- The paper introduces a training-free method that analyzes embedding trajectories to detect abrupt discontinuities at splice boundaries in audio deepfakes.
- It employs first-order dynamics and multi-scale statistical fusion from frozen speech models, achieving competitive EER and AUC across linguistic and domain shifts.
- Experimental results demonstrate reliable cross-lingual and cross-domain performance without gradient updates or additional training, offering an efficient forensic framework.
TRACE: Training-Free Partial Audio Deepfake Detection via Embedding Trajectory Analysis of Speech Foundation Models
Introduction and Motivation
The proliferation of high-fidelity neural TTS, VC, and commercial LLM-driven audio synthesis systems has intensified the challenge of audio deepfake detection, particularly for the “partial deepfake” scenario: when only localized segments of a recording are manipulated and seamlessly embedded into bona fide speech. This manipulation adversarially evades conventional supervised detectors, which typically rely on supervised learning and often overfit to specific generative pipelines or require exhaustive frame-level annotations. The paper introduces TRACE, a strictly training-free countermeasure for partial audio deepfake detection. TRACE leverages the geometric properties of pretrained, frozen speech foundation models, hypothesizing that bona fide speech induces smooth, temporally coherent embedding trajectories, while manipulated segment boundaries are marked by abrupt discontinuities in the first-order transition dynamics of frame-level representations. TRACE’s cross-domain generality and operational efficiency address critical deployment and robustness limitations of supervised pipelines.
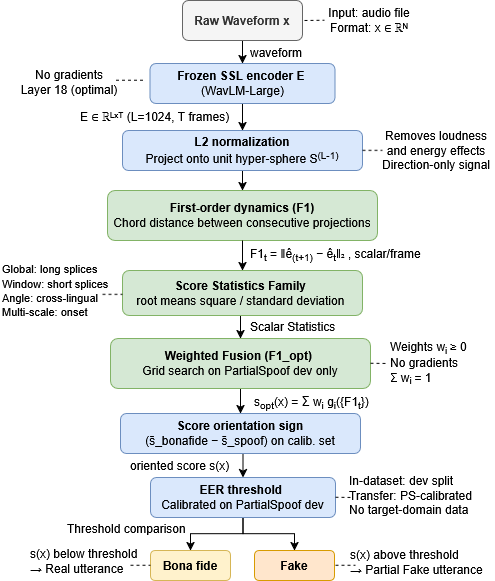
Figure 1: Overview of the TRACE pipeline—from raw waveform input, through frozen WavLM-Large (layer 18), L2 normalization, and computation of first-order dynamics, to score aggregation and spoof detection.
Methodology: Geometric Characterization of Splice Boundaries
The TRACE pipeline centers on analyzing the transition dynamics in the latent space of frozen speech models:
- Embedding Extraction: Given an utterance, frame-level representations (stride = 20ms) are extracted using a foundation model (e.g., WavLM-Large, HuBERT). Embeddings are projected onto the unit hypersphere to isolate directional information, suppressing nuisance variability (e.g., loudness or device effects).
- First-Order Dynamics (F1): For each consecutive pair t,t+1, the Euclidean chord distance is computed. This dynamic, F1t, captures the frame-to-frame trajectory “velocity.” Genuine speech is expected to exhibit smoothly varying transitions, while splice boundaries induce sharp discontinuities.
- Statistical Aggregation: Sequences of {F1t} are summarized via diverse statistics: global RMS, std/mean, sliding window maxima (for local spikes), multi-scale finite differences (for onsets), and angle-based direction-invariant metrics. These statistics are linearly fused, with weights calibrated on a development set, to yield an utterance-level spoof score.
- Score Orientation and Thresholding: Orientation is automatically calibrated to account for statistic directionality; thresholds are dataset-calibrated (for in-domain) or transferred directly (for cross-domain).
TRACE neither utilizes gradient updates nor any labeled or architectural customization, making it strictly training-free and foundation-model-agnostic.
Experimental Protocol
TRACE is evaluated across four representative benchmarks: PartialSpoof (English, TTS/VC splices), HAD and ADD2023 Track 2 (Mandarin, dense and short manipulations), and LlamaPartialSpoof (English, LLM/ElevenLabs). Six frozen foundation models are utilized, predominantly WavLM-Large (24-layer, 317M), with comparisons against state-of-the-art (SOTA) supervised baselines. Metrics include utterance-level EER and AUC, with stringent cross-corpus and cross-lingual transfer settings by direct threshold application (i.e., zero target domain adaptation).
