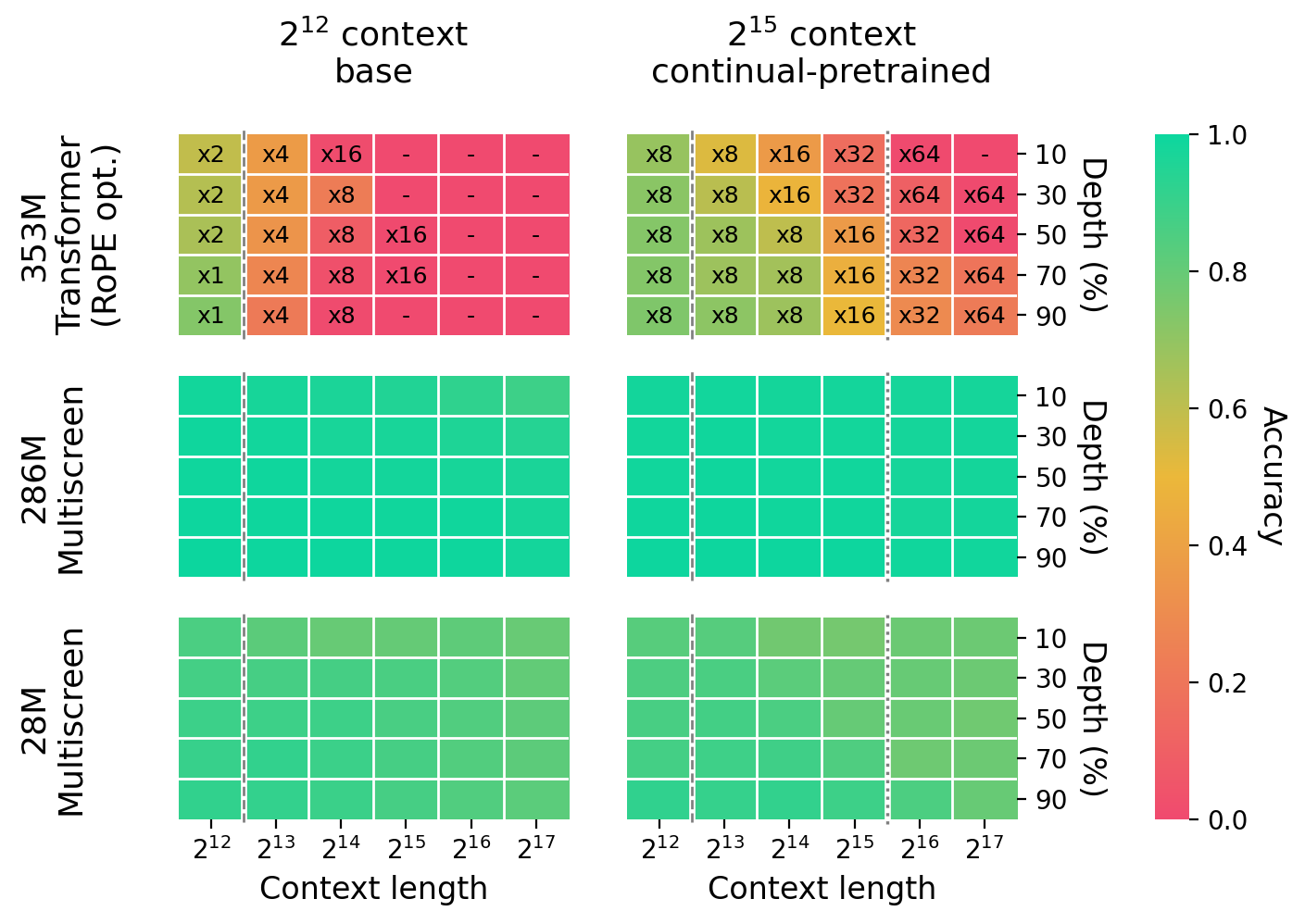
Figure 7: Example of an ABCDigits prompt, showing the synthetic, semantics-free key–value retrieval format.