Results
PartialSpoof Benchmark
On PartialSpoof, TRACE (optimal fusion at WavLM-Large, layer 18) achieves 8.08% EER and 0.97 AUC, matching or outperforming complex supervised systems trained with full frame-level annotations.
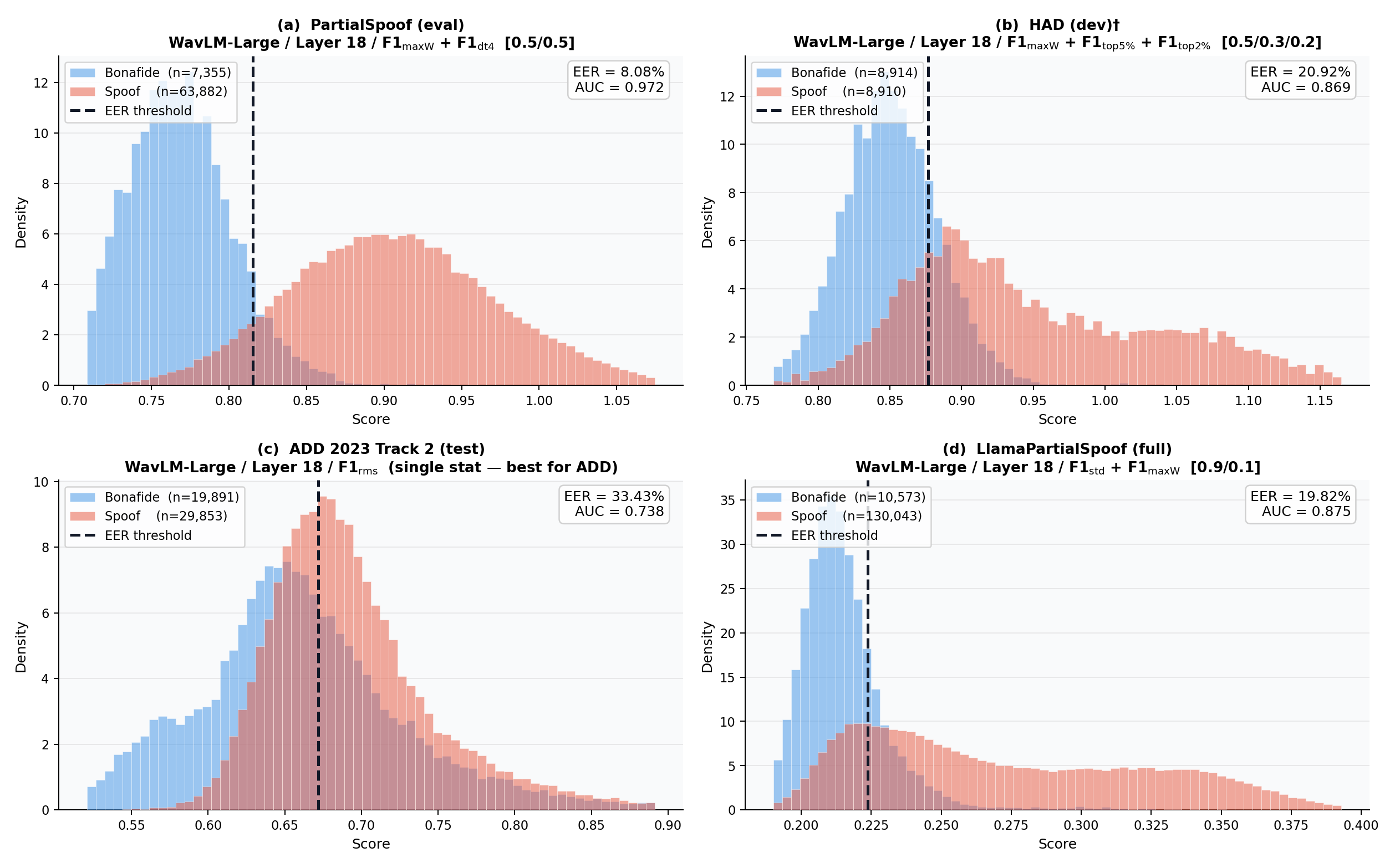
Figure 2: Score distributions across benchmarks indicate consistent separation between bonafide and partial-fake classes, verifying TRACE’s distributional invariance across both domains and languages.