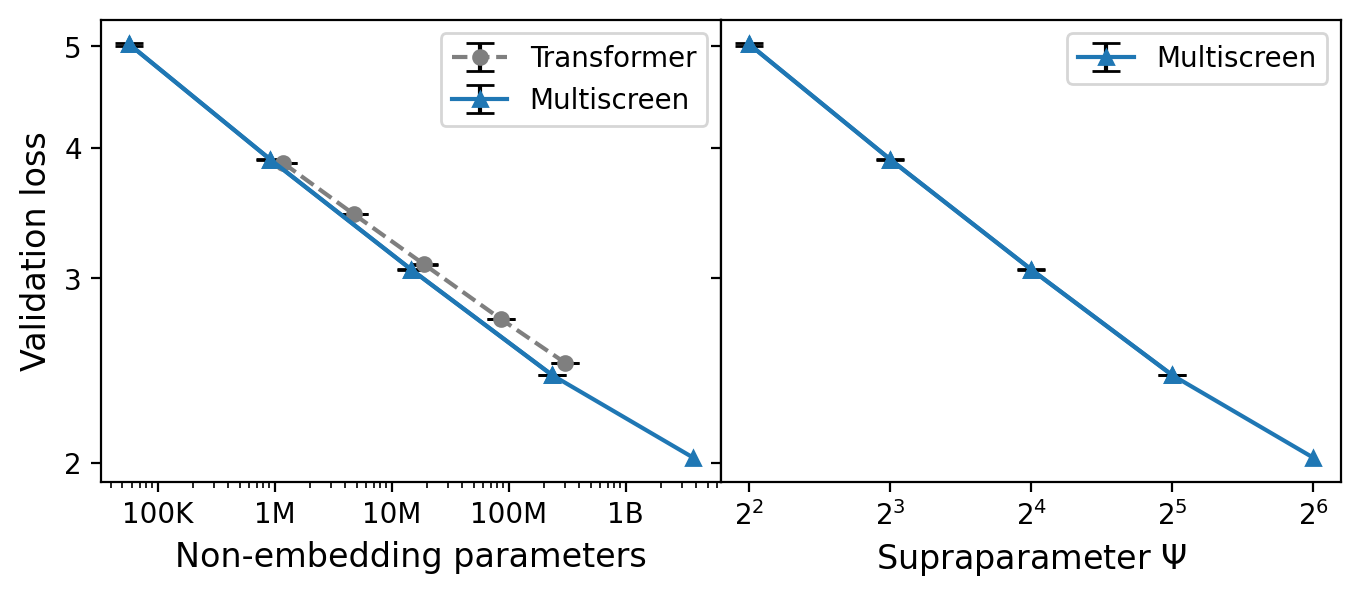
Figure 8: Across model scales and context lengths, Multiscreen maintains high retrieval accuracy on ABCDigits, while Transformers breakdown beyond the pretraining context.
Remarkably, smaller Multiscreen models can outperform substantially larger Transformers in raw retrieval accuracy, even when carrying higher validation loss, emphasizing that standard next-token prediction metrics are not reliable proxies for retrieval capabilities.
Inference Latency
Owing to learned sparse windows and computational skipping for tiles with limited context range, Multiscreen attains 2.3–3.2× lower inference latency for single-token prediction at 100k-token context, compared to Transformers, without sacrificing performance.
Theoretical and Practical Implications
Rethinking Context Aggregation
The findings illustrate that absolute relevance selection is a crucial architectural inductive bias enabling both efficiency and interpretability:
- Models need not forcibly allocate attention mass to irrelevant tokens (addressing the "dilution" problem).
- Representations in Multiscreen are more robust, exhibiting meaningful sparsity and local decisions without adversarial interaction among keys.
- Generalization to long contexts and retrieval is vastly improved, even beyond nominal training windows.
Training and Deployment Efficiency
By stabilizing gradient and update dynamics:
- Training can use larger learning rates, reducing wallclock and compute to convergence.
- Inference is accelerated by learned, context-dependent windowing, reducing operational costs for long-context deployments.
Future Prospects
This research indicates directions for further architectural innovation:
- Extending absolute-relevance screening principles to multimodal, retrieval-augmented, or instruction-following settings.
- Developing improved analysis and debugging tools based on interpretable, modular screening maps.
- Revisiting benchmark design to prioritize direct measures of retrieval and long-context processing, as validation loss may not capture essential behaviors.
Conclusion
"Screening Is Enough" provides a thorough critique of standard softmax attention and introduces Multiscreen, which leverages absolute query–key relevance for efficient sequence modeling. Empirical results demonstrate significant improvements in parameter efficiency, training stability, long-context generalization, robust retrieval, and inference speed. The evidence implies that moving beyond redistribution-based attention is a crucial trajectory for advancing large-scale, context-aware sequence models. Multiscreen sets the groundwork for a new class of architectures grounded in explicit selection and interpretable information flow, with implications for improved LLM performance and resource utilization.