The analysis highlights that intermediate backbone layers (not the last) maximize forensic discriminativity—semantic smoothing in the final layer degrades the boundary spike contrast, whereas layer 18 optimally captures abrupt acoustic changes.
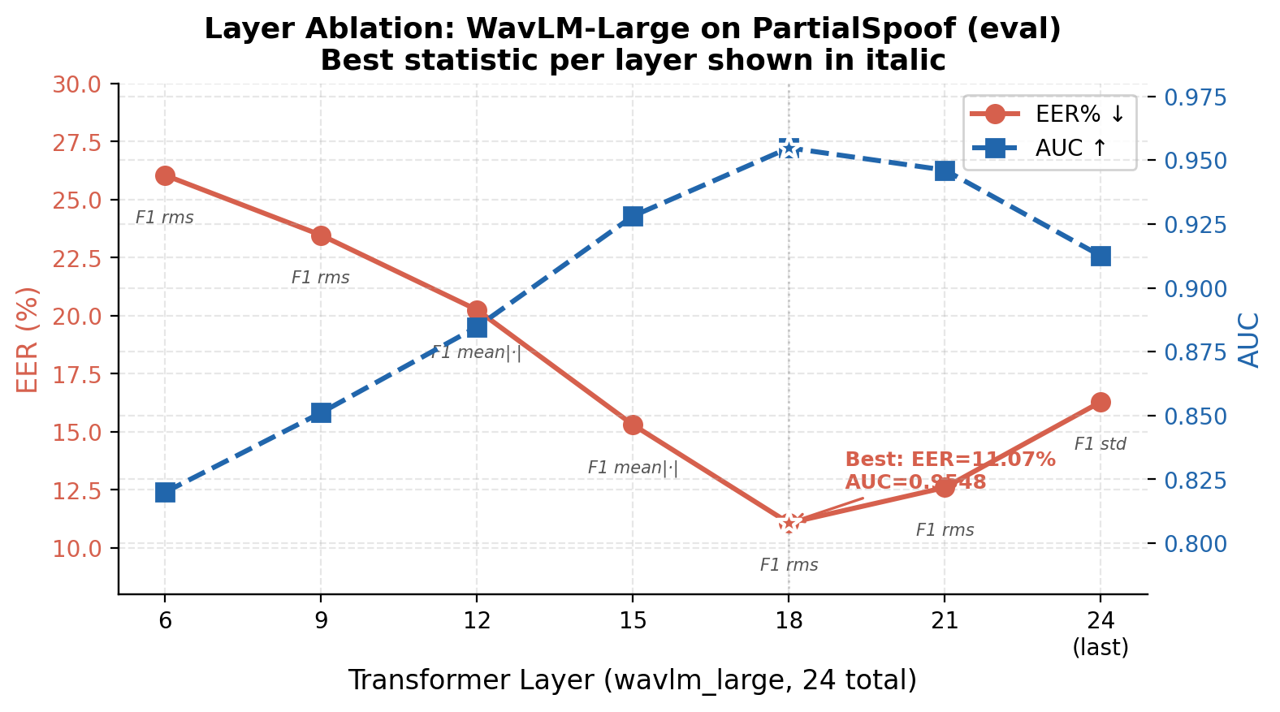
Figure 3: Per-layer ablation for WavLM-Large (F1-rms): EER curve minimizes at layer 18 and rises towards random at the last layer, affirming the critical importance of intermediate layer selection.
Cross-Lingual and Cross-Corpus Transfer
TRACE maintains non-trivial generalization on Mandarin (HAD: 20.92% EER, ADD2023: 33.43% EER) despite domain and language shift, outperforming the majority of training-free and many supervised models. Windowed and directionally fused statistics help mitigate local spoof-region dilution, decreasing EERs on more fragmented manipulations.
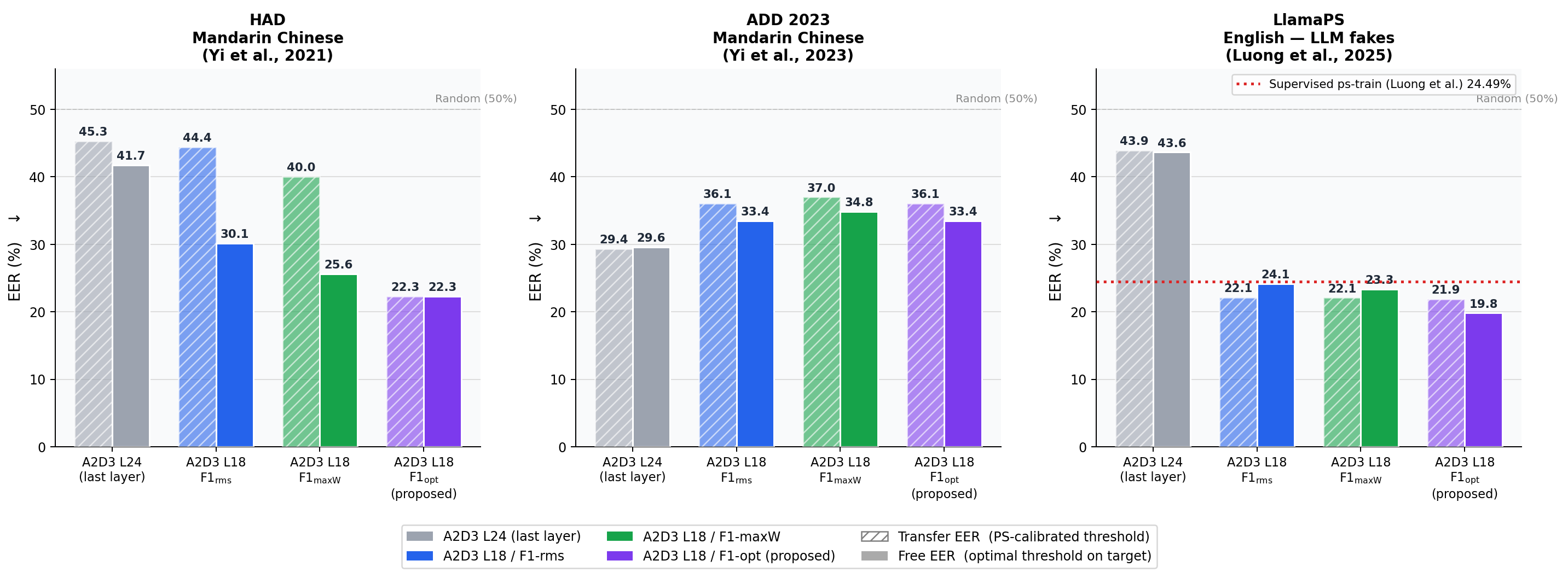
Figure 4: Transfer EER (PartialSpoof-calibrated threshold) vs. Free EER for cross-corpus deployment, confirming generalization and minimal adaptation cost.
Notably, the optimal fusion of magnitude and angle features is critical for cross-domain robustness, especially for language transfer. Direction-invariant statistics ameliorate calibration mismatch between English and Mandarin.
LlamaPartialSpoof: Unseen Synthesis Generalization
On the LlamaPartialSpoof dataset, which simulates black-box, commercial/LLM TTS attacks, TRACE not only generalizes but surpasses the best supervised baseline, achieving 24.12% EER versus 24.49% (SOTA PartialSpoof-trained) without observing any target-domain samples.
Key empirical claims:
- TRACE achieves or exceeds SOTA supervised detectors on the most challenging cross-domain partial deepfake benchmark (LlamaPartialSpoof), despite being strictly training-free.
- On fully synthesized utterances (no splice points), performance converges to random, which is a principled limitation aligned with the boundary-centric design.
Ablations and Statistic Design
Systematic ablations establish:
- First-order dynamics are consistently superior to second-order for all encoders; local boundary energy is the main invariant cue.
- Among 43 evaluated statistics, RMS, mean-absolute F1, and multi-scale RMS dominate for in-domain performance, while sliding window and angle statistics are vital for transfer robustness.
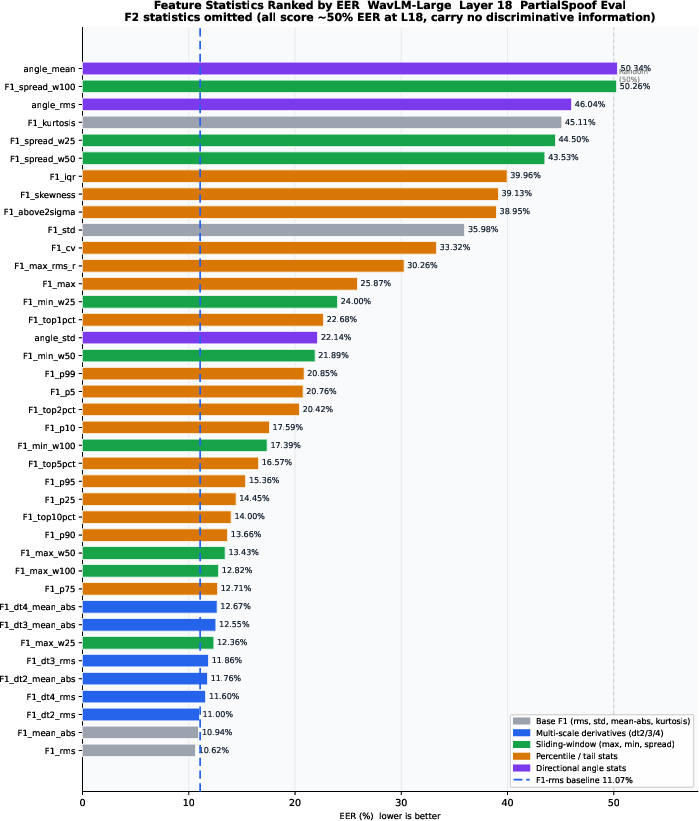
Figure 5: Full statistic ranking on PartialSpoof (WavLM-Large, layer 18): First-order RMS, mean-abs, and multi-scale derivatives lead; angle features are weak stand-alone but essential for transfer when fused.
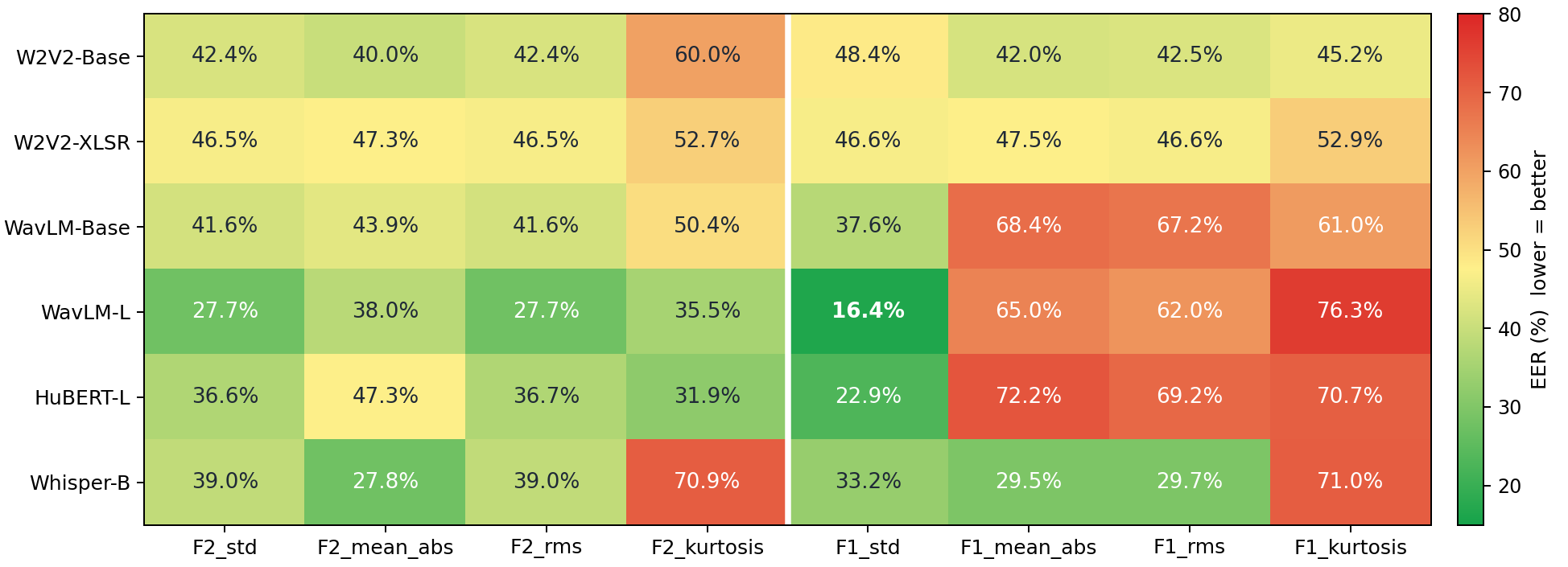
Figure 6: EER heatmap for encoder × statistic: WavLM-Large and HuBERT-Large yield the best results, with F1 consistently superior to F2 and kurtosis statistics unreliable.
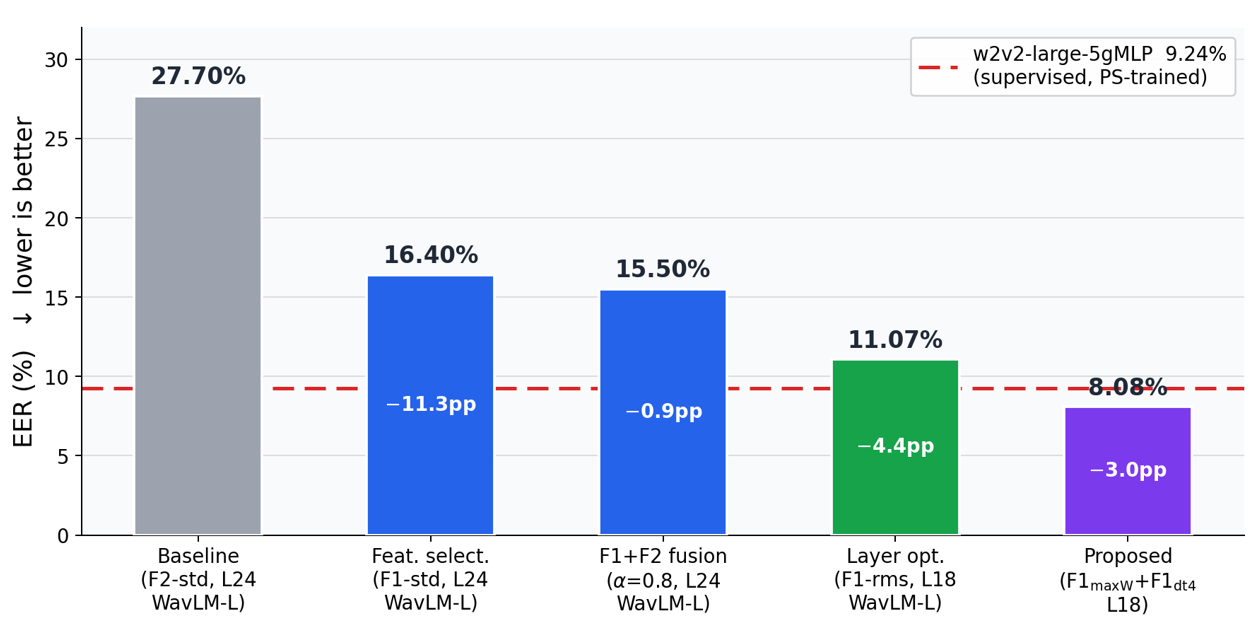
Figure 7: Progressive improvement of TRACE: Early baselines already outperform classical methods; optimal fusion reduces EER below the state-of-the-art.
Implications and Future Directions
TRACE highlights the viability of analyzing the intrinsic dynamics of frozen foundation model embeddings for forensics. The strong generalization across:
- languages (English/Chinese),
- unseen synthesis (e.g., LLM-based),
- and manipulation strategies
suggests that geometry-driven signals in foundation models are domain invariant and robust to rapid generative model evolution. Unlike approaches requiring continual labeling and retraining, TRACE delivers a robust, low-maintenance forensic framework—critical for reaction time and cost in security-critical deployments.
Limitations include reduced efficacy on fully synthetic utterances and dependency on a preselected statistic combination. Advances may emerge from:
- unsupervised identification of discriminative statistics,
- fusion of frame-level anomaly maps for localization,
- extension to vision and multimodal domains for universal deepfake forensics,
- and systematic mapping of “forensic phase transitions” in embedding layers of massive foundation models.
Conclusion
TRACE fundamentally shifts the paradigm for partial audio deepfake detection from supervised, data-dependent strategies to analytical, training-free exploitation of speech foundation model geometry. The evidence refutes the necessity of labeled data and gradient-based fine-tuning for discriminative detection in the partial deepfake regime. Foundation models’ latent dynamics encode robust, cross-lingual, and cross-domain forensic signals—TRACE’s pipeline provides a quantifiable and scalable means of surfacing those invariants. As models scale and representation learning advances, the efficacy of behavioral and geometric analysis for forensics will likely only increase, complementing or even displacing supervised adversarial arms races.